
Оскільки компанії генерують все більше і більше даних, традиційний підхід до сховищ даних стає все складнішим і дорожчим для підтримки. Data Vault, відносно новий підхід до сховищ даних, пропонує вирішення цієї проблеми, надаючи масштабований, гнучкий і економічно ефективний спосіб керування великими обсягами даних.
У цьому дописі ми дослідимо, як Data Vaults — це майбутнє сховищ даних і чому все більше компаній використовують цей підхід. Ми також надамо навчальні ресурси для тих, хто хоче глибше зануритися в тему!
Що таке Data Vault?
Data Vault — це техніка моделювання сховищ даних, яка особливо підходить для гнучких сховищ даних. Він пропонує високий ступінь гнучкості для розширень, повну одиничну часову історизацію даних і дозволяє розпаралелювати процеси завантаження даних. Ден Лінстедт розробив моделювання Data Vault у 1990-х роках.
Після першої публікації в 2000 році вона привернула більшу увагу в 2002 році завдяки серії статей. У 2007 році Лінстедт отримав підтримку Білла Інмона, який назвав це «оптимальним вибором» для своєї архітектури Data Vault 2.0.
Кожен, хто має справу з терміном agile data warehouse, швидко закінчить Data Vault. Особливістю цієї технології є те, що вона зосереджена на потребах компаній, оскільки дає змогу гнучко, легко коригувати сховище даних.
Data Vault 2.0 розглядає весь процес розробки та архітектуру та складається з методу компонентів (реалізації), архітектури та моделі. Перевагою цього підходу є те, що під час розробки враховуються всі аспекти бізнес-аналітики з базовим сховищем даних.
Модель Data Vault пропонує сучасне рішення для подолання обмежень традиційних підходів до моделювання даних. Завдяки масштабованості, гнучкості та гнучкості він забезпечує міцну основу для побудови платформи даних, яка може вмістити складність і різноманітність сучасних середовищ даних.
Архітектура концентратора Data Vault і поділ сутностей і атрибутів забезпечують інтеграцію та гармонізацію даних у кількох системах і доменах, сприяючи поступовому та гнучкому розвитку.
Вирішальною роллю Data Vault у створенні платформи даних є встановлення єдиного джерела правдивості для всіх даних. Уніфіковане представлення даних і підтримка збору та відстеження історичних змін даних за допомогою супутникових таблиць забезпечують відповідність, аудит, нормативні вимоги, а також комплексний аналіз і звітність.
Можливості Data Vault інтеграції даних майже в режимі реального часу за допомогою дельта-завантаження полегшують обробку великих обсягів даних у швидкозмінних середовищах, таких як програми Big Data та IoT.
Data Vault проти традиційних моделей сховищ даних
Третя звичайна форма (3NF) є однією з найвідоміших традиційних моделей сховищ даних, якій часто надають перевагу в багатьох великих реалізаціях. До речі, це відповідає ідеям Білла Інмона, одного з «прабатьків» концепції сховищ даних.
Архітектура Inmon базується на моделі реляційної бази даних і усуває надмірність даних, розбиваючи джерела даних на менші таблиці, які зберігаються у вітринах даних і з’єднані між собою за допомогою первинних і зовнішніх ключів. Він забезпечує узгодженість і точність даних, дотримуючись правил посилальної цілісності.
Мета звичайної форми полягала в тому, щоб створити комплексну модель даних для всієї компанії для основного сховища даних; однак він має проблеми з масштабованістю та гнучкістю через сильно пов’язані вітрини даних, труднощі із завантаженням у режимі майже в реальному часі, трудомісткі запити та низхідний дизайн та впровадження.
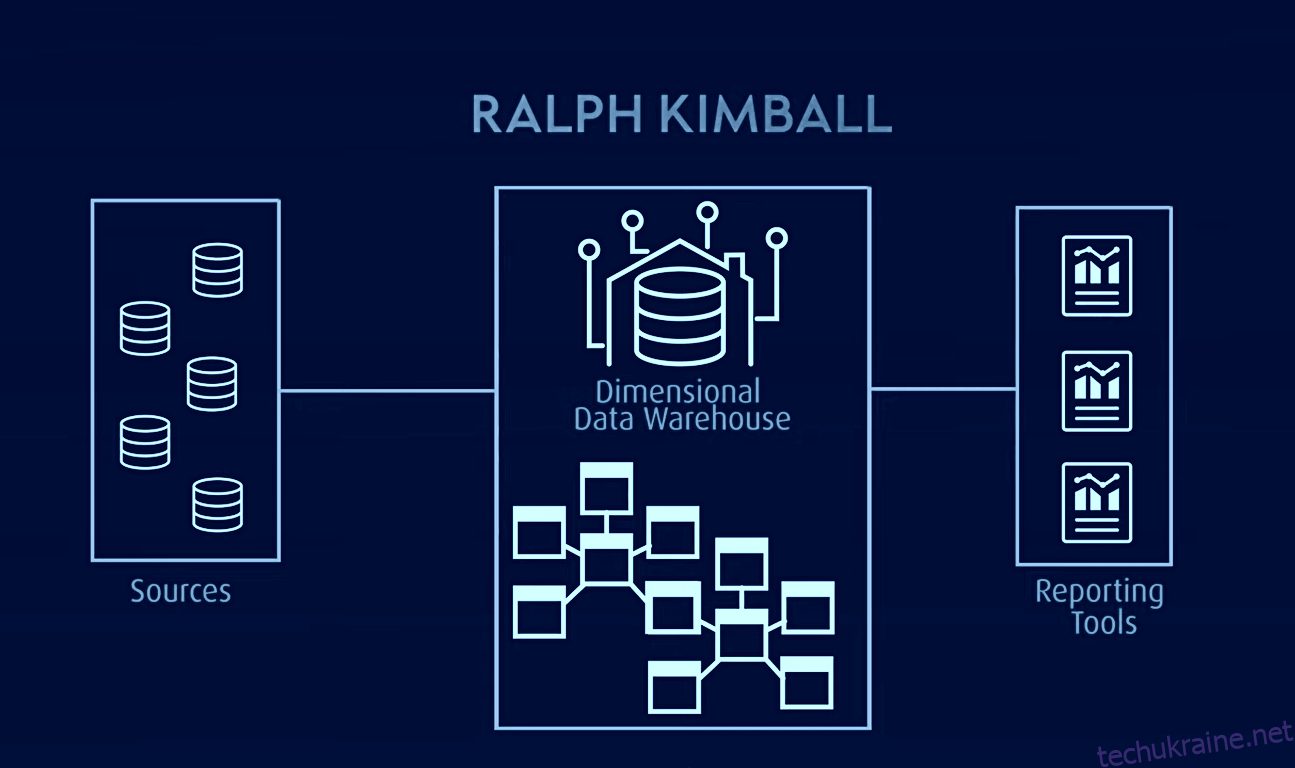
Модель Кімбала, яка використовується для OLAP (онлайн-аналітичної обробки) і вітрин даних, є ще однією відомою моделлю сховища даних, у якій таблиці фактів містять агреговані дані, а таблиці розмірів описують збережені дані в схемі зірки або схеми сніжинки. У цій архітектурі дані організовані в таблиці фактів і розмірів, які денормализовані для спрощення запитів і аналізу.
Kimbal базується на розмірній моделі, яка оптимізована для запитів і звітів, що робить його ідеальним для програм бізнес-аналітики. Однак у нього виникли проблеми з ізоляцією предметно-орієнтованої інформації, надлишковістю даних, несумісними структурами запитів, труднощами масштабованості, непослідовною деталізацією таблиць фактів, проблемами синхронізації та необхідністю проектування зверху вниз із реалізацією знизу вгору.
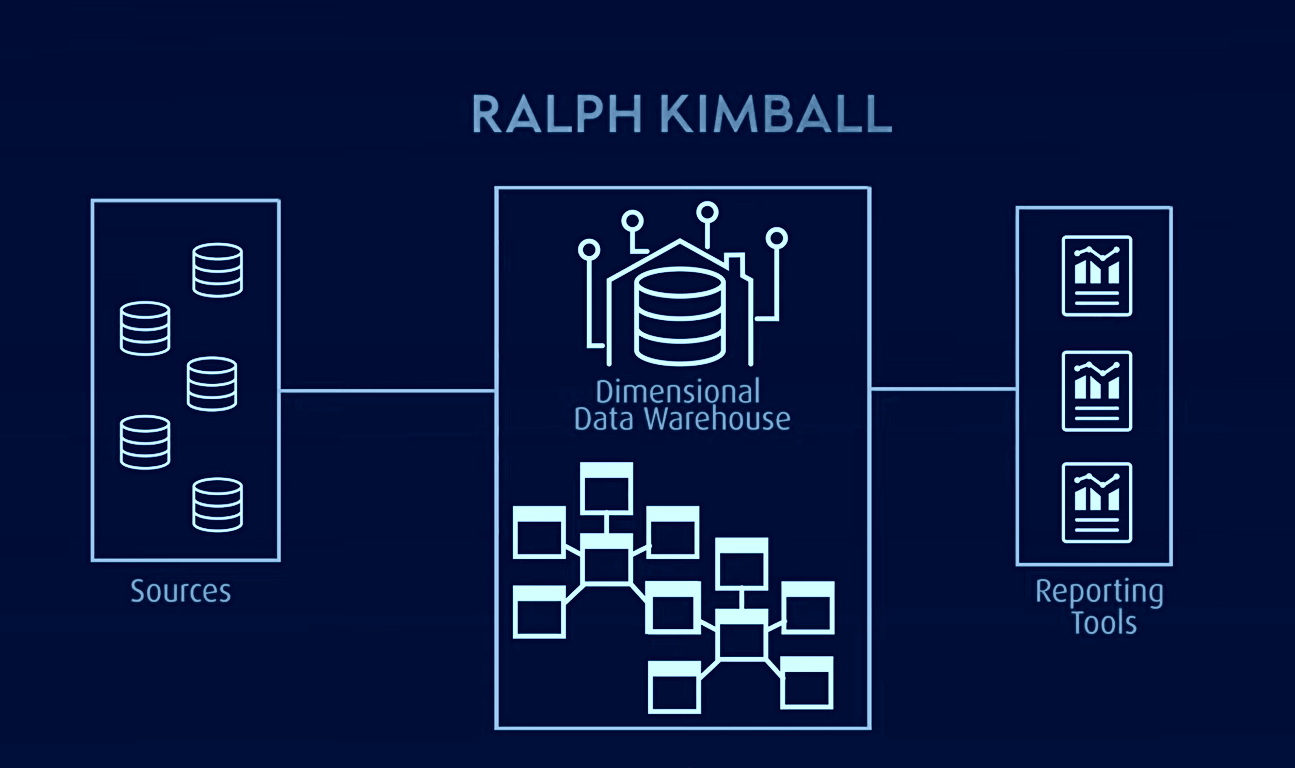
Навпаки, архітектура сховища даних є гібридним підходом, який поєднує в собі аспекти архітектур 3NF і Kimball. Це модель, заснована на реляційних принципах, нормалізації даних і математиці надлишковості, яка по-іншому представляє зв’язки між об’єктами та по-іншому структурує поля таблиці та позначки часу.
У цій архітектурі всі дані зберігаються в сховищі необроблених даних або озері даних, тоді як дані, які зазвичай використовуються, зберігаються в нормалізованому форматі в бізнес-сховищі, яке містить історичні та контекстно-залежні дані, які можна використовувати для звітності.
Data Vault вирішує проблеми традиційних моделей, будучи більш ефективним, масштабованим і гнучким. Це забезпечує завантаження майже в реальному часі, кращу цілісність даних і легке розширення без впливу на існуючі структури. Модель також можна розширити без перенесення існуючих таблиць.
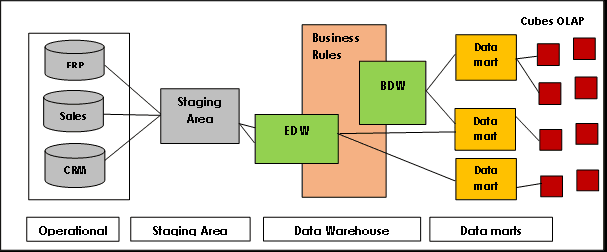
Підхід до моделюванняСтруктура данихПідхід до проектування3NF Таблиці моделювання в 3NFBottom-upKimbal Modeling Схема зірки або СніжинкаЗверху-вниз Data VaultHub-and-SpokeBottom-up
Архітектура сховища даних
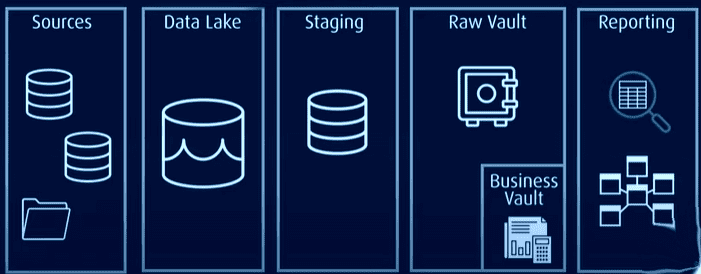
Data Vault має архітектуру hub and spoke і по суті складається з трьох рівнів:
Проміжний рівень: збирає необроблені дані з вихідних систем, таких як CRM або ERP
Рівень сховища даних: у моделі сховища даних цей рівень включає:
- Raw Data Vault: зберігає необроблені дані.
- Business Data Vault: містить узгоджені та трансформовані дані на основі бізнес-правил (необов’язково).
- Metrics Vault: зберігає інформацію про час виконання (необов’язково).
- Operational Vault: зберігає дані, які надходять безпосередньо з операційних систем у сховище даних (необов’язково).
Рівень Data Mart: цей рівень моделює дані як зіркову схему та/або інші методи моделювання. Він надає інформацію для аналізу та звітності.
 Джерело зображення: Lamia Yessad
Джерело зображення: Lamia Yessad
Data Vault не потребує зміни архітектури. Нові функції можна створювати паралельно безпосередньо за допомогою концепцій і методів Data Vault, і наявні компоненти не втрачаються. Фреймворки можуть істотно полегшити роботу: вони створюють прошарок між сховищем даних і розробником і таким чином зменшують складність реалізації.
Компоненти Data Vault
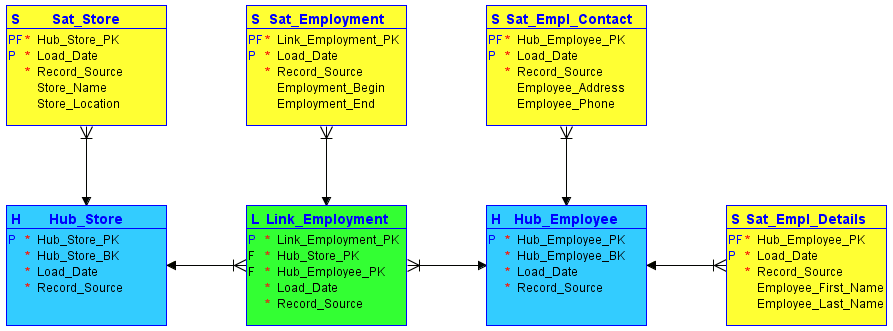
Під час моделювання Data Vault ділить всю інформацію, що належить об’єкту, на три категорії – на відміну від класичного моделювання третьої нормальної форми. Потім ця інформація зберігається строго окремо одна від одної. Функціональні області можна відобразити в Data Vault у так званих хабах, посиланнях і супутниках:
#1. Хаби
Центри є серцевиною основної бізнес-концепції, як-от клієнт, продавець, продаж або продукт. Таблиця концентратора формується навколо бізнес-ключа (ім’я магазину або розташування), коли новий екземпляр цього бізнес-ключа вперше вводиться в сховище даних.
Хаб не містить описової інформації та FK. Він складається лише з бізнес-ключа зі згенерованою в сховищі послідовністю ідентифікаторів або хеш-ключів, позначки дати/часу завантаження та джерела запису.
#2. Посилання
Посилання встановлюють зв’язки між бізнес-ключами. Кожен запис у посиланні моделює nm зв’язків будь-якої кількості концентраторів. Це дозволяє сховищу даних гнучко реагувати на зміни в бізнес-логіці вихідних систем, такі як зміни в сердечності відносин. Як і хаб, посилання не містить жодної описової інформації. Він складається з ідентифікаторів послідовності концентраторів, на які він посилається, ідентифікатора послідовності, створеного складом, позначки дати/часу завантаження та джерела запису.
#3. Супутники
Супутники містять описову інформацію (контекст) для бізнес-ключа, що зберігається в концентраторі, або зв’язку, що зберігається в посиланні. Супутники працюють «лише вставлення», тобто повна історія даних зберігається на супутнику. Кілька супутників можуть описувати один бізнес-ключ (або зв’язок). Однак супутник може описати лише один ключ (хаб або посилання).
 Джерело зображення: Carbidfischer
Джерело зображення: Carbidfischer
Як створити модель сховища даних
Створення моделі сховища даних складається з кількох етапів, кожен із яких має вирішальне значення для того, щоб модель була масштабованою, гнучкою та здатною відповідати потребам бізнесу.
#1. Визначте сутності та атрибути
Визначте суб’єкти господарювання та їхні відповідні атрибути. Це передбачає тісну співпрацю з бізнес-стейкхолдерами, щоб зрозуміти їхні вимоги та дані, які вони повинні отримати. Після визначення цих об’єктів і атрибутів розділіть їх на концентратори, посилання та супутники.
#2. Визначте зв’язки сутностей і створіть зв’язки
Після визначення сутностей і атрибутів визначаються зв’язки між сутностями та створюються зв’язки для представлення цих зв’язків. Кожному зв’язку призначається бізнес-ключ, який визначає зв’язок між сутностями. Потім додаються супутники, щоб зафіксувати атрибути та зв’язки об’єктів.
#3. Встановіть правила та стандарти
Після створення зв’язків необхідно встановити набір правил і стандартів моделювання сховищ даних, щоб гарантувати, що модель є гнучкою та може обробляти зміни з часом. Ці правила та стандарти слід регулярно переглядати та оновлювати, щоб вони залишалися актуальними та відповідали потребам бізнесу.
#4. Заповніть модель
Після створення моделі її слід заповнити даними за допомогою підходу поступового завантаження. Він передбачає завантаження даних у концентратори, канали зв’язку та супутники за допомогою дельта-завантажень. Дельта-завантаження гарантує, що завантажуються лише зміни, внесені до даних, що зменшує час і ресурси, необхідні для інтеграції даних.
#5. Випробуйте та перевірте модель
Нарешті, модель має бути перевірена та підтверджена, щоб переконатися, що вона відповідає бізнес-вимогам і є достатньо масштабованою та гнучкою для обробки майбутніх змін. Слід проводити регулярне технічне обслуговування та оновлення, щоб гарантувати, що модель залишається узгодженою з потребами бізнесу та продовжує надавати уніфіковане уявлення про дані.
Навчальні ресурси Data Vault
Опанування Data Vault може надати цінні навички та знання, які дуже затребувані в сучасних галузях, що керуються даними. Ось вичерпний список ресурсів, включаючи курси та книги, які можуть допомогти вивчити тонкощі Data Vault:
#1. Моделювання сховища даних за допомогою Data Vault 2.0

Цей курс Udemy є комплексним вступом до підходу моделювання Data Vault 2.0, гнучкого управління проектами та інтеграції великих даних. Курс охоплює основи Data Vault 2.0, включаючи його архітектуру та рівні, бізнес-сховища та інформаційні сховища, а також передові методи моделювання.
Він навчить вас створювати модель Data Vault з нуля, перетворювати традиційні моделі, як-от 3NF, і розмірні моделі в Data Vault, а також зрозуміти принципи розмірного моделювання в Data Vault. Курс вимагає базових знань баз даних і основ SQL.
Завдяки високому рейтингу 4,4 з 5 і понад 1700 відгуків, цей курс-бестселер підходить для тих, хто хоче побудувати міцну основу для Data Vault 2.0 та інтеграції Big Data.
#2. Моделювання сховища даних пояснюється випадками використання

Цей курс Udemy спрямований на те, щоб допомогти вам створити модель сховища даних на практичному бізнес-прикладі. Він слугує посібником для початківців із моделювання сховища даних, охоплюючи такі ключові поняття, як відповідні сценарії використання моделей сховища даних, обмеження традиційного моделювання OLAP і систематичний підхід до побудови моделі сховища даних. Курс доступний для осіб з мінімальними знаннями баз даних.
#3. Гуру Data Vault: прагматичний посібник
Гуру Data Vault пана Патріка Куби — це вичерпний посібник із методології сховища даних, який пропонує унікальну можливість моделювати корпоративне сховище даних із використанням принципів автоматизації, подібних до тих, що використовуються в розробці програмного забезпечення.
У книзі представлено огляд сучасної архітектури, а потім пропонується докладний посібник щодо того, як створити гнучку модель даних, яка адаптується до змін на підприємстві, сховища даних.
Крім того, книга розширює методологію сховища даних, забезпечуючи автоматизовану корекцію часової шкали, журнали аудиту, контроль метаданих та інтеграцію з гнучкими інструментами доставки.
#4. Створення масштабованого сховища даних за допомогою Data Vault 2.0
Ця книга надає читачам вичерпний посібник зі створення масштабованого сховища даних від початку до кінця за допомогою методології Data Vault 2.0.
Ця книга охоплює всі основні аспекти побудови масштабованого сховища даних, включаючи техніку моделювання Data Vault, яка розроблена для запобігання типових збоїв у сховищі даних.
Книга містить численні приклади, які допоможуть читачам чітко зрозуміти концепції. Завдяки практичним ідеям і реальним прикладам ця книга є важливим ресурсом для всіх, хто цікавиться сховищами даних.
#5. Слон у холодильнику: покрокові кроки до успіху Data Vault
«Слон у холодильнику» Джона Джайлза — це практичний посібник, який має на меті допомогти читачам досягти успіху в Data Vault, починаючи з бізнесу й закінчуючи ним.
Книга зосереджена на важливості корпоративної онтології та моделювання бізнес-концепції та містить покрокові вказівки щодо застосування цих концепцій для створення надійної моделі даних.
Завдяки практичним порадам і зразкам шаблонів автор пропонує чітке та нехитре пояснення складних тем, що робить книгу чудовим посібником для тих, хто вперше знайомиться зі сховищем даних.
Заключні слова
Data Vault представляє майбутнє сховищ даних, пропонуючи компаніям значні переваги з точки зору гнучкості, масштабованості та ефективності. Він особливо добре підходить для компаній, яким потрібно швидко завантажувати великі обсяги даних, і тих, хто хоче розвивати свої програми бізнес-аналітики гнучким способом.
Крім того, компанії, які мають існуючу силосну архітектуру, можуть отримати значну вигоду від впровадження базового сховища даних на першому етапі за допомогою Data Vault.
Вам також може бути цікаво дізнатися про походження даних.