Amazon Glue набуває все більшої популярності, оскільки багато компаній почали застосовувати керовані сервіси для інтеграції даних.
ETL – це процедура переміщення інформації з джерела до сховища даних. Через свою складність, ETL є непростим завданням для реалізації з усіма корпоративними даними. Щоб розв’язати цю проблему, Amazon запропонував AWS Glue.
Розробники ETL та інженери з обробки інформації використовують Glue для створення, відстеження та виконання робочих процесів ETL.
Що таке AWS Glue?
AWS Glue, як безсерверна служба для інтеграції даних, робить легким процес пошуку, підготовки, переміщення та інтеграції даних з різних джерел. Це є корисним для машинного навчання (ML) і аналітичних цілей.
Цей інструмент значно скорочує час, потрібний для підготовки даних до аналізу. Він автоматично виявляє та класифікує дані, генерує код на Scala або Python для перенесення даних з джерела, а також завантажує і перетворює завдання згідно із запланованими подіями.
Він надає можливості гнучкого планування та створює масштабоване середовище Apache Spark для цільового завантаження даних. Крім того, AWS Glue забезпечує спостереження за складними потоками даних та їх модифікацію. AWS Glue – це безсерверний сервіс, який полегшує розробку складних програмних операцій.
Це прискорює процес інтеграції різноманітних актуальних даних. Також, він швидко структурує та авторизує дані.
Для чого використовується AWS Glue?
Важливо розуміти, де найкраще застосовувати Amazon Glue. Ось деякі з варіантів використання AWS Glue, які варто розглянути.
- Glue – це інструмент, що дозволяє виконувати безсерверні запити до озер даних Amazon S3. Amazon Glue – це чудовий інструмент для початку роботи. Він робить усі ваші дані доступними в одному інтерфейсі, дозволяючи їх аналізувати без потреби у переміщенні.
- Amazon Glue може використовуватися для розуміння ваших інформаційних ресурсів. Amazon Glue спрощує пошук у різних наборах даних AWS за допомогою каталогу даних. Ви також можете зберігати дані у різних сервісах AWS, маючи при цьому уніфіковане представлення через каталог даних.
- Glue може бути корисним під час створення керованих подіями робочих процесів ETL. Ви можете виконувати операції ETL з Amazon S3, викликаючи завдання Glue ETL через службу AWS Lambda.
- AWS Glue можна використовувати для очищення, перевірки, форматування та впорядкування даних перед їх зберіганням в озері даних або сховищі.
Які компоненти AWS Glue?
Нижче представлені головні складові AWS Glue:
- Каталог даних: Цей каталог містить метадані та структуру даних.
- База даних: Це ключ для доступу та створення бази даних для джерел і цілей.
- Таблиця: Створення однієї або декількох таблиць у базі даних, які можуть використовуватись як цільові, так і вихідні.
- Сканер та класифікатор: Сканер отримує дані з джерела, використовуючи вбудовані або кастомні класифікації. Він створює/використовує заздалегідь визначені метадані таблиць у каталозі даних.
- Завдання: Це бізнес-логіка для виконання ETL завдання. Ця логіка написана на основі Apache Spark, використовуючи python та scala.
- Тригер: Тригер ETL – це механізм, що ініціює виконання завдання ETL за запитом або в конкретний час.
- Кінцева точка для розробки: Це середовище, де скрипт завдання ETL тестується, розробляється та налагоджується.
Переваги AWS Glue
Це переваги від використання сервісу у вашій роботі чи організації.
- AWS Glue сканує всі доступні дані за допомогою сканера.
- Оброблені дані можна зберігати в різних місцях (Amazon RDS, Amazon Redshift, Amazon S3 тощо).
- Це хмарний сервіс, отже немає потреби витрачати кошти на локальну інфраструктуру.
- Оскільки це безсерверний ETL, він є економічно вигідним варіантом.
- Це швидко. Сервіс миттєво створює ETL код на Python/Scala.
Основні характеристики AWS Glue?
Amazon Glue має всі необхідні функції для інтеграції даних, що дозволяє вам отримати більш глибоке розуміння інформації та використовувати ці знання для досягнення нових результатів за лічені хвилини, а не місяці. Ось деякі з ключових функцій, про які варто знати.
- Інтерфейс перетягування: Редактор завдань з функцією перетягування дозволяє вам створювати процес ETL. AWS Glue одразу генерує код, необхідний для вилучення, конвертації та завантаження даних.
- Автоматичне виявлення схеми: Для створення сканерів, які під’єднуються до різних джерел даних, можна використовувати сервіс Glue. Він аналізує дані та вилучає відповідну інформацію. Потім ці дані можна використовувати для моніторингу процесів ETL за допомогою ETL завдань.
- Планування роботи: Glue можна використовувати за потреби або за розкладом. Планувальник можна використовувати для побудови складних конвеєрів ETL, встановлюючи залежності між завданнями.
- Генерація коду: Glue Elastic Views дає змогу легко створювати матеріалізовані представлення, які комбінують та копіюють дані з різних джерел, без потреби писати кастомний код.
- Вбудоване машинне навчання: Glue поставляється з вбудованою функцією машинного навчання під назвою «FindMatches». Вона видаляє дублікати записів, які не є точними копіями один одного.
- Кінцеві точки розробника: Якщо вам потрібно активно розробляти ETL код, Glue пропонує кінцеві точки розробника, які дозволяють змінювати, налагоджувати та тестувати створений код.
- Glue DataBrew: Це інструмент підготовки даних, який можуть використовувати аналітики та дослідники даних для очищення та нормалізації даних. Він використовує активний та візуальний інтерфейс Glue DataBrew.
Як працює ціноутворення AWS Glue?
AWS Glue стягує погодинну плату, що виставляється за секунду, для сканерів (виявлення даних) і ETL завдань (обробка та завантаження даних). За доступ і зберігання метаданих у каталозі даних AWS Glue стягується фіксована щомісячна плата.
Вартість Amazon Glue починається з 0,44 доларів. Ви можете обрати один із чотирьох планів:
- Завдання ETL, кінцеві точки розробки та інші завдання ETL доступні за $0,44.
- Інтерактивні сеанси сканерів доступні за $0,44.
- Вакансії DataBrew починаються від $0,48.
- Щомісячне зберігання та запити до каталогу даних коштують $1,00.
AWS не надає безкоштовний план для Glue. Кожна година обійдеться в $0,44 за DPU. В середньому це коштуватиме 21 долар на день. Ціни можуть відрізнятися в залежності від вашого місця перебування.
Кроки для налаштування AWS Glue
Каталог даних можна використовувати для швидкого пошуку та виявлення інформації у різних наборах даних AWS без потреби у переміщенні цих даних. Після каталогізації, дані одразу стають доступними для запитів та пошуку за допомогою Amazon Athena та Amazon EMR.
Посилання: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS і бази даних на Amazon EC2 – знаходьте свої дані, зберігайте метадані та використовуйте AWS Glue Data Catalog для їх пошуку.
- AWS Glue Data Catalog – керуйте даними за допомогою каталогу даних, який виступає централізованим сховищем метаданих.
- AWS Glue ETL – читання та запис метаданих у ваш каталог даних.
- Amazon Athena та Amazon Redshift, Amazon EMR, Amazon ETL – отримайте каталог даних для ETL, аналітики тощо.
Як налаштувати AWS Glue?
Спочатку увійдіть у консоль керування AWS та відкрийте консоль IAM. Натисніть “Створити роль”. Потім для типу ролі знайдіть Glue та виберіть “Дозволи”.
Я вибираю AWSGlueServiceRole для загальних дозволів AWS Glue Studio та AWS Glue, а також керовану AWS політику AmazonS3FullAccess для доступу до ресурсів Amazon S3.
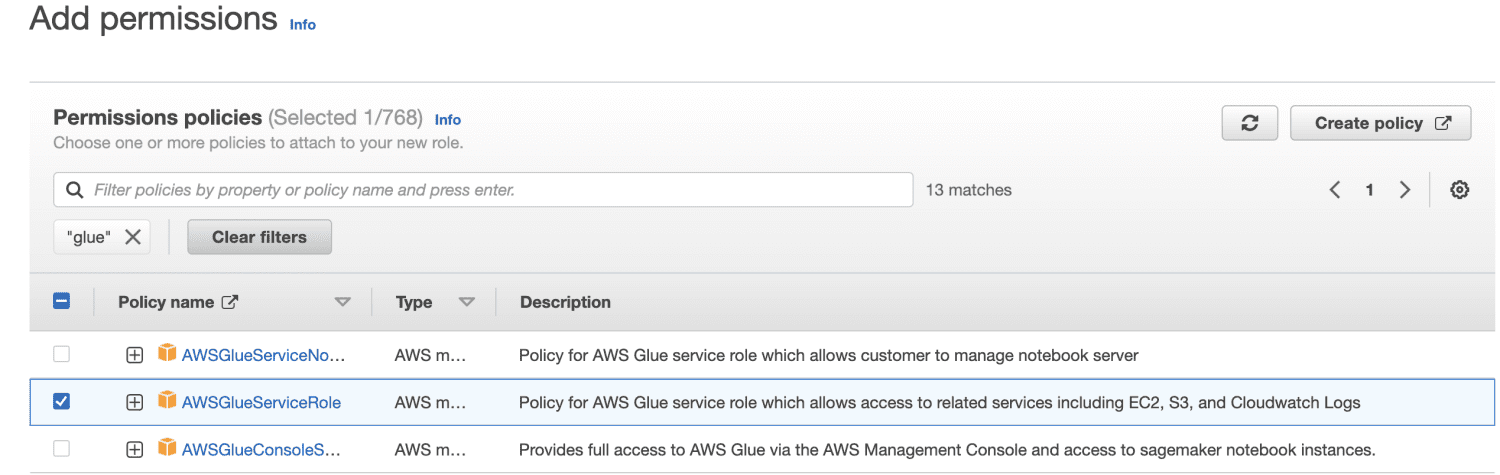
Введіть назву ролі.
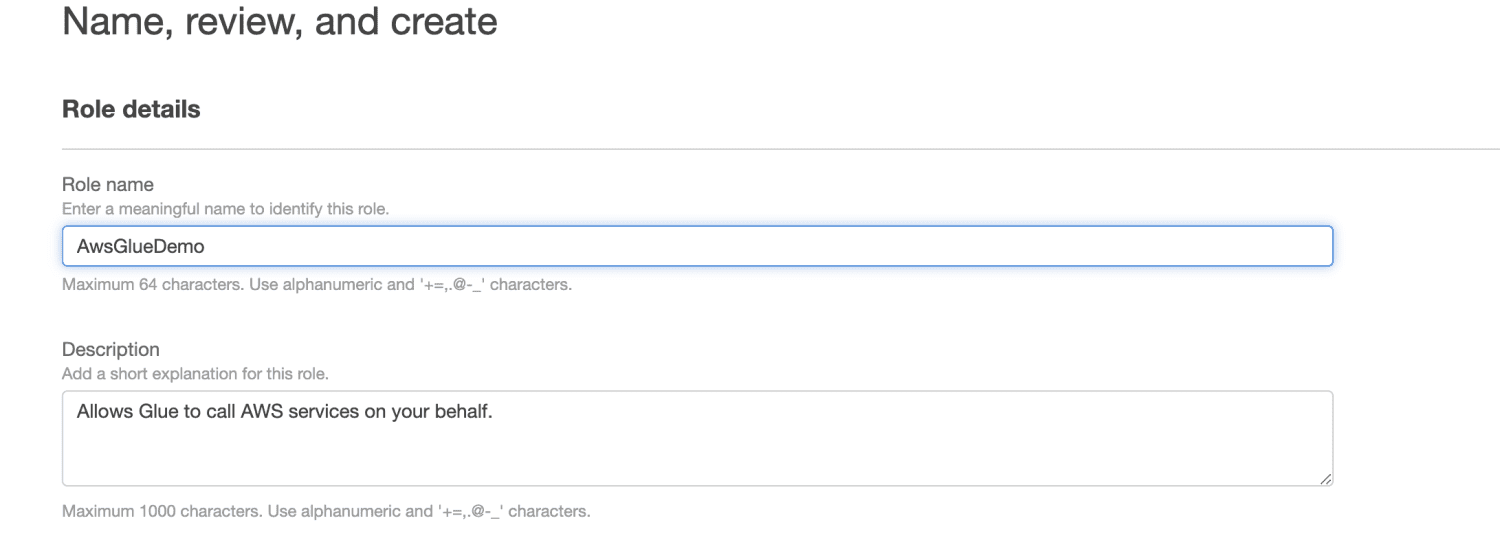
Натисніть “Створити роль”.
Створіть сегмент Amazon S3.
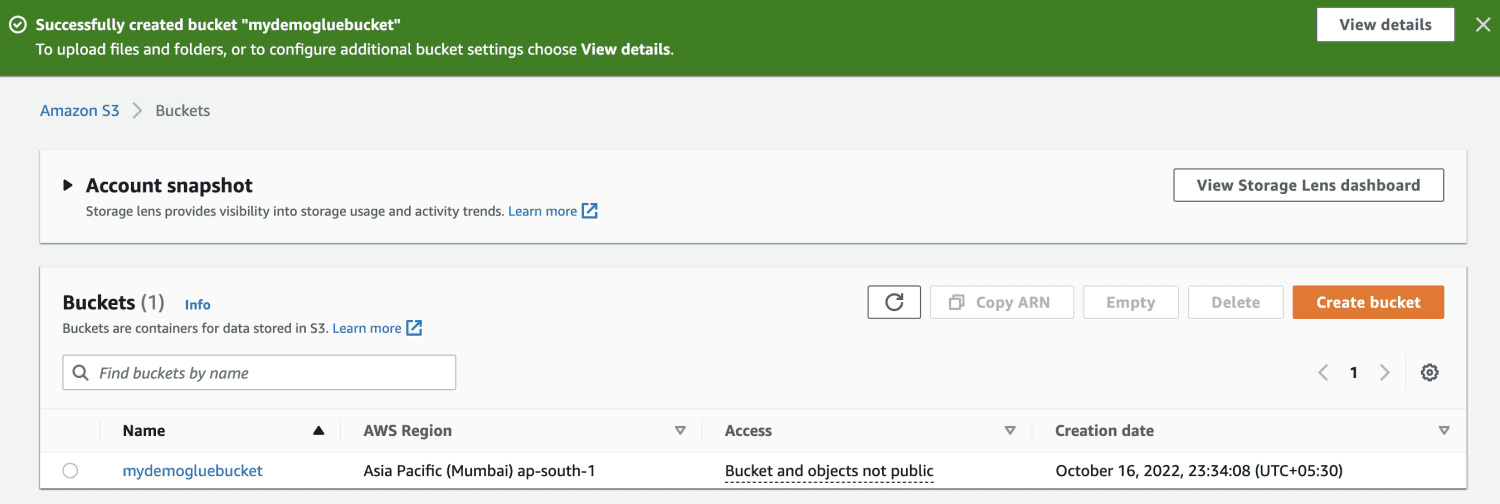
Створіть папку всередині відра S3.
Виберіть файл для завантаження.
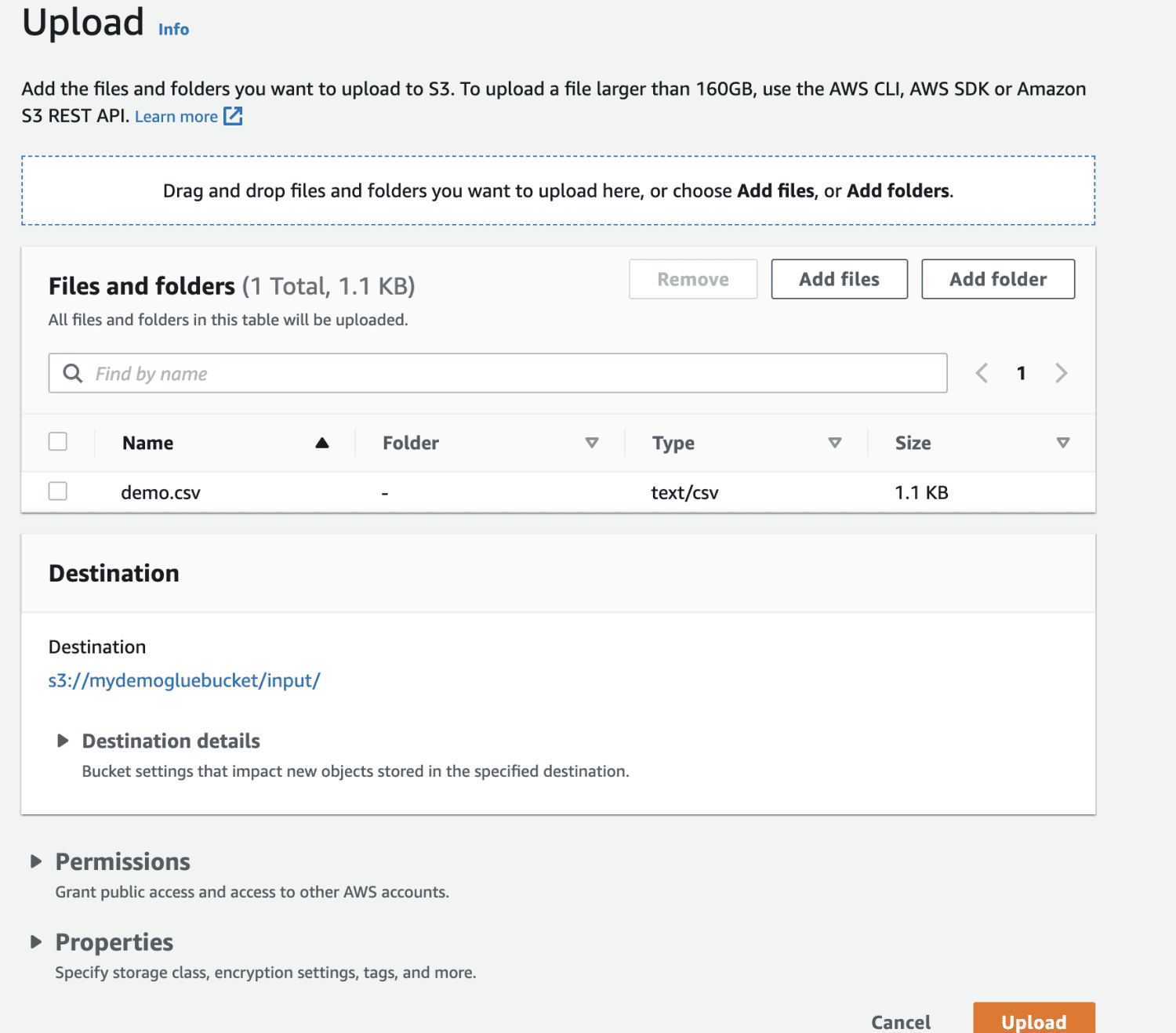
Нарешті, завантажте файл у відро.
Потім відкрийте AWS Glue з консолі керування AWS та створіть базу даних.
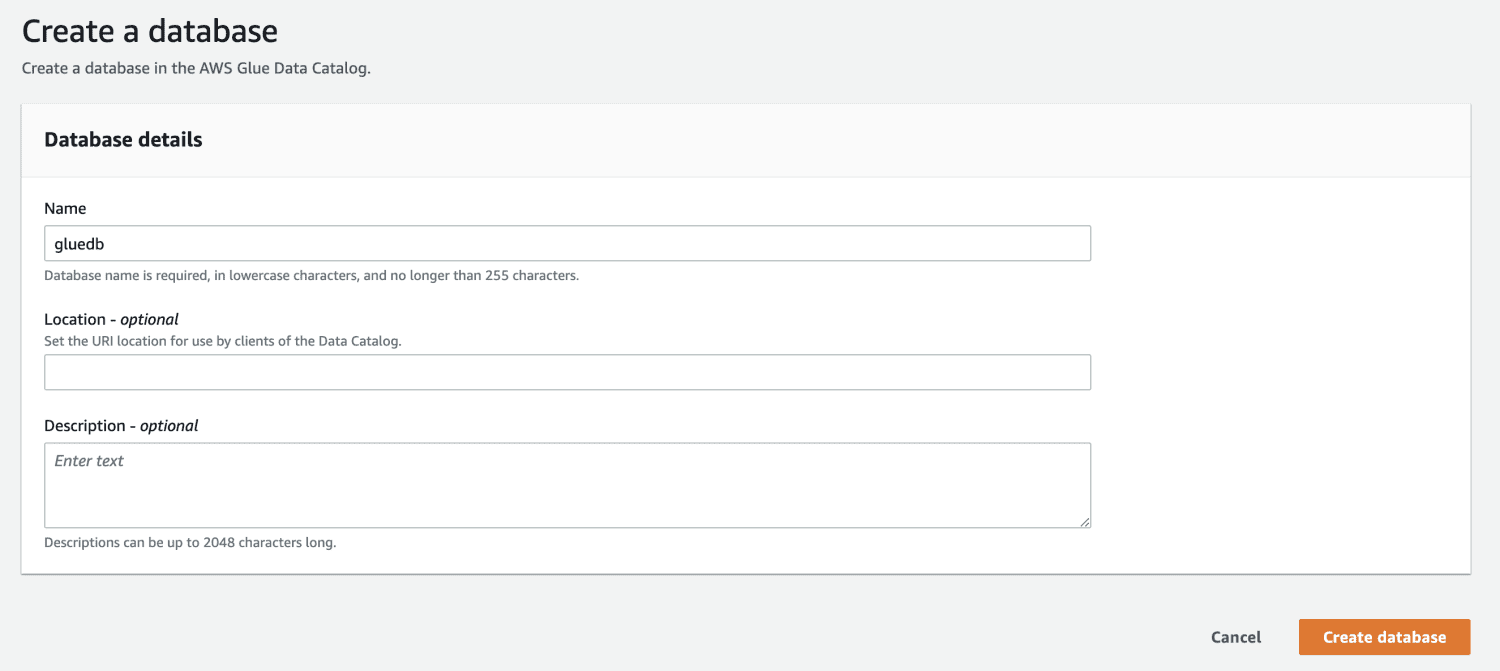
Тепер, коли у вас є база даних в AWS Glue, створіть сканер.
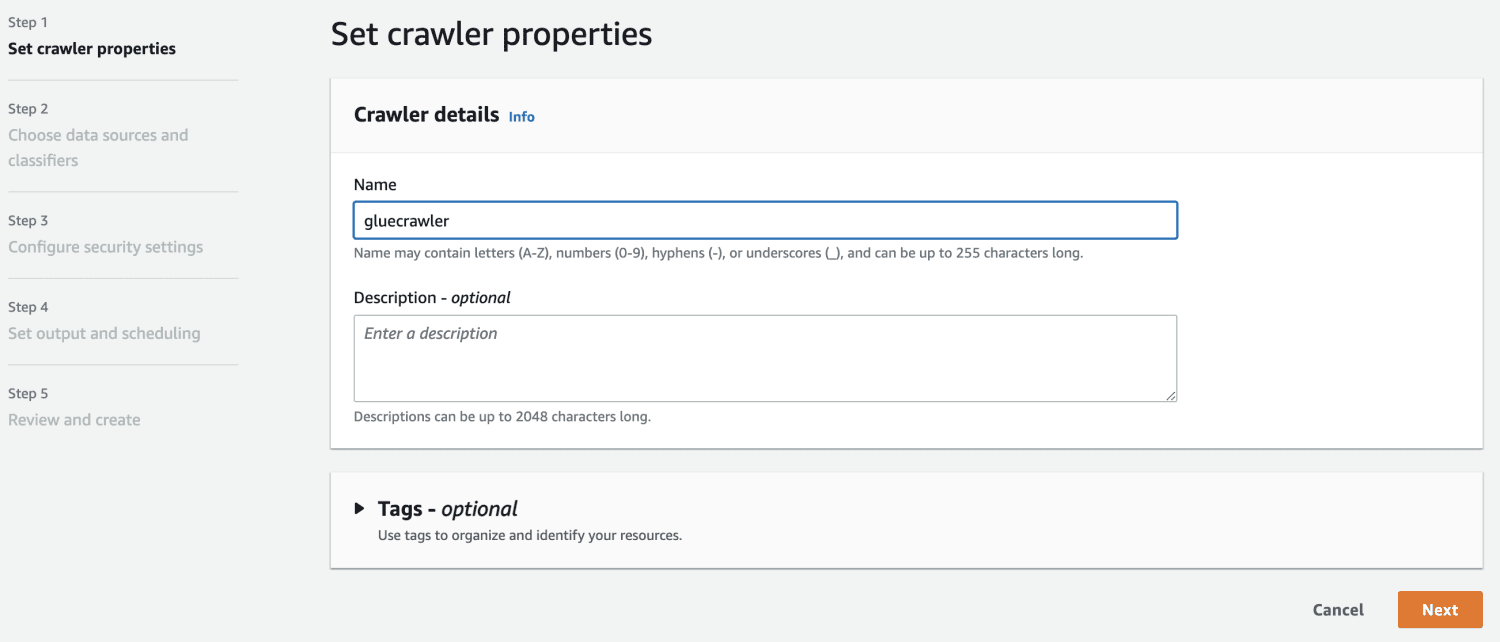
У джерелі даних виберіть створений вами сегмент S3.
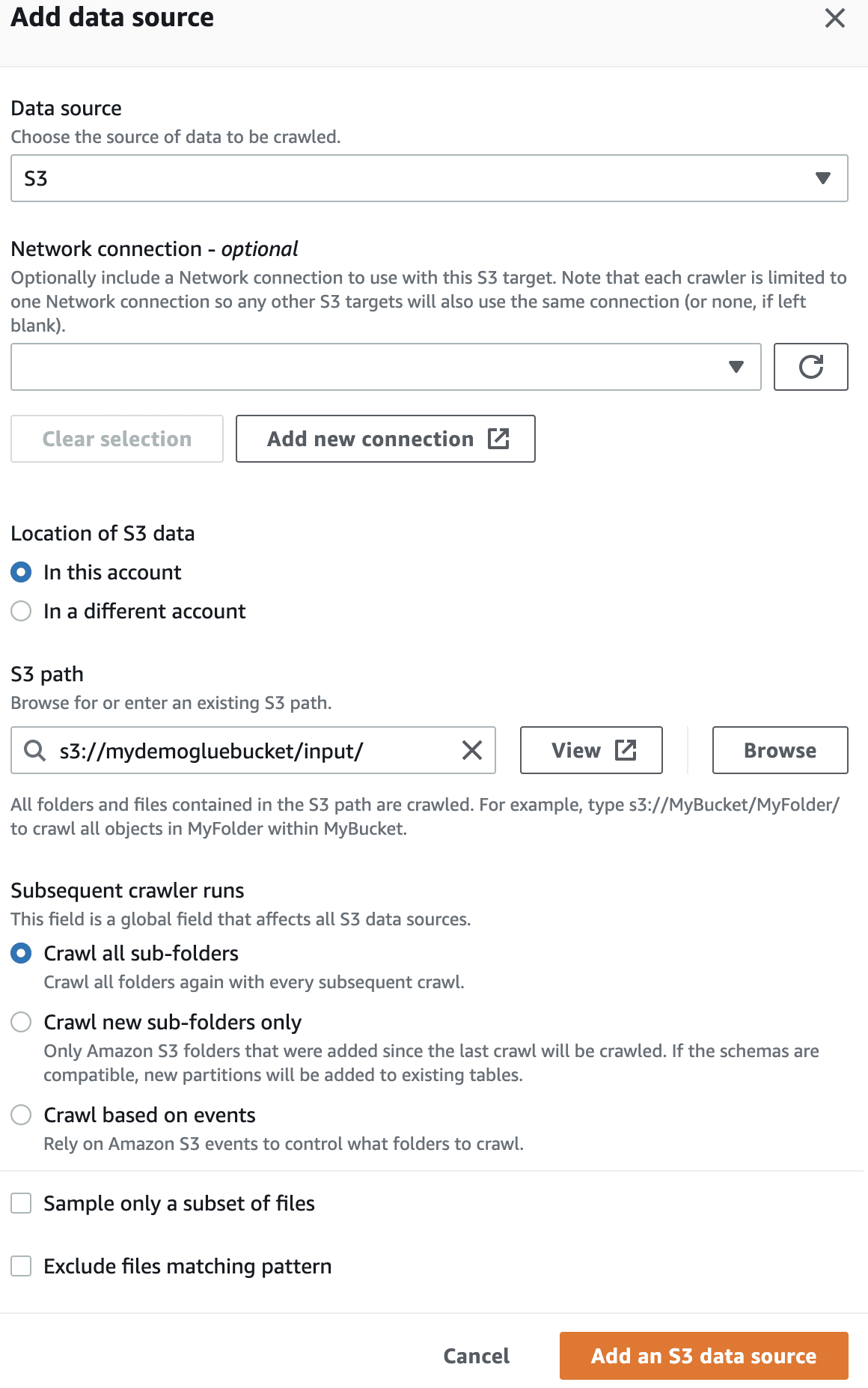
Далі оберіть роль IAM для AWS Glue, яку ви створили на початку.
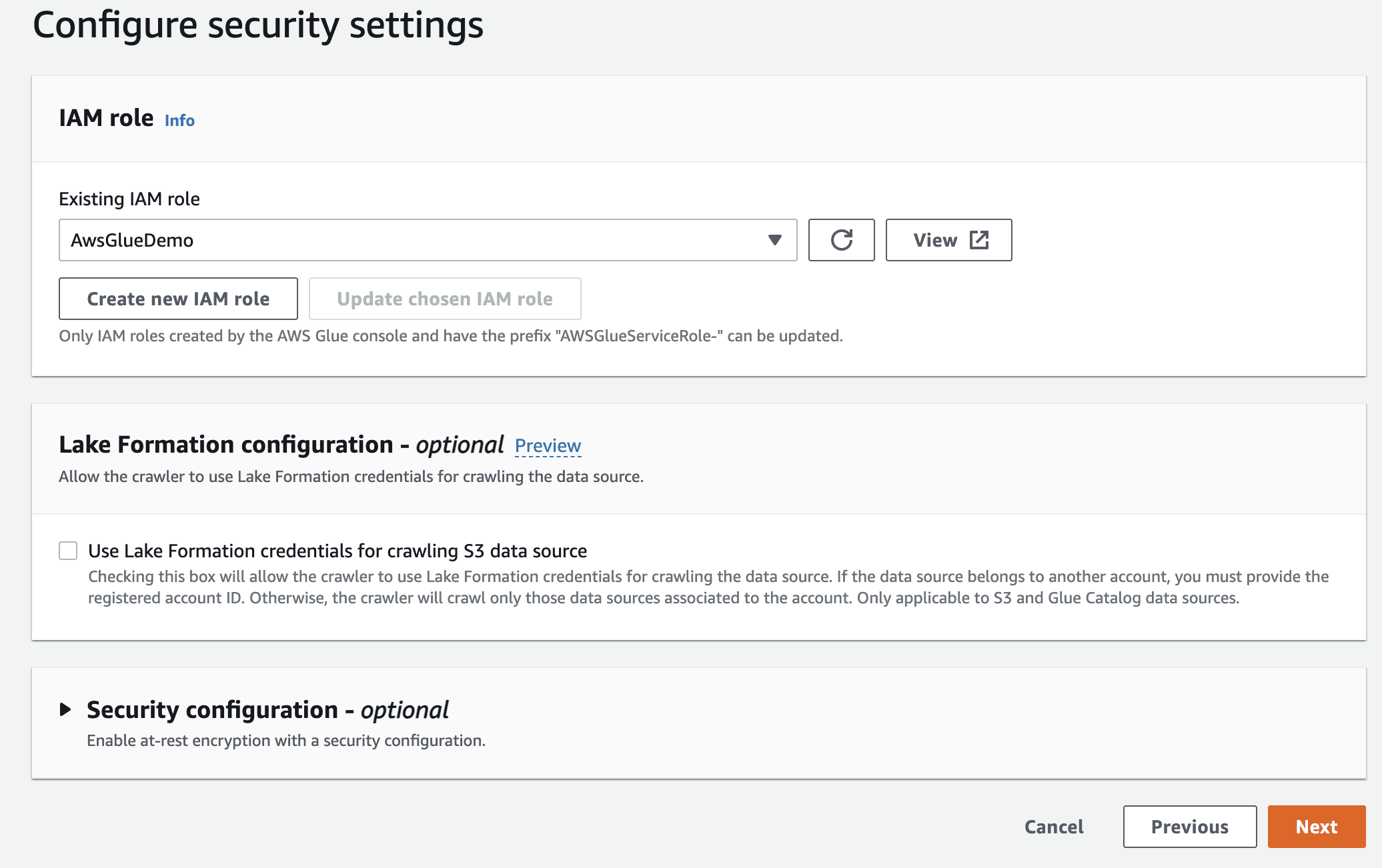
Нарешті, у вихідних даних виберіть gluedb, який ви створили.
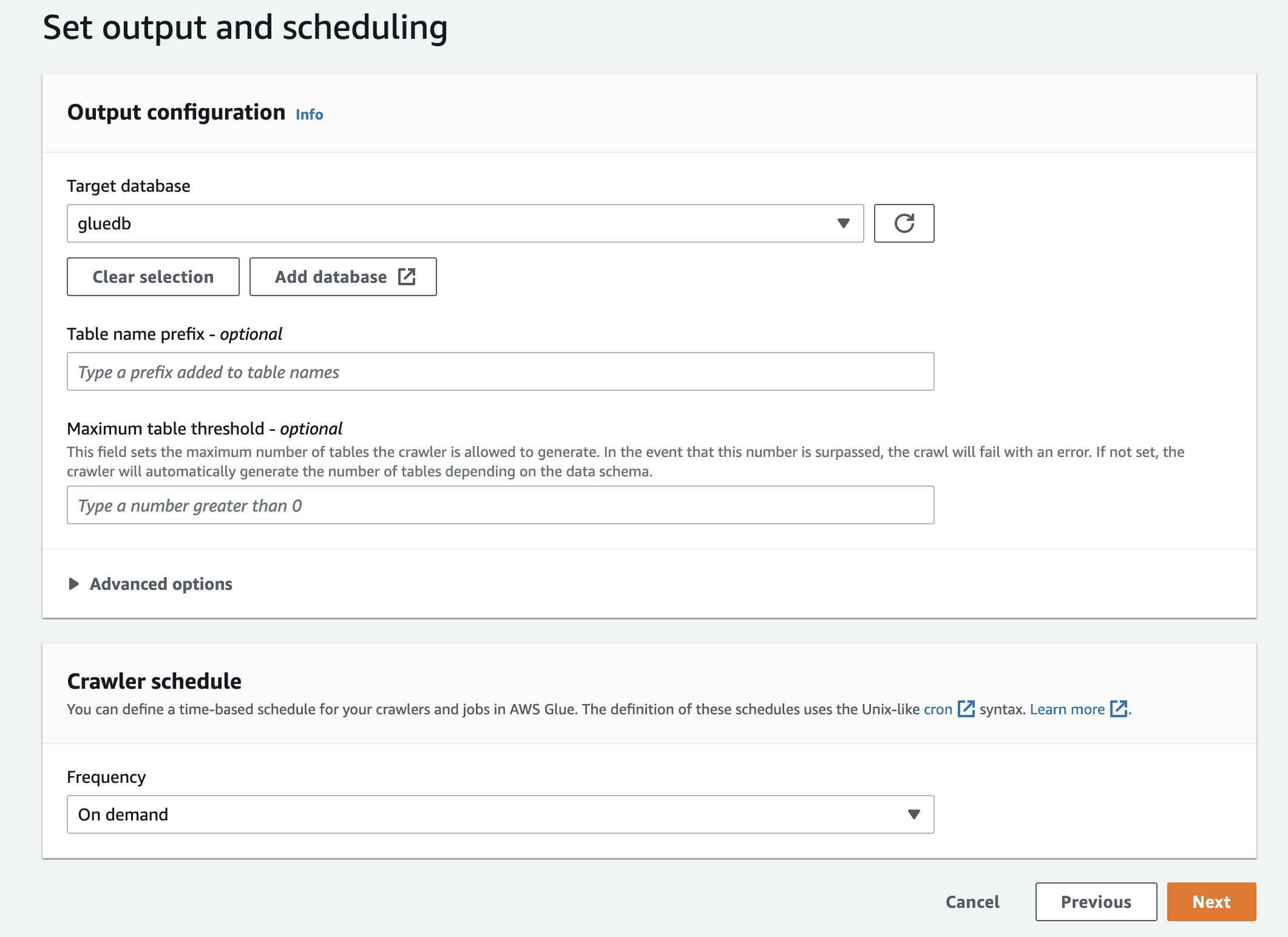
Перегляньте всі налаштування та створіть сканер.
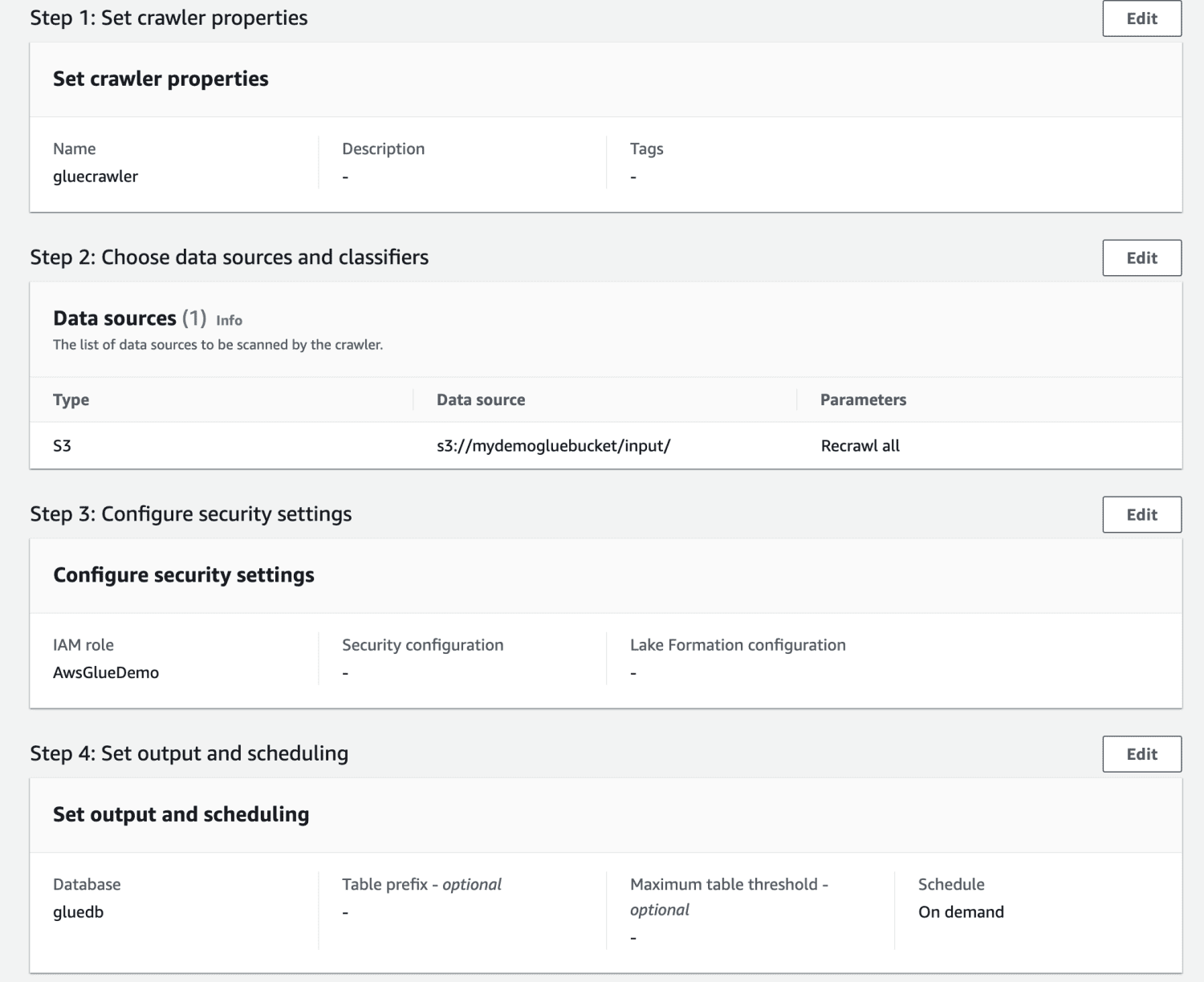
Після створення сканера оберіть його та натисніть «Запустити». Через певний час ви отримаєте статус “Готово”.
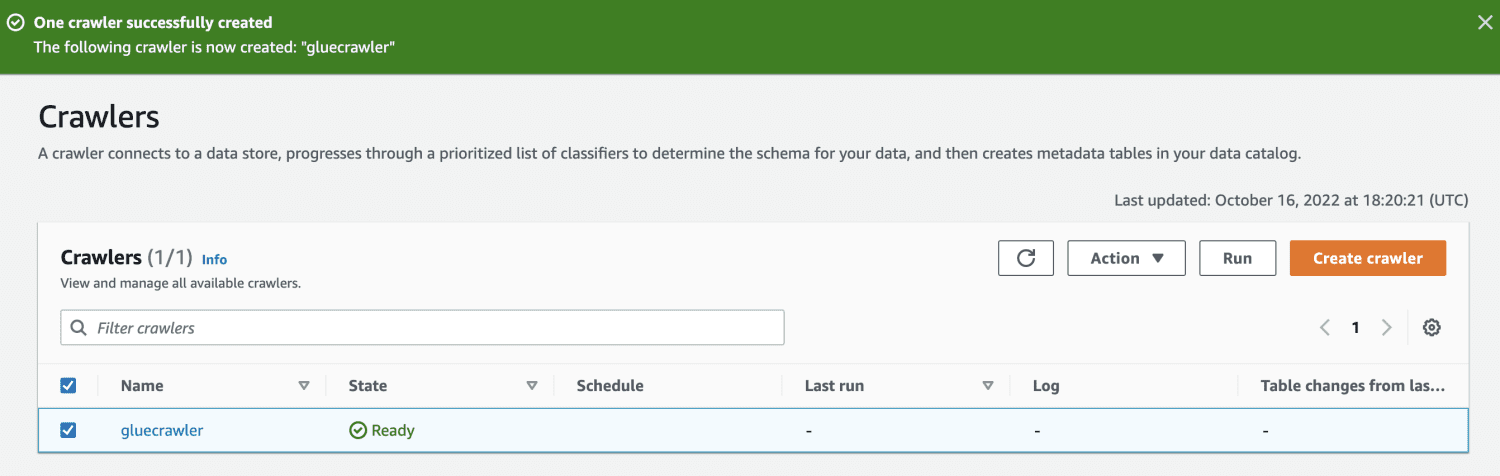
Запустивши сканер, база даних отримає таблицю зі всіма даними з файлу CSV.
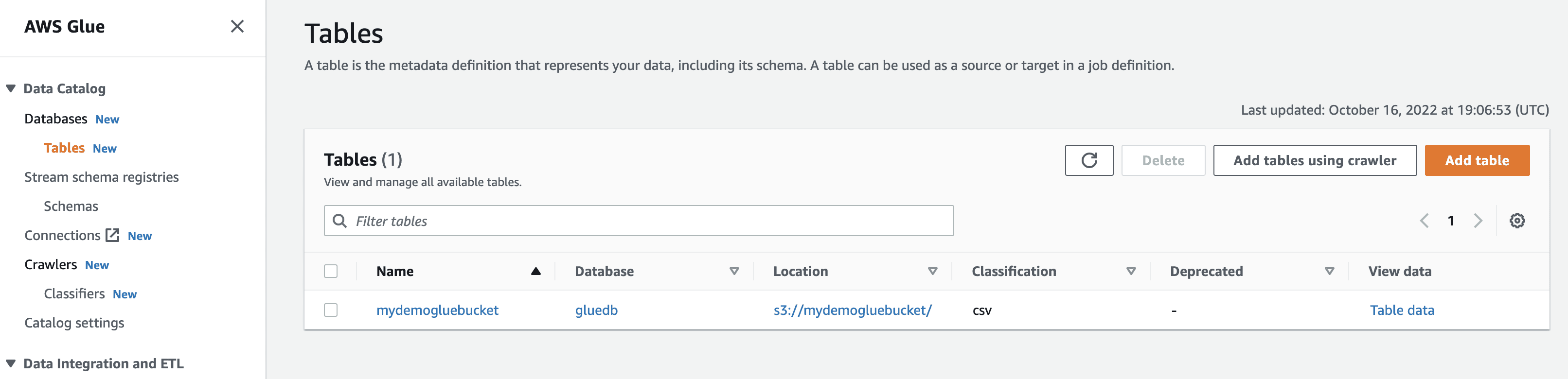
Коли ви клацнете на “Переглянути дані”, вас перенаправить до Amazon Athena (редактора запитів). Виконавши запит, ви зможете переглянути дані таблиці.
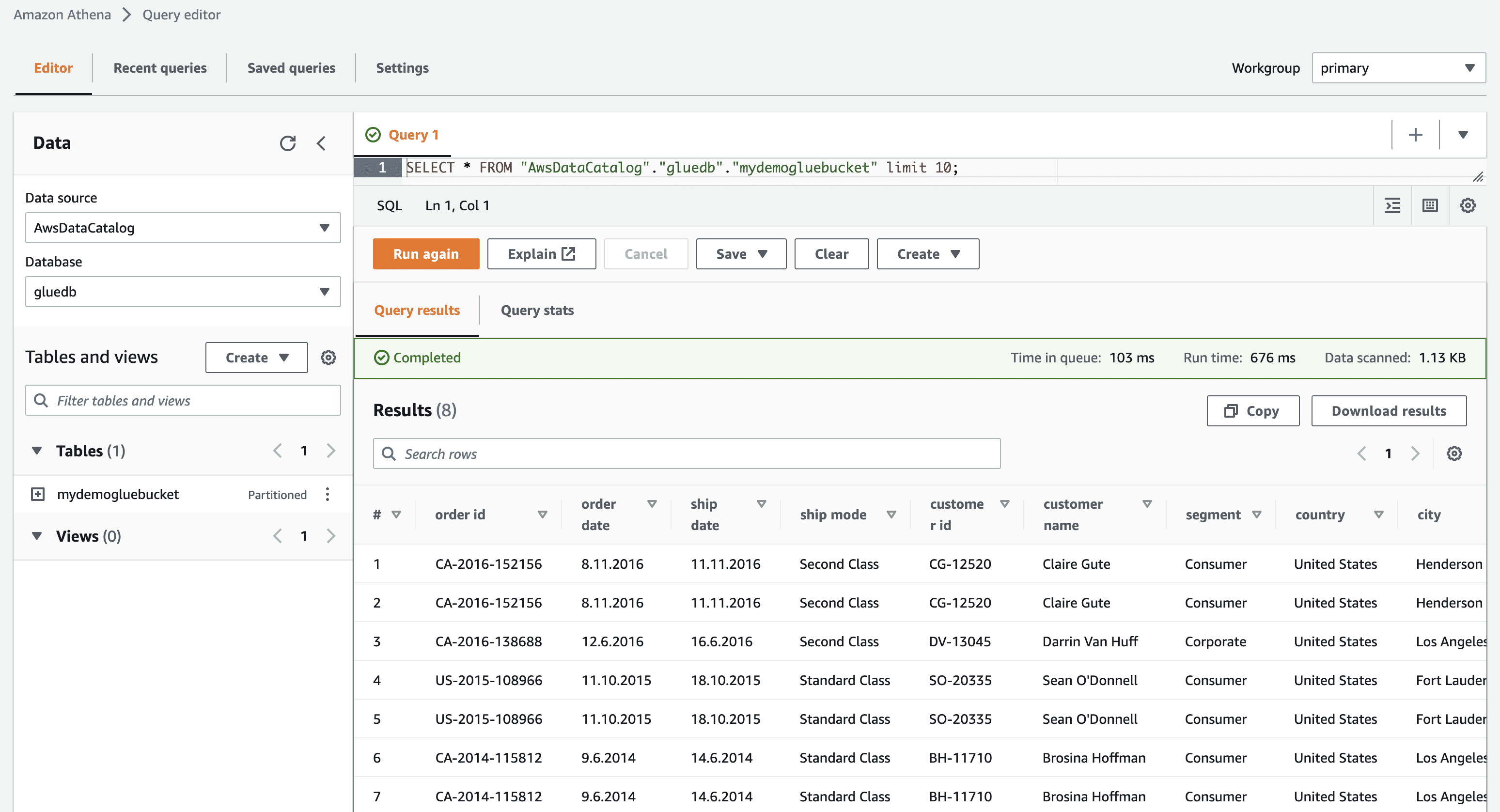
Тепер ви можете успішно використовувати цей сканер AWS Glue у будь-якій роботі ETL.
Що таке AWS Glue DataBrew?
AWS Glue DataBrew дозволяє користувачам нормалізувати та очищати дані без написання коду. DataBrew може скоротити час, необхідний для підготовки даних для машинного навчання та аналізу, до 80% порівняно з ручною підготовкою даних.
Він має понад 250 готових перетворень даних, які можна використовувати для автоматизації завдань підготовки даних, таких як фільтрування аномалій, виправлення недійсних значень та перетворення даних у стандартні формати.
DataBrew полегшує співпрацю між фахівцями з обробки даних, бізнес-аналітиками та інженерами для отримання корисних відомостей з необроблених даних. DataBrew працює без серверів, отже вам не потрібно керувати інфраструктурою або створювати кластери для дослідження та перетворення терабайтів вихідних даних.
Функції DataBrew для підприємств
Візуалізована підготовка даних
DataBrew – це інший спосіб перегляду даних, які зазвичай розглядаються в базах даних як стовпці з буквено-цифровими значеннями. DataBrew візуалізує всі завантажені джерела даних, щоб допомогти вам зрозуміти зв’язки та ієрархію даних.
250+ автоматизованих систем підготовки даних
Очікується, що фахівці, які працюють з даними, виконуватимуть різноманітні повторювані ізольовані робочі процеси в межах своїх обов’язків. AWS змоделювали ці процеси як незалежні від мови та даних модулі. Ця бібліотека містить дії, які можуть використовувати кінцеві користувачі.
Лінія даних
Подібно до журналів аудиту, що використовуються для відстеження активності клієнтів в IT мережі, лінія даних дозволяє відстежувати дії перетворення даних в AWS DataBrew. Ця інформація включає джерело даних, застосовані перетворення та вихідні дані, включаючи цільове розташування.
Відображення даних
Databrew дозволяє знаходити відповідні поля у двох джерелах даних. Після визначення відповідних полів їх можна завантажити в схему.
AWS Glue DataBrew: переваги
Нижче наведено функції AWS Glue DataBrew:
- Нижчий поріг для входу в підготовку даних.
- Автоматизоване створення профілю даних.
- Автоматизація понад 250 процесів підготовки даних.
- Інтелектуальні пропозиції.
Альтернативи AWS Glue
Airflow
Airflow належить до категорії менеджерів робочих процесів. Це інструмент з відкритим вихідним кодом, який підтримується через GitHub stars, GitHub forks та інші функції. Airflow дозволяє створювати робочі процеси за допомогою орієнтованих ациклічних графів (DAG). Планувальник Airflow виконує ваші завдання, використовуючи масив працівників і дотримуючись заданих залежностей.
Matillion

Matillion ETL, інструмент ETL/ELT, був розроблений спеціально для хмарних платформ баз даних, таких як Amazon Redshift та Google BigQuery. Він має сучасний веб-інтерфейс з потужними можливостями ETL/ELT. Завдяки швидкому налаштуванню ви можете розпочати роботу за лічені хвилини.
Stitch
Stitch – це ETL-сервіс з відкритим вихідним кодом, який з’єднує різні джерела даних і копіює дані у визначені місця призначення. Він дуже простий у використанні, оскільки вам не потрібні знання програмування для переміщення даних між джерелами та призначеннями в Stitch. Він легкий у використанні, має зручний графічний інтерфейс і працює швидко.
На відміну від інших інструментів ETL, Stitch не дозволяє обрати готову інформаційну панель. Замість цього ви повинні інтегрувати свої дані у відкриті сховища даних, які ви обрали як місце призначення. Може бути складно орієнтуватись у запасах.
Alteryx

Alteryx – це платформа автоматизації аналітики, яка допомагає у підготовці та комбінуванні збору даних. Ці дані можна використовувати для прискорення процесів та отримання бізнес-аналітики. Оскільки це інструмент перетягування, вам не потрібні знання програмування. Alteryx – гарне місце, де можна отримати поради та відповіді від професіоналів галузі.
Висновок
Отже, це все про AWS Glue, який є хмарним рішенням, що дозволяє працювати з конвеєрами ETL. Підсумовуючи, процес взаємодії з користувачем AWS Glue складається з трьох етапів. Щоб створити каталог даних, ви спочатку використовуєте сканери даних. Далі ви створюєте код ETL, потрібний для конвеєра даних AWS. Нарешті створюється розклад ETL. Сподіваюся, цей блог дав вам гарне розуміння Amazon Glue.
Ви також можете ознайомитися з найкращими порадами щодо захисту сховища AWS S3.