Операційні системи Linux та macOS використовують віртуальну пам’ять. Давайте розглянемо, як це впливає на завантаження фізичної пам’яті, центрального процесора та дискових ресурсів вашого комп’ютера.
Що являє собою віртуальна пам’ять?
Комп’ютер має обмежений обсяг фізичної пам’яті, відомої як оперативна пам’ять (ОЗП). Управління цією пам’яттю здійснюється ядром, і вона використовується спільно операційною системою та всіма запущеними програмами. Що робить ядро, якщо сумарні потреби в пам’яті перевищують фізичний обсяг встановленої ОЗП?
Операційні системи, такі як Linux та macOS, можуть використовувати дисковий простір для управління пам’яттю. Спеціальна область на жорсткому диску, звана “файлом підкачки”, може використовуватися як розширення оперативної пам’яті. Це і є віртуальна пам’ять.
Ядро Linux може переносити вміст блоку пам’яті до файлу підкачки, звільняючи цей простір в ОЗП для інших процесів. Пам’ять, що вивантажується (також називають її “свопнутою”), може бути відновлена з файлу підкачки назад в ОЗП, коли це потрібно.
Звісно, швидкість доступу до вивантаженої пам’яті нижча, ніж до пам’яті, що знаходиться в ОЗП. Це не єдиний компроміс. Хоча віртуальна пам’ять допомагає Linux керувати потребами в пам’яті, її використання збільшує навантаження на інші компоненти комп’ютера.
Вашому жорсткому диску доводиться виконувати більше операцій читання та запису. Ядро, а отже, і процесор, працюють активніше, переміщаючи дані, та підтримуючи обертання диска, щоб задовольнити потреби в пам’яті різних процесів.
Linux надає інструмент для моніторингу цієї активності – команду vmstat, яка надає статистику віртуальної пам’яті.
Команда vmstat
Якщо ви запустите команду vmstat без параметрів, вона відобразить набір значень. Ці значення є середніми показниками кожної статистичної величини з моменту останнього завантаження комп’ютера, а не миттєвим знімком.
vmstat

З’явиться таблиця з даними.
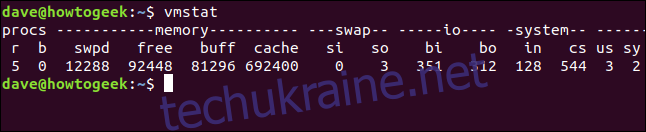
Вона містить стовпці Procs, Memory, Swap, IO, System та CPU. Останній стовпець (крайній правий) відображає дані, що стосуються центрального процесора.
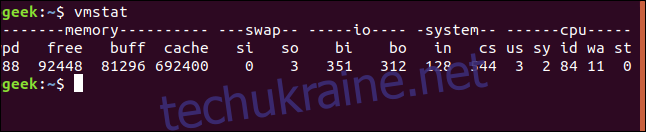
Ось опис елементів даних в кожному стовпці:
Proc
r: Кількість процесів, готових до виконання. Це процеси, які запущені і або виконуються, або очікують на свою чергу для отримання циклів процесора.
b: Кількість процесів у стані безперервного сну. Процес не просто спить, він виконує блокуючий системний виклик і не може бути перерваний, поки не завершить поточну операцію. Зазвичай це драйвер пристрою, який очікує на звільнення певного ресурсу. Будь-які переривання, що надходять для цього процесу, обробляються після завершення поточної операції.
Memory
swpd: Обсяг використовуваної віртуальної пам’яті, тобто скільки пам’яті було перенесено до файлу підкачки.
free: Обсяг вільної, неактивної пам’яті.
buff: Обсяг пам’яті, що використовується для буферів.
cache: Обсяг пам’яті, що використовується як кеш.
Swap
si: Обсяг віртуальної пам’яті, перенесеної з файлу підкачки.
so: Обсяг віртуальної пам’яті, перенесеної до файлу підкачки.
IO
bi: Блоки даних, отримані від блочного пристрою. Кількість блоків даних, які використовуються для переміщення віртуальної пам’яті назад в оперативну пам’ять.
bo: Блоки даних, надіслані блочному пристрою. Кількість блоків даних, що використовуються для переміщення віртуальної пам’яті з ОЗП до файлу підкачки.
System
in: Кількість переривань за секунду, включаючи переривання від годинника.
cs: Кількість перемикань контексту за секунду. Перемикання контексту відбувається, коли ядро перемикається з режиму ядра в режим користувача.
CPU
Усі значення в цьому стовпці є відсотками від загального часу процесора.
us: Час, витрачений на виконання коду поза ядром, тобто час користувача та пріоритетний час.
sy: Час, витрачений на виконання коду ядра.
id: Час простою.
wa: Час очікування введення-виведення.
st: Час, “вкрадений” у віртуальної машини. Це час, коли віртуальній машині доводиться чекати, поки гіпервізор завершить обслуговування інших віртуальних машин.
Використання інтервалів часу
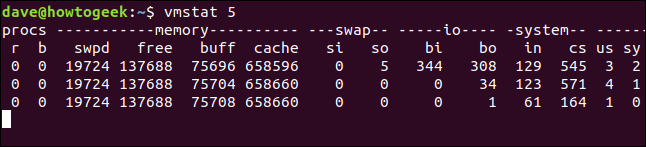
Ми можемо змусити vmstat регулярно оновлювати ці показники, використовуючи значення затримки, вказане в секундах. Наприклад, щоб оновлювати статистику кожні 5 секунд, скористаємось командою:
vmstat 5

Кожні п’ять секунд vmstat буде додавати новий рядок даних до таблиці. Для зупинки необхідно натиснути Ctrl+C.
Використання значення кількості
Занадто мале значення затримки може створити додаткове навантаження на систему. Якщо вам потрібні швидкі оновлення для діагностики проблеми, рекомендується використовувати значення кількості (count) разом зі значенням затримки.
Значення count вказує vmstat, скільки оновлень потрібно виконати, перш ніж завершити роботу та повернути вас до командного рядка. Без вказаного значення count, vmstat буде працювати до натискання Ctrl+C.
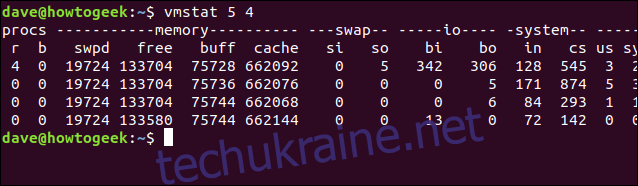
Щоб vmstat оновлював дані кожні 5 секунд, але лише 4 рази, скористайтеся командою:
vmstat 5 4

Після чотирьох оновлень vmstat завершить роботу автоматично.
Зміна одиниць вимірювання
Ви можете вибрати, щоб статистика пам’яті та підкачки відображалася в кілобайтах або мегабайтах, використовуючи параметр -S (символ одиниці). Після нього повинен йти один із символів: k, K, m або M. Вони означають:
k: 1000 байт
K: 1024 байти
m: 1 000 000 байт
M: 1 048 576 байт
Щоб статистика оновлювалася кожні 10 секунд, а дані пам’яті та підкачки відображалися в мегабайтах, використайте команду:
vmstat 10 -S M

Тепер статистика пам’яті та підкачки відображається в мегабайтах. Зверніть увагу, що параметр -S не впливає на статистику IO, вона завжди відображається в блоках.
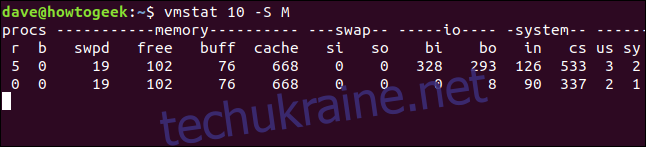
Активна та неактивна пам’ять
Якщо ви використовуєте параметр -a (активний), стовпці buff та cache замінюються стовпцями “inact” та “active”. Вони показують обсяг неактивної та активної пам’яті, відповідно.
Щоб побачити ці два стовпці замість buff та cache, додайте параметр -a:
vmstat 5 -a -S M

На неактивні та активні стовпці також впливає параметр -S (символ одиниці).
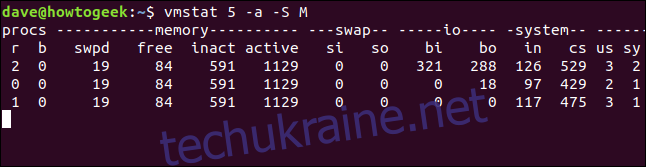
Розгалуження
Параметр -f показує кількість розгалужень (fork), що відбулися з моменту завантаження комп’ютера.
Іншими словами, це кількість запущених процесів (і більшість з них вже завершені) з моменту завантаження системи. Кожен процес, запущений з командного рядка, збільшує це число. Також воно збільшується щоразу, коли завдання створює або клонує нове завдання.
vmstat -f

Відображення кількості розгалужень не оновлюється.
Відображення інформації про плити (Slabinfo)
Ядро також має власну систему управління пам’яттю, крім управління пам’яттю для операційної системи та програм.
Ядро постійно виділяє та звільняє пам’ять для різних типів об’єктів даних, які воно обробляє. Для ефективності цього процесу ядро використовує систему “плит” (slabs), яка є формою кешування.
Пам’ять, виділена, використана та вже не потрібна для об’єкту даних ядра, може бути повторно використана для іншого об’єкту того ж типу без вивільнення та перерозподілу. Плити – це попередньо виділені сегменти оперативної пам’яті, що спеціально створені для потреб ядра.
Щоб переглянути статистику плит, використовуйте параметр -m (плити). Для цього потрібні права sudo, і вас попросять ввести пароль. Оскільки вивід може бути довгим, використаємо less для його перегляду.
sudo vmstat -m | less

Вивід має п’ять стовпців:
Кеш: Назва кешу.
num: Кількість активних об’єктів у цьому кеші.
total: Загальна кількість доступних об’єктів у цьому кеші.
size: Розмір кожного об’єкта в кеші.
сторінки: Загальна кількість сторінок пам’яті, що містять (принаймні) один об’єкт, пов’язаний з цим кешем.
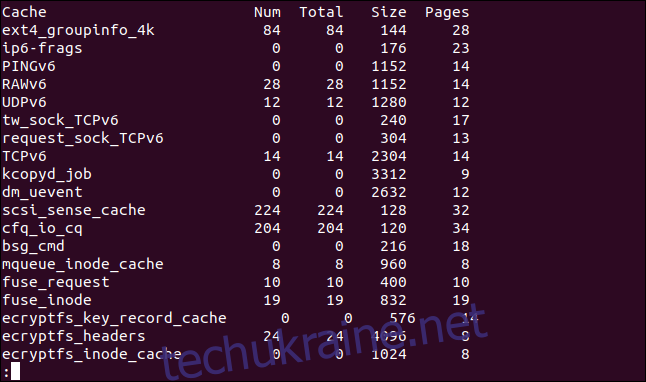
Натисніть q, щоб вийти з less.
Відображення лічильників подій та статистики пам’яті
Щоб відобразити лічильники подій та статистику пам’яті, використовуйте параметр -s (статистика). Зверніть увагу на малу літеру “s”.
vmstat -s

Статистичні дані в основному збігаються з інформацією, що відображається за замовчуванням, але деякі з них розбиті на детальніші категорії.
Наприклад, стандартний вивід об’єднує пріоритетний та непріоритетний час процесора в стовпці “us”. Вивід з параметром -s (статистика) показує ці дані окремо.
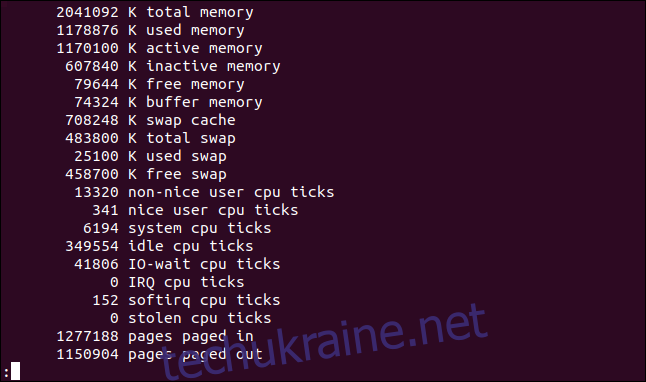
Відображення статистики диска
Ви можете отримати схожий список статистики диска, використовуючи параметр -d (диск).
vmstat -d | less

Для кожного диска відображаються три стовпці: Reads, Writes та IO.
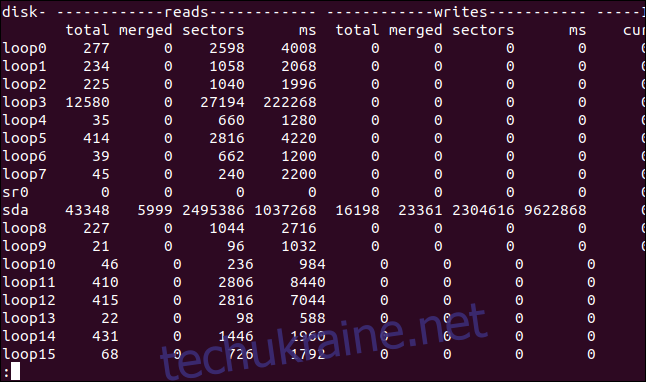
IO – це крайній правий стовпець. Зверніть увагу, що одиниці вимірювання часу в стовпці IO – секунди, а в стовпцях читання та запису – мілісекунди.
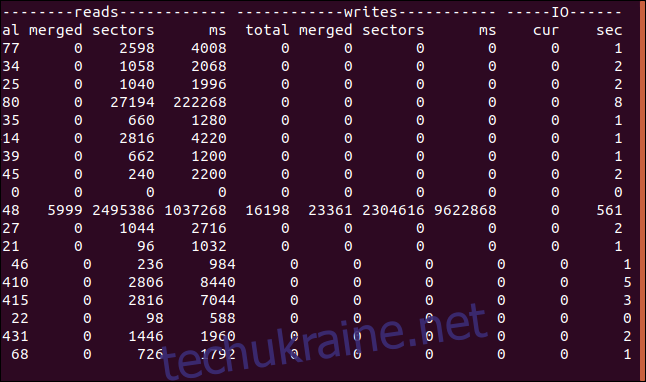
Ось що означають ці стовпці:
Читає (Reads)
total: Загальна кількість операцій читання з диска.
merged: Загальна кількість згрупованих читань.
sectors: Загальна кількість секторів, прочитаних з диска.
ms: Загальний час у мілісекундах, витрачений на читання даних з диска.
Записує (Writes)
total: Загальна кількість операцій запису на диск.
merged: Загальна кількість згрупованих операцій запису.
sectors: Загальна кількість секторів, записаних на диск.
ms: Загальний час у мілісекундах, витрачений на запис даних на диск.
IO
cur: Кількість поточних операцій читання або запису на диск.
sec: Час у секундах, витрачений на виконання будь-яких операцій читання або запису.
Відображення зведеної статистики диска
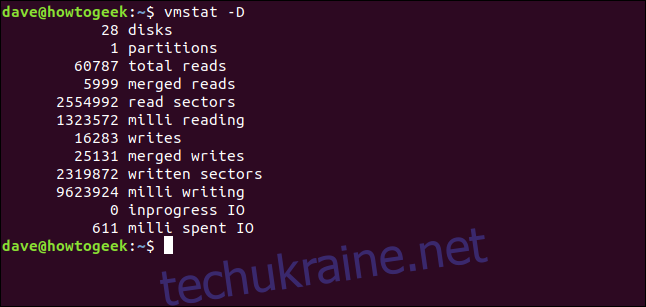
Щоб побачити швидке відображення зведеної статистики активності диска, використовуйте параметр -D (сума диска). Зверніть увагу на велику літеру “D”.
vmstat -D

Кількість дисків може виглядати надто великою. Комп’ютер, що використовується для цього дослідження, працює під Ubuntu. В Ubuntu, при встановленні програми з Snap, створюється псевдо-файлова система squashfs, яка приєднується до пристрою /dev/loop.
На жаль, ці пристрої розглядаються як жорсткі диски багатьма командами та утилітами Linux.
Відображення статистики розділу
Щоб переглянути статистику конкретного розділу, використовуйте параметр -p (розділ) і вкажіть ідентифікатор розділу як аргумент командного рядка.
Тут ми розглянемо розділ sda1. Цифра 1 вказує, що це перший розділ на пристрої sda, що є основним жорстким диском на цьому комп’ютері.
vmstat -p sda1

Відображена інформація показує загальну кількість операцій читання та запису на диск і з цього розділу, а також кількість секторів, задіяних в операціях читання та запису.

Зазирнути під капот
Завжди корисно знати, як “зазирнути під капот” і подивитися, що відбувається всередині. Іноді це необхідно для вирішення проблеми, а іноді просто цікаво, як працює ваш комп’ютер.
vmstat надає багато корисної інформації. Тепер ви знаєте, як отримати до неї доступ і що вона означає. Знання – сила, тому коли вам знадобиться провести діагностику, ви знатимете, що vmstat у вас під рукою.