З плином часу популярність Python у сфері обробки даних нестримно зростає, і ця тенденція зберігається щодня.
Наука про дані – це розгалужена сфера досліджень із численними піднапрямками. Серед них аналіз даних є, безсумнівно, одним з ключових. Незалежно від рівня вашої кваліфікації в цій галузі, стає все важливішим мати хоча б базове розуміння аналізу даних.
Що таке аналіз даних?
Аналіз даних — це процес очищення та трансформації великих обсягів неструктурованої інформації з метою виявлення ключових інсайтів та закономірностей, які допомагають приймати обґрунтовані рішення.
Існує різноманітний інструментарій для аналізу даних, включаючи Python, Microsoft Excel, Tableau, SaS тощо. У цій статті ми зосередимося на тому, як аналіз даних здійснюється за допомогою Python, зокрема, з використанням бібліотеки під назвою Pandas.
Що таке Pandas?
Pandas – це бібліотека Python з відкритим вихідним кодом, призначена для маніпулювання та обробки даних. Вона відрізняється високою швидкістю та ефективністю, а також має інструменти для завантаження різних типів даних у пам’ять. Pandas дозволяє змінювати структуру, розбивати, індексувати та групувати дані.
Структури даних у Pandas
Pandas оперує трьома основними структурами даних:
| Series | DataFrame | Panel |
Ці структури можна розглядати як вкладені одна в одну. DataFrame є набором Series, а Panel – набором DataFrame.
Series — це одновимірний масив даних.
Поєднання кількох Series утворює двовимірний DataFrame.
Зібрання декількох DataFrame формує тривимірну Panel.
Найчастіше в роботі використовується двовимірна структура DataFrame, яка є стандартною для представлення багатьох наборів даних.
Аналіз даних з використанням Pandas
Для практичних завдань цієї статті додаткове встановлення програмного забезпечення не потрібне. Ми будемо використовувати онлайн-інструмент Colab, розроблений Google. Це онлайн-середовище Python, призначене для аналізу даних, машинного навчання та штучного інтелекту. По суті, це хмарний блокнот Jupyter з попередньо встановленими пакетами Python, необхідними для дослідника даних.
Перейдіть за посиланням: https://colab.research.google.com/notebooks/intro.ipynb. Ви побачите наступне.
У верхній лівій частині навігаційної панелі виберіть “Файл” та “Новий блокнот”. У вашому браузері відкриється нова сторінка блокнота Jupyter. Першим кроком є імпорт бібліотеки pandas у наше робоче середовище, що здійснюється за допомогою наступного коду:
import pandas as pd
У цій статті ми будемо використовувати набір даних про ціни на житло для нашого аналізу. Завантажити його можна тут. Перше, що потрібно зробити, це завантажити цей набір даних у наше середовище.
Це можна зробити за допомогою наступного коду у новій клітинці:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media&token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')
Функція `.read_csv` використовується для читання файлу CSV, а параметр `sep` вказує, що розділювачем між даними є кома.
Завантажений файл CSV зберігається у змінній `df`.
У Jupyter Notebook не потрібно використовувати функцію `print()`. Можна просто ввести ім’я змінної у клітинку, і Jupyter Notebook виведе її вміст.
Спробуйте ввести `df` у нову клітинку та запустіть її. Ви побачите, що всі дані з набору відобразяться у форматі DataFrame.
Проте, не завжди потрібно переглядати всі дані. Іноді достатньо переглянути перші кілька рядків та назви стовпців. Для цього використовуються функції `df.head()` (для перших п’яти рядків) та `df.tail()` (для останніх п’яти). Ось як виглядає результат їхньої роботи:
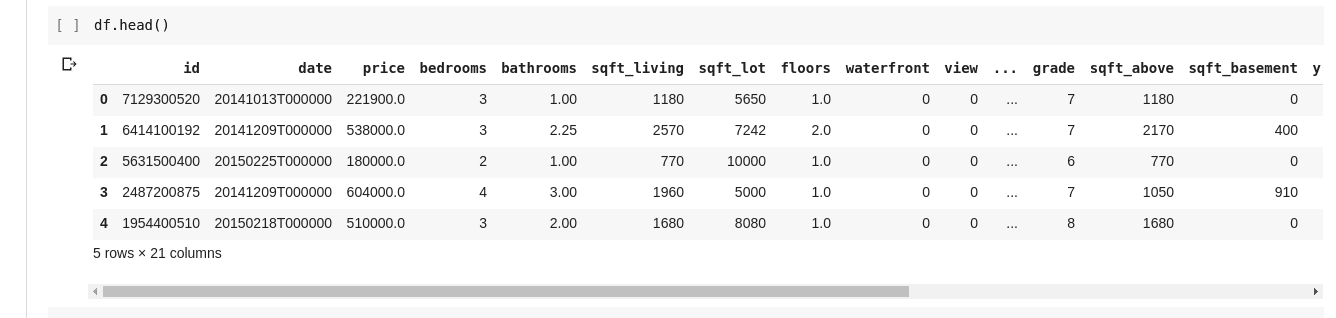
Функція `.describe()` дозволяє перевірити залежності між рядками та стовпцями даних. Вона повертає статистичні характеристики набору даних.
Виконання `df.describe()` дає наступний результат:
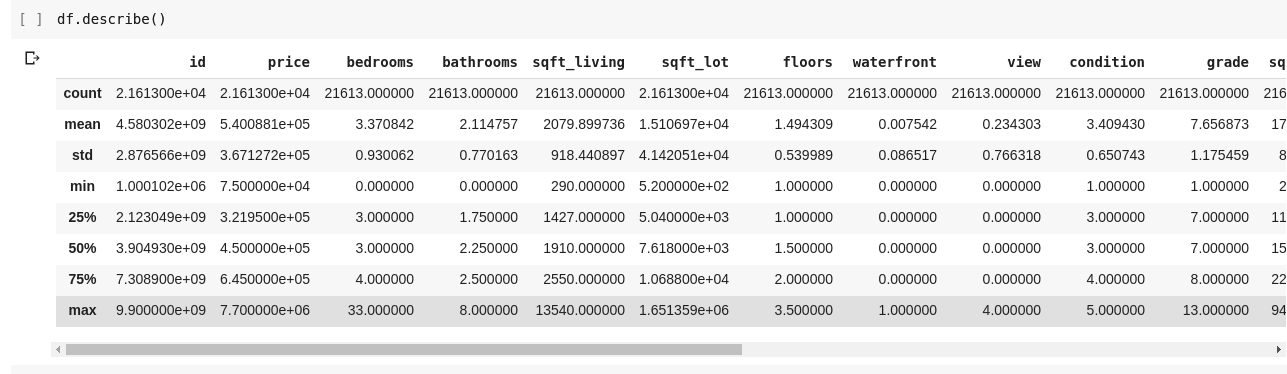
Ми бачимо, що `.describe()` надає середнє значення, стандартне відхилення, мінімальне, максимальне значення та процентилі для кожного стовпця DataFrame. Це дуже корисна інформація.
Для отримання інформації про кількість рядків та стовпців у DataFrame можна скористатися `df.shape`. Ця функція повертає кортеж у форматі (рядки, стовпці).
Список назв стовпців можна переглянути за допомогою `df.columns`.
Щоб виділити окремий стовпець, можна використовувати синтаксис, аналогічний до доступу до елементів словника. Наприклад, наступний код:
df['price ']
поверне стовпець з цінами. Можна зберегти його в окрему змінну:
price = df['price']
Тепер зі змінною `price` можна виконувати ті ж дії, що й з DataFrame, адже це його підмножина. Можна застосовувати такі функції, як `df.head()`, `df.shape` тощо.
Для вибору декількох стовпців потрібно передати список їхніх назв у `df`:
data = df[['price ', 'bedrooms']]
Цей код вибере стовпці “ціна” та “кількість спалень”. Якщо ввести `data.head()` у нову клітинку, результат буде наступним:
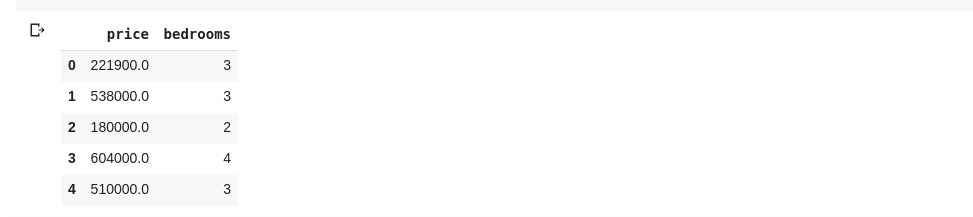
Описаний спосіб виділення стовпців повертає всі елементи в рядках цих стовпців. Але як повернути підмножину рядків та підмножину стовпців? Для цього використовується `.iloc` та індексація, подібна до списків Python. Наприклад:
df.iloc[50: , 3]
поверне 3-й стовпець, починаючи з 50-го рядка й до кінця. Це працює подібно до зрізів у списках Python.
Тепер перейдемо до цікавішого. У нашому наборі даних про ціни на житло є стовпець, що містить ціну будинку, та стовпець із кількістю спалень. Ціна будинку є унікальною величиною, а кількість спалень може повторюватися. Може виникнути потреба отримати всі будинки з однаковою кількістю спалень і знайти середню ціну для кожної кількості.
Це відносно просто зробити в Pandas:
df.groupby('bedrooms ')['price '].mean()
Цей код спочатку групує дані за кількістю спалень, використовуючи `df.groupby()`, потім вибирає стовпець цін та обчислює середнє значення за допомогою `.mean()`.
Для візуалізації отриманих результатів можна скористатися функцією `.plot()`:
df.groupby('bedrooms ')['price '].mean().plot()
Результатом буде графік, як показано нижче:
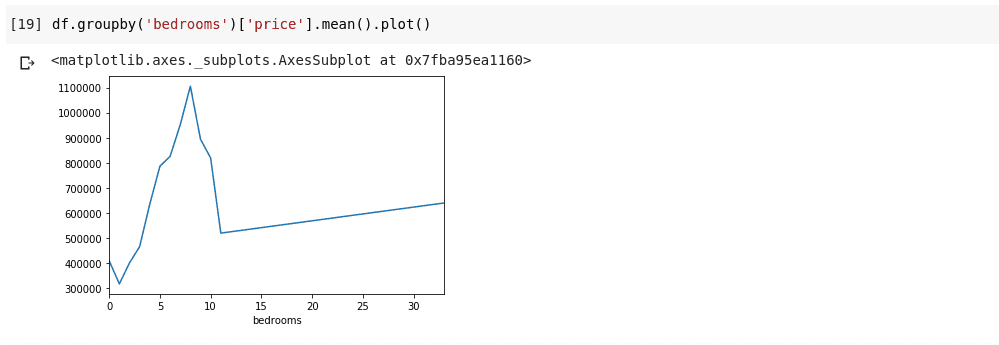
На горизонтальній осі ми бачимо кількість спалень, а на вертикальній – середню ціну для цієї кількості. Графік наочно демонструє, що будинки з 5-10 спальнями є дорожчими, ніж з трьома спальнями. Також помітно, що будинки з 7-8 спальнями коштують більше, ніж будинки з 15, 20 чи навіть 30 кімнатами.
Цей приклад підкреслює важливість аналізу даних. Він допомагає отримати цінні відомості, які неочевидні без спеціальної обробки.
Відсутні дані
Уявіть, що ви проводите опитування. Ви надаєте посилання на нього тисячам людей. Вашою метою є аналіз отриманих даних для виявлення закономірностей. Проте, частина респондентів може пропустити деякі питання. Це може створити проблеми, особливо, якщо ви збираєте числові дані, оскільки відсутність значень може спотворити результати обчислень. Тому потрібно знайти спосіб виявити та замінити відсутні дані.
Pandas надає функцію `isnull()` для виявлення відсутніх значень у DataFrame.
Її можна використовувати наступним чином:
df.isnull()
Ця функція повертає DataFrame з логічними значеннями, що показують, де дані відсутні. Результат виглядатиме так:
Найпростішим способом заміни відсутніх значень є заміна їх на нуль. Іноді можна використовувати середнє значення або інший показник, залежно від контексту.
Для заповнення відсутніх значень використовується функція `.fillna()`:
df.fillna(0)
У цьому прикладі ми замінюємо всі відсутні значення на нуль. Замість нуля можна вказати будь-яке інше число.
Важливість даних важко переоцінити, адже вони дозволяють отримувати відповіді з самої інформації. Аналіз даних, у певному сенсі, є новою нафтою для цифрової економіки.
Всі приклади коду з цієї статті можна знайти тут.
Для глибшого вивчення теми рекомендуємо онлайн-курс “Аналіз даних за допомогою Python і Pandas“.