
Шардинг бази даних — це техніка досягнення горизонтальної масштабованості у великих системах.
Майже всі системи реального світу складаються з сервера бази даних, який отримує багато запитів на читання та незначну кількість запитів на запис. Це може перевантажити сервер і погіршити роботу системи.
Щоб пом’якшити такий вплив і підвищити продуктивність системи, існують такі підходи, як реплікація бази даних і шардинг бази даних. У цьому посібнику ми спочатку дослідимо методи покращення продуктивності системи, зокрема:
- Масштабування сервера бази даних
- Реплікація бази даних
- Горизонтальна перегородка
Після обговорення цих методів ми перейдемо до вивчення того, як працює сегментування бази даних, а також розглянемо переваги та обмеження цього підходу.
Давайте почнемо!
Методи покращення продуктивності системи
Давайте почнемо з обговорення методів покращення продуктивності системи, коли є вузькі місця через сервер бази даних:
#1. Масштабування сервера бази даних
Масштабування екземпляра сервера бази даних може здатися простим підходом до підвищення продуктивності системи. Це включає в себе підвищення обчислювальної потужності, додавання більше оперативної пам’яті тощо.
Однак ця техніка має такі обмеження. Ми не можемо мати сервер із нескінченною пам’яттю та обчислювальною потужністю. І після певної межі ми отримуємо зменшувану віддачу.
#2. Реплікація бази даних
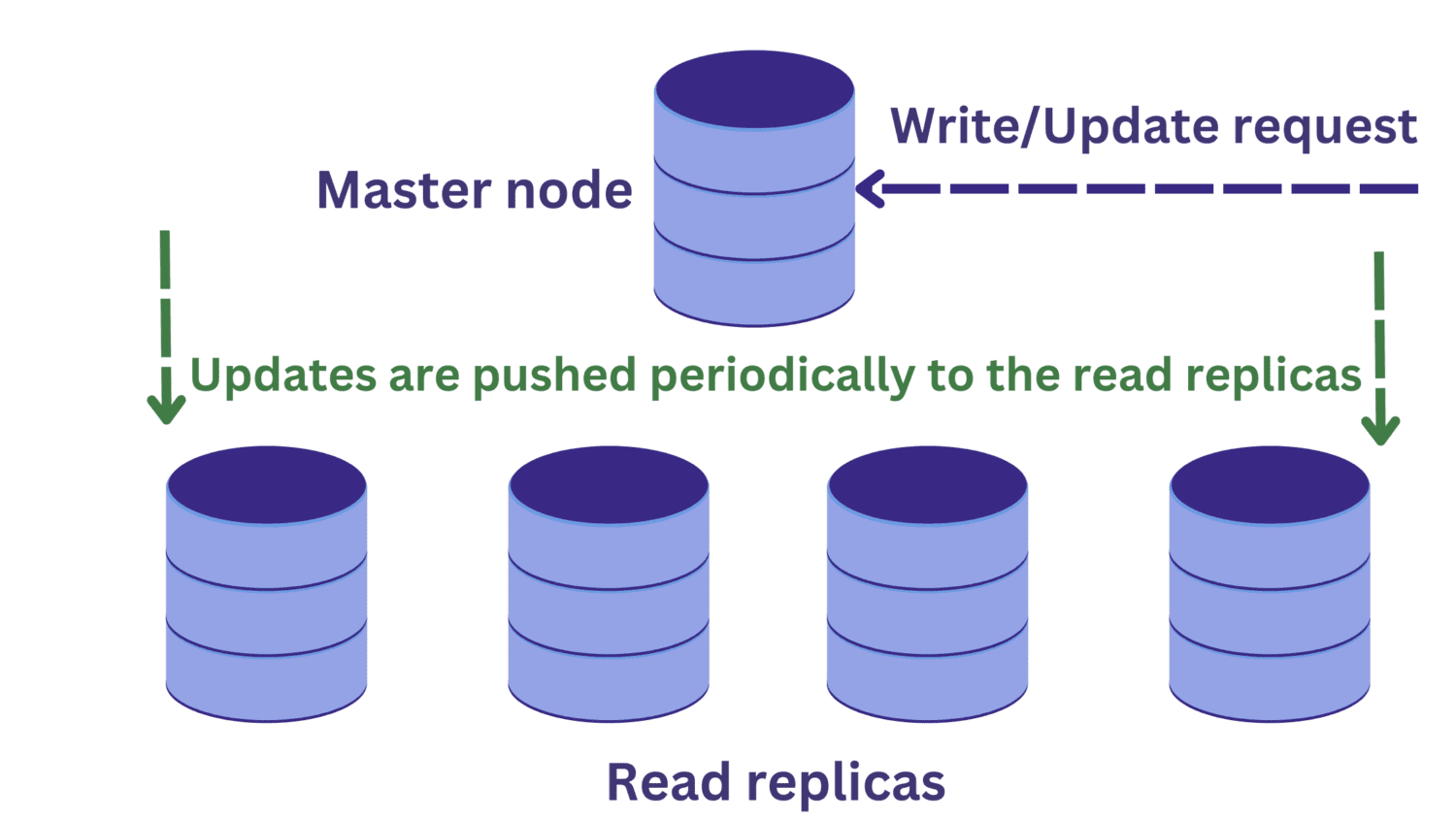
Коли екземпляр сервера бази даних перевантажується через вхідні запити, ми можемо розглянути реплікацію бази даних.
У реплікації бази даних ми маємо один головний вузол, який зазвичай отримує запити на запис. Існує кілька прочитаних реплік.
Це покращує доступність і зменшує перевантаження системи. Тепер ми можемо обробляти декілька запитів паралельно, оскільки запити на читання можна направляти до однієї з реплік читання.
Але це створює іншу проблему. Запити на запис до головного вузла можуть змінити дані, і ці оновлення періодично поширюються на репліки для читання.
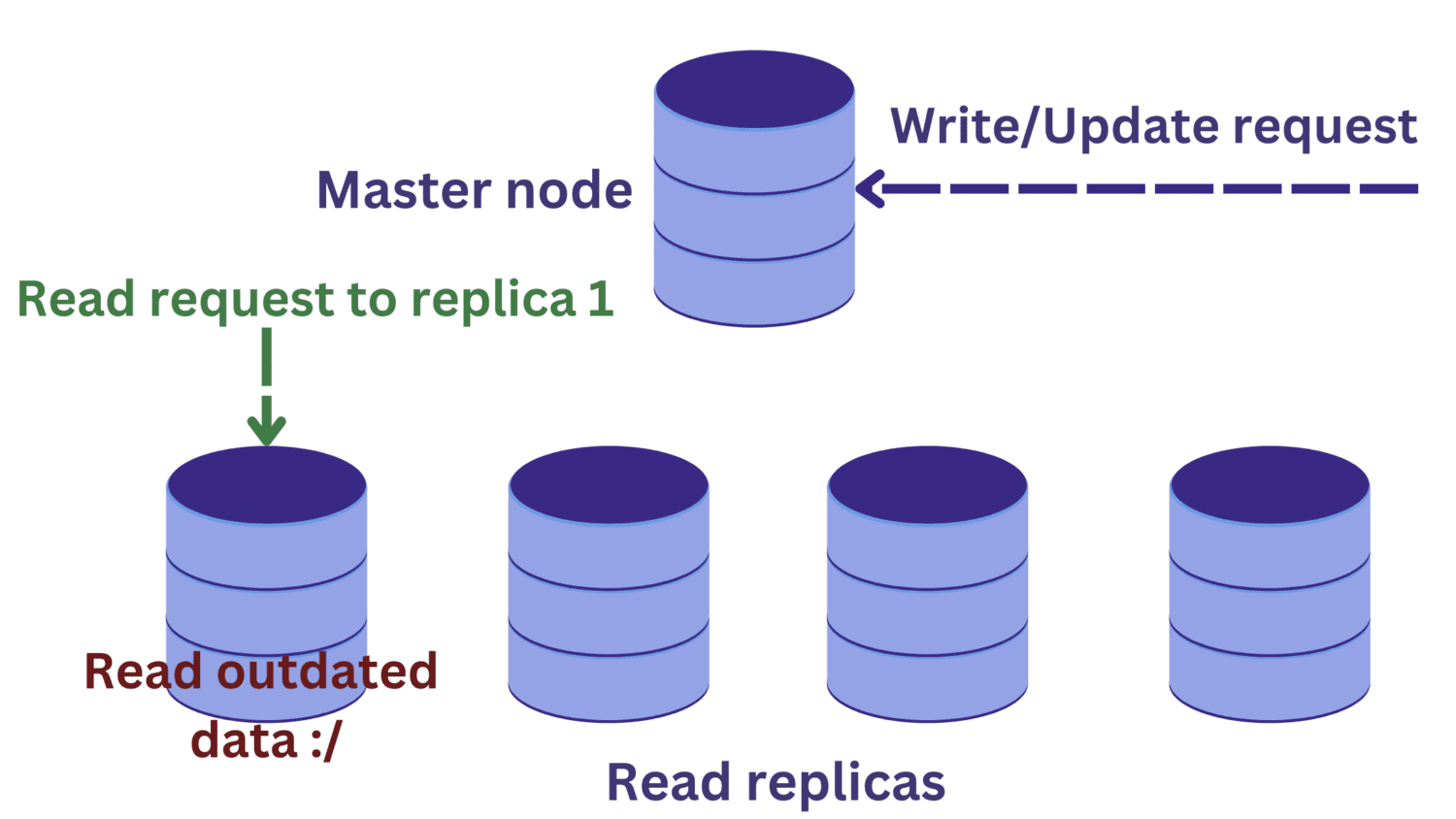
Припустимо, є запит на читання до однієї з реплік читання в той же час, коли на головному вузлі виконується операція запису.
Зміни в головному вузлі ще не поширюватимуться на репліки для читання. У цьому випадку ми можемо читати застарілі дані, що небажано.
#3. Горизонтальне розділення
Горизонтальне розділення — ще один метод оптимізації продуктивності системи. У нас може бути одна велика таблиця з мільярдами рядків (така як таблиця клієнтів і даних про транзакції).
Операції читання з такої таблиці бази даних повільніші. Але за допомогою горизонтального розділення одна велика таблиця тепер розділена на кілька розділів (або менших таблиць), з яких ми можемо читати. Реляційні бази даних, такі як PostgreSQL, спочатку підтримують розділення.
Однак усі розділи все ще знаходяться в одному екземплярі сервера бази даних. Єдина відмінність полягає в тому, що тепер ми можемо читати з розділів замість однієї великої таблиці.
Таким чином, коли кількість вхідних запитів збільшується, сервер може бути не в змозі підтримувати збільшений попит.
Як працює шардинг бази даних?
Тепер, коли ми обговорили підходи до покращення продуктивності системи та їхні обмеження, давайте зрозуміємо, як працює шардинг бази даних.
У шардингу ми розділяємо одну велику базу даних на кілька менших баз даних, кожна з яких працює на екземплярі сервера бази даних. Кожна така менша база даних називається сегментом. І кожен фрагмент містить унікальну підмножину даних.
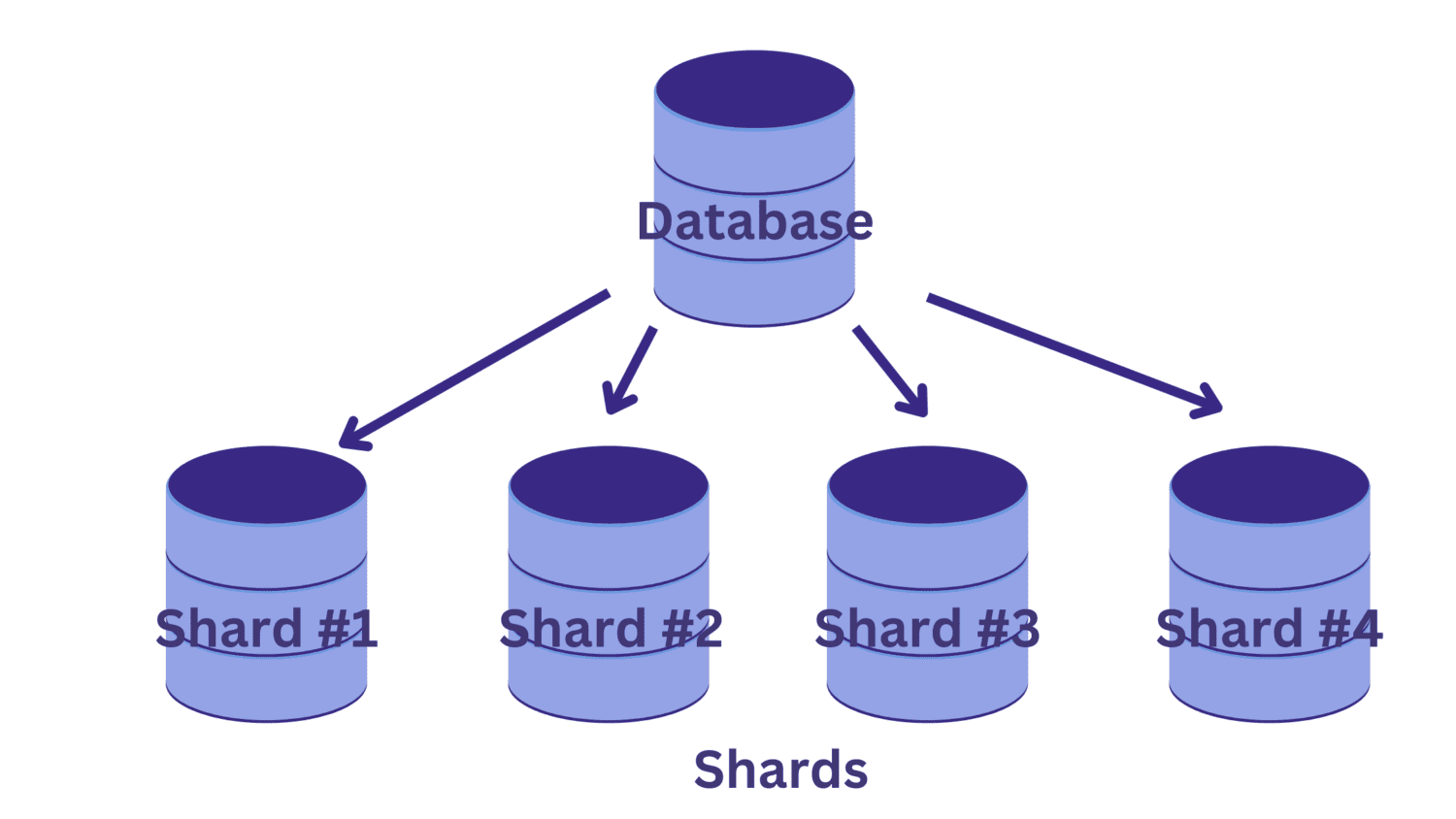
Але як ми розбиваємо базу даних на шарди? І як ми визначаємо, який із рядів входить до якого з шардів?
🔑 Введіть ключ шардингу.
Розуміння ключа шардингу
Давайте розберемося в ролі ключа шардингу.
Ключ шардингу, яким зазвичай є стовпець (або комбінація стовпців) у таблиці бази даних, слід вибирати таким чином, щоб дані розподілялися рівномірно між кількома шардами. Тому що ми не хочемо, щоб певний шард був набагато більшим за інші сегменти.
У базі даних, яка зберігає дані про клієнтів і транзакції, customer_ID є хорошим кандидатом на ключ сегментування.
Після того, як ми визначилися з ключем сегментування, ми можемо придумати функцію хешування, яка визначає, які з рядків потрапляють до того чи іншого сегменту.
У цьому прикладі, скажімо, нам потрібно розділити базу даних на п’ять шардів (шард №0 по шард №4), використовуючи customer_ID як ключ сегментування. У цьому випадку простою функцією хешування є customer_ID % 5.
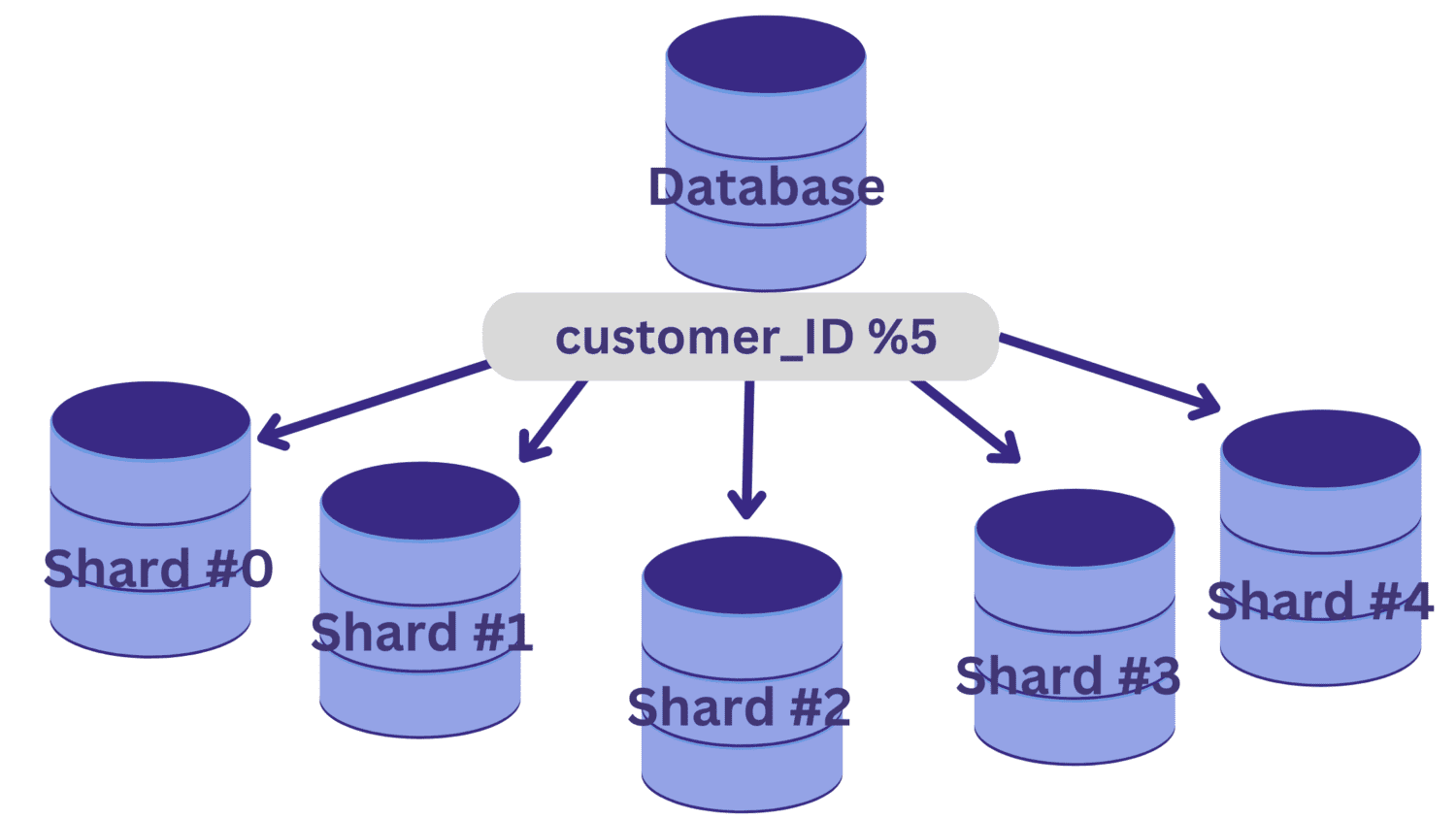
Усі значення customer_ID, які залишають нульовий залишок після ділення на 5, відображатимуться на фрагменті №0. А значення customer_ID, які залишають залишки від 1 до 4, будуть відображатися на фрагменти №1–№4 відповідно.
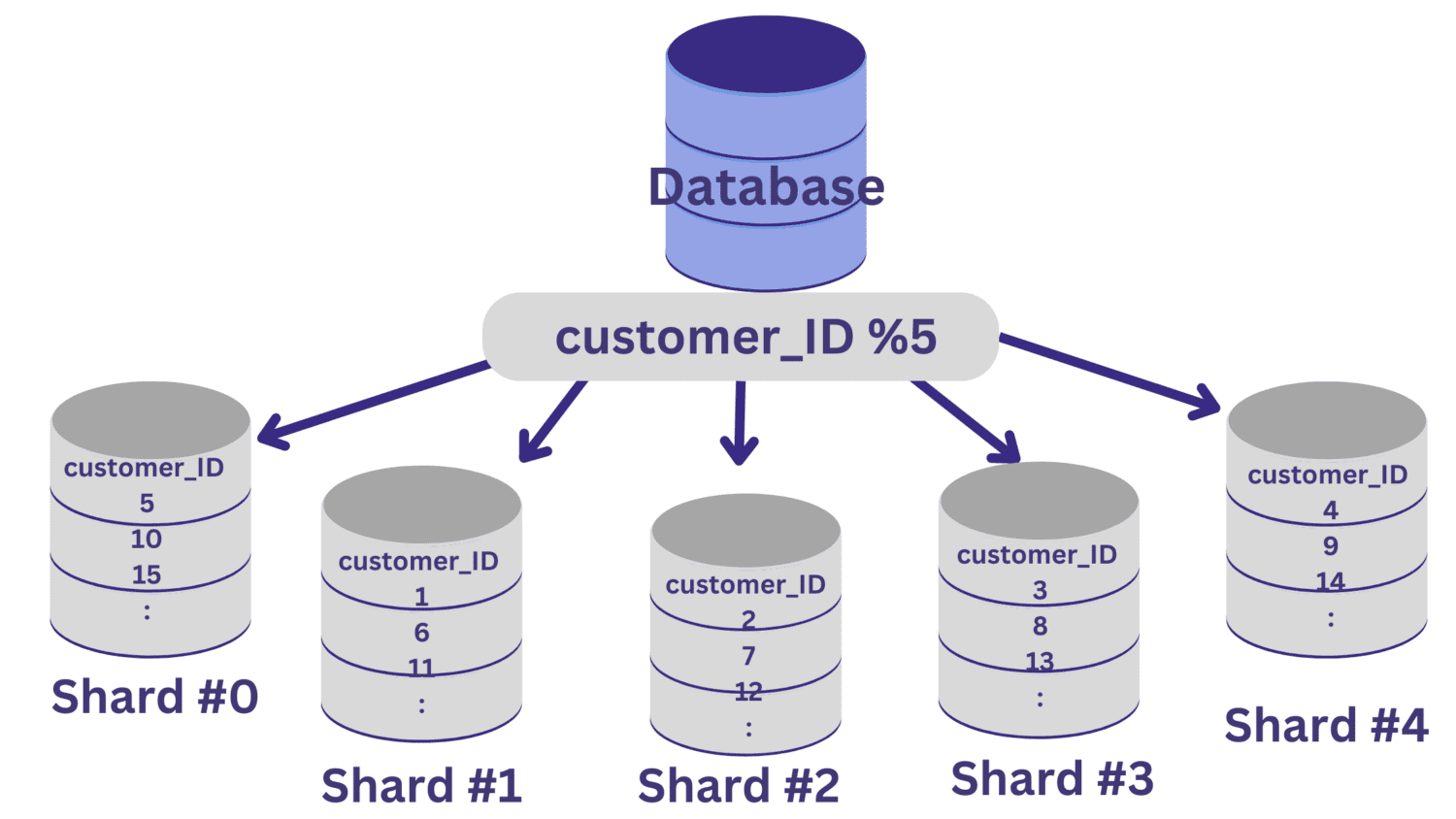
Після того, як сегментування бази даних реалізовано таким чином, важливо мати рівень маршрутизації, який направляє вхідні запити до правильного шарду бази даних.
Переваги шардингу бази даних
Ось деякі з переваг шардингу бази даних:
#1. Висока масштабованість
Завжди можна розділити більшу базу даних на кілька менших фрагментів. Таким чином, сегментування бази даних дозволяє нам масштабувати горизонтально.
#2. Висока доступність
Коли існує єдиний екземпляр сервера бази даних, який обробляє всі вхідні запити, у нас є єдина точка відмови. Якщо сервер бази даних не працює, вся програма не працює.
За допомогою сегментування бази даних ймовірність того, що всі сегменти бази даних не працюють у певний момент, відносно низька. Тому, якщо певний шард не працює, ми не зможемо обробити запити на читання до цього шарду. Але інші шарди можуть обробляти вхідні запити. Це призводить до високої доступності та підвищеної відмовостійкості.
Обмеження шардингу бази даних
Тепер давайте розглянемо деякі обмеження сегментування бази даних:
#1. Складність
Хоча шардинг має переваги з точки зору масштабованості та відмовостійкості, він ускладнює систему.
Від відображення записів до розділів до впровадження рівня маршрутизації для маршрутизації запитів до відповідних шардів, шардинг баз даних пов’язаний із значною складністю.
#2. Перешардинг
Іншим обмеженням шардингу є необхідність повторного шардингу.
Хоча ми використовуємо функцію хешування, щоб отримати рівномірний розподіл записів даних, можливо, що один із сегментів набагато більший за інші сегменти, і він може вичерпатися раніше. У цьому випадку ми повинні врахувати повторне шардинг (або перетасування), а це супроводжується значними накладними витратами.
#3. Виконання складних запитів
Коли вам потрібно запустити запити для аналізу, які включають об’єднання, вам потрібно використовувати записи з кількох шардів, а не з однієї бази даних. Тож це може бути проблемою, коли вам потрібно запустити забагато аналітичних запитів. Ви можете обійти це шляхом денормалізації баз даних, але це все одно вимагає певних зусиль!
Висновок
Давайте завершимо обговорення підсумком вивченого.
Масштабування апаратного забезпечення не завжди є оптимальним. Тому посилення екземпляра сервера не рекомендується. Ми також розглянули такі методи, як реплікація бази даних і горизонтальне розділення та їхні обмеження.
Потім ми дізналися, як працює сегментування бази даних, розділивши велику базу даних на менші шарди, якими легко керувати. Ми обговорювали, як слід ретельно вибирати ключ шардингу, щоб отримати рівномірні розділи, і необхідність рівня маршрутизації для маршрутизації вхідних запитів до правильного шарду бази даних.
Шардинг бази даних має такі переваги, як висока доступність і масштабованість. Деякі з недоліків включають складність налаштування шардингу та повторного шардингу, коли один або кілька сегментів вичерпуються.
Тож ви можете розглядати шардинг, якщо вважаєте, що переваги переважують складність, яку створює шардинг. Далі перегляньте порівняння різних реляційних баз даних AWS.