У MongoDB конвеєр агрегації є оптимальним інструментом для виконання складних запитів. Якщо ви раніше використовували MapReduce, рекомендується перейти на конвеєр агрегації для підвищення ефективності обчислень.
Що таке агрегація в MongoDB та як вона функціонує?
Конвеєр агрегації являє собою багатоетапний процес, призначений для обробки розширених запитів у MongoDB. Дані проходять обробку на різних етапах, що формують конвеєр. Результати, отримані на одному етапі, можуть бути використані як вхідні дані для наступного.
Наприклад, ви можете передати результат операції фільтрації на етап сортування, і так далі, доки не досягнете бажаного результату.
Кожен етап конвеєра агрегації використовує оператор MongoDB та створює один або кілька трансформованих документів. Залежно від вашого запиту, певний етап може використовуватися кілька разів. Наприклад, вам може знадобитися застосувати оператори $count або $sort декілька разів протягом конвеєра.
Етапи конвеєра агрегації
Конвеєр агрегації передає дані через послідовність етапів в межах одного запиту. Існує різноманіття етапів, детальний опис яких можна знайти в документації MongoDB.
Розглянемо деякі з найбільш часто використовуваних етапів.
Етап $match
Цей етап призначений для визначення конкретних умов фільтрації даних перед виконанням інших етапів агрегації. Він дозволяє вибрати тільки ті дані, які відповідають заданим критеріям, для подальшої обробки.
Етап $group
На етапі групування дані розподіляються на окремі групи на основі певних критеріїв, використовуючи пари “ключ-значення”. Кожна група представляє окремий ключ у вихідному документі.
Наприклад, розглянемо наступні дані про продажі:
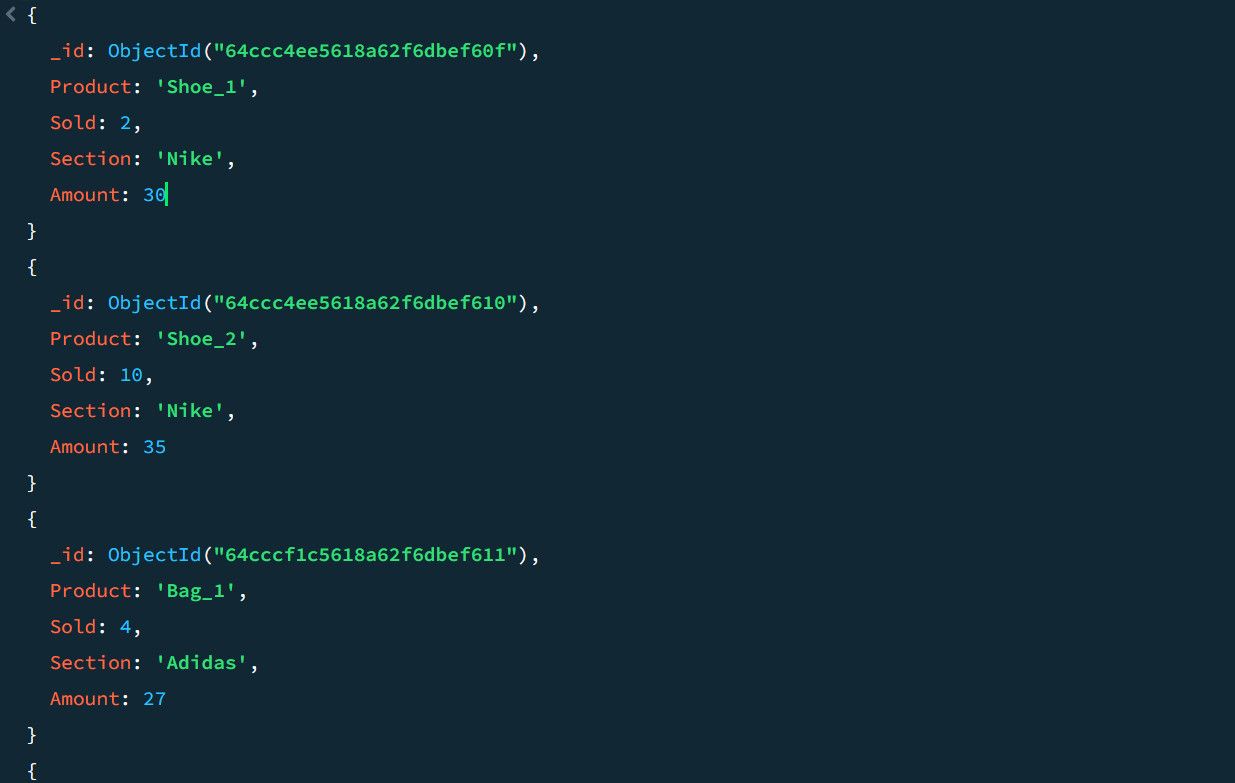
Використовуючи конвеєр агрегації, ви можете обчислити загальну кількість продажів та максимальну суму продажів для кожного розділу товару:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Пара “_id: $Section” групує вихідні документи за розділами. Призначення полів “total_sales_count” та “top_sales” дає можливість MongoDB створити нові ключі на основі агрегаційних операцій, таких як $sum, $min, $max або $avg.
Етап $skip
Етап $skip дозволяє пропустити задану кількість документів у вихідних даних. Він часто використовується після етапу групування. Наприклад, якщо ви очікуєте два документи, але пропускаєте один, агрегація виведе тільки другий.
Для застосування етапу пропуску, додайте оператор $skip до конвеєра агрегації:
...,
{
$skip: 1
},
Етап $sort
Етап сортування дозволяє впорядкувати дані в порядку зростання або спадання. Наприклад, можна додатково відсортувати дані з попереднього прикладу в порядку спадання, щоб визначити розділ з найбільшими продажами.
Додайте оператор $sort до попереднього запиту:
...,
{
$sort: {top_sales: -1}
},
Етап $limit
Операція обмеження дозволяє зменшити кількість вихідних документів, які ви хочете отримати в конвеєрі агрегації. Наприклад, можна використати оператор $limit, щоб отримати розділ з найбільшими продажами, що був визначений на попередньому етапі:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Зазначений запит поверне лише перший документ, який є розділом з найвищими продажами, оскільки він знаходиться на початку відсортованого результату.
Етап $project
Етап $project дозволяє змінювати вигляд вихідного документа за вашим бажанням. З використанням оператора $project, ви можете вказати, які поля включити до виводу та змінити їхні назви.
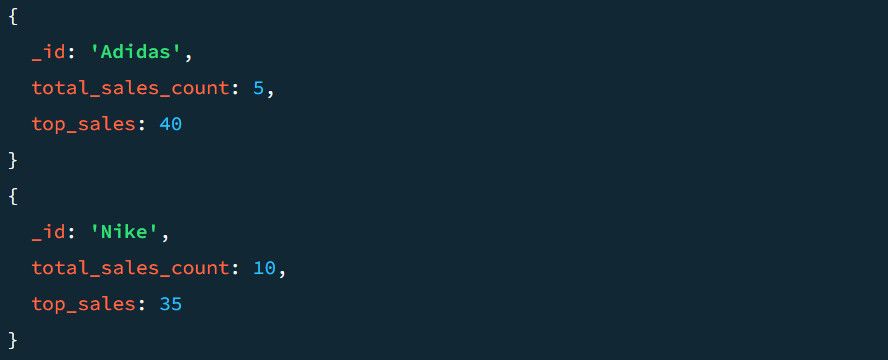
Наприклад, результат без етапу $project може виглядати наступним чином:
Давайте поглянемо, як він виглядатиме після застосування етапу $project. Для цього додайте наступний код до конвеєра:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Оскільки ми раніше згрупували дані за розділами товарів, наведений вище запит включає кожен розділ товару до вихідного документа. Він також гарантує, що загальна кількість продажів і максимальна сума продажів будуть відображені як “TotalSold” та “TopSale” відповідно.
Кінцевий результат є набагато більш структурованим у порівнянні з початковим:

Етап $unwind
Етап $unwind розбиває масиви в документах на окремі документи. Розглянемо наступні дані про замовлення:
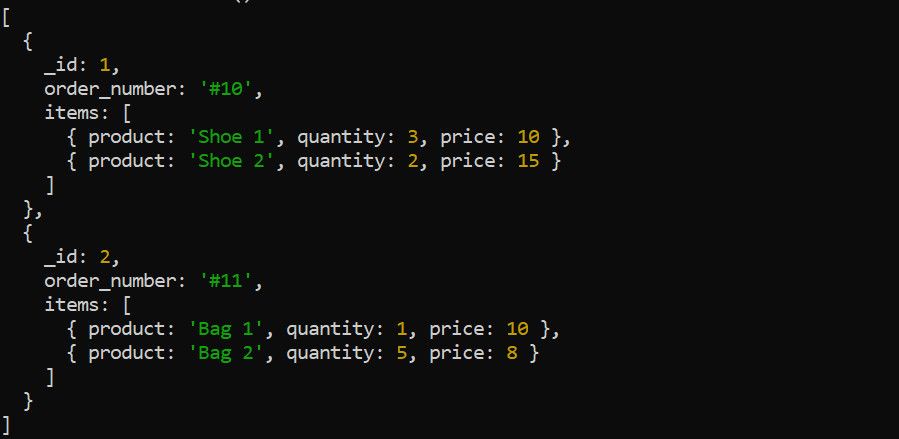
Застосуйте етап $unwind для деконструкції масиву товарів перед використанням інших етапів агрегації. Наприклад, розгортання масиву є корисним, якщо ви хочете обчислити загальний дохід для кожного товару:
db.Orders.aggregate([
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Ось результат вищезазначеного агрегаційного запиту:

Як створити конвеєр агрегації в MongoDB
Конвеєр агрегації складається з декількох операцій. Описані вище етапи дають загальне уявлення про те, як їх можна застосовувати в конвеєрі, а також наведено базовий приклад запиту для кожного з них.
Використовуючи попередній зразок даних про продажі, об’єднаємо деякі з розглянутих етапів в один фрагмент для кращого розуміння конвеєра агрегації:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Кінцевий результат матиме вигляд, показаний раніше:
Конвеєр агрегації проти MapReduce
До моменту припинення підтримки в MongoDB 5.0, MapReduce був традиційним методом агрегування даних у MongoDB. Хоча MapReduce має ширше застосування за межами MongoDB, він є менш ефективним порівняно з конвеєром агрегації, оскільки вимагає окремого написання функцій “map” та “reduce”, що нерідко потребує використання сторонніх скриптів.
З іншого боку, конвеєр агрегації є специфічним для MongoDB, але він пропонує більш зрозумілий та ефективний спосіб виконання складних запитів. Окрім простоти та масштабованості запитів, наявні етапи конвеєра дозволяють гнучко налаштовувати вихід.
Існує багато інших відмінностей між конвеєром агрегації та MapReduce, які ви побачите при переході з MapReduce на конвеєр агрегації.
Зробіть запити великих даних ефективними в MongoDB
Ваш запит повинен бути максимально ефективним для виконання складних обчислень з великими об’ємами даних у MongoDB. Конвеєр агрегації ідеально підходить для виконання розширених запитів. Замість того, щоб маніпулювати даними в окремих операціях, що часто знижує продуктивність, агрегація дозволяє об’єднати всі операції в один ефективний конвеєр та виконати їх за один прохід.
Хоча конвеєр агрегації є ефективнішим за MapReduce, ви можете зробити агрегацію ще швидшою та ефективнішою, індексуючи свої дані. Це обмежить обсяг даних, який MongoDB потрібно сканувати на кожному етапі агрегації.