Аналітика великих даних і Hadoop: Підготовка до співбесіди
За даними Forbes, майже 90% компаній по всьому світу використовують аналітику великих даних для підготовки інвестиційних звітів.
Зі зростанням популярності технологій Big Data, збільшується і попит на фахівців у сфері Hadoop.
Щоб допомогти вам стати експертом у Hadoop, ми підготували цю статтю з питаннями та відповідями на співбесіді.
Можливо, інформація про рівень зарплат у цій галузі, мотивує вас краще підготуватися до співбесіди? 🤔
- За даними indeed.com, середній річний дохід розробника Big Data Hadoop у США становить 144 000 доларів.
- За даними itjobswatch.co.uk, середній річний дохід розробника Big Data Hadoop у Великій Британії складає £66 750.
- Згідно з indeed.com, в Індії фахівці цієї сфери заробляють в середньому ₹16 00 000 на рік.
Досить привабливо, чи не так? Тож давайте перейдемо до вивчення Hadoop.
Що таке Hadoop?
Hadoop – це розповсюджена платформа, розроблена на Java, яка застосовує моделі програмування для опрацювання, зберігання та аналізу великих масивів даних.
Завдяки своїй архітектурі, Hadoop здатний масштабуватися від одного сервера до багатьох комп’ютерів, забезпечуючи локальні обчислення та зберігання. Крім того, він може виявляти та обробляти збої на рівні додатків, що робить його дуже надійним.
Перейдемо до типових питань на співбесіді та відповідей на них.
Запитання та відповіді на співбесіді з Hadoop
Яка одиниця зберігання в Hadoop?
Відповідь: Одиниця зберігання даних у Hadoop називається HDFS (Hadoop Distributed File System).
Чим відрізняється мережеве сховище від розподіленої файлової системи Hadoop?
Відповідь: HDFS – це розподілена файлова система, що зберігає великі файли на звичайному обладнанні. NAS (Network Attached Storage), зі свого боку, це файловий сервер для зберігання даних, що забезпечує доступ до них різним клієнтам.
У NAS дані зберігаються на спеціальному обладнанні, тоді як HDFS розподіляє блоки даних між усіма машинами в кластері Hadoop.
Використання спеціалізованого обладнання в NAS є дорогим, а HDFS використовує звичайне обладнання, що є економічно вигіднішим.
NAS зберігає дані та обчислення окремо, що робить його неідеальним для MapReduce. Натомість HDFS дозволяє працювати з фреймворком MapReduce, де обчислення виконуються там, де знаходяться дані.
Поясніть MapReduce в Hadoop і Shuffling
Відповідь: MapReduce – це два етапи обробки даних в Hadoop, що забезпечують масштабованість на великих кластерах. Shuffling – це процес передачі вихідних даних з Mapper до Reducer у MapReduce.
Огляд архітектури Apache Pig
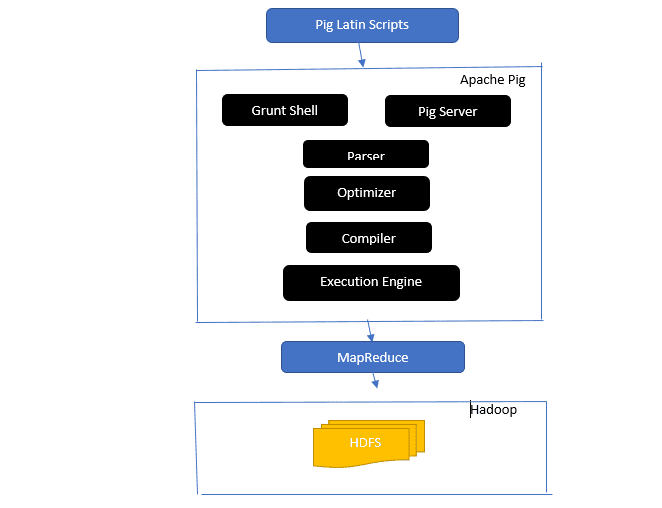
Відповідь: Архітектура Apache Pig включає інтерпретатор Pig Latin, що обробляє великі масиви даних за допомогою сценаріїв Pig Latin.
Apache Pig працює з наборами даних, над якими виконуються такі операції як об’єднання, завантаження, фільтрування, сортування та групування.
Pig Latin використовує механізми виконання, такі як оболонки Grant, UDF та вбудовані функції для написання сценаріїв, які виконують необхідні завдання.
Pig спрощує роботу програмістів, перетворюючи сценарії в послідовність завдань MapReduce.
Компоненти архітектури Apache Pig:
- Парсер – обробляє сценарії Pig, перевіряє синтаксис і типи даних. Вихід парсера – це DAG (спрямований ациклічний граф), що представляє операції.
- Оптимізатор – застосовує логічні оптимізації, такі як проекція, до DAG.
- Компілятор – перетворює оптимізований логічний план у серію завдань MapReduce.
- Механізм виконання – виконує завдання MapReduce для отримання результату.
- Режим виконання – Apache Pig може працювати в локальному режимі або в режимі MapReduce.
Відповідь: Служба Metastore в Local Metastore працює в тому ж JVM, що й Hive, але підключається до бази даних, яка працює в іншому процесі. Metastore в Remote Metastore працює в окремому JVM.
Які п’ять V великих даних?
Відповідь: П’ять V – це основні характеристики великих даних:
- Цінність (Value): Великі дані мають забезпечувати значну вигоду для організації, підвищуючи рентабельність інвестицій (ROI).
- Різноманітність (Variety): Означає різноманітність форматів зібраних даних (CSV, відео, аудіо тощо).
- Обсяг (Volume): Це значний обсяг і розмір даних, які обробляються.
- Швидкість (Velocity): Це швидкість, з якою дані створюються.
- Правдивість (Veracity): Означає, наскільки дані є точними та надійними.
Поясніть типи даних Pig Latin
Відповідь: Типи даних Pig Latin: атомарні та складні.
Атомарні типи:
- Int – 32-розрядне ціле число зі знаком (приклад: 13).
- Long – 64-розрядне ціле число (приклад: 10L).
- Float – 32-розрядне число з плаваючою точкою (приклад: 2.5F).
- Double – 64-розрядне число з плаваючою точкою (приклад: 23.4).
- Boolean – логічне значення (True/False).
- DateTime – значення дати та часу (приклад: 1980-01-01T00:00.00.000+00:00).
Складні типи даних:
- Map – набір пар ключ-значення (приклад: [‘color’#’yellow’, ‘number’#3]).
- Bag – колекція кортежів (приклад: {(Генрі, 32), (Кіті, 47)}).
- Tuple – впорядкований набір полів (приклад: (Вік, 33)).
Що таке Apache Oozie та Apache ZooKeeper?
Відповідь: Apache Oozie – це планувальник завдань Hadoop, який відповідає за їх об’єднання в логічну роботу.
Apache ZooKeeper координує роботу різних служб у розподіленому середовищі, надаючи прості сервіси, такі як синхронізація, групування, обслуговування конфігурації та іменування.
Яка роль Combiner, RecordReader та Partitioner в операції MapReduce?
Відповідь: Combiner діє як міні-Reducer, отримує дані від Mapper та передає їх до Reducer.
RecordReader перетворює дані з InputSplit у пари ключ-значення для читання Mapper.
Partitioner визначає кількість скорочених завдань для підсумовування даних і направляє вихідні дані Combiner до Reducer.
Назвіть дистрибутиви Hadoop від різних постачальників.
Відповідь: Ось деякі з постачальників, що пропонують Hadoop:
- IBM Open Platform.
- Cloudera CDH Hadoop Distribution.
- MapR Hadoop Distribution.
- Amazon Elastic MapReduce.
- Hortonworks Data Platform (HDP).
- Key Big Data Bundle.
- Datastax Enterprise Analytics.
- HDInsight від Microsoft Azure.
Чому HDFS є відмовостійким?
Відповідь: HDFS реплікує дані на різних DataNode, що забезпечує відмовостійкість. У разі збою одного вузла, дані можна отримати з іншого.
Розрізняйте федерацію та високу доступність.
Відповідь: Федерація HDFS забезпечує безперервний потік даних, коли один вузол виходить з ладу. Висока доступність передбачає два окремих NameNode – активний та резервний.
Федерація може мати багато незалежних NameNode, тоді як висока доступність використовує два пов’язаних вузла: активний і резервний.
NameNode у федерації використовують спільний пул метаданих. У режимі високої доступності, активний NameNode працює, а резервний – оновлює свої метадані.
Як перевірити стан блоків і справність файлової системи?
Відповідь: Для цього використовується команда `hdfs fsck /` як від root, так і з окремого каталогу.
Команда:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Опис:
- `-files`: виводить файли, що перевіряються.
- `–locations`: виводить розташування всіх блоків під час перевірки.
Команда для перевірки стану блоків:
hdfs fsck <path> -files -blocks
- `<path>`: шлях, з якого починається перевірка.
- `–blocks`: виводить блоки файлів під час перевірки.
Коли використовуються команди rmadmin-refreshNodes і dfsadmin-refreshNodes?
Відповідь: Ці команди використовуються для оновлення інформації про вузол під час введення в експлуатацію або після завершення введення в експлуатацію.
Команда `dfsadmin-refreshNodes` оновлює конфігурацію NameNode. Команда `rmadmin-refreshNodes` виконує адміністративні завдання ResourceManager.
Що таке контрольна точка?
Відповідь: Контрольна точка – це операція, що об’єднує останні зміни файлової системи з останнім FSImage, щоб файли журналу редагування були меншими. Контрольна точка створюється у Secondary NameNode.
Чому HDFS використовується для програм з великими наборами даних?
Відповідь: HDFS забезпечує архітектуру DataNode і NameNode, що реалізує розподілену файлову систему.
NameNode зберігає метадані в пам’яті, що обмежує кількість файлів, що можуть бути в HDFS.
Що робить команда ‘jps’?
Відповідь: Команда Java Virtual Machine Process Status (JPS) перевіряє, чи запущені демони Hadoop, такі як NodeManager, DataNode, NameNode та ResourceManager.
Що таке спекулятивне виконання в Hadoop?
Відповідь: Це процес, де Hadoop запускає резервну копію завдання на іншому вузлі, якщо виявляється, що оригінальне завдання виконується занадто повільно. Це економить час, особливо при великих навантаженнях.
Назвіть три режими роботи Hadoop.
Відповідь: Hadoop може працювати в трьох режимах:
- Автономний вузол – режим за замовчуванням, де Hadoop використовує локальну файлову систему та один процес Java.
- Псевдорозподілений вузол – всі служби Hadoop виконуються в одному розгортанні.
- Повністю розподілений вузол – головні та підлеглі служби Hadoop запускаються на різних вузлах.
Що таке UDF?
Відповідь: UDF (User-Defined Functions) дозволяє створювати власні функції для обробки даних під час запиту Impala.
Що таке DistCp?
Відповідь: DistCp (Distributed Copy) – це інструмент для копіювання великих обсягів даних між кластерами, використовуючи MapReduce.
Що таке метасховище Hive?
Відповідь: Метасховище Hive зберігає метадані таблиць Hive у реляційній базі даних, наприклад MySQL.
Визначте RDD.
Відповідь: RDD (Resilient Distributed Datasets) – це структура даних Spark, незмінна розподілена колекція елементів, що виконує обчислення на різних вузлах кластера.
Як включити нативні бібліотеки до завдань YARN?
Відповідь: Це можна зробити за допомогою `-Djava.library.path` або через встановлення `LD_LIBRARY_PATH` у файлі `.bashrc`:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Поясніть WAL в HBase.
Відповідь: Write Ahead Log (WAL) – це протокол відновлення, який записує зміни даних MemStore в HBase у файлове сховище. WAL відновлює ці дані у разі збою RegionalServer.
Чи є YARN заміною Hadoop MapReduce?
Відповідь: Ні, YARN не є заміною Hadoop MapReduce, а є платформою, що підтримує MapReduce.
Яка різниця між ORDER BY та SORT BY у Hive?
Відповідь: `SORT BY` може дати частково впорядковані результати, використовуючи декілька Reducer. `ORDER BY` використовує один Reducer для повного впорядкування, але може використовувати `LIMIT` для швидкодії.
Яка різниця між Spark і Hadoop?
Відповідь: Hadoop підходить для пакетної обробки, а Spark – для обробки даних в режимі реального часу. Hadoop читає і записує дані на HDFS, а Spark працює з даними в оперативній пам’яті за допомогою RDD.
Hadoop має високу затримку і не має інтерактивного режиму, тоді як Spark має низьку затримку та підтримує інтерактивну обробку.
Порівняйте Sqoop і Flume.
Відповідь: Sqoop і Flume – інструменти для збору даних та завантаження їх у HDFS.
- Sqoop (SQL-to-Hadoop) витягує структуровані дані з баз даних (Teradata, MySQL, Oracle), а Flume – неструктуровані.
- Flume керується подіями, а Sqoop – ні.
- Sqoop використовує конектори, а Flume – агентну архітектуру.
- Flume може збирати та агрегувати дані, Sqoop – паралельно передавати дані.
Поясніть BloomMapFile.
Відповідь: BloomMapFile – це клас, що розширює MapFile, що використовує фільтри Блума для швидкої перевірки ключів.
Перелічіть різницю між HiveQL та PigLatin.
Відповідь: HiveQL – декларативна мова, схожа на SQL, а PigLatin – процедурна мова потоку даних.
Що таке очищення даних?
Відповідь: Очищення даних – це процес виправлення або видалення помилок (неправильних, неповних, пошкоджених, дублікатів) у наборі даних. Це необхідно для покращення якості даних і прийняття обґрунтованих рішень.
Висновок💃
У зв’язку зі зростаючим попитом на фахівців з Big Data і Hadoop, ця стаття з питаннями та відповідями допоможе вам успішно пройти співбесіду.
Рекомендуємо вивчити додаткові ресурси з великих даних та Hadoop.
Успіхів! 👍