Синтетичні дані: Ключ до машинного навчання та конфіденційності
Сьогодні дані відіграють критичну роль у розробці моделей машинного навчання, тестуванні програмних продуктів та отриманні цінних бізнес-інсайтів.
Проте, через суворі норми конфіденційності, доступ до реальних даних часто обмежений, що ускладнює їх використання. Отримання необхідних дозволів може зайняти тривалий час. Альтернативою можуть слугувати синтетичні дані.
Що таке синтетичні дані?

Синтетичні дані – це штучно згенерована інформація, яка статистично відтворює характеристики наявних наборів даних. Їх можна використовувати як доповнення до реальних даних для навчання та покращення моделей штучного інтелекту, або як їх повну заміну.
Оскільки синтетичні дані не пов’язані з конкретними особами та не містять персональної інформації (наприклад, ідентифікаційних номерів чи інших конфіденційних відомостей), їх використання є безпечним з точки зору конфіденційності. Це робить їх чудовою альтернативою для роботи з чутливою інформацією.
Різниця між реальними та синтетичними даними
- Джерело походження: Реальні дані отримують безпосередньо від користувачів через опитування або використання програм. Синтетичні ж дані генеруються штучно, але зберігають статистичні властивості оригінальних наборів.
- Правила захисту: Реальні дані підпадають під дію законів про захист персональних даних, вимагаючи згоди користувачів та обмеження їх використання. Синтетичні дані, не будучи пов’язаними з конкретними особами, звільняються від цих обмежень.
- Обсяг даних: Кількість реальних даних залежить від активності користувачів. Синтетичні дані можна генерувати у будь-якому потрібному обсязі, забезпечуючи достатню кількість для навчання моделей.
Переваги використання синтетичних даних
- Економічна ефективність: Створення синтетичних даних обходиться дешевше, особливо при генерації великих наборів, що позитивно впливає на навчання моделей машинного навчання.
- Готовність до використання: Синтетичні дані автоматично маркуються та очищаються, що економить час і ресурси на підготовку до машинного навчання чи аналізу.
- Конфіденційність: Відсутність персональних даних робить синтетичні дані безпечними для вільного використання та поширення.
- Подолання упереджень ШІ: Збалансоване представлення різних класів у синтетичних даних сприяє створенню чесного та відповідального штучного інтелекту.
Процес генерації синтетичних даних
Процес генерації залежить від обраного інструменту, але зазвичай починається з підключення до наявного набору даних. Далі, визначаються поля з персональною інформацією, які виключаються або маскуються.
Генератор ідентифікує типи даних та статистичні закономірності в решті стовпців, створюючи на їх основі синтетичні дані. Можна порівняти згенеровані дані з вихідними, щоб оцінити їх схожість.
Далі розглянемо інструменти для створення синтетичних даних, які можна використовувати для навчання моделей машинного навчання.
Mostly AI
Mostly AI використовує штучний інтелект для аналізу статистичних закономірностей у вихідних даних, а потім генерує синтетичні набори даних, що імітують ці закономірності. За допомогою цього інструменту можна створювати цілі бази даних, зберігаючи при цьому цілісність посилань.
Synthesized.io

Synthesized.io є популярним рішенням для великих компаній. Для використання необхідно задати вимоги до даних у файлі YAML. Після цього запускається завдання, як частина конвеєра даних. Платформа має безкоштовну версію для тестування можливостей.
YData

YData дозволяє генерувати різні типи даних: табличні, часові ряди, транзакційні, багатотабличні та реляційні. Сервіс пропонує AI та SDK для інтеграції з платформою. Також є безкоштовний тариф для демонстрації продукту.
Gretel AI

Gretel AI надає API для створення необмеженої кількості синтетичних даних. Має генератор даних з відкритим кодом, а також платні REST API та CLI. Цінова політика є гнучкою і залежить від розміру бізнесу.
Копули
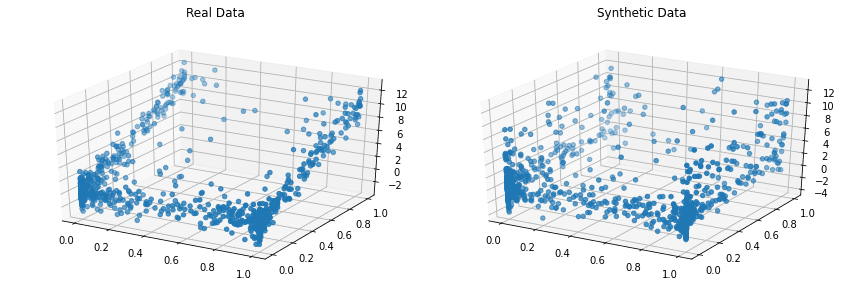
Copulas – це бібліотека Python з відкритим кодом, що використовується для моделювання багатовимірних розподілів та генерації синтетичних даних, які зберігають статистичні властивості оригіналу. Проєкт був запущений у 2018 році в MIT.
CTGAN
CTGAN — це генеративна мережа, яка використовується для навчання на основі однотабличних реальних даних та генерації синтетичних даних. Вона реалізована як бібліотека Python з відкритим кодом і є частиною проєкту Synthetic Data Vault.
DoppelGANger
DoppelGANger — це реалізація генеративних змагальних мереж для створення синтетичних даних, особливо корисних для часових рядів. Бібліотека Python є безкоштовною та з відкритим кодом.
Synth

Synth — це інструмент з відкритим кодом, що дозволяє створювати реалістичні дані, приховувати персональну інформацію та розробляти тестові дані. Підтримує генерацію часових рядів та реляційних даних, і не залежить від конкретних баз даних.
SDV.dev
SDV (Synthetic Data Vault) — це проєкт, що розпочався в MIT у 2016 році, і який розробив різні інструменти для генерації синтетичних даних. Ці інструменти включають Copulas, CTGAN, DeepEcho та RDT, які є бібліотеками Python з відкритим кодом.
Tofu
Tofu — це бібліотека Python з відкритим кодом для створення синтетичних даних на основі даних біобанку Великобританії. На відміну від інших інструментів, Tofu спеціалізується на створенні даних, схожих на дані цього конкретного дослідження.
Twinify
Twinify – програмний пакет для створення синтетичних даних з ідентичним статистичним розподілом до оригінальних даних. Працює як бібліотека або інструмент командного рядка.

Для використання Twinify потрібно надати реальні дані у форматі CSV. Інструмент є безкоштовним.
Datanamic
Datanamic допомагає створювати тестові дані для програм та машинного навчання, генеруючи дані на основі характеристик стовпців (електронна пошта, імена, номери телефонів). Підтримує більшість баз даних і забезпечує цілісність посилань у згенерованих даних.
Benerator
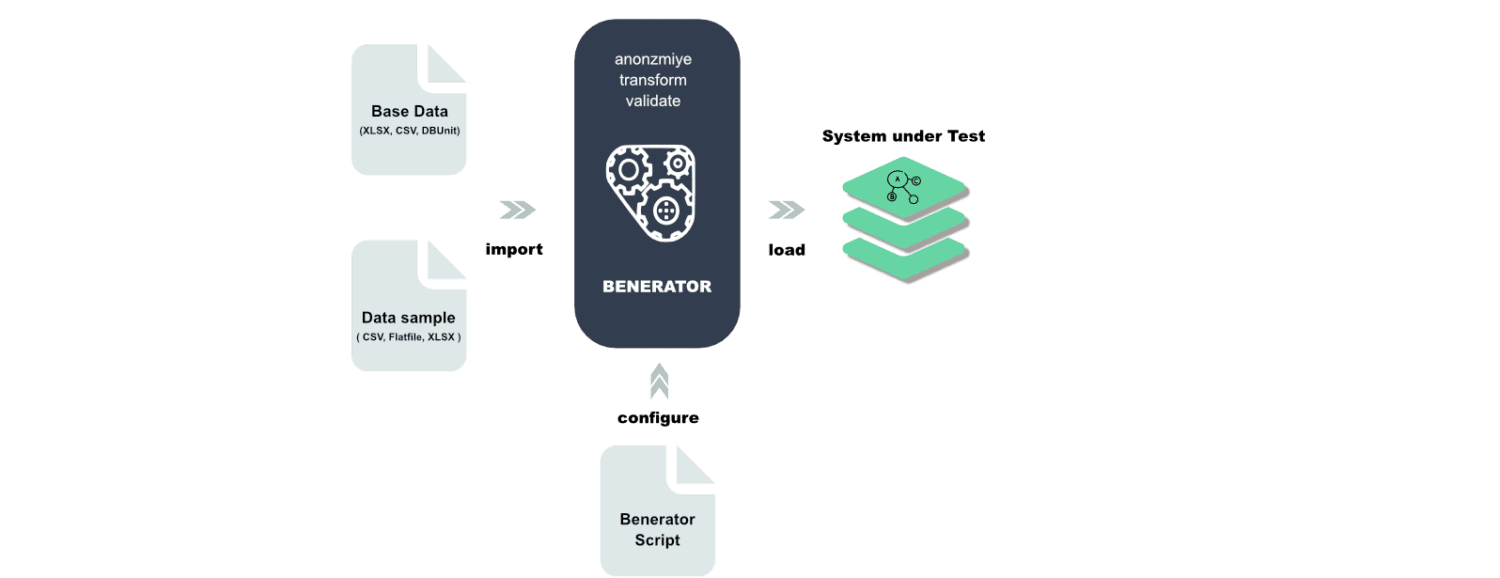
Benerator — це програмне забезпечення для обфускації, генерації та міграції даних. Дані описуються за допомогою XML, а генеруються за допомогою інструменту командного рядка. Він призначений для не розробників, є безкоштовним та має відкритий код.
Заключні слова
За прогнозами Gartner, до 2030 року для машинного навчання буде використовуватися більше синтетичних даних, ніж реальних. Це пов’язано з вартістю та проблемами конфіденційності використання реальних даних. Тому важливо, щоб компанії вивчали синтетичні дані та інструменти для їх створення.
Рекомендуємо також ознайомитись з інструментами синтетичного моніторингу для вашого онлайн-бізнесу.