Шардинг баз даних – це підхід, що дозволяє досягти горизонтального масштабування в складних системах.
У більшості реальних систем використовується сервер баз даних, який обробляє велику кількість запитів на зчитування та обмежену кількість запитів на запис. Це може призвести до перевантаження сервера та сповільнення роботи системи.
Для покращення продуктивності та зменшення навантаження на сервер існують такі методи, як реплікація та шардинг баз даних. У цьому матеріалі ми розглянемо різні підходи до підвищення ефективності системи, зокрема:
- Масштабування серверного обладнання для баз даних
- Реплікація даних
- Розподіл даних по горизонталі
Після ознайомлення з цими методами ми детально розглянемо принцип роботи шардингу баз даних, а також його переваги та обмеження.
Розпочнемо!
Способи підвищення ефективності системи
Розглянемо способи покращення продуктивності системи у випадку виникнення перевантаження сервера баз даних:
#1. Розширення можливостей сервера баз даних
Збільшення потужності сервера баз даних може здатися простим рішенням для підвищення продуктивності системи. Цей метод включає збільшення обчислювальних можливостей, додавання оперативної пам’яті тощо.
Проте цей підхід має певні обмеження. Неможливо мати сервер з необмеженою пам’яттю та обчислювальною потужністю. Крім того, після досягнення певної межі, подальше розширення потужностей сервера приносить все меншу віддачу.
#2. Реплікація баз даних
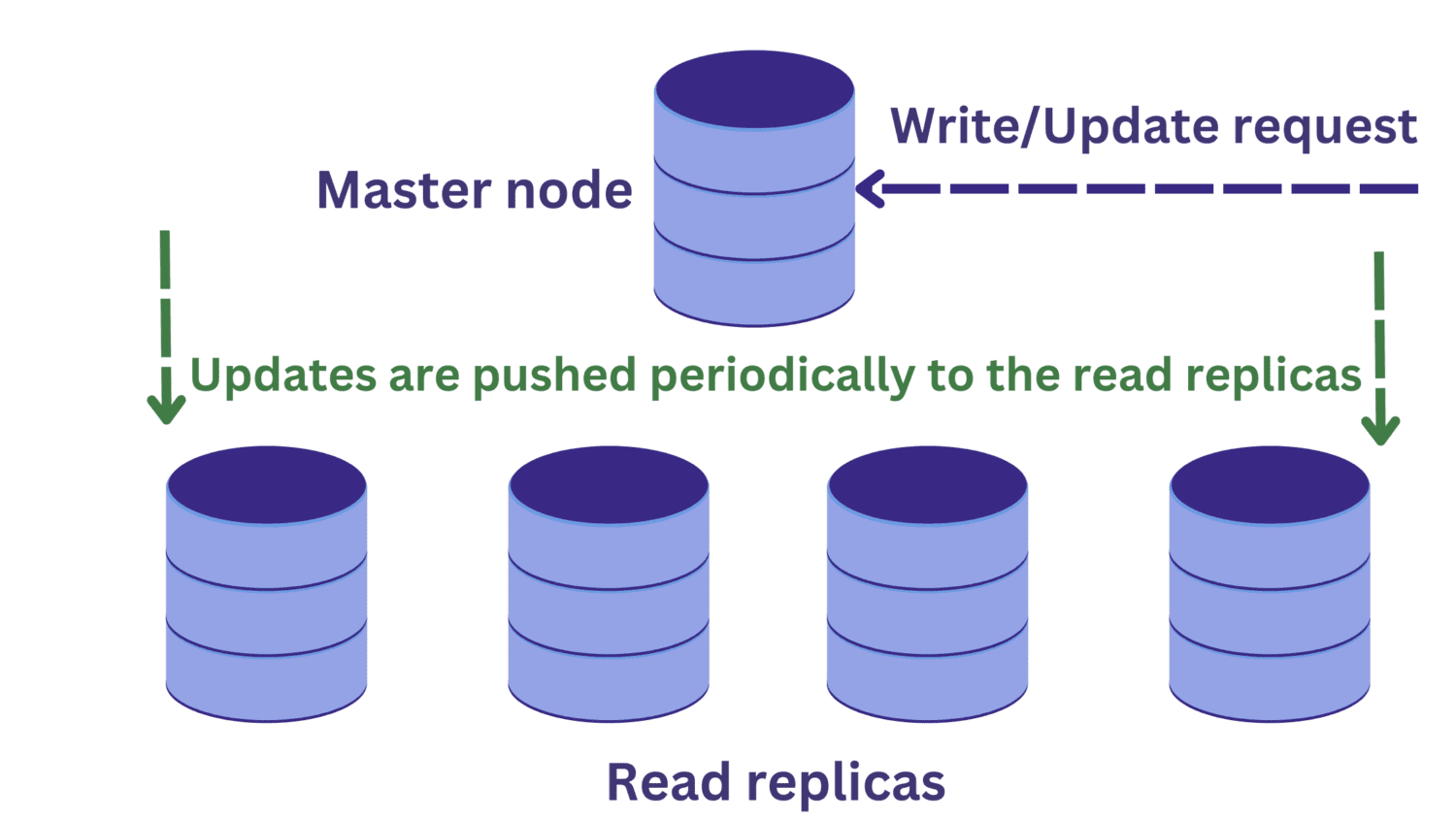
Якщо сервер баз даних перевантажений вхідними запитами, можна використовувати реплікацію баз даних.
У реплікації баз даних існує один головний вузол, який приймає запити на запис. Крім того, є декілька реплік для читання.
Це покращує доступність і зменшує навантаження на систему. Тепер можна обробляти декілька запитів паралельно, оскільки запити на читання можуть бути перенаправлені на одну з реплік.
Однак, це породжує іншу проблему. Запити на запис до головного вузла можуть змінювати дані, і ці зміни згодом переносяться на репліки.
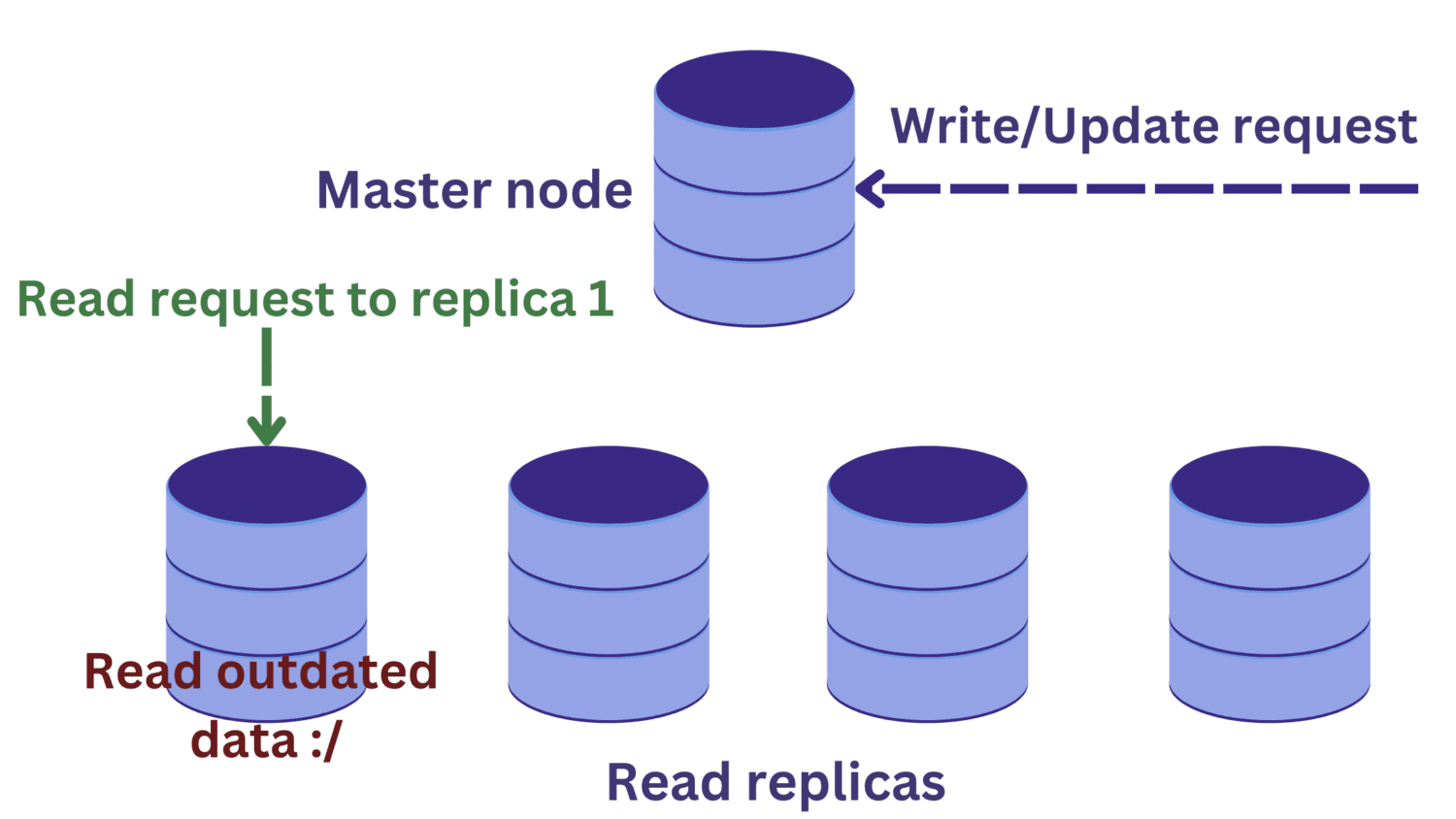
Наприклад, якщо запит на читання надходить на одну з реплік одночасно з операцією запису на головному вузлі,
зміни, внесені на головному вузлі, ще не будуть відображені на репліках. У такому випадку ми можемо отримати застарілі дані, що є небажаним.
#3. Горизонтальний поділ
Горизонтальний поділ – це ще один метод оптимізації продуктивності системи. Можлива ситуація, коли є одна велика таблиця з мільярдами рядків (наприклад, таблиця клієнтів або транзакцій).
Зчитування з такої таблиці буде повільним. Але за допомогою горизонтального поділу, одна велика таблиця розподіляється на кілька розділів (або менших таблиць), з яких можна зчитувати. Реляційні бази даних, такі як PostgreSQL, підтримують подібний поділ.
Проте, всі розділи все ще розташовані на одному сервері. Різниця полягає лише в тому, що тепер ми зчитуємо дані з розділів, а не з однієї великої таблиці.
Таким чином, при збільшенні кількості вхідних запитів сервер може не впоратися зі збільшеним навантаженням.
Як працює шардинг баз даних?
Після розгляду методів підвищення продуктивності системи та їх обмежень, давайте з’ясуємо, як працює шардинг баз даних.
У шардингу ми розбиваємо одну велику базу даних на декілька менших, кожна з яких працює на окремому сервері. Кожна така база даних називається шардом. Кожен шард містить унікальну підмножину даних.
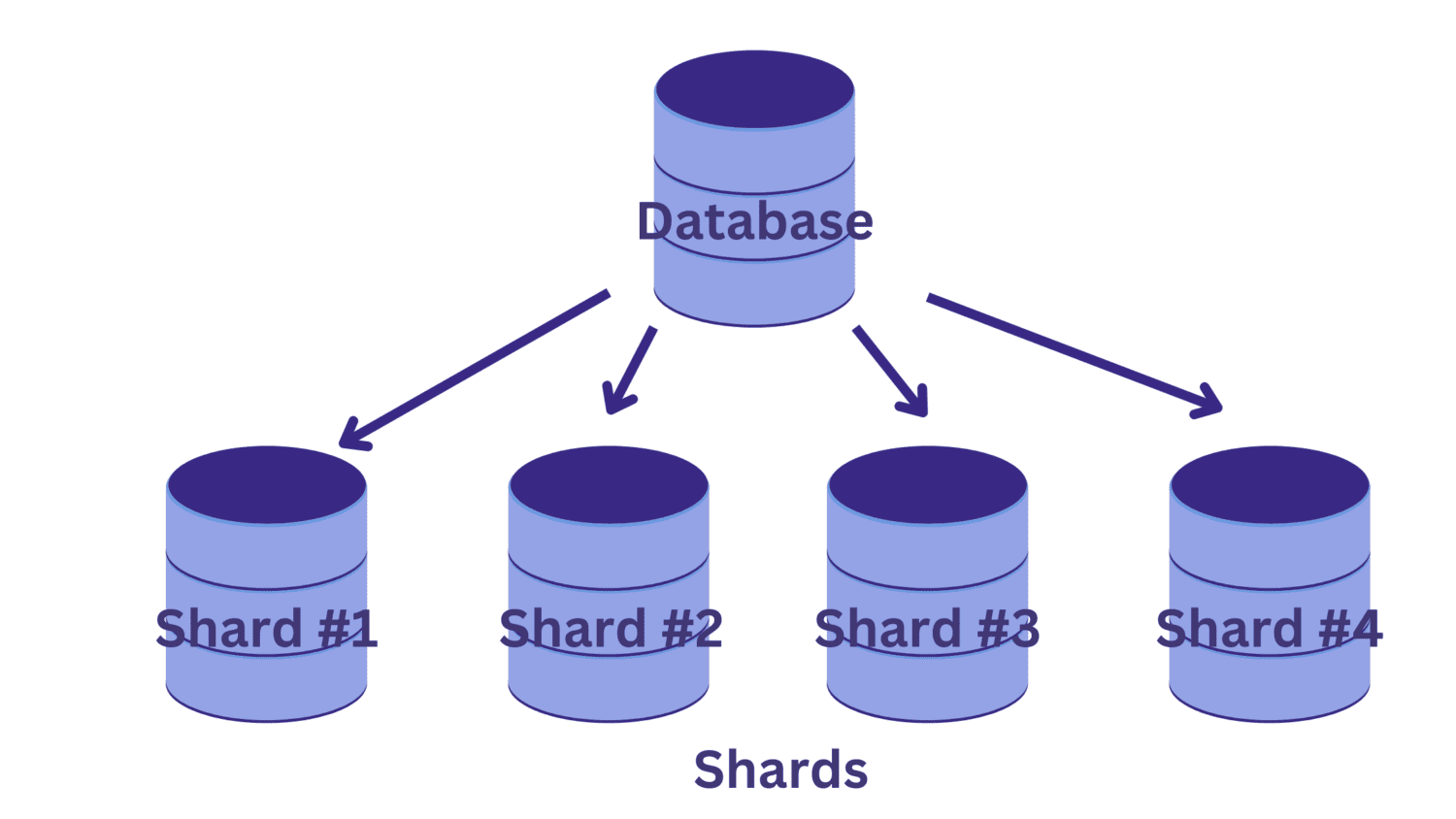
Як база даних поділяється на шарди? І як визначити, який рядок потрапляє до якого шарду?
🔑 Тут застосовується ключ шардингу.
Розуміння ключа шардингу
Розглянемо детальніше роль ключа шардингу.
Ключ шардингу, який зазвичай є стовпцем (або комбінацією стовпців) у таблиці, має бути обраний таким чином, щоб дані рівномірно розподілялися між шардамі. Неприпустимо, щоб один шард був значно більший за інші.
У базі даних, яка зберігає інформацію про клієнтів і транзакції, `customer_ID` може бути вдалим ключем для сегментування.
Після вибору ключа, потрібно визначити функцію хешування, яка визначатиме, який рядок потрапляє до якого шарду.
Припустимо, нам потрібно розділити базу даних на п’ять шардів (шард №0 – шард №4), використовуючи `customer_ID` як ключ. У такому випадку простою функцією хешування може бути `customer_ID % 5`.
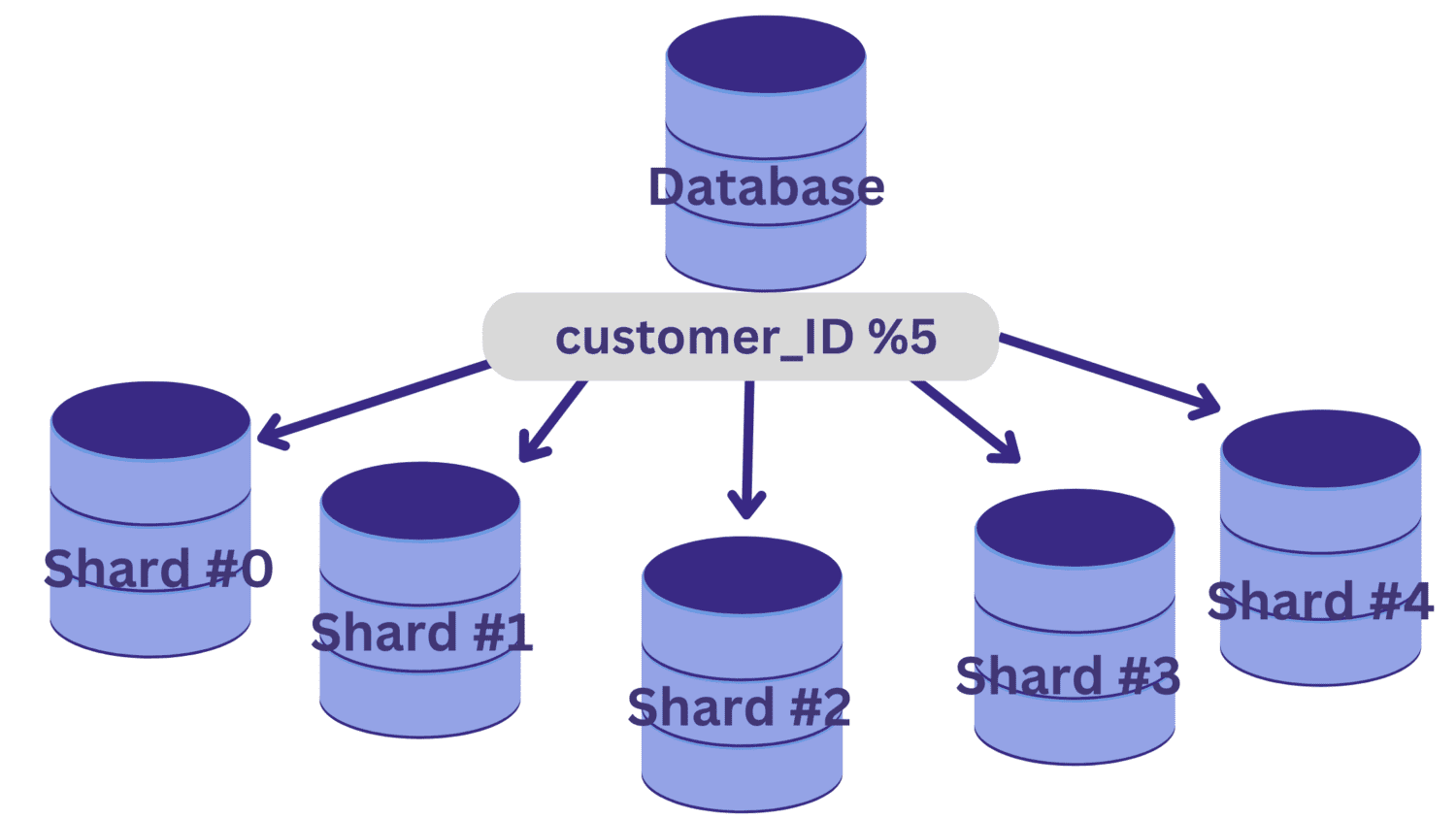
Усі значення `customer_ID`, які при діленні на 5 дають остачу 0, потраплять на шард №0. Значення, які дають остачу від 1 до 4, потраплять відповідно на шарди №1-№4.
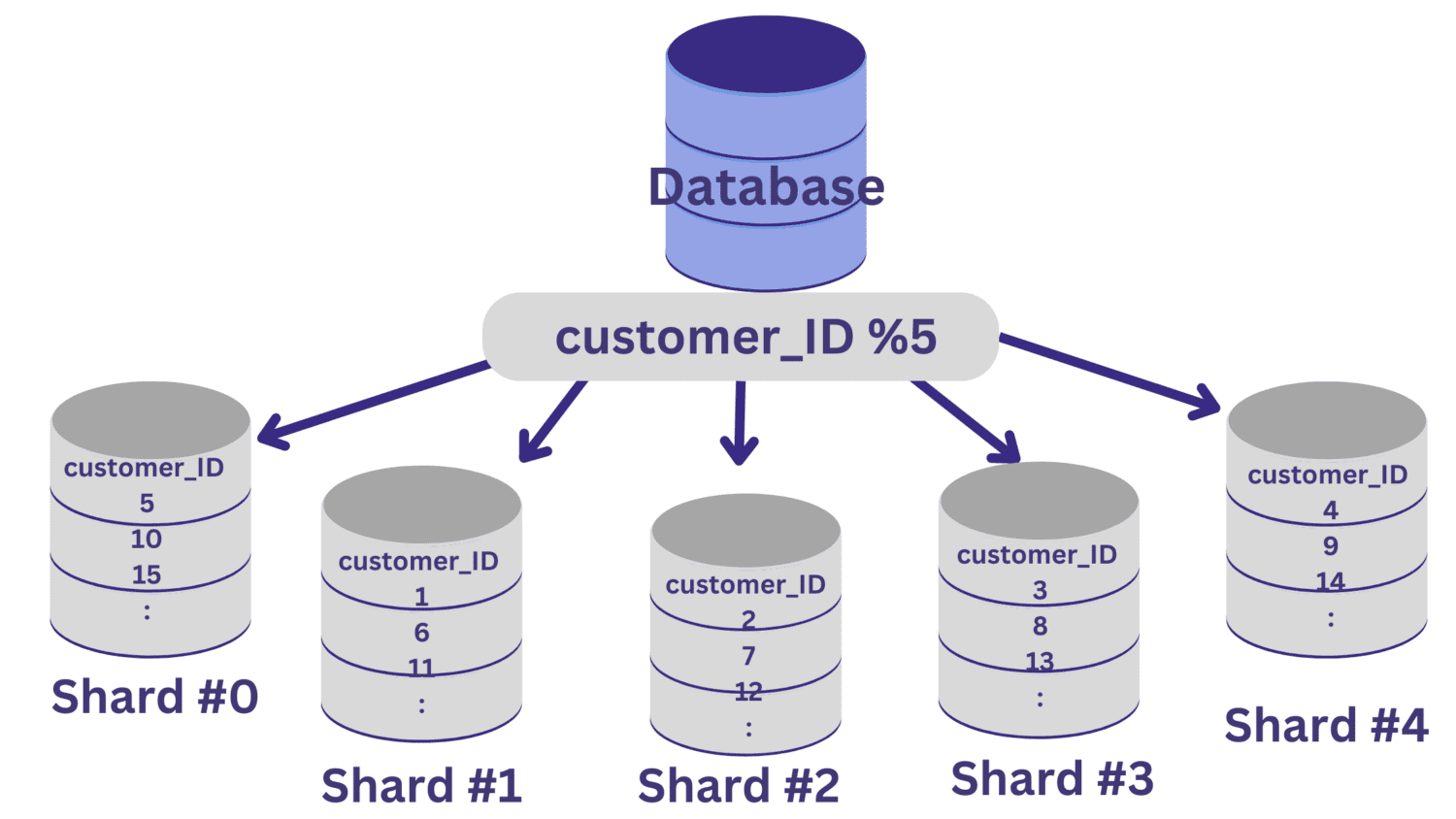
Після реалізації шардингу необхідно мати рівень маршрутизації, який направлятиме вхідні запити на відповідний шард.
Переваги шардингу баз даних
Розглянемо деякі переваги шардингу:
#1. Висока масштабованість
Завжди можна розділити більшу базу даних на декілька менших шардів. Таким чином, шардинг дозволяє досягти горизонтального масштабування.
#2. Висока доступність
Коли всі запити обробляються одним сервером, виникає єдина точка відмови. Якщо сервер виходить з ладу, вся програма стає недоступною.
При шардингу ймовірність того, що всі шарди одночасно вийдуть з ладу, є відносно низькою. Якщо один шард не працює, ми не зможемо обробляти запити до цього шарду, але інші шарди продовжуватимуть працювати. Це забезпечує високу доступність і стійкість до відмов.
Обмеження шардингу баз даних
Тепер розглянемо деякі обмеження шардингу:
#1. Складність
Хоча шардинг має переваги з точки зору масштабованості та відмовостійкості, він ускладнює систему.
Від відображення записів до шардів до впровадження рівня маршрутизації, шардинг баз даних пов’язаний зі значною складністю.
#2. Перешардинг
Інше обмеження – необхідність перешардингу.
Навіть якщо функція хешування забезпечує рівномірний розподіл даних, можливо, що один із шардів стане набагато більшим за інші. У такому випадку потрібен перешардинг, що вимагає значних зусиль.
#3. Виконання складних запитів
Аналітичні запити, які використовують об’єднання даних з декількох шардів, можуть бути проблематичними. Можна використовувати денормалізацію, але це також вимагає певних зусиль.
Висновок
Підсумуємо розглянуту інформацію.
Масштабування апаратного забезпечення не завжди є оптимальним рішенням. Ми розглянули такі методи як реплікація та горизонтальний поділ, і їх обмеження.
Ми дізналися, як працює шардинг: розділення великої бази даних на менші шарди, якими легше керувати. Важливим є вибір ключа шардингу для рівномірного розподілу даних і використання рівня маршрутизації для перенаправлення запитів.
Шардинг баз даних має переваги, такі як висока доступність і масштабованість. До недоліків належать складність налаштування та перешардингу.
Шардинг можна використовувати, якщо його переваги перевищують складність, яку він створює. Далі ви можете розглянути порівняння різних реляційних баз даних AWS.