Scikit-LLM є Python-пакетом, який спрощує інтеграцію великих мовних моделей (LLM) в інфраструктуру scikit-learn. Він призначений для полегшення виконання завдань, пов’язаних з аналізом тексту. Якщо ви вже знайомі зі scikit-learn, то робота з Scikit-LLM буде для вас інтуїтивно зрозумілою.
Слід підкреслити, що Scikit-LLM не є заміною scikit-learn. Scikit-learn – це універсальна бібліотека машинного навчання, тоді як Scikit-LLM спеціалізується на завданнях текстового аналізу.
Початок роботи зі Scikit-LLM
Для початку роботи з Scikit-LLM, необхідно встановити бібліотеку та налаштувати ключ API. Для інсталяції бібліотеки відкрийте вашу IDE та створіть нове віртуальне середовище. Це допоможе уникнути можливих конфліктів версій бібліотек. Потім в терміналі виконайте наступну команду:
pip install scikit-llm
Ця команда встановить Scikit-LLM разом з усіма необхідними залежностями.
Для налаштування ключа API, його потрібно отримати у вашого провайдера LLM. Ось як можна отримати ключ API OpenAI:
Перейдіть на сторінку OpenAI API. Потім натисніть на іконку свого профілю, яка знаходиться у верхньому правому куті. З випадаючого меню виберіть “Переглянути ключі API”. Це переведе вас на сторінку ключів API.
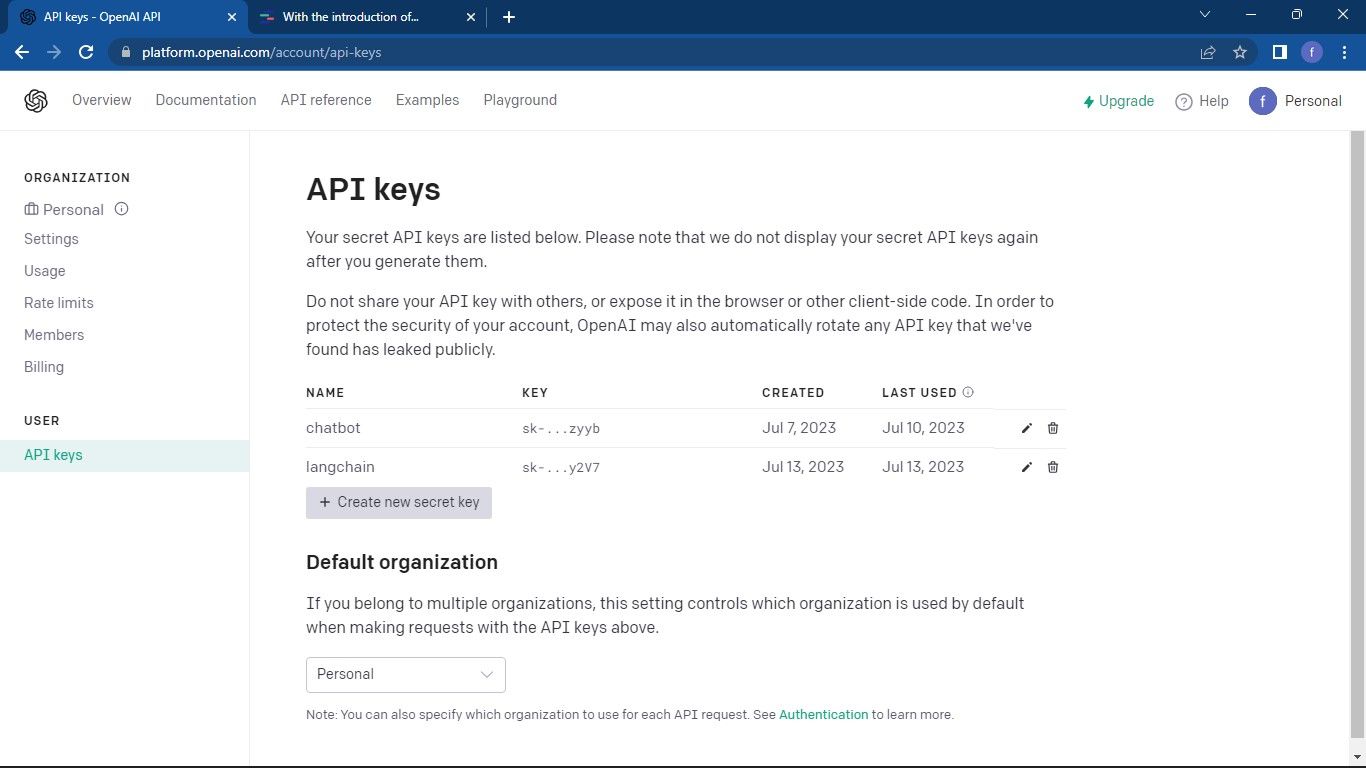
На сторінці ключів API натисніть кнопку “Створити новий секретний ключ”.
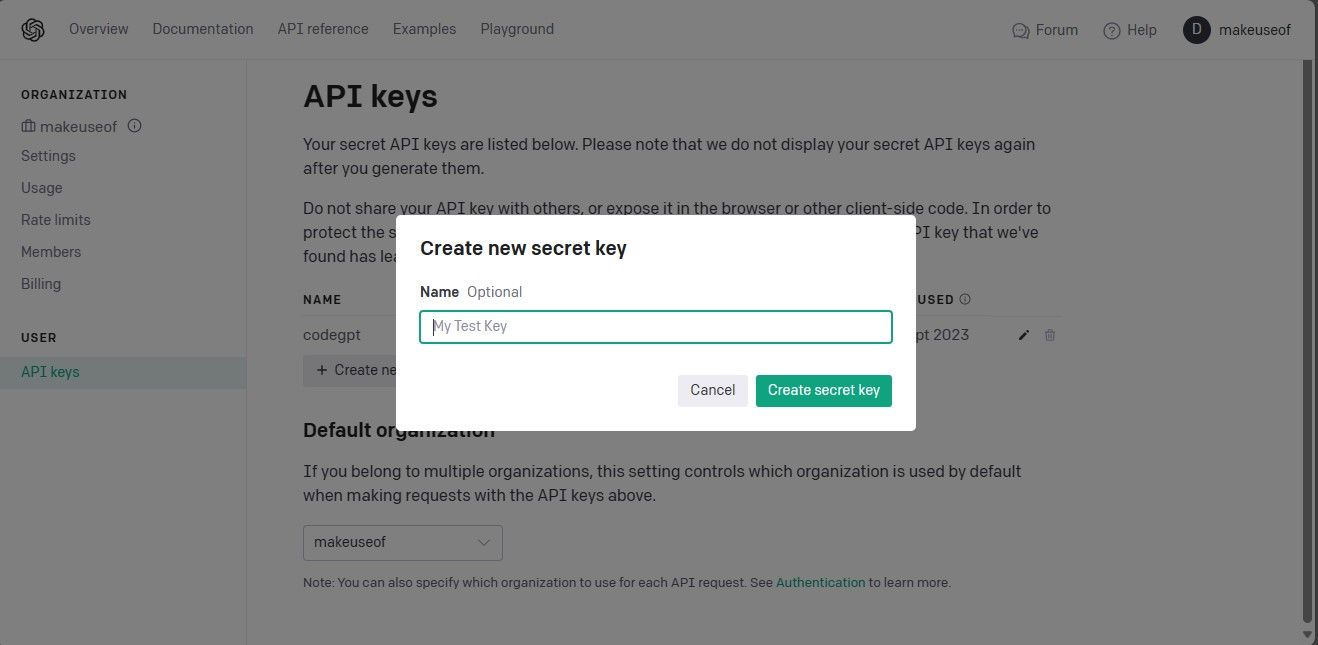
Дайте назву своєму ключу API і натисніть кнопку “Створити секретний ключ” для його генерації. Після створення необхідно скопіювати ключ і зберегти його в надійному місці, оскільки OpenAI більше не буде його показувати. У разі втрати, доведеться створити новий.
Тепер, коли ви маєте ключ API, відкрийте IDE та імпортуйте клас SKLLMConfig з бібліотеки Scikit-LLM. Цей клас призначений для налаштування параметрів конфігурації, пов’язаних з використанням великих мовних моделей.
from skllm.config import SKLLMConfig
Цей клас вимагає налаштування вашого ключа API OpenAI та ідентифікатора організації.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
Ідентифікатор організації не збігається з її назвою. Ідентифікатор організації є унікальним ідентифікатором вашої організації. Щоб отримати його, перейдіть на сторінку налаштувань організації OpenAI та скопіюйте його. Тепер ви встановили зв’язок між Scikit-LLM та великою мовною моделлю.
Scikit-LLM передбачає наявність платного плану для використання. Це зумовлено тим, що безкоштовний пробний обліковий запис OpenAI має обмеження на швидкість у три запити на хвилину, чого недостатньо для ефективної роботи Scikit-LLM.
Спроба використання безкоштовного пробного облікового запису призведе до помилки, подібної до наведеної нижче, під час аналізу тексту.

Щоб дізнатися більше про обмеження швидкості, відвідайте сторінку обмежень швидкості OpenAI.
Провайдери LLM не обмежуються тільки OpenAI. Ви можете використовувати й інші.
Імпортування необхідних бібліотек і завантаження набору даних
Імпортуйте pandas, який ви будете використовувати для завантаження набору даних. З Scikit-LLM та scikit-learn імпортуйте потрібні класи.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Далі завантажте набір даних, для якого ви хочете провести аналіз тексту. У цьому прикладі використовується набір даних фільмів IMDB. Однак, ви можете налаштувати його для роботи з власним набором даних.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Використання лише перших 100 рядків набору даних не є обов’язковим. Ви можете використовувати весь набір даних.
Потім витягніть ознаки та стовпці міток. Після цього розділіть ваш набір даних на навчальну та тестову вибірки.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Стовпець “Genre” містить мітки, які потрібно передбачити.
Класифікація тексту Zero-Shot за допомогою Scikit-LLM
Класифікація Zero-Shot – це функція, що надається великими мовними моделями. Вона класифікує текст за попередньо визначеними категоріями без необхідності у явному навчанні на розмічених даних. Ця можливість є дуже корисною у випадках, коли потрібно класифікувати текст за категоріями, які не були передбачені під час навчання моделі.
Для виконання Zero-Shot класифікації тексту за допомогою Scikit-LLM використовуйте клас ZeroShotGPTClassifier.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Результат виглядає наступним чином:
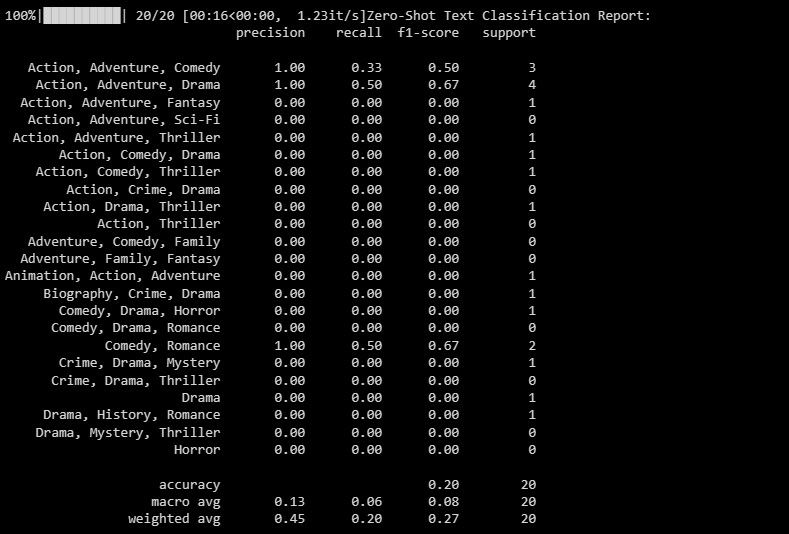
Звіт про класифікацію містить метрики для кожної мітки, яку намагається передбачити модель.
Класифікація тексту з кількома мітками Zero-Shot за допомогою Scikit-LLM
У деяких випадках один і той самий текст може належати до кількох категорій одночасно. Традиційні моделі класифікації не завжди можуть з цим впоратися. Scikit-LLM, з іншого боку, надає можливість проводити таку класифікацію. Класифікація тексту з кількома мітками є критично важливою для присвоєння кількох описових міток одному зразку тексту.
Використовуйте MultiLabelZeroShotGPTClassifier для передбачення відповідних міток для кожного зразка тексту.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
У наведеному вище коді ви визначаєте мітки-кандидати, до яких може належати ваш текст.
Вихід виглядає наступним чином:
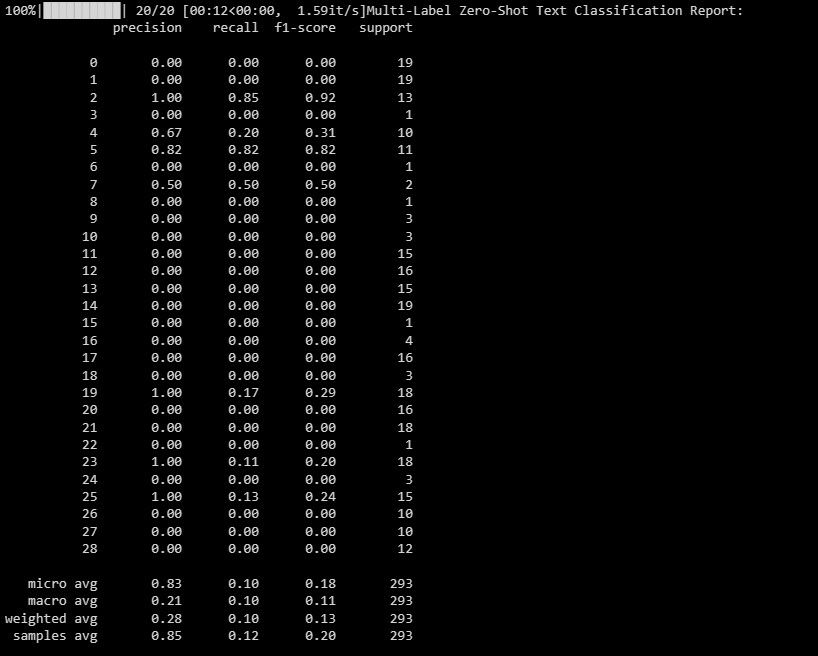
Цей звіт допоможе вам зрозуміти, наскільки добре ваша модель працює для кожної мітки при класифікації за кількома мітками.
Векторизація тексту за допомогою Scikit-LLM
У векторизації тексту текстові дані перетворюються на числовий формат, який можуть розуміти моделі машинного навчання. Scikit-LLM пропонує для цього GPTVectorizer. Він дозволяє перетворювати текст у вектори фіксованої розмірності з використанням моделей GPT.
Цього можна досягти за допомогою підходу TF-IDF (Term Frequency-Inverse Document Frequency).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Ось результат:
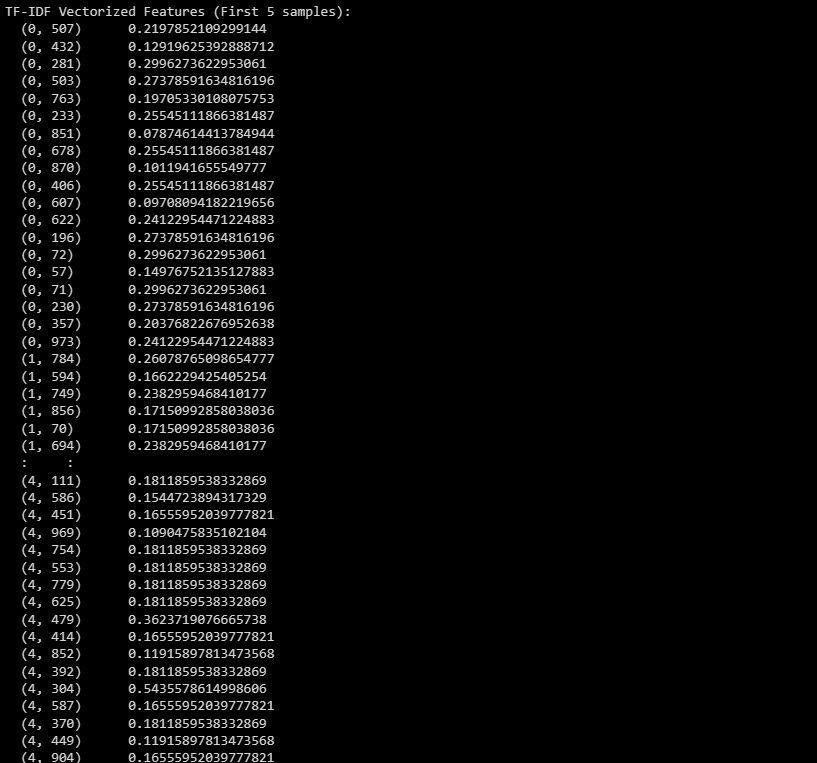
Результат представляє векторизовані функції TF-IDF для перших 5 зразків у наборі даних.
Резюмування тексту за допомогою Scikit-LLM
Резюмування тексту допомагає стиснути фрагмент тексту, зберігаючи його найважливішу інформацію. Scikit-LLM пропонує GPTSummarizer, який використовує моделі GPT для створення стислих резюме тексту.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Результат виглядає наступним чином:
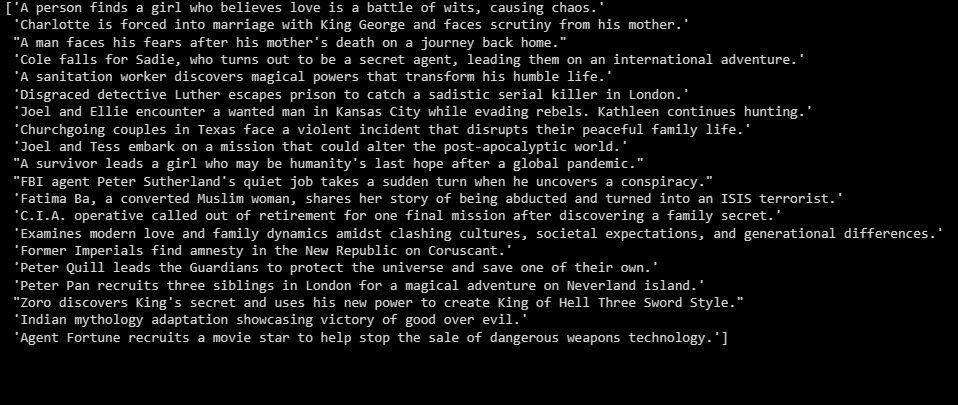
Вище наведено зведення даних тестової вибірки.
Створюйте програми на основі LLM
Scikit-LLM відкриває широкий спектр можливостей для аналізу тексту за допомогою великих мовних моделей. Розуміння принципів роботи великих мовних моделей є важливим. Це допоможе вам зрозуміти їх сильні та слабкі сторони, що, в свою чергу, допоможе вам створювати ефективні програми на основі цієї передової технології.