
Контроль і керування даними може бути важким завданням. Ці команди AWS S3 допоможуть вам швидко й ефективно керувати сегментами й даними AWS S3.
AWS S3 це служба зберігання об’єктів, яку надає AWS. Це найпоширеніша служба зберігання від AWS, яка може фактично зберігати нескінченну кількість даних. Він високодоступний, надійний і його легко інтегрувати з кількома іншими службами AWS.
AWS S3 можуть використовувати люди з будь-якими вимогами, як-от зберігання мобільних/веб-додатків, зберігання великих даних, зберігання даних машинного навчання, розміщення статичних веб-сайтів тощо.
Якщо ви використовували S3 у своєму проекті, ви б знали, що з огляду на величезну ємність зберігання, керування сотнями сегментів і терабайтів даних у цих сегментах може бути складною роботою. У нас є список команд AWS S3 із прикладами, які можна використовувати для ефективного керування сегментами й даними AWS S3.
Налаштування AWS CLI
Після того, як ви успішно завантажили та встановили AWS CLI, вам потрібно налаштувати облікові дані AWS, щоб отримати доступ до свого облікового запису та послуг AWS. Давайте швидко розглянемо, як налаштувати AWS CLI.
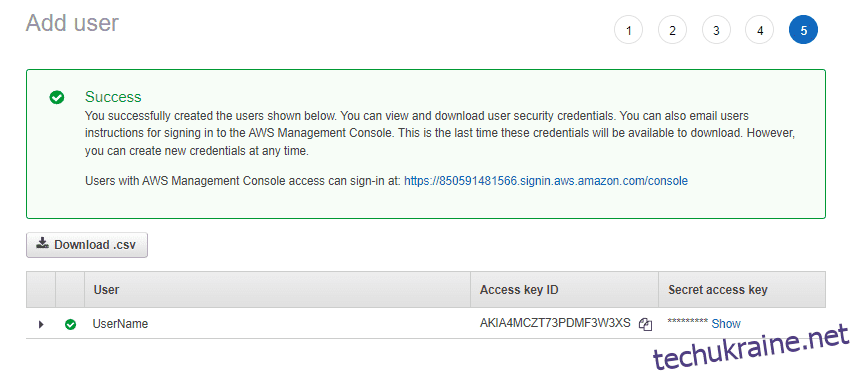
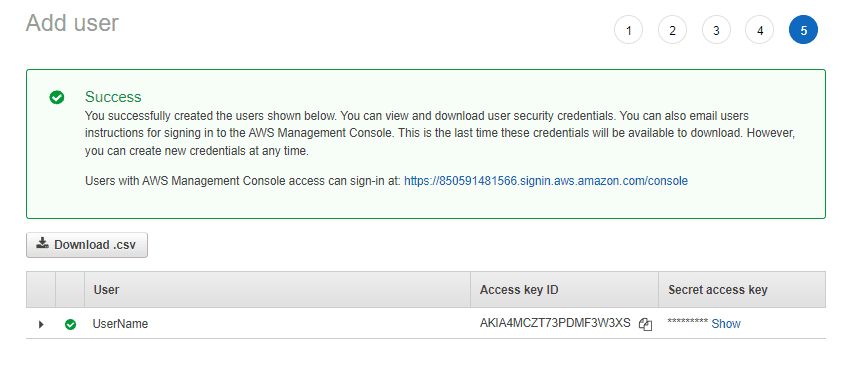
Першим кроком є створення користувача з програмним доступом до облікового запису AWS. Не забудьте поставити цей прапорець під час створення користувача для AWS CLI.
Надайте дозволи та створіть користувача. На останньому екрані після успішного створення цього користувача скопіюйте ідентифікатор ключа доступу та секретний ключ доступу для цього користувача. Ми використовуватимемо ці облікові дані для входу через AWS CLI.
Тепер перейдіть до обраного вами терміналу та виконайте наступну команду.
aws configure
Коли буде запропоновано, введіть ідентифікатор ключа доступу та секретний ключ доступу. Виберіть будь-який регіон AWS на ваш вибір і формат виведення команди. Я особисто віддаю перевагу формату JSON. Це нічого страшного, ви завжди можете змінити ці значення пізніше.

Тепер ви можете запускати будь-яку команду AWS CLI на консолі. Тепер розглянемо команди AWS S3.
cp
Команда cp просто копіює дані до та з сегментів S3. Його можна використовувати для копіювання файлів з локального на S3, з S3 на локальний і між двома сегментами S3. Є багато інших параметрів, які ви можете надати за допомогою команд.
Наприклад, параметр -dryrun для перевірки команди, параметр –storage-class для визначення класу зберігання ваших даних у S3, інші параметри для встановлення шифрування та багато іншого. The cp команда дає вам повний контроль над тим, як ви налаштовуєте захист даних у S3.
Використання
aws s3 cp <SOURCE> <DESTINATION> [--options]
Приклади
Скопіюйте дані з локального на S3
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt
Скопіюйте дані з S3 на локальний
aws s3 cp s3://bucket_name/file_name_2.txt file_name.txt
Копіювати дані між сегментами S3
aws s3 cp s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
Копіювати дані з локального на S3 – IA
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
Скопіюйте всі дані з локальної папки в S3
aws s3 cp ./local_folder s3://bucket_name --recursive
ls
The Команда ls використовується для переліку відер або вмісту відер. Отже, якщо ви просто хочете переглянути інформацію про свої сегменти або дані в цих сегментах, ви можете скористатися командою ls.
Використання:
aws s3 ls NONE or <BUCKET_NAME> [--options]
Приклади
Перелічіть усі сегменти в обліковому записі
aws s3 ls Output: 2022-02-02 18:20:14 BUCKET_NAME_1 2022-03-20 13:12:43 BUCKET_NAME_2 2022-03-29 10:52:33 BUCKET_NAME_3
Ця команда містить список усіх сегментів у вашому обліковому записі з датою створення сегмента.
Перерахувати всі об’єкти верхнього рівня у відрі
aws s3 ls BUCKET_NAME_1 or s3://BUCKET_NAME_1
Output:
PRE samplePrefix/
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 file_2.json
2021-12-09 12:23:21 3088 file_3.html
Ця команда перераховує всі об’єкти верхнього рівня в сегменті S3. Зауважте, що об’єкти з префіксом samplePrefix/ тут не показані, лише об’єкти верхнього рівня.
Перелічіть усі об’єкти у відрі
aws s3 ls BUCKET_NAME_1 or s3://BUCKET_NAME_1 --recursive Output: 2021-12-09 12:23:20 8754 file_1.png 2021-12-09 12:23:21 1290 file_2.json 2021-12-09 12:23:21 3088 file_3.html 2021-12-09 12:23:20 16328 samplePrefix/file_1.txt 2021-12-09 12:23:20 29325 samplePrefix/sampleSubPrefix/file_1.css
Ця команда перераховує всі об’єкти у сегменті S3. Зауважте, що об’єкти з префіксом samplePrefix/ та всі підпрефікси також відображаються.
мб
The команда mb просто використовується для створення нових сегментів S3. Це досить проста команда, але для створення нових сегментів ім’я нового блоку має бути унікальним для всіх сегментів S3.
Використання
aws s3 mb <BUCKET_NAME>
приклад
Створіть нове відро в певному регіоні
aws s3 mb myUniqueBucketName --region eu-west-1
мв
The команда mv просто переміщує дані до та з сегментів S3. Подібно до команди cp, команда mv використовується для переміщення даних з локального на S3, S3 на локальний або між двома сегментами S3.
Єдина відмінність між командою mv і cp полягає в тому, що під час використання команди mv файл видаляється з джерела. AWS переміщує цей файл до місця призначення. Є багато параметрів, які ви можете вказати за допомогою команди.
Використання
aws s3 mv <SOURCE> <DESTINATION> [--options]
Приклади
Перемістіть дані з локального на S3
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt
Перемістіть дані з S3 на локальний
aws s3 mv s3://bucket_name/file_name_2.txt file_name.txt
Переміщення даних між сегментами S3
aws s3 mv s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
Перемістити дані з локального на S3 – IA
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
Перемістіть усі дані з префікса в S3 до локальної папки.
aws s3 mv s3://bucket_name/somePrefix ./localFolder --recursive
передписати
Команда presign генерує попередньо підписану URL-адресу для ключа в сегменті S3. Ви можете використовувати цю команду для створення URL-адрес, які можуть використовувати інші для доступу до файлу в указаному ключі сегмента S3.
Використання
aws s3 presign
приклад
Створіть попередньо підписану URL-адресу, дійсну протягом 1 години для об’єкта в сегменті.
aws s3 presign s3://bucket_name/samplePrefix/file_name.png --expires-in 3600 Output: https://s3.ap-south-1.amazonaws.com/bucket_name/samplePrefix/file_name.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4MCZT73PAX7ZMVFW%2F20220314%2Fap-south-1%2Fs3%2Faws4_request&X-Amz-Date=20220314T054113Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=f14608bbf3e1f9f8d215eb5b439b87e167b1055bcd7a45c13a33debd3db1be96
рб
Команда rb просто використовується для видалення сегментів S3.
Використання
aws rb <BUCKET_NAME>
приклад
Видалити сегмент S3.
aws s3 mb myBucketName # This command fails if there is any data in this bucket.
Видаліть сегмент S3 разом із даними в сегменті S3.
aws s3 mb myBucketName --force
пд
Команда rm просто використовується для видалення об’єктів у сегментах S3.
Використання
aws s3 rm <S3Uri_To_The_File>
Приклади
Видалити один файл із відра S3.
aws s3 rm s3://bucket_name/sample_prefix/file_name_2.txt
Видалити всі файли з певним префіксом у сегменті S3.
aws s3 rm s3://bucket_name/sample_prefix --recursive
Видаліть усі файли у відрі S3.
aws s3 rm s3://bucket_name --recursive
синхронізація
Команда sync копіює та оновлює файли з джерела до місця призначення так само, як команда cp. Важливо розуміти різницю між cp і командою sync. Коли ви використовуєте cp, він копіює дані з джерела до місця призначення, навіть якщо дані вже існують у місці призначення.
Він також не видаляє файли з місця призначення, якщо їх видалено з джерела. Однак синхронізація переглядає місце призначення перед копіюванням даних і копіює лише нові та оновлені файли. The команда синхронізації схоже на фіксацію та надсилання змін до віддаленої гілки в git. Команда синхронізації пропонує багато параметрів для налаштування команди.
Використання
aws s3 sync <SOURCE> <DESTINATION> [--options]
Приклади
Синхронізувати локальну папку з S3
aws s3 sync ./local_folder s3://bucket_name
Синхронізація даних S3 з локальною папкою
aws s3 sync s3://bucket_name ./local_folder
Синхронізація даних між двома сегментами S3
aws s3 sync s3://bucket_name s3://bucket_name_2
Переміщення даних між двома сегментами S3, за винятком усіх файлів .txt
aws s3 sync s3://bucket_name s3://bucket_name_2 --exclude "*.txt
веб-сайт
Ви можете використовувати сегменти S3 для розміщення статичних веб-сайтів. Команда website використовується для налаштування хостингу статичного веб-сайту S3 для вашого сегмента.
Ви вказуєте індекс і файли помилок, а S3 надає URL-адресу, за якою ви можете переглянути файл.
Використання
aws s3 website <S3_URI> [--options]
приклад:
Налаштуйте статичний хостинг для сегмента S3 і вкажіть файли індексу та файли помилок
aws s3 website s3://bucket_name --index-document index.html --error-document error.html
Висновок
Сподіваюся, наведене вище дасть вам уявлення про деякі з часто використовуваних команд AWS S3 для керування сегментами. Якщо вам цікаво дізнатися більше, ви можете переглянути деталі сертифікації AWS.