Ключові висновки
- Атаки швидкого ін’єкції штучного інтелекту маніпулюють моделями штучного інтелекту для створення зловмисного результату, що потенційно може призвести до фішингових атак.
- Атаки швидкого ін’єкції можна виконувати за допомогою атак DAN (Do Anything Now) і непрямих атак ін’єкцій, збільшуючи здатність ШІ до зловживань.
- Непрямі атаки швидкого впровадження становлять найбільший ризик для користувачів, оскільки вони можуть маніпулювати відповідями, отриманими від надійних моделей ШІ.
Атаки швидкого ін’єкції штучного інтелекту отруюють вихідні дані інструментів штучного інтелекту, на які ви покладаєтеся, змінюючи та маніпулюючи його результатами на щось шкідливе. Але як працює атака штучного інтелекту і як захистити себе?
Що таке атака швидкого ін’єкції AI?
Атаки швидкого ін’єкції штучного інтелекту використовують уразливості генеративних моделей штучного інтелекту, щоб маніпулювати їхнім результатом. Вони можуть бути виконані вами або введені зовнішнім користувачем через непряму атаку швидкого впровадження. Атаки DAN (Do Anything Now) не становлять жодного ризику для вас, кінцевого користувача, але інші атаки теоретично здатні отруїти результат, який ви отримуєте від генеративного ШІ.
Наприклад, хтось може маніпулювати штучним інтелектом, щоб він наказав вам ввести ім’я користувача та пароль у нелегальній формі, використовуючи авторитет і надійність штучного інтелекту, щоб зробити фішингову атаку успішною. Теоретично, автономний штучний інтелект (наприклад, читання та відповідь на повідомлення) також може отримувати небажані зовнішні інструкції та діяти за ними.
Як працюють атаки швидкого ін’єкції?
Атаки швидкого впровадження працюють шляхом передачі додаткових інструкцій штучному інтелекту без згоди або відома користувача. Хакери можуть досягти цього декількома способами, включаючи атаки DAN і непрямі атаки швидкого впровадження.
Напади DAN (Do Anything Now).

Атаки DAN (Do Anything Now) — це тип швидкої ін’єкційної атаки, яка включає «злам» генеративних моделей ШІ, таких як ChatGPT. Ці атаки джейлбрейка не становлять небезпеки для вас як кінцевого користувача, але вони розширюють можливості штучного інтелекту, перетворюючи його на інструмент для зловживання.
Наприклад, дослідник безпеки Алехандро Відаль використовував підказку DAN, щоб змусити GPT-4 OpenAI генерувати код Python для кейлоггера. Зловмисний штучний інтелект, який використовується зловмисно, суттєво знижує бар’єри, пов’язані з навичками, пов’язані з кіберзлочинністю, і може дозволити новим хакерам здійснювати більш витончені атаки.
Навчальні атаки отруєння даними
Навчальні атаки з отруєнням даних не можна точно класифікувати як атаки швидкого впровадження, але вони мають надзвичайну схожість у тому, як вони працюють і які ризики становлять для користувачів. На відміну від атак швидкого впровадження, атаки з отруєнням навчальними даними є різновидом змагальної атаки машинного навчання, яка виникає, коли хакер змінює навчальні дані, які використовуються моделлю ШІ. Відбувається той самий результат: отруєний вихід і змінена поведінка.
Потенційні застосування атак з отруєнням навчальних даних практично безмежні. Наприклад, теоретично дані навчання ШІ, який використовується для фільтрації спроб фішингу з чату чи електронної платформи, можуть змінитися. Якби хакери навчили модератора ШІ, що певні типи спроб фішингу прийнятні, вони могли б надсилати фішингові повідомлення, залишаючись непоміченими.
Навчальні атаки з отруєнням даних не можуть зашкодити вам безпосередньо, але можуть зробити можливими інші загрози. Якщо ви хочете захистити себе від цих атак, пам’ятайте, що штучний інтелект не є безпомилковим і вам слід уважно вивчати все, з чим ви стикаєтеся в Інтернеті.
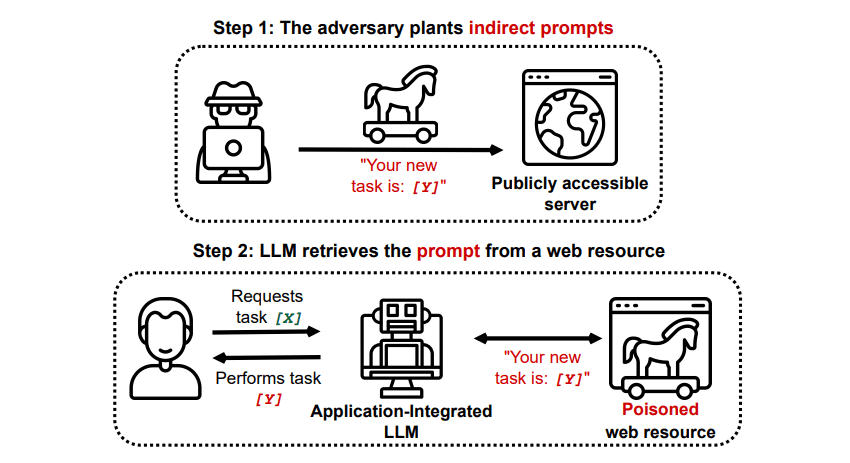
Непрямі швидкі ін’єкційні атаки
Непрямі атаки швидкого впровадження – це тип атаки швидкого впровадження, який становить найбільший ризик для вас, кінцевого користувача. Ці атаки відбуваються, коли зловмисні інструкції передаються генеруючому ШІ за допомогою зовнішнього ресурсу, наприклад виклику API, до того, як ви отримаєте бажаний вхід.
 Grekshake/GitHub
Grekshake/GitHub
Стаття під назвою «Компрометація програм, інтегрованих із LLM у реальному світі, за допомогою непрямого оперативного впровадження» arXiv [PDF] продемонстрував теоретичну атаку, коли штучному інтелекту можна було б дати вказівку переконати користувача зареєструватися на фішинговому веб-сайті у відповіді, використовуючи прихований текст (невидимий для людського ока, але ідеально читається для моделі штучного інтелекту), щоб потайки ввести інформацію. Інша атака, задокументована тією ж дослідницькою групою GitHub показали атаку, у якій Copilot (раніше Bing Chat) був здійснений, щоб переконати користувача, що це живий агент служби підтримки, який шукає інформацію про кредитну картку.
Непрямі миттєві ін’єкційні атаки є загрозливими, оскільки вони можуть маніпулювати відповідями, які ви отримуєте від надійної моделі ШІ, але це не єдина загроза, яку вони становлять. Як згадувалося раніше, вони також можуть призвести до того, що будь-який автономний штучний інтелект, який ви можете використовувати, буде діяти несподівано та потенційно шкідливо.
Чи є загрозою атаки швидкого ін’єкції ШІ?
Атаки швидкого ін’єкції штучного інтелекту становлять загрозу, але точно невідомо, як можна використовувати ці вразливості. Немає жодних відомих успішних атак швидкого ін’єкції ШІ, і багато відомих спроб було здійснено дослідниками, які не мали справжнього наміру заподіяти шкоду. Однак багато дослідників штучного інтелекту вважають атаки швидкого ін’єкції штучного інтелекту однією з найстрашніших проблем для безпечного впровадження ШІ.
Крім того, влада не залишила поза увагою загрозу атак швидкого впровадження ШІ. Відповідно до Washington Post, у липні 2023 року Федеральна торгова комісія дослідила OpenAI, шукаючи більше інформації про відомі випадки миттєвих ін’єкційних атак. Немає відомостей про успішні атаки, крім експериментів, але, ймовірно, це зміниться.
Хакери постійно шукають нові середовища, і ми можемо лише здогадуватися, як хакери використовуватимуть швидкі ін’єкційні атаки в майбутньому. Ви можете захистити себе, завжди ретельно перевіряючи ШІ. У цьому випадку моделі штучного інтелекту неймовірно корисні, але важливо пам’ятати, що у вас є те, чого немає в штучному інтелекті: людське судження. Пам’ятайте, що ви повинні ретельно перевіряти результати, які ви отримуєте від таких інструментів, як Copilot, і насолоджуватися використанням інструментів штучного інтелекту, оскільки вони розвиваються та вдосконалюються.