
Apache Kafka — це служба потокового передавання повідомлень, яка дозволяє різним програмам у розподіленій системі спілкуватися та обмінюватися даними через повідомлення.
Він функціонує як паб/підсистема, де програми-виробники публікують повідомлення, а системи споживачів підписуються на них.
Apache Kafka дає змогу прийняти архітектуру слабкого зв’язку між частинами вашої системи, які створюють і споживають дані. Це спрощує проектування та керування системою. Kafka покладається на Zookeeper для керування метаданими та синхронізації різних елементів кластера.
Особливості Apache Kafka
Apache Kafka став популярним, серед інших причин
- Масштабується за допомогою кластерів і розділів
- Швидкий, здатний виконувати 2 мільйони записів за секунду
- Зберігає порядок надсилання повідомлень
- Надійний завдяки своїй системі копій
- Його можна оновити без простоїв
Тепер давайте розглянемо деякі типові випадки використання Kafka.
Загальні випадки використання Apache Kafka
Kafka часто використовується для обробки великих даних, запису та агрегування подій, таких як натискання кнопок для аналітики, і об’єднання журналів із різних частин системи в одному центральному місці.
Це допомагає у забезпеченні зв’язку між різними програмами в системі та обробці даних у реальному часі з пристроїв IoT.
Тепер давайте перевіримо докладні кроки для встановлення Kafka на Windows і Linux.
Встановлення Kafka на Windows
Спочатку перевірте, чи на вашому комп’ютері встановлено Java, щоб інсталювати Apache Kafka у Windows. Відкрийте командний рядок у режимі адміністратора та введіть команду:
java --version
Якщо інстальовано Java, ви повинні отримати номер поточної інстальованої версії JDK.
Якщо ви отримуєте повідомлення про помилку, що команду не розпізнано, Java не встановлено, і вам потрібно встановити Java. Щоб інсталювати Java, перейдіть на Adoptium.net і натисніть кнопку завантаження.
Це має завантажити файл інсталятора Java. Після завершення завантаження запустіть інсталятор. Це має відкрити підказку встановлення.
Щоб вибрати параметри за замовчуванням, кілька разів натисніть «Далі». Після цього слід розпочати встановлення. Перевірте встановлення, закривши командний рядок, повторно відкривши інший командний рядок у режимі адміністратора та ввівши команду:
java --version
Цього разу ви повинні отримати версію JDK, яку щойно встановили. Після завершення встановлення ми можемо почати встановлення Kafka.
Щоб установити Kafka, спочатку перейдіть на веб-сайт Kafka.

Клацніть посилання, і воно має перевести вас на сторінку завантажень. Завантажте найновіші доступні двійкові файли.
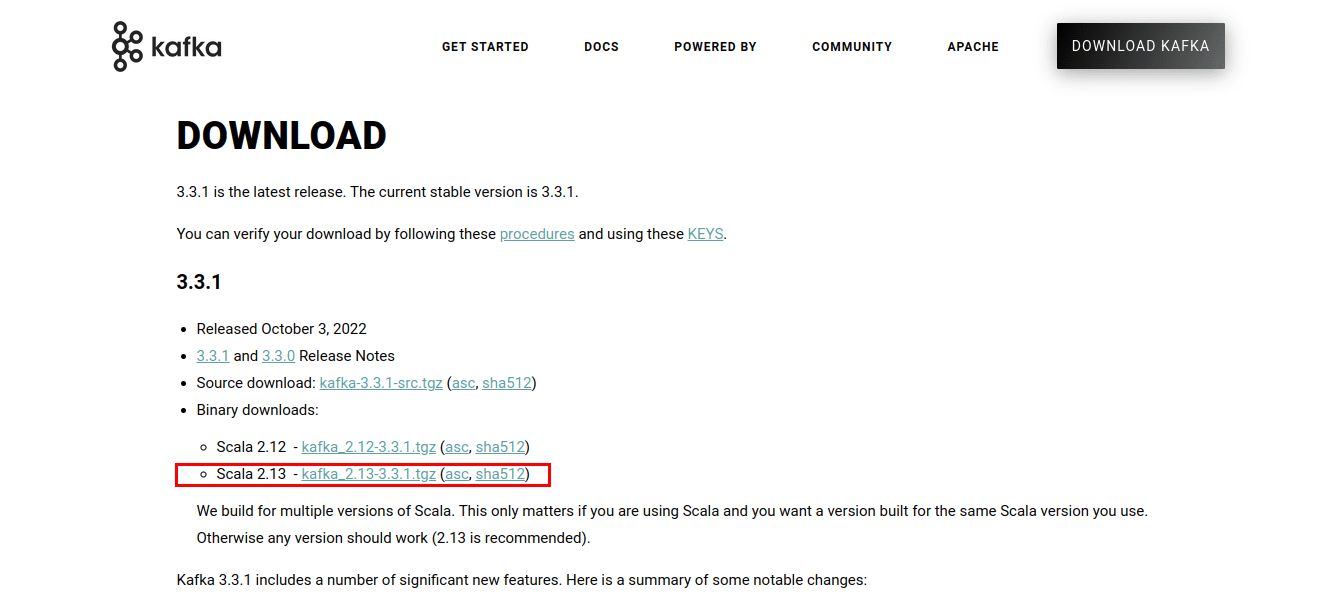
Це завантажить сценарії Kafka та двійкові файли, упаковані у файл .tgz. Після завантаження ви повинні розпакувати файли з архіву .tgz. Для розпакування я буду використовувати WinZip, який можна завантажити з веб-сайту WinZip.
Після вилучення файлу перемістіть його на C: так, щоб шлях до файлу став C:kafka
Потім відкрийте командний рядок у режимі адміністратора та запустіть Zookeeper, спочатку перейшовши до каталогу Kafka. І запустіть файл zookeeper-server-start.bat із zookeeper.properties як файл конфігурації
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
Коли Zookeeper запущено, нам потрібно додати виконуваний файл wmic, який використовує Kafka, у наш системний ШЛЯХ,
set PATH=C:WindowsSystem32wbem;%PATH%;
Після цього запустіть сервер Apache Kafka, відкривши інший сеанс командного рядка в режимі адміністратора та перейшовши до папки C:kafka
cd C:kafka
Тоді почніть Кафку з бігу
binwindowskafka-server-start.bat configserver.properties
З цим Кафка мав би працювати. Ви можете налаштувати властивості сервера, наприклад місце запису журналів у файлі server.properties.
Встановлення Kafka на Linux
По-перше, переконайтеся, що ваша система оновлена, оновивши всі пакети
sudo apt update && sudo apt upgrade
Далі перевірте, чи Java встановлено на вашій машині, запустивши
java --version
Якщо java встановлена, ви побачите номер версії. Однак якщо це не так, ви можете встановити його за допомогою apt.
sudo apt install default-jdk
Після цього ми можемо встановити Apache Kafka, завантаживши двійкові файли з веб-сайту.
Відкрийте свій термінал і перейдіть до папки, де було збережено завантаження. У моєму випадку мені потрібно перейти до папки «Завантаження».
cd Downloads
Опинившись у папці завантажень, розпакуйте завантажені файли за допомогою tar:
tar -xvzf kafka_2.13-3.3.1.tgz
Перейдіть до витягнутої папки
cd kafka_2.13-3.3.1.tgz
Перелічіть каталоги та файли.
Опинившись у папці, запустіть сервер Zookeeper, запустивши сценарій zookeeper-server-start.sh, розташований у каталозі bin витягнутої папки.
Сценарій потребуватиме файл конфігурації Zookeeper. Файл за замовчуванням називається zookeeper.properties і розташований у підкаталозі config.
Отже, щоб запустити сервер, використовуйте команду:
bin/zookeeper-server-start.sh config/zookeeper.properties
Запустивши Zookeeper, ми можемо запустити сервер Apache Kafka. Сценарій kafka-server-start.sh також знаходиться в каталозі bin. Команда також очікує файл конфігурації. Типовим є server.properties, що зберігається у файлі конфігурації.
bin/kafka-server-start.sh config/server.properties
Це має запустити Apache Kafka. У каталозі bin ви знайдете багато сценаріїв для створення тем, керування виробниками та споживачами. Ви також можете налаштувати властивості сервера у файлі server.properties.
Заключні слова
У цьому посібнику ми розповіли, як встановити Java та Apache Kafka. Хоча ви можете встановлювати та керувати кластерами Kafka вручну, ви також можете використовувати керовані параметри, такі як Amazon Web Services і Confluent.
Далі ви можете навчитися обробці даних за допомогою Kafka та Spark.