Збір Даних з Веб-сайтів: Методи та Інструменти
Видобуток інформації з інтернет-сторінок – це процес отримання певних даних із веб-сайтів. Користувачі можуть збирати різноманітну інформацію, включаючи текстовий контент, зображення, відеоматеріали, відгуки споживачів, характеристики товарів та інше. Зібрані дані використовуються для проведення маркетингових досліджень, аналізу громадської думки, дослідження конкурентів та зведення статистичних даних.
Для невеликих обсягів інформації, видобування можна здійснювати вручну, копіюючи необхідні дані з веб-сторінок в електронні таблиці або текстові документи. Наприклад, якщо покупець шукає відгуки про продукт для прийняття рішення про покупку, він може вручну збирати цю інформацію.
Однак, при роботі з великими обсягами даних необхідні автоматизовані методи. Можна розробити власне рішення для видобутку або скористатися API проксі-серверів або API скрапінгу.
Важливо зазначити, що ці методи можуть бути менш ефективними через захист веб-сайтів від автоматичних запитів за допомогою капчі. Також може знадобитися управління ботами та проксі, що потребує додаткових зусиль і обмежує обсяг даних, які можна отримати.
Браузер для Веб-Скрапінгу: Ефективне Рішення
Інноваційним рішенням для подолання цих викликів є Scraping Browser від Bright Data. Це універсальний інструмент для збору даних з веб-сайтів, які важко піддаються видобуванню. Він працює як браузер з графічним інтерфейсом (GUI), керований API Puppeteer або Playwright, що дозволяє залишатися непомітним для ботів.
Scraping Browser має вбудовані функції розблокування, які автоматично обробляють всі перешкоди, такі як капча, блокування доступу та відбитки браузера. Браузер працює на серверах Bright Data, що означає, що не потрібно створювати власну інфраструктуру для масштабних проєктів зі збору даних.
Ключові Характеристики Scraping Browser від Bright Data
- Автоматичне Розблокування Веб-сайтів: Браузер автоматично адаптується до нових блокувань, перевірок CAPTCHA, відбитків браузера та повторних спроб, імітуючи дії реального користувача.
- Розгалужена Мережа Проксі-Серверів: Завдяки понад 72 мільйонам IP-адрес, ви можете збирати дані з будь-якої країни, обираючи міста або навіть операторів, використовуючи передові технології.
- Масштабованість: Можливість одночасного відкриття тисяч сеансів браузера, що забезпечується інфраструктурою Bright Data, дозволяє обробляти великі обсяги запитів.
- Сумісність з Puppeteer та Playwright: Інтеграція з API Puppeteer (Python) та Playwright (Node.js) для керування сеансами браузера та отримання даних.
- Економія Часу та Ресурсів: Браузер автоматично керує проксі-серверами, усуваючи необхідність у налаштуванні складної інфраструктури.
Інструкція з Налаштування Scraping Browser
- Перейдіть на офіційний веб-сайт Bright Data та оберіть Scraping Browser у розділі “Scraping Solutions”.
- Створіть обліковий запис, вибравши безкоштовну пробну версію або зареєструвавшись через Google.
- Після реєстрації на панелі керування оберіть “Проксі та інфраструктура копіювання”.
- У вікні, що відкриється, виберіть Scraping Browser та натисніть “Почати”.
- Збережіть налаштування та активуйте їх.
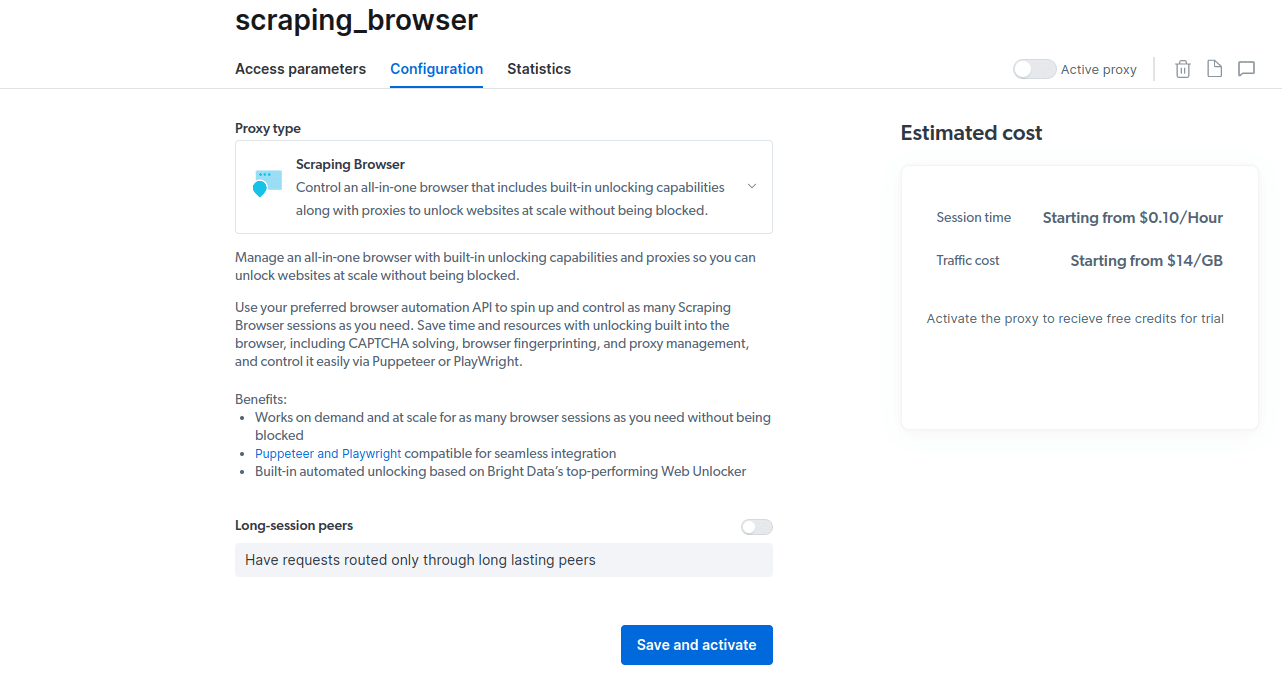
- Активуйте безкоштовну пробну версію, вибравши варіант з $5 кредитом або варіант з $50 кредитом за умови поповнення рахунку на $50.
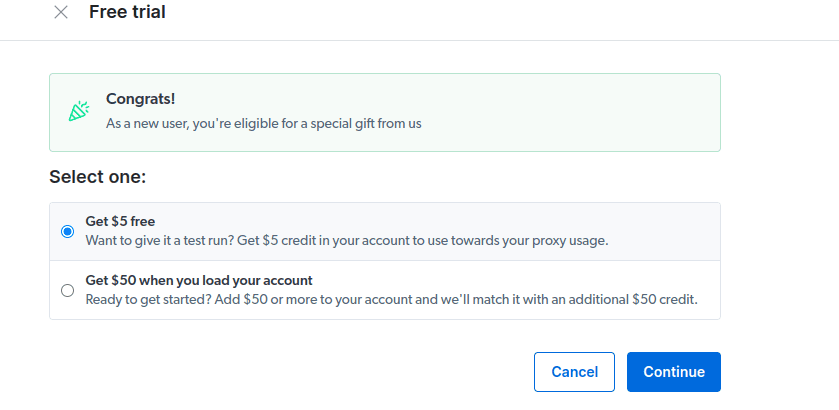
- Введіть платіжну інформацію. Платіжні дані використовуються для підтвердження, що ви новий користувач і не створюєте декілька облікових записів для отримання безкоштовного кредиту.
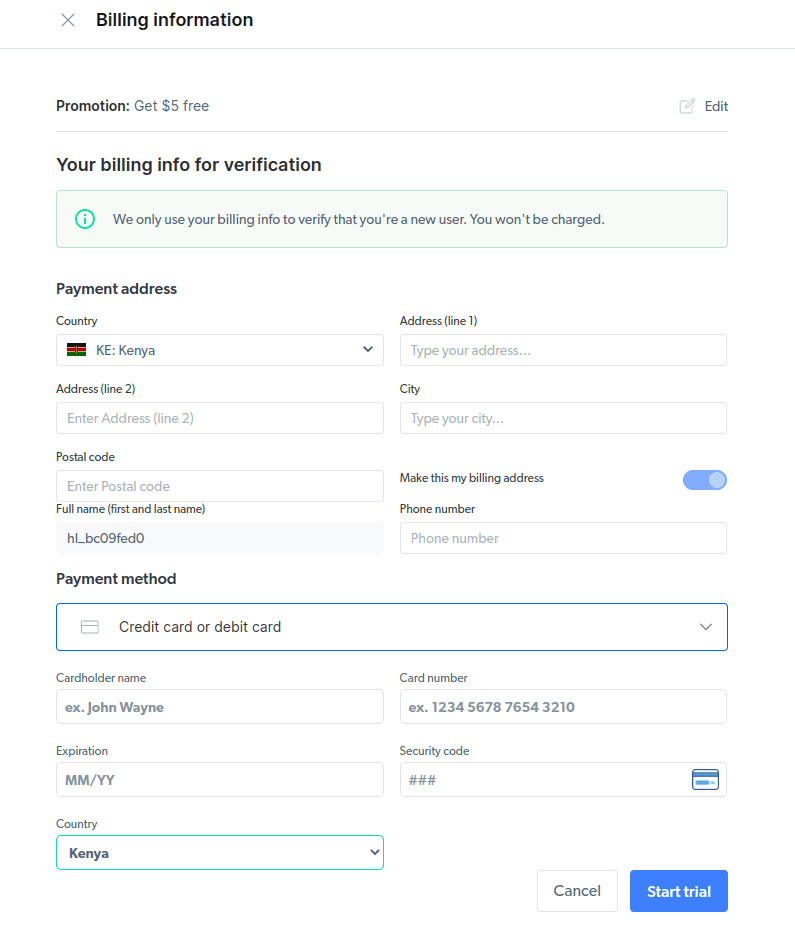
- Створіть новий проксі-сервер, вибравши “Проксі-сервер” як “Тип проксі”.
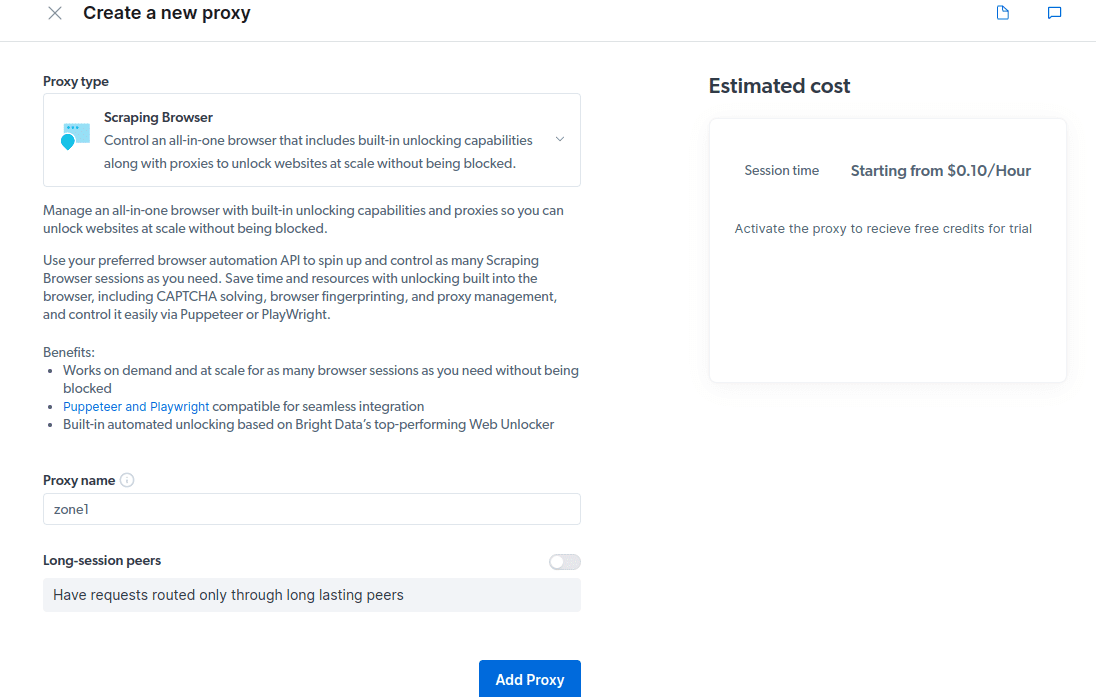
- Створіть нову “зону”, підтвердивши відповідний запит.
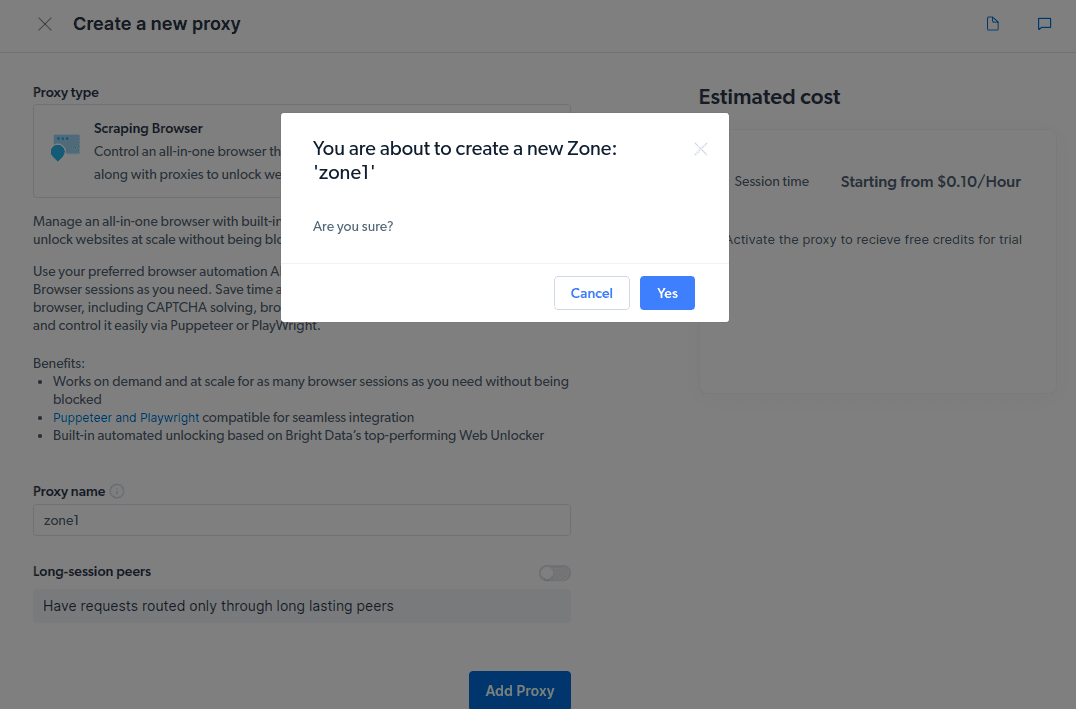
- Ознайомтесь з прикладами інтеграції проксі-сервера, які можна використовувати для збору даних з цільового веб-сайту за допомогою Node.js або Python.
Тепер ви готові до збору даних. На прикладі веб-сайту techukraine.net.com продемонструємо роботу Scraping Browser, використовуючи node.js.
- Створіть новий проєкт, наприклад, script.js, на локальному комп’ютері.
- Відкрийте проєкт у текстовому редакторі, наприклад, VsCode.
- Встановіть puppeteer за допомогою команди: npm i puppeteer-core
- Додайте наступний код до файлу script.js:
const puppeteer = require('puppeteer-core');
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
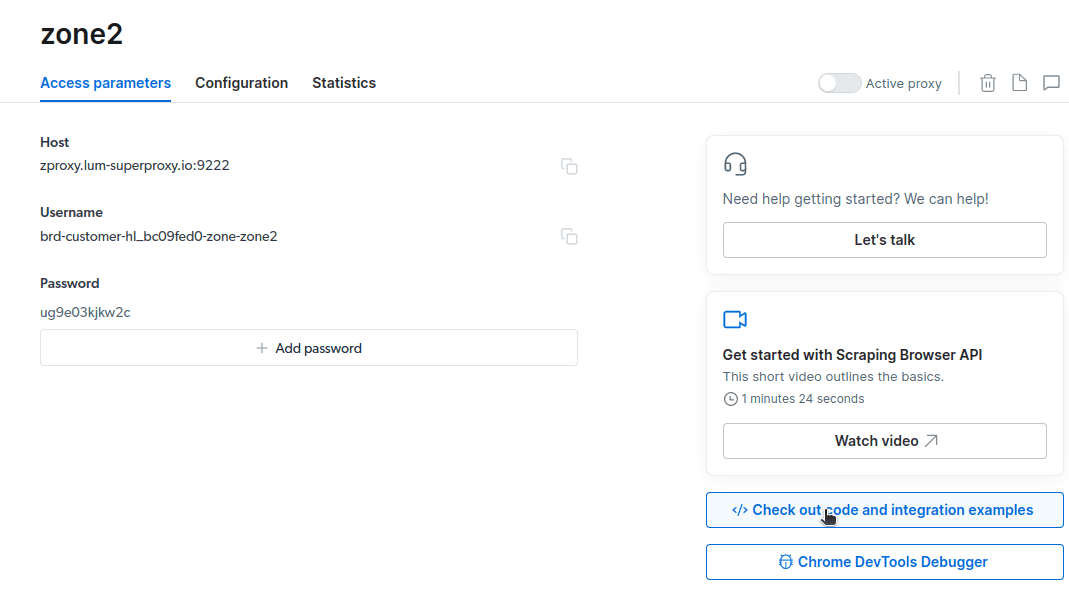
- Замініть `USERNAME:PASSWORD` на дані вашого облікового запису, зокрема, ім’я користувача, назву зони та пароль, які можна знайти у вкладці “Параметри доступу”.
- Вкажіть цільову URL-адресу для збору даних. Наприклад, для збору даних про авторів на techukraine.net.com, вкажіть: https://techukraine.net.com/authors/.
Оновлений код буде мати наступний вигляд:
const puppeteer = require('puppeteer-core');
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://techukraine.net.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
- Запустіть код за допомогою команди: `node script.js`.
Результат виконання коду буде відображено в терміналі.
Експорт Зібраних Даних
Існує декілька способів експорту даних, залежно від їх подальшого використання. Наприклад, можна експортувати дані у файл HTML, змінивши сценарій на створення файлу `data.html` замість виведення на консоль. Для цього змінимо код на наступний:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://techukraine.net.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
- Запустіть код за допомогою команди: `node script.js`.
Після виконання, в терміналі з’явиться повідомлення “Data export complete”.
У папці проєкту з’явиться файл `data.html`, який міститиме HTML-код веб-сторінки.
Це лише базовий приклад використання Scraping Browser. За допомогою цього інструменту можна збирати дані різного типу, такі як текст, зображення, відео, метадані та посилання, в залежності від структури веб-сайту.
Поширені Питання
Чи є видобуток даних та веб-скрапінг законними?
Законність видобутку даних залежить від характеру зібраної інформації та політики веб-сайту. Збір персональних даних, таких як адреси або фінансова інформація, вважається незаконним. Завжди перевіряйте умови використання веб-сайту та переконайтесь, що ви не збираєте дані, які не є загальнодоступними.
Чи є Scraping Browser безкоштовним інструментом?
Scraping Browser – платний сервіс. Безкоштовна пробна версія надає кредит у розмірі $5. Платні тарифи починаються від $15/ГБ + $0,1/год, також доступна опція “Pay As You Go”, від $20/ГБ + $0,1/год.
Яка різниця між Scraping Browser та безголовими браузерами?
Scraping Browser – це повноцінний браузер з графічним інтерфейсом. Безголові браузери, як Selenium, використовуються для автоматизації веб-скрапінгу, але іноді вони стикаються з обмеженнями, такими як капча та виявлення ботів.
Підсумки
Scraping Browser спрощує процес збору даних з веб-сайтів. Він простіший у використанні, ніж інші інструменти, такі як Selenium. Інтуїтивно зрозумілий інтерфейс та якісна документація роблять його доступним навіть для користувачів без досвіду розробки. Інструмент має можливості розблокування, що робить його ефективним для автоматизації збору даних.
Також, ви можете дізнатися, як запобігти плагінам ChatGPT копіювати контент з вашого веб-сайту.