
Веб-збирання — це потужна техніка для отримання інформації з веб-сайтів і їх автоматичного аналізу. Хоча ви можете зробити це вручну, це може бути виснажливим і трудомістким завданням. Інструменти для сканування веб-сторінок роблять процес швидшим і ефективнішим, але коштують менше.
Цікаво, що завдяки функції IMPORTXML Google Sheets може стати вашим універсальним інструментом для запису в Інтернеті. За допомогою IMPORTXML ви можете легко знімати дані з веб-сторінок і використовувати їх для аналізу, звітування або будь-яких інших завдань, керованих даними.
Функція IMPORTXML у Google Таблицях
Google Таблиці містять вбудовану функцію під назвою IMPORTXML, яка дозволяє імпортувати дані з таких веб-форматів, як XML, HTML, RSS і CSV. Ця функція може змінити правила гри, якщо ви хочете збирати дані з веб-сайтів, не вдаючись до складного кодування.
Ось основний синтаксис IMPORTXML:
=IMPORTXML(url, xpath_query)
- url: URL-адреса веб-сторінки, з якої потрібно отримати дані.
- xpath_query: Запит XPath, який визначає дані, які ви хочете отримати.
XPath (XML Path Language) — це мова, яка використовується для навігації по XML-документах, включаючи HTML, що дозволяє вказувати розташування даних у структурі HTML. Розуміння запитів XPath є важливим для належного використання IMPORTXML.
Розуміння XPath
XPath надає різні функції та вирази для навігації та фільтрації даних у документі HTML. Вичерпний посібник із XML і XPath виходить за рамки цієї статті, тому ми зупинимося на деяких основних концепціях XPath:
- Вибір елементів: Ви можете вибирати елементи за допомогою / і // для позначення шляхів. Наприклад, /html/body/div вибирає всі елементи div у тілі документа.
- Вибір атрибутів: щоб вибрати атрибути, ви можете використовувати @. Наприклад, //@href вибирає всі атрибути href на сторінці.
- Фільтри предикатів: Ви можете фільтрувати елементи за допомогою предикатів, узятих у квадратні дужки ([ ]). Наприклад, /div[@class=”container”] вибирає всі елементи div з контейнером класу.
- Функції: XPath надає різні функції, такі як contains(), starts-with() і text() для виконання певних дій, як-от перевірка текстового вмісту або значень атрибутів.
Наразі ви знаєте синтаксис IMPORTXML, ви знаєте URL-адресу веб-сайту та знаєте, який елемент ви хочете витягти. Але як отримати XPath елемента?
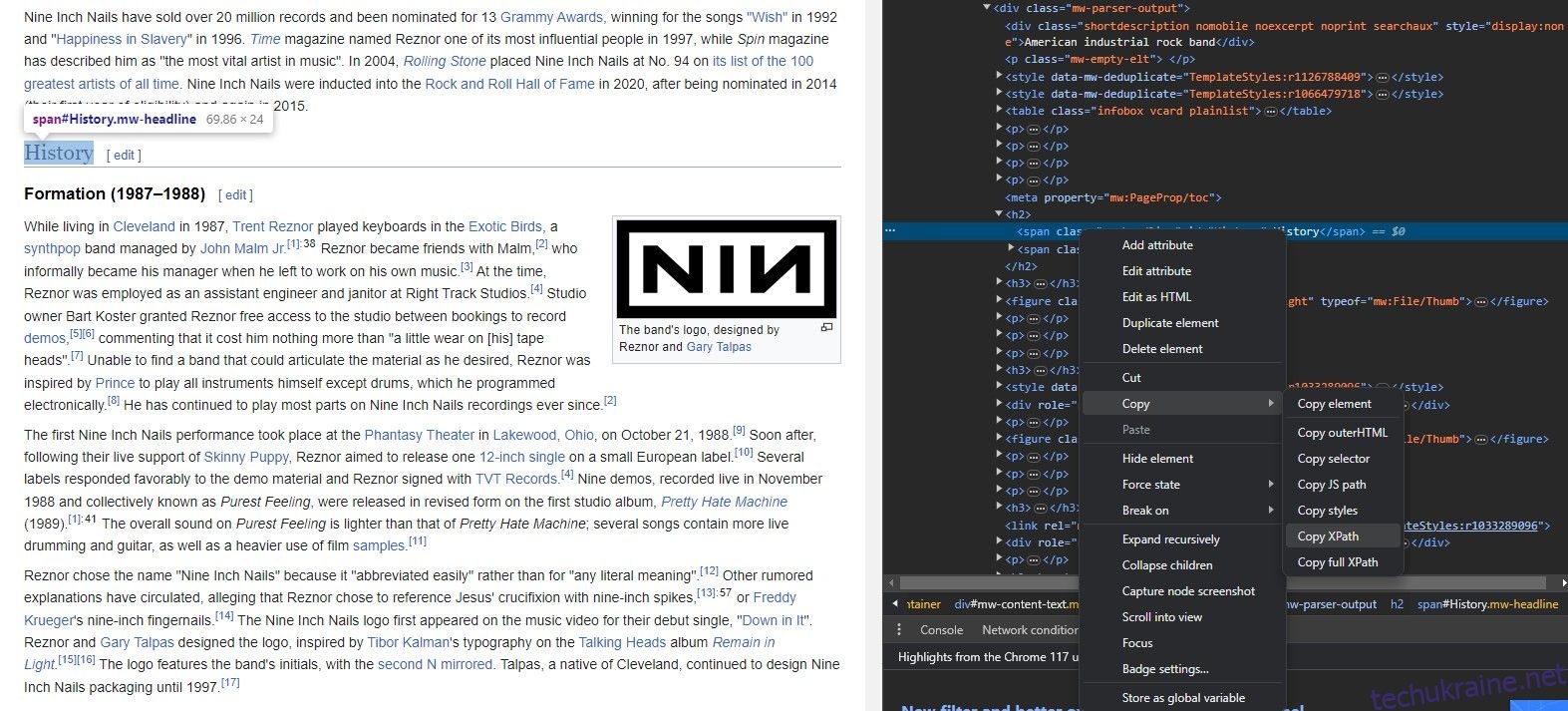
Вам не обов’язково знати структуру веб-сайту напам’ять, щоб отримати його дані за допомогою IMPORTXML. Насправді кожен браузер має чудовий інструмент, який дозволяє миттєво скопіювати XPath будь-якого елемента.
Інструмент Inspect Element дозволяє витягувати XPath з елементів веб-сайту. Ось як:
Тепер, коли у вас є все, що вам потрібно, настав час побачити IMPORTXML у дії та отримати деякі посилання.
Як отримати посилання з веб-сайту за допомогою IMPORTXML
Ви можете використовувати IMPORTXML для збирання всіляких даних із веб-сайтів. Це включає в себе посилання, відео, зображення та майже будь-який елемент веб-сайту. Посилання є одним із найпомітніших елементів веб-аналізу, і ви можете багато чого дізнатися про веб-сайт, просто проаналізувавши сторінки, на які він посилається.
IMPORTXML дозволяє швидко очищати посилання в Таблицях Google, а потім аналізувати їх за допомогою різних функцій, які пропонує Google Таблиці.
1. Очистіть усі посилання
Щоб видалити всі посилання з веб-сторінки, можна використати таку формулу:
=IMPORTXML(url, "//a/@href")
Цей запит XPath вибирає всі атрибути href елементів, фактично вилучаючи всі посилання на сторінці.
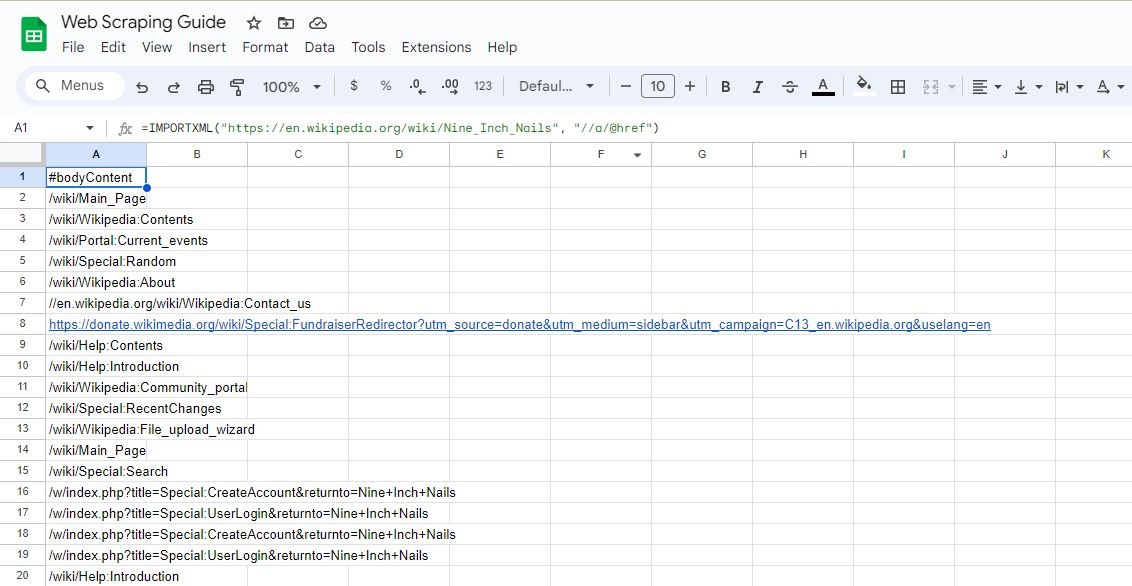
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Наведена вище формула знімає всі посилання у статті Вікіпедії.
Бажано ввести URL-адресу веб-сторінки в окрему клітинку, а потім звернутися до неї. Це дозволить вашій формулі не стати занадто довгою та громіздкою. Ви можете зробити те саме за допомогою запиту XPath.
2. Збирання всіх текстів посилань
Щоб отримати текст посилань разом із їхніми URL-адресами, ви можете використати:
=IMPORTXML(url, "//a")
Цей запит вибирає всі елементи, і ви можете отримати текст посилання та URL-адреси з результатів.
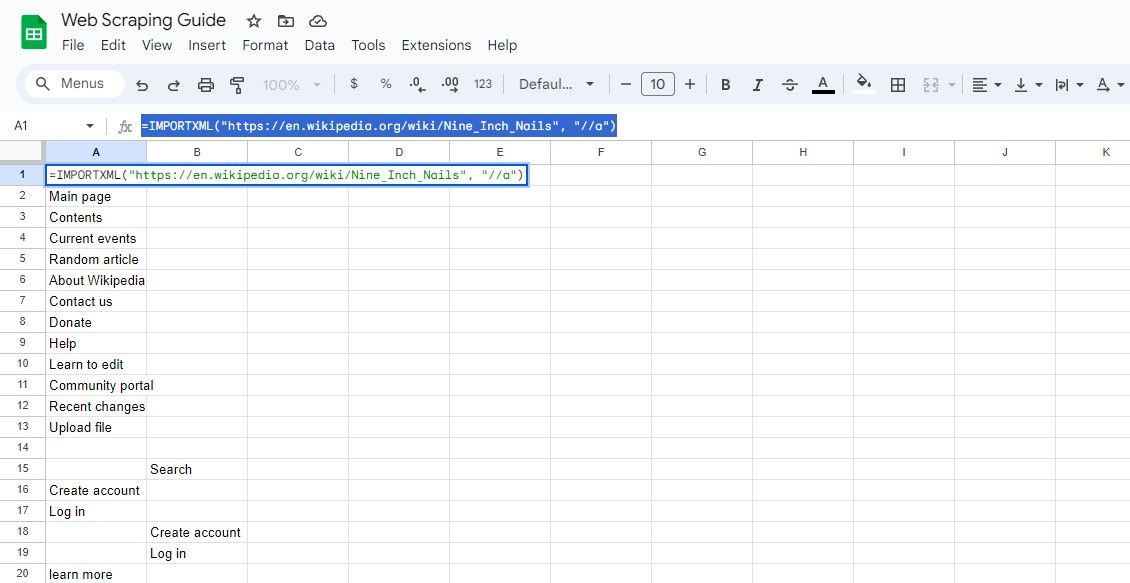
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Наведена вище формула отримує тексти посилань у тій самій статті Вікіпедії.
Як отримати певні посилання з веб-сайту за допомогою IMPORTXML
Іноді вам може знадобитися отримати певні посилання на основі критеріїв. Наприклад, вас може зацікавити отримання посилань, які містять певне ключове слово, або посилань, розташованих у певному розділі сторінки.
З належним знанням XPath ви зможете точно визначити будь-який елемент, який шукаєте.
1. Збирання посилань, що містять ключове слово
Щоб отримати посилання, які містять певне ключове слово, ви можете використати функцію contains() XPath:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Цей запит вибирає атрибути href елементів, де href містить вказане ключове слово.
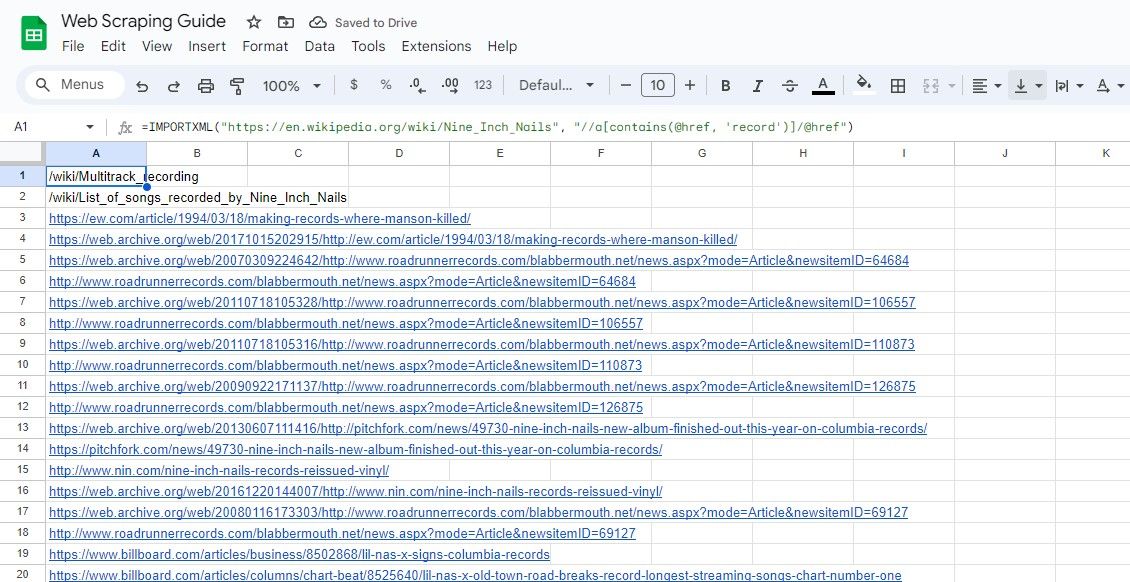
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Наведена вище формула очищає всі посилання, які містять запис слова у тексті зразка статті Вікіпедії.
2. Викопування посилань у розділі
Щоб отримати посилання з певного розділу сторінки, ви можете вказати XPath розділу. Наприклад:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Цей запит вибирає атрибути href елементів у елементах div із класом «section».
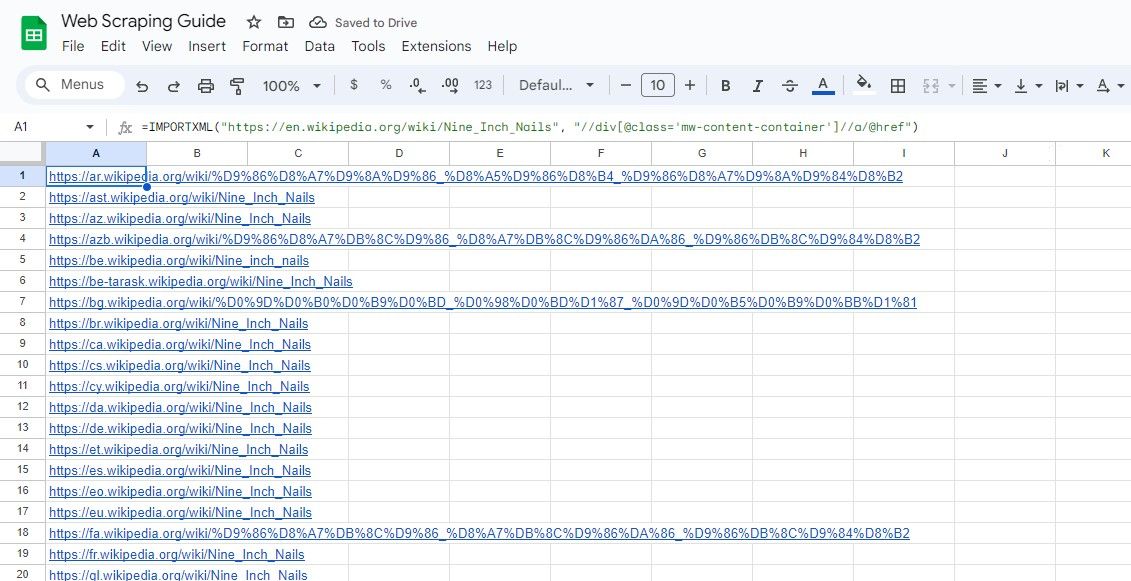
Подібним чином наведена нижче формула вибирає всі посилання в класі div, які мають клас mw-content-container:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Варто зазначити, що ви можете використовувати IMPORTXML не тільки для веб-збирання. Ви можете використовувати сімейство функцій IMPORT, щоб імпортувати таблиці даних із веб-сайтів у Google Таблиці.
Хоча Google Таблиці та Excel мають спільну більшість функцій, сімейство функцій IMPORT є унікальним для Google Таблиць. Вам потрібно буде розглянути інші методи імпорту даних із веб-сайтів до Excel.
Спростіть веб-скрапінг за допомогою Google Таблиць
Веб-збирання за допомогою Google Sheets і функції IMPORTXML — це універсальний і доступний спосіб збору даних із веб-сайтів.
Освоївши XPath і зрозумівши, як створювати ефективні запити, ви зможете повністю розкрити потенціал IMPORTXML і отримати цінну інформацію з веб-ресурсів. Отже, почніть копіювання та виведіть свій веб-аналіз на новий рівень!