У сучасній царині штучного інтелекту (ШІ), навчання з підкріпленням (RL) займає передові позиції серед напрямків досліджень. Розробники інтелектуальних систем та машинного навчання (ML) активно використовують методи RL для створення інноваційних програм та інструментів.
Машинне навчання є фундаментальним принципом, на якому базуються всі продукти ШІ. Розробники застосовують різноманітні методології ML для навчання своїх інтелектуальних додатків, ігор та іншого. ML – це широка галузь, і постійно з’являються нові методи навчання машин.
Одним з перспективних методів ML є глибоке навчання з підкріпленням, де небажана поведінка машини карається, а бажані дії заохочуються. Експерти вважають, що цей метод машинного навчання дозволяє ШІ навчатися на власному досвіді.
Якщо ви розглядаєте кар’єру в галузі штучного інтелекту та машинного навчання, цей посібник з методів навчання з підкріпленням для інтелектуальних програм та машин стане для вас корисним.
Що являє собою навчання з підкріпленням у машинному навчанні?
RL – це процес навчання моделей машинного навчання для комп’ютерних програм. Після цього програма здатна приймати рішення, послідовно базуючись на навчених моделях. Програмне забезпечення навчається досягати мети в умовах потенційно складного та невизначеного середовища. У такій моделі машинного навчання ШІ стикається із ситуацією, подібною до гри.
Додаток зі штучним інтелектом використовує підхід проб і помилок, щоб знайти ефективне вирішення проблеми. Коли програма ШІ освоює правильні моделі ML, вона надає вказівки машині, якою керує, для виконання певних завдань, визначених програмістом.
За правильне рішення та виконання завдання ШІ отримує винагороду. Однак, якщо ШІ робить помилковий вибір, його очікує покарання, наприклад, втрата бонусних балів. Головна мета програми ШІ – накопичити якомога більше бонусних балів для досягнення успіху у грі.
Програміст програми ШІ встановлює правила гри або політику винагород. Він також визначає проблему, яку ШІ повинен розв’язати. На відміну від інших моделей ML, програма ШІ не отримує жодних прямих підказок від програміста.
Штучний інтелект повинен самостійно розібратися, як вирішувати ігрові завдання, щоб отримати максимальну винагороду. Для досягнення мети додаток може використовувати метод проб і помилок, випадкові випробування, можливості суперкомп’ютера та складні когнітивні стратегії.
Ви повинні забезпечити програму ШІ потужною обчислювальною інфраструктурою та інтегрувати її систему мислення з різноманітними паралельними та історичними процесами гри. Завдяки цьому ШІ зможе продемонструвати високий рівень критичного мислення, який може виходити за межі людських можливостей.
Популярні приклади навчання з підкріпленням
#1. Перемога над найкращим гравцем у Го
AlphaGo AI від DeepMind Technologies, дочірньої компанії Google, є одним із показових прикладів машинного навчання з використанням RL. ШІ грає в китайську настільну гру Го, якій 3000 років і яка базується на тактиці та стратегії.
Програмісти використовували метод RL для навчання AlphaGo. Він провів тисячі ігрових сеансів, граючи в Го з людьми та сам із собою. У 2016 році він переміг найкращого гравця Го у світі, Лі Седола, в особистій зустрічі.
#2. Робототехніка в реальних умовах
Традиційно робототехніка використовується на виробничих лініях для виконання заздалегідь запрограмованих і повторюваних завдань. Однак, створення багатофункціонального робота для реальних умов, де дії не є заздалегідь визначеними, є значним викликом.
Тим не менш, ШІ з використанням навчання з підкріпленням здатний знаходити плавні, ефективні та найкоротші маршрути між двома точками.
#3. Автономні транспортні засоби
Дослідники автономних транспортних засобів активно застосовують методи RL для навчання свого ШІ у таких сферах:
- Динамічне планування маршрутів
- Оптимізація траєкторій
- Планування маневрів, таких як паркування та перестроювання в іншу смугу руху
- Оптимізація контролерів (електронних блоків керування) ECU, (мікроконтролерів) MCU тощо
- Навчання на різних сценаріях на автострадах
#4. Автоматизовані системи охолодження

ШІ, що базується на RL, може сприяти мінімізації споживання енергії системами охолодження у великих офісних будівлях, бізнес-центрах, торгових комплексах та, особливо, у центрах обробки даних. ШІ збирає дані з тисяч теплових датчиків.
Він також аналізує дані про активність людей та машин. На основі цієї інформації ШІ здатний передбачити майбутній потенціал тепловиділення та відповідно вмикати/вимикати системи охолодження для економії енергії.
Як налаштувати модель навчання з підкріпленням
Модель RL можна налаштувати за допомогою таких методів:
#1. На основі політики
Цей підхід допомагає програмісту ШІ розробити оптимальну стратегію для досягнення максимальної винагороди. Програміст не використовує функцію значення. Після встановлення методу на основі політики агент навчання з підкріпленням намагається реалізувати цю стратегію, щоб дії, які він робить на кожному етапі, дозволяли ШІ максимізувати бали винагороди.
Загалом, існує два типи політики:
#1. Детермінований: політика завжди призводить до однакових дій у заданому стані.
#2. Стохастичний: дії визначаються ймовірністю їх виникнення.
#2. На основі цінностей
Підхід, що базується на цінностях, допомагає програмісту знайти оптимальну функцію значення, яка представляє максимальне значення за стратегією в певному стані. Після застосування агент RL очікує на довгостроковий прибуток у одному або кількох станах відповідно до визначеної стратегії.
#3. На основі моделі
У підході RL на основі моделі програміст ШІ створює віртуальну модель середовища. Після цього агент RL взаємодіє з цим середовищем і навчається в ньому.
Типи навчання з підкріпленням
#1. Навчання з позитивним підкріпленням (PRL)
Позитивне навчання передбачає додавання певних елементів, щоб збільшити ймовірність повторення очікуваної поведінки. Цей метод навчання позитивно впливає на дії агента RL та підвищує силу певної поведінки ШІ.
PRL-тип навчання з підкріпленням готує ШІ до адаптації до змін протягом тривалого часу. Однак надмірна кількість позитивного підкріплення може призвести до перевантаження станами, що може зменшити ефективність ШІ.

#2. Навчання з негативним підкріпленням (NRL)
Коли алгоритм RL допомагає ШІ уникати або припиняти небажану поведінку, він вчиться на цьому та покращує свої майбутні дії. Це називається негативним навчанням. Воно надає ШІ обмежений інтелект, щоб відповідати конкретним поведінковим вимогам.
Реальні приклади використання навчання з підкріпленням
#1. Розробники рішень для електронної комерції створили персоналізовані інструменти для рекомендацій товарів або послуг. Ви можете інтегрувати API цього інструменту на свій сайт для онлайн-покупок. ШІ навчатиметься на основі дій кожного користувача і пропонуватиме персоналізовані товари та послуги.
#2. Відеоігри з відкритим світом надають безмежні можливості. За ігровим процесом стоїть програма ШІ, яка аналізує дані гравців та динамічно змінює код відеогри, щоб адаптуватися до непередбачуваних ситуацій.
#3. Торгові платформи акціями та інвестиційні платформи на основі ШІ використовують моделі RL для аналізу руху акцій та глобальних індексів. Відповідно до цього вони створюють ймовірнісну модель для рекомендацій акцій для інвестування або торгівлі.
#4. Онлайн-платформи для відео, такі як YouTube, Metacafe, Dailymotion, використовують ботів AI, навчених на моделях RL, щоб пропонувати своїм користувачам персоналізовані відео.
Навчання з підкріпленням проти. Контрольоване навчання
Мета навчання з підкріпленням – навчити агента ШІ приймати рішення послідовно. Іншими словами, вихід ШІ залежить від поточного вхідного сигналу. Так само наступний вхідний сигнал для алгоритму RL залежатиме від результату попередніх вхідних даних.

Роботизована машина на базі ШІ, яка грає в шахи проти людини, є прикладом моделі машинного навчання RL.
Навпаки, при контрольованому навчанні програміст навчає агента ШІ приймати рішення на основі вхідних даних, наданих на початку або будь-яких інших початкових вхідних даних. ШІ автономного автомобіля, який розпізнає об’єкти навколишнього середовища, є прикладом контрольованого навчання.
Навчання з підкріпленням проти. Навчання без контролю
Ви вже знаєте, що метод RL змушує агента ШІ вивчати стратегію моделі машинного навчання. Основна мета ШІ – виконувати дії, за які він отримує максимальну кількість бонусних балів. RL допомагає ШІ навчатися через спроби та помилки.
З іншого боку, під час неконтрольованого навчання програміст ШІ подає програмне забезпечення ШІ з даними без міток. Інструктор ML не надає ШІ жодної інформації про структуру даних або про те, що шукати у даних. Алгоритм вивчає різні рішення, самостійно аналізуючи задані набори даних.
Курси з навчання з підкріпленням
Після вивчення основних концепцій, представляємо декілька онлайн-курсів, які допоможуть вам поглибити знання у сфері навчання з підкріпленням. Також ви отримаєте сертифікат, який можна використовувати у LinkedIn або інших соціальних мережах:
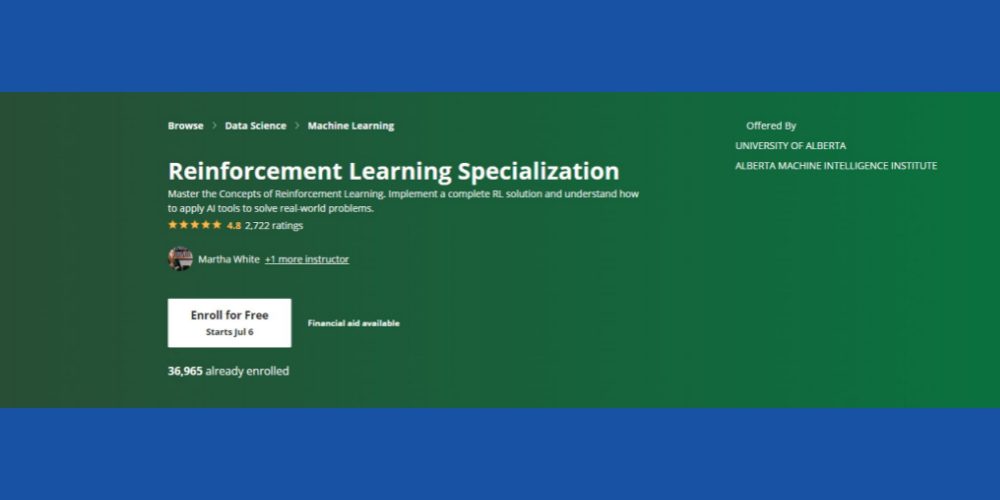
Спеціалізація з навчання з підкріпленням: Coursera
Бажаєте освоїти ключові концепції навчання з підкріпленням у контексті ML? Рекомендуємо розглянути цей Курс Coursera RL, що доступний онлайн і пропонує можливості для самостійного навчання та сертифікації. Курс підійде вам, якщо ви маєте наступні базові навички:
- Знання програмування на Python
- Базові статистичні концепції
- Можливість конвертувати псевдокоди та алгоритми в коди Python
- Досвід розробки програмного забезпечення від двох до трьох років
- Студенти другого курсу з інформатики також можуть брати участь
Курс має рейтинг 4,8 зірки, і понад 36 тисяч студентів вже зареєструвалися на різні курси. Крім того, курс пропонує фінансову допомогу, якщо кандидат відповідає певним критеріям Coursera.
Цей курс пропонує Інститут машинного інтелекту Альберти Університету Альберти (без кредитів). Видатні професори у сфері інформатики будуть викладачами курсу. Після його завершення ви отримаєте сертифікат Coursera.
AI Reinforcement Learning у Python: Udemy
Якщо ви працюєте на фінансовому ринку або в цифровому маркетингу і бажаєте розробляти інтелектуальні програмні пакети для цих сфер, зверніть увагу на цей Курс RL на Udemy. Окрім основних принципів RL, зміст курсу навчить вас розробляти RL-рішення для онлайн-реклами та біржової торгівлі.

Деякі з тем, що охоплює курс:
- Загальний огляд RL
- Динамічне програмування
- Метод Монте-Карло
- Методи апроксимації
- Проект біржової торгівлі з RL
Понад 42 тисячі студентів вже пройшли цей курс. Навчальний онлайн-ресурс наразі має рейтинг 4,6 зірки, що є дуже вражаючим. Крім того, курс орієнтований на глобальну спільноту студентів, оскільки навчальний контент доступний французькою, англійською, іспанською, німецькою, італійською та португальською мовами.
Глибоке навчання з підкріпленням у Python: Udemy
Якщо ви допитливі і маєте базові знання про глибоке навчання та ШІ, можете спробувати цей просунутий Курс RL на Python від Udemy. Він має рейтинг 4,6 зірки від студентів і є ще одним популярним курсом для вивчення RL у контексті AI/ML.

Курс складається з 12 розділів і охоплює такі теми:
- OpenAI Gym та основні техніки RL
- TD Lambda
- A3C
- Основи Theano
- Основи TensorFlow
- Програмування на Python для початківців
Навчання займе 10 годин 40 хвилин. Крім тексту, курс включає 79 експертних лекцій.
Експерт з глибокого навчання з підкріпленням: Udacity
Бажаєте навчитися передовим технікам машинного навчання від провідних світових експертів ШІ/ML, таких як Nvidia Deep Learning Institute і Unity? Udacity дозволяє вам втілити цю мрію. Зверніть увагу на Глибоке навчання з підкріпленням, щоб стати експертом ML.

Однак вам потрібні знання просунутого Python, проміжної статистики, теорії ймовірностей, TensorFlow, PyTorch і Keras.
Щоб завершити курс, знадобиться до 4 місяців інтенсивного навчання. Під час курсу ви вивчите основні алгоритми RL, такі як глибокі детерміновані градієнти політики (DDPG), глибокі Q-мережі (DQN) тощо.
Заключні слова
Навчання з підкріпленням є наступним кроком у розвитку ШІ. Агенції, що займаються розробкою ШІ, та ІТ-компанії інвестують у цю галузь, щоб створювати надійні методи навчання ШІ.
Хоча RL вже досягло значних успіхів, є ще можливості для розвитку. Наприклад, окремі агенти RL не обмінюються знаннями між собою. Таким чином, якщо ви навчаєте додаток керувати автомобілем, процес навчання буде тривалим. Тому що агенти RL, які займаються виявленням об’єктів, розпізнаванням доріг тощо, не обмінюються даними.
Є можливість застосувати свій творчий потенціал і досвід ML до вирішення цих завдань. Реєстрація на онлайн-курси допоможе вам поглибити знання про передові методи RL та їх застосування у реальних проектах.
Для вас також може бути цікавою інформація про відмінності між штучним інтелектом, машинним навчанням і глибоким навчанням.