

Python є дуже універсальною мовою, і розробникам Python часто доводиться працювати з різноманітними файлами та отримувати збережену в них інформацію для обробки. Одним із популярних форматів файлів, з якими ви неодмінно зіткнетеся як розробник Python, є Portable Document Format, широко відомий як PDF
PDF-файли можуть містити текст, зображення та посилання. Під час обробки даних у програмі Python вам може знадобитися витягнути дані, що зберігаються в документі PDF. На відміну від структур даних, таких як кортежі, списки та словники, отримати інформацію, що зберігається в документі PDF, може здатися складною справою.
На щастя, існує низка бібліотек, які спрощують роботу з PDF-файлами та видобування даних, що зберігаються у PDF-файлах. Щоб дізнатися про ці різні бібліотеки, давайте розглянемо, як можна витягувати тексти, посилання та зображення з файлів PDF. Щоб продовжити, завантажте наступний PDF-файл і збережіть його в тому самому каталозі, що й програмний файл Python.
Щоб отримати текст із PDF-файлів за допомогою Python, ми збираємося використовувати PyPDF2 бібліотека. PyPDF2 — це безкоштовна бібліотека Python із відкритим кодом, яку можна використовувати для об’єднання, обрізання та трансформації сторінок PDF-файлів. Він може додавати власні дані, параметри перегляду та паролі до PDF-файлів. Однак важливо, що PyPDF2 може отримувати текст із файлів PDF.
Щоб використовувати PyPDF2 для вилучення тексту з файлів PDF, установіть його за допомогою pip, який є інсталятором пакетів для Python. pip дозволяє встановлювати різні пакунки Python на вашу машину:
1. Перевірте, чи у вас уже встановлено pip, виконавши:
pip --version
Якщо ви не отримуєте номер версії, це означає, що pip не встановлено.
2. Щоб встановити pip, натисніть на отримати піп щоб завантажити сценарій встановлення.
Посилання відкриває сторінку зі сценарієм для встановлення pip, як показано нижче:
Клацніть правою кнопкою миші на сторінці та натисніть «Зберегти як», щоб зберегти файл. За замовчуванням ім’я файлу get-pip.py
Відкрийте термінал і перейдіть до каталогу з файлом get-pip.py, який ви щойно завантажили, а потім виконайте команду:
sudo python3 get-pip.py
Це має встановити pip, як показано нижче:
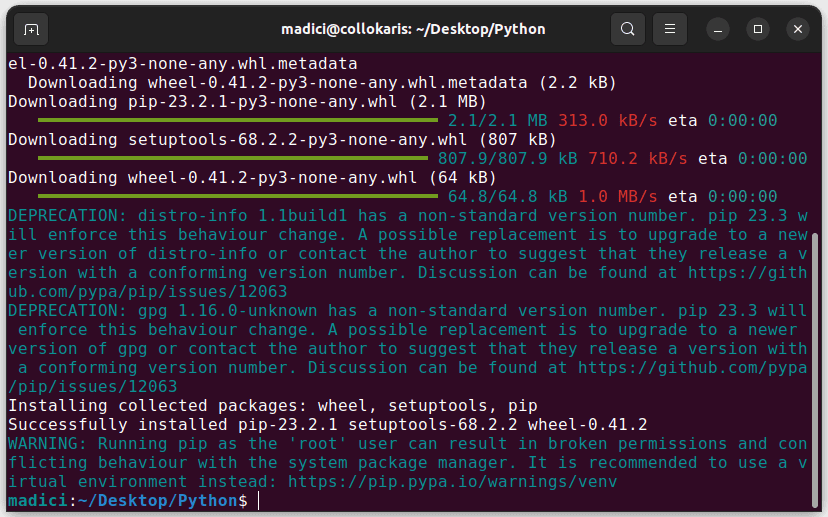
3. Переконайтеся, що pip успішно встановлено, виконавши:
pip --version
У разі успіху ви повинні отримати номер версії:

Після встановлення pip ми можемо почати працювати з PyPDF2.
1. Встановіть PyPDF2, виконавши таку команду в терміналі:
pip install PyPDF2
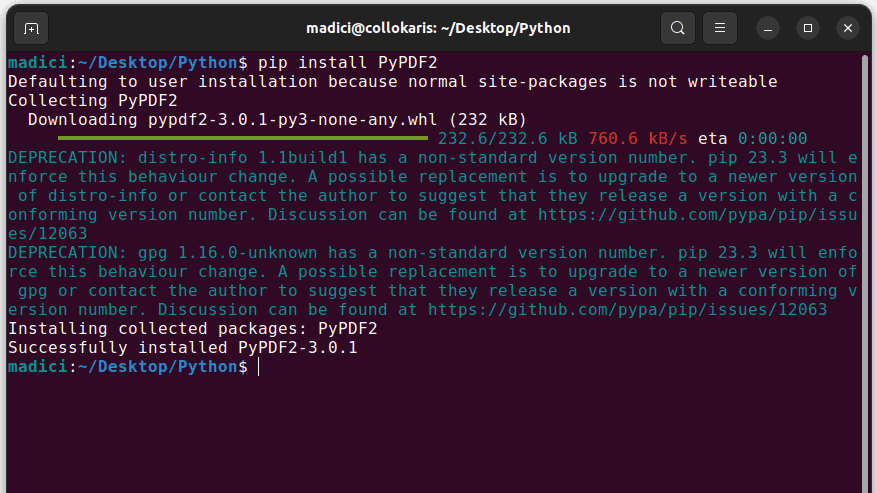
2. Створіть файл Python та імпортуйте PdfReader із PyPDF2 за допомогою такого рядка:
from PyPDF2 import PdfReader
Бібліотека PyPDF2 надає різноманітні класи для роботи з файлами PDF. Одним із таких класів є PdfReader, який, серед іншого, можна використовувати для відкриття PDF-файлів, читання вмісту та вилучення тексту з PDF-файлів.
3. Щоб розпочати роботу з PDF-файлом, спочатку потрібно відкрити файл. Для цього створіть екземпляр класу PdfReader і передайте PDF-файл, з яким ви хочете працювати:
reader = PdfReader('games.pdf')
Рядок вище створює екземпляр PdfReader і готує його до доступу до вмісту вказаного вами PDF-файлу. Екземпляр зберігається в змінній під назвою reader, яка матиме доступ до різноманітних методів і властивостей, доступних у класі PdfReader.
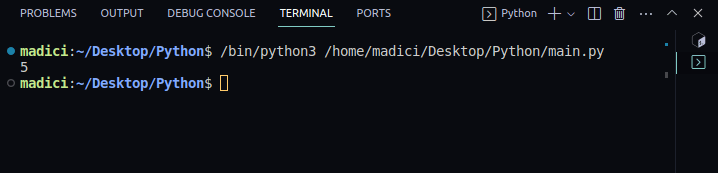
4. Щоб перевірити, чи все працює нормально, роздрукуйте кількість сторінок у PDF-файлі, який ви передали, використовуючи такий код:
print(len(reader.pages))
Вихід:
5
5. Оскільки наш файл PDF містить 5 сторінок, ми можемо отримати доступ до кожної сторінки, доступної в PDF. Однак підрахунок починається з 0, як і в індексації Python. Таким чином, перша сторінка у файлі PDF матиме номер сторінки 0. Щоб отримати першу сторінку PDF-файлу, додайте такий рядок до свого коду:
page1 = reader.pages[0]
Рядок вище отримує першу сторінку PDF-файлу та зберігає її у змінній з іменем page1.
6. Щоб витягти текст на першій сторінці PDF-файлу, додайте такий рядок:
textPage1 = page1.extract_text()
Це витягує текст на першій сторінці PDF-файлу та зберігає вміст у змінній з іменем textPage1. Таким чином, ви маєте доступ до тексту на першій сторінці PDF-файлу через змінну textPage1.
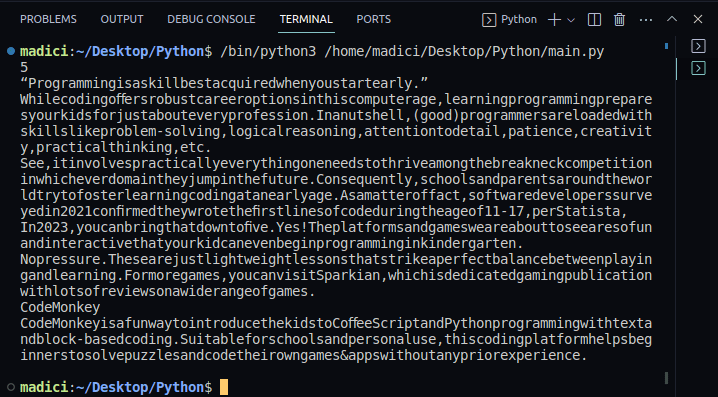
7. Щоб підтвердити успішне вилучення тексту, ви можете надрукувати вміст змінної textPage1. Весь наш код, який також друкує текст на першій сторінці PDF-файлу, показано нижче:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Вихід:
Щоб отримати посилання з PDF-файлів, ми перейдемо до PyMuPDF, яка є бібліотекою Python для вилучення, аналізу, перетворення та обробки даних, що зберігаються в таких документах, як PDF. Щоб використовувати PyMuPDF, у вас повинен бути Python 3.8 або новішої версії. Щоб почати:
1. Встановіть PyMuPDF, виконавши такий рядок у терміналі:
pip install PyMuPDF
2. Імпортуйте PyMuPDF у свій файл Python за допомогою наступного оператора:
import fitz
3. Щоб отримати доступ до PDF-файлу, з якого ви бажаєте отримати посилання, спершу його потрібно відкрити. Щоб відкрити його, введіть наступний рядок:
doc = fitz.open("games.pdf")
4. Відкривши PDF-файл, надрукуйте кількість сторінок у PDF-файлі за допомогою такого рядка:
print(doc.page_count)
Вихід:
5
4. Щоб отримати посилання зі сторінки у файлі PDF, нам потрібно завантажити сторінку, з якої ми хочемо отримати посилання. Щоб завантажити сторінку, введіть наступний рядок, де ви передаєте номер сторінки, яку хочете завантажити, у функцію під назвою load_page()
page = doc.load_page(0)
Щоб отримати посилання з першої сторінки, ми передаємо 0 (нуль). Підрахунок сторінок починається з нуля, як і в структурах даних, таких як масиви та словники.
5. Витягніть посилання зі сторінки за допомогою такого рядка:
links = page.get_links()
Усі посилання на сторінці, яку ви вказали, у нашому випадку, на сторінці 1, будуть витягнуті та збережені у змінній links
6. Щоб побачити вміст змінної links, роздрукуйте його так:
print(links)
Вихід:
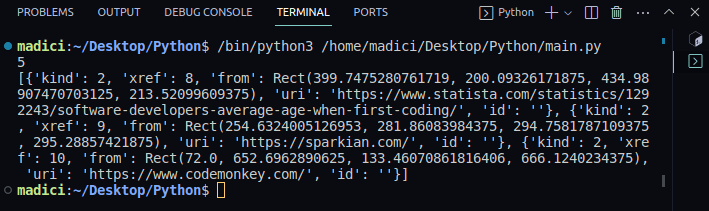
З надрукованого виходу зауважте, що посилання на змінні містять список словників із парами ключ-значення. Кожне посилання на сторінці представлено словником, а фактичне посилання зберігається під ключем «uri»
7. Щоб отримати посилання зі списку об’єктів, що зберігаються під назвою змінної links, переберіть список за допомогою оператора for in і роздрукуйте конкретні посилання, що зберігаються під uri ключа. Весь код, який це робить, показано нижче:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
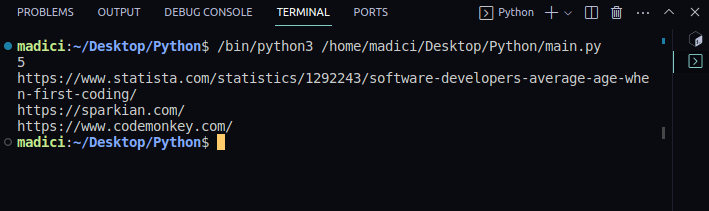
Вихід:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
8. Щоб зробити наш код більш придатним для повторного використання, ми можемо змінити його, визначивши функцію для вилучення всіх посилань у PDF-файлі та функцію для друку всіх посилань, знайдених у PDF-файлі. Таким чином, ви можете викликати функції з будь-яким PDF-файлом, і ви отримаєте назад усі посилання в PDF-файлі. Код, який це робить, показано нижче:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
Вихід:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
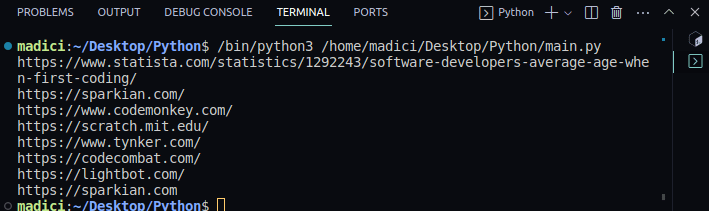
З наведеного вище коду функція extract_link() отримує PDF-файл, перебирає всі сторінки PDF-файлу, витягує всі посилання та повертає їх. Результат цієї функції зберігається в змінній з іменем all_links
Функція print_all_links() приймає результат extract_link(), перебирає список і друкує всі фактичні посилання, знайдені в PDF-файлі, який ви передали у функцію extract_link().
Щоб отримати зображення з PDF-файлу, ми все ще будемо використовувати PyMuPDF. Щоб отримати зображення з файлу PDF:
1. Імпортуйте PyMuPDF, io та PIL. Бібліотека зображень Python (PIL) надає інструменти, які спрощують створення та збереження зображень, серед інших функцій. io надає класи для легкої та ефективної обробки двійкових даних.
import fitz from io import BytesIO from PIL import Image
2. Відкрийте PDF-файл, з якого потрібно витягти зображення:
doc = fitz.open("games.pdf")
3. Завантажте сторінку, з якої потрібно отримати зображення:
page = doc.load_page(0)
4. PyMuPdf ідентифікує зображення у файлі PDF за допомогою перехресного посилання (xref), яке зазвичай є цілим числом. Кожне зображення у файлі PDF має унікальне посилання. Таким чином, щоб отримати зображення з PDF-файлу, ми спочатку повинні отримати номер зовнішнього посилання, який його ідентифікує. Щоб отримати номер xref для зображень на сторінці, ми використовуємо функцію get_images() таким чином:
image_xref = page.get_images() print(image_xref)
Вихід:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
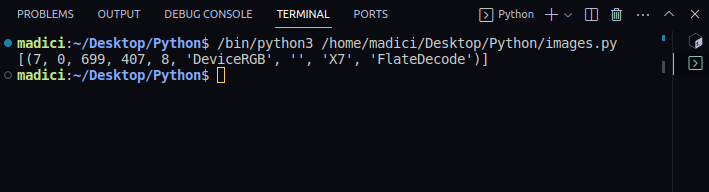
get_images() повертає список кортежів з інформацією про зображення. Оскільки ми маємо лише одне зображення на першій сторінці, є лише один кортеж. Перший елемент у кортежі представляє зовнішнє посилання зображення на сторінці. Таким чином, зовнішнє посилання зображення на першій сторінці дорівнює 7.
5. Щоб отримати значення xref для зображення зі списку кортежів, ми використовуємо наведений нижче код:
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Вихід:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
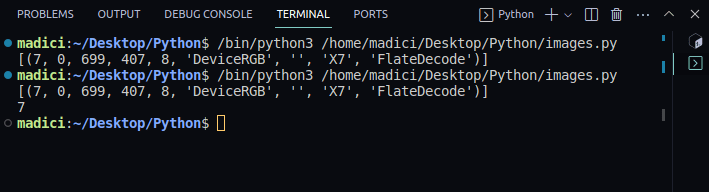
6. Оскільки тепер у вас є зовнішнє посилання, яке ідентифікує зображення в PDF-файлі, ви можете витягти зображення за допомогою функції extract_image() таким чином:
img_dictionary = doc.extract_image(xref_value)
Однак ця функція не повертає фактичне зображення. Натомість він повертає словник, що містить двійкові дані зображення та метадані про зображення, серед іншого.
7. У словнику, який повертає функція extract_image(), перевірте розширення файлу вилученого зображення. Розширення файлу зберігається під ключем «ext»:
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Вихід:
png
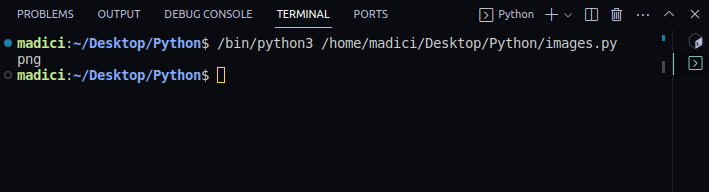
8. Витягніть двійкові файли зображення зі словника, що зберігається в img_dictionary. Двійкові файли зображень зберігаються під ключем «image»
# get the actual image binary data img_binary = img_dictionary["image"]
9. Створіть об’єкт BytesIO та ініціалізуйте його даними двійкового зображення, які представляють зображення. Це створює файлоподібний об’єкт, який можна обробляти бібліотеками Python, такими як PIL, щоб ви могли зберегти зображення.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Відкрийте та проаналізуйте дані зображення, що зберігаються в об’єкті BytesIO під назвою image_io, використовуючи бібліотеку PIL. Це важливо, оскільки дозволяє бібліотеці PIL визначати формат зображення, з яким ви намагаєтеся працювати, у даному випадку це PNG. Після визначення формату зображення PIL створює об’єкт зображення, яким можна керувати за допомогою функцій і методів PIL, наприклад методу save(), щоб зберегти зображення в локальному сховищі.
# open the image using Pillow image = Image.open(image_io)
11. Вкажіть шлях, куди потрібно зберегти зображення.
output_path = "image_1.png"
Оскільки наведений вище шлях містить лише назву файлу з його розширенням, видобуте зображення буде збережено в тому самому каталозі, що й файл Python, що містить цю програму. Зображення буде збережено як image_1.png. Розширення PNG важливо, щоб воно відповідало вихідному розширенню зображення.
12. Збережіть зображення та закрийте об’єкт ByteIO.
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Повний код для вилучення зображення з PDF-файлу показано нижче:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
Запустіть код і перейдіть до папки, що містить ваш файл Python; Ви повинні побачити витягнуте зображення з назвою image_1.png, як показано нижче:
Висновок
Щоб отримати більше практики з вилучення посилань, зображень і текстів із PDF-файлів, спробуйте змінити код у прикладах, щоб зробити їх більш придатними для повторного використання, як показано у прикладі посилань. Таким чином вам потрібно буде передати лише PDF-файл, і ваша програма на Python витягне всі посилання, зображення чи текст із усього PDF-файлу. Щасливого кодування!
Ви також можете дослідити деякі найкращі PDF API для будь-яких потреб бізнесу.