
Конвеєр агрегації є рекомендованим способом виконання складних запитів у MongoDB. Якщо ви використовували MapReduce від MongoDB, вам краще переключитися на конвеєр агрегації для більш ефективних обчислень.
Що таке агрегація в MongoDB і як вона працює?
Конвеєр агрегації — це багатоетапний процес для виконання розширених запитів у MongoDB. Він обробляє дані на різних етапах, які називаються конвеєром. Ви можете використовувати результати, згенеровані на одному рівні, як шаблон операції на іншому.
Наприклад, ви можете передати результат операції зіставлення на інший етап для сортування в такому порядку, поки не отримаєте бажаний результат.
Кожна стадія конвеєра агрегації має оператор MongoDB і генерує один або кілька трансформованих документів. Залежно від вашого запиту рівень може з’явитися кілька разів у конвеєрі. Наприклад, вам може знадобитися використовувати етапи оператора $count або $sort кілька разів у конвеєрі агрегації.
Етапи конвеєра агрегації
Конвеєр агрегації передає дані через кілька етапів в одному запиті. Є кілька етапів, і ви можете знайти їх деталі в Документація MongoDB.
Давайте визначимо деякі з найбільш часто використовуваних нижче.
Етап $match
Цей етап допомагає визначити конкретні умови фільтрації перед початком інших етапів агрегації. Ви можете використовувати його, щоб вибрати відповідні дані, які ви хочете включити в конвеєр агрегації.
$груповий етап
На груповому етапі дані поділяються на різні групи на основі певних критеріїв за допомогою пар ключ-значення. Кожна група представляє ключ у вихідному документі.
Наприклад, розглянемо такі дані про продажі:
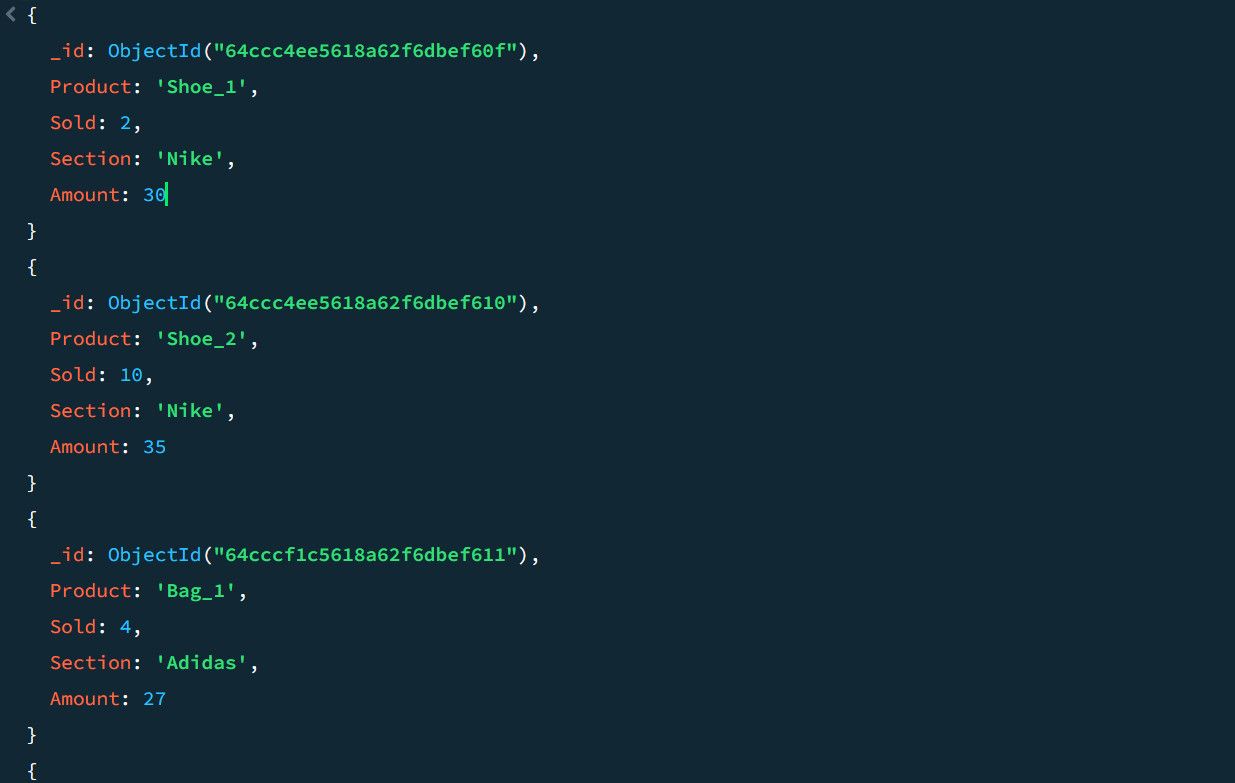
Використовуючи конвеєр агрегації, ви можете обчислити загальну кількість продажів і найбільші продажі для кожного розділу продукту:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Пара _id: $Section групує вихідний документ на основі розділів. Вказуючи поля top_sales_count і top_sales, MongoDB створює нові ключі на основі операції, визначеної агрегатором; це може бути $sum, $min, $max або $avg.
Етап $skip
Ви можете використовувати етап $skip, щоб пропустити вказану кількість документів у виводі. Зазвичай це відбувається після групового етапу. Наприклад, якщо ви очікуєте два вихідних документа, але пропустите один, агрегація виведе лише другий документ.
Щоб додати етап пропуску, вставте операцію $skip у конвеєр агрегації:
...,
{
$skip: 1
},
Етап $sort
Етап сортування дозволяє впорядкувати дані в порядку спадання або зростання. Наприклад, ми можемо додатково відсортувати дані в попередньому прикладі запиту в порядку спадання, щоб визначити, який розділ має найбільші продажі.
Додайте оператор $sort до попереднього запиту:
...,
{
$sort: {top_sales: -1}
},
Етап $limit
Операція обмеження допомагає зменшити кількість вихідних документів, які ви хочете показати в конвеєрі агрегації. Наприклад, скористайтеся оператором $limit, щоб отримати розділ із найвищими продажами, отриманими на попередньому етапі:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Наведене вище повертає лише перший документ; це розділ із найвищими продажами, оскільки він відображається у верхній частині відсортованого результату.
Стадія $project
Етап $project дозволяє вам формувати вихідний документ як вам подобається. Використовуючи оператор $project, ви можете вказати, яке поле включити до виводу, і налаштувати назву його ключа.
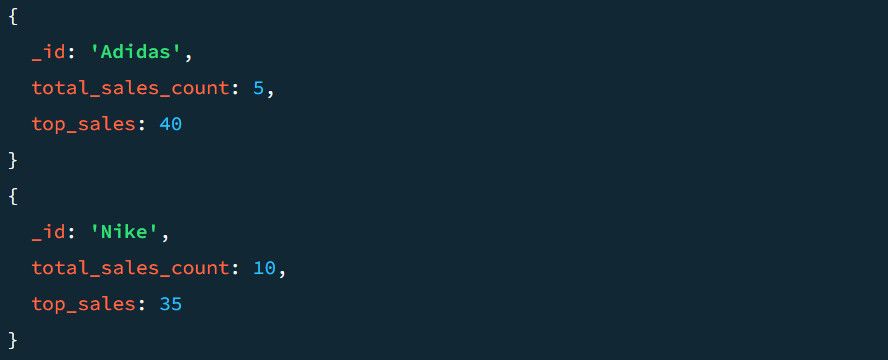
Наприклад, зразок результату без етапу $project виглядає так:
Давайте подивимося, як це виглядає на етапі $project. Щоб додати $project до конвеєра:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Оскільки ми раніше згрупували дані на основі розділів продукту, вищевказане включає кожен розділ продукту у вихідному документі. Це також гарантує, що сукупна кількість продажів і найбільші продажі відображаються у вихідних даних як TotalSold і TopSale.
Кінцевий результат набагато чистіший порівняно з попереднім:

Етап $unwind
Етап $unwind розбиває масив у документі на окремі документи. Візьмемо, наприклад, такі дані про замовлення:
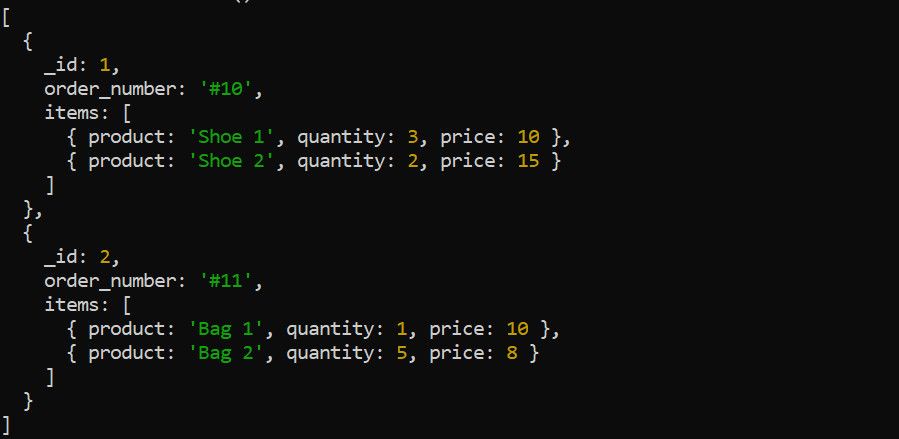
Використовуйте етап $unwind, щоб деконструювати масив елементів перед застосуванням інших етапів агрегації. Наприклад, розгортання масиву елементів має сенс, якщо ви хочете обчислити загальний дохід для кожного продукту:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Ось результат наведеного вище агрегаційного запиту:

Як створити конвеєр агрегації в MongoDB
Хоча конвеєр агрегації включає кілька операцій, описані раніше етапи дають вам уявлення про те, як застосовувати їх у конвеєрі, включаючи базовий запит для кожного.
Використовуючи попередній зразок даних про продажі, розглянемо деякі етапи, розглянуті вище, одним фрагментом для ширшого уявлення про конвеєр агрегації:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Кінцевий результат виглядає так, як ви бачили раніше:
Конвеєр агрегації проти MapReduce
До моменту припинення підтримки, починаючи з MongoDB 5.0, традиційним способом агрегування даних у MongoDB був MapReduce. Хоча MapReduce має ширші застосування за межі MongoDB, він менш ефективний, ніж конвеєр агрегації, тому для окремого написання функцій карти та редукції потрібні сторонні сценарії.
З іншого боку, конвеєр агрегації є специфічним лише для MongoDB. Але він забезпечує чистіший і ефективніший спосіб виконання складних запитів. Окрім простоти та масштабованості запитів, представлені етапи конвеєра роблять вихід більш настроюваним.
Існує ще багато відмінностей між конвеєром агрегації та MapReduce. Ви побачите їх під час переходу з MapReduce на конвеєр агрегації.
Зробіть запити великих даних ефективними в MongoDB
Ваш запит має бути максимально ефективним, якщо ви хочете виконати поглиблені обчислення складних даних у MongoDB. Конвеєр агрегації ідеально підходить для розширених запитів. Замість того, щоб маніпулювати даними в окремих операціях, що часто знижує продуктивність, агрегація дозволяє вам упакувати їх усі в один ефективний конвеєр і виконати їх один раз.
Хоча конвеєр агрегації ефективніший, ніж MapReduce, ви можете зробити агрегацію швидшою та ефективнішою, індексуючи свої дані. Це обмежує кількість даних, які MongoDB потрібно сканувати на кожному етапі агрегації.