Основні висновки
- Платформи соціальних мереж продають інформацію про користувачів компаніям, що займаються штучним інтелектом, для навчання генеративних ШІ-моделей, попри питання конфіденційності.
- Такі платформи, як Meta, Reddit, Tumblr та WordPress.com активно беруть участь у цих угодах щодо ліцензування даних для навчання штучного інтелекту.
- Користувачі можуть вжити певних заходів для захисту своїх даних, зокрема налаштувати параметри приватності, відмовитися від передачі даних та бути обережними щодо того, що вони публікують в мережі.
Одним з останніх методів монетизації даних користувачів компаніями, що володіють соціальними медіа, є співпраця з компаніями, що займаються штучним інтелектом. Але чи можуть звичайні користувачі зробити щось для збереження своєї інформації та контенту?
Використання даних з соціальних мереж для навчання генеративних моделей штучного інтелекту є спірним питанням, але, схоже, це не заважає соціальним мережам ділитися даними своїх користувачів.
Компанія Meta вже використовує інформацію з соціальних мереж для навчання генеративних функцій штучного інтелекту, представлених на Meta Connect у 2023 році. Це стосується Meta AI та таких функцій, як створення стікерів, згенерованих штучним інтелектом у WhatsApp.
Як зазначив Майк Кларк, директор з управління продуктами в Meta, в публікації Meta Newsroom:
“Публічні дописи з Instagram та Facebook, включаючи фотографії та текст, були частиною даних, використаних для навчання генеративних моделей штучного інтелекту, які лежать в основі функцій, анонсованих на Connect.”
Ця тенденція, ймовірно, не сповільниться у 2024 році. Згідно з повідомленням Reuters, Reddit підписав угоду з Google, щоб надати доступ до контенту платформи для навчання моделей ШІ.
Заявка Reddit S-1 для IPO, подана 22 лютого 2024 року, підтверджує, що компанія розглядає угоди про ліцензування. У поданні вказано:
“Дані Reddit є основою для створення сучасної технології ШІ та багатьох великих мовних моделей (LLM). Ми вважаємо, що великий обсяг розмовних даних і знань Reddit продовжуватиме відігравати важливу роль у навчанні та вдосконаленні LLM.”
Зазначається, що Reddit “на початкових етапах надання дозволу третім сторонам на ліцензування доступу для пошуку, аналізу та відображення історичних даних і даних у реальному часі з нашої платформи” з метою навчання LLM.
І хоча Meta та Reddit є одними з найбільших гравців серед соціальних мереж, вони не єдині платформи, які використовують дані соціальних мереж для навчання ШІ. Згідно з повідомленням 404 Media, Tumblr і WordPress.com також планують продавати інформацію користувачів компаніям Midjourney та OpenAI.
Найімовірніше, якщо ви користуєтеся Facebook, Instagram, Reddit, Tumblr або WordPress.com, ваш відкритий контент уже використовувався для навчання великих мовних моделей (LLM).
Наприклад, якщо ви використаєте інструмент пошуку Washington Post, щоб дізнатися, які сайти були включені до набору даних Google C4, використаного для навчання Bard, ви побачите, що на Reddit.com припадає 7,9 мільйона токенів.

На Tumblr.com припадає 1,6 мільйона токенів. Мій невеликий веб-сайт, що працює на WordPress.com, мав 14 000 токенів, отже навіть невеликі особисті блоги могли потрапити до цього набору даних.
Враховуючи поточні угоди між компаніями штучного інтелекту та соціальними мережами, ліцензійні угоди означають, що ці дані будуть активно продаватися, а не просто збиратися з інтернету.
Але що ви можете зробити з цим щодо майбутньої обробки даних? Meta представила форму для суб’єктів даних щодо генеративного ШІ, що дозволяє відхилити або обмежити обробку ваших персональних даних третіми сторонами для навчання генеративних моделей ШІ Meta.
Варто зауважити, що ця опція не дозволяє вам відмовитися від власної обробки ваших даних Meta для навчання генеративного ШІ. До того ж, коли я відправив запит на відмову від використання моїх персональних даних через форму, служба підтримки попросила мене надати докази, що моя особиста інформація вже є в генеративних результатах ШІ Meta.
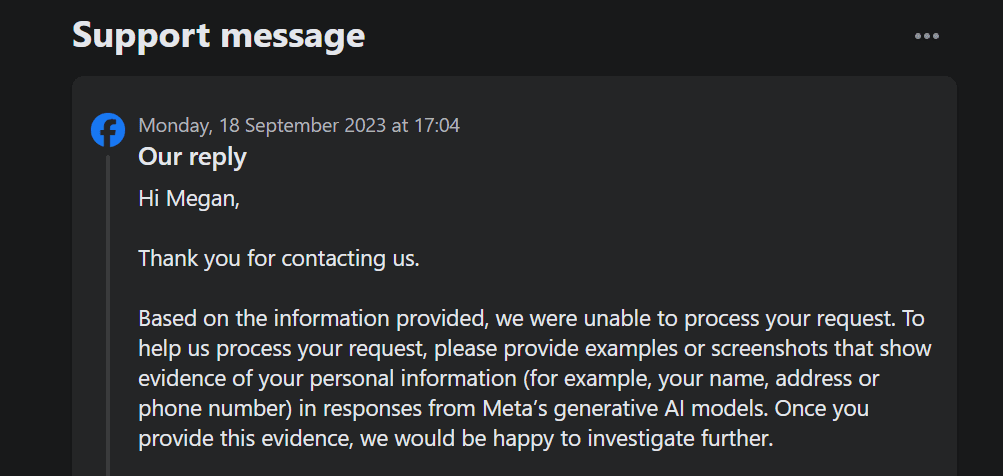
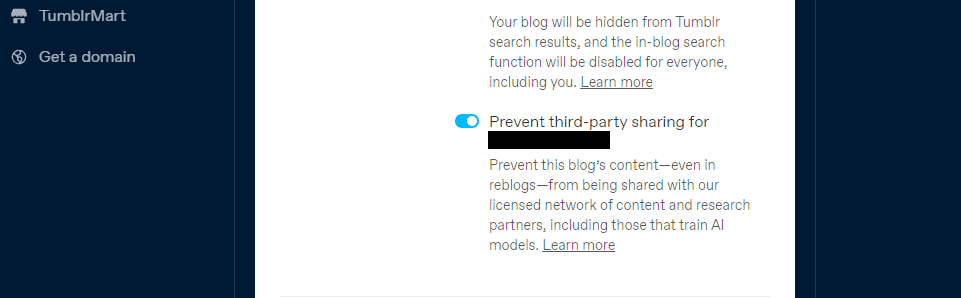
Tumblr також додав можливість відмовитися від надання доступу до контенту ваших відкритих блогів третім сторонам через налаштування блогу. Ви можете знайти її в налаштуваннях, клікнувши на свій блог і прокрутивши вниз до налаштувань видимості. Потім виберіть опцію “Запобігти поширенню блогу третьою стороною”.
Щодо платформи Instagram, ви можете спробувати зробити свій обліковий запис приватним, щоб уникнути використання ваших даних. Це не гарантує, що ваші дані не будуть використані, але оскільки збір даних для LLM, як видається, зосереджений на публічній інформації, це може бути профілактичним заходом.
Ви також можете зробити свій обліковий запис X (Twitter) приватним, але це також лише профілактичний крок, і це не гарантує конфіденційності ваших даних.
Спільна заява різних національних уповноважених з питань інформації та експертів з усього світу також пропонує певні дії для осіб, які прагнуть мінімізувати ризик конфіденційності, пов’язаний зі збором даних компаніями штучного інтелекту. Поради включають:
- Читайте умови та політику конфіденційності веб-сайту, щоб зрозуміти, як він використовує вашу персональну інформацію.
- Обмежуйте інформацію, яку ви публікуєте в Інтернеті, особливо конфіденційну.
- Керуйте налаштуваннями приватності.
- Подумайте про довгострокові наслідки інформації, яку ви публікуєте онлайн.
- Зв’яжіться із соціальною мережею або веб-сайтом, якщо ви вважаєте, що ваші дані були зібрані незаконно. Якщо ви не задоволені їхньою відповіддю, подайте скаргу до відповідного органу із захисту даних.
Ви також можете видалити певну інформацію з інтернету, якщо ви не хочете, щоб треті сторони мали до неї доступ, хоча загальнодоступна інформація у ваших профілях, можливо, вже була зібрана.
На жаль, як звичайні користувачі, ми можемо зробити не так багато для захисту своїх даних від компаній, що займаються штучним інтелектом. Справжній контроль над цією інформацією, швидше за все, буде досягнуто за допомогою регуляторних органів.