Сховище інформації. Озеро даних. Lakehouse. Якщо ці терміни не викликають у вас жодних асоціацій, ймовірно, ваша робота не пов’язана безпосередньо з обробкою даних.
Втім, це припущення є малоймовірним, оскільки сучасний світ тісно переплетений з даними. Керівники компаній часто заявляють про таке:
- Бізнес, який орієнтується на даних та керується ними.
- Доступ до даних будь-де, будь-коли та будь-яким способом.
Ключовий актив
Дані стають найціннішим ресурсом для зростаючої кількості компаній. Ще 10-15 років тому великі корпорації генерували значні обсяги даних, можливо, терабайти щомісяця. Сьогодні ж таку кількість даних можна створити всього за кілька днів. Виникає питання, чи дійсно це необхідно, навіть якщо це якийсь контент, який хтось буде використовувати? Відповідь, скоріш за все, буде негативною 😃.
Не весь контент виявиться корисним, а деякі його фрагменти взагалі можуть ніколи не знадобитися. Я був свідком ситуацій, коли компанії створювали величезні масиви даних, які ставали марними одразу після їх завантаження.
Але зараз це вже не проблема. Зберігання даних – завдяки хмарним технологіям – стало дешевим, джерела даних множаться в геометричній прогресії, і сьогодні ніхто не може точно спрогнозувати, які дані знадобляться через рік, коли з’являться нові сервіси. У такі моменти навіть старі дані можуть виявитися цінними.
Тому стратегія полягає у тому, щоб зберігати якомога більше даних, але у максимально ефективній формі. Це дозволить не тільки ефективно їх зберігати, але й швидко запитувати, переробляти, трансформувати та передавати далі.
Розгляньмо три основні способи реалізації цього в AWS:
- Athena Database – недорогий та ефективний, але простий спосіб створення озера даних у хмарі.
- Redshift Database – серйозна хмарна версія сховища даних, яка має потенціал замінити більшість локальних рішень, що не встигають за експоненційним зростанням обсягів даних.
- Databricks – гібрид озера та сховища даних в одному рішенні з додатковими перевагами.
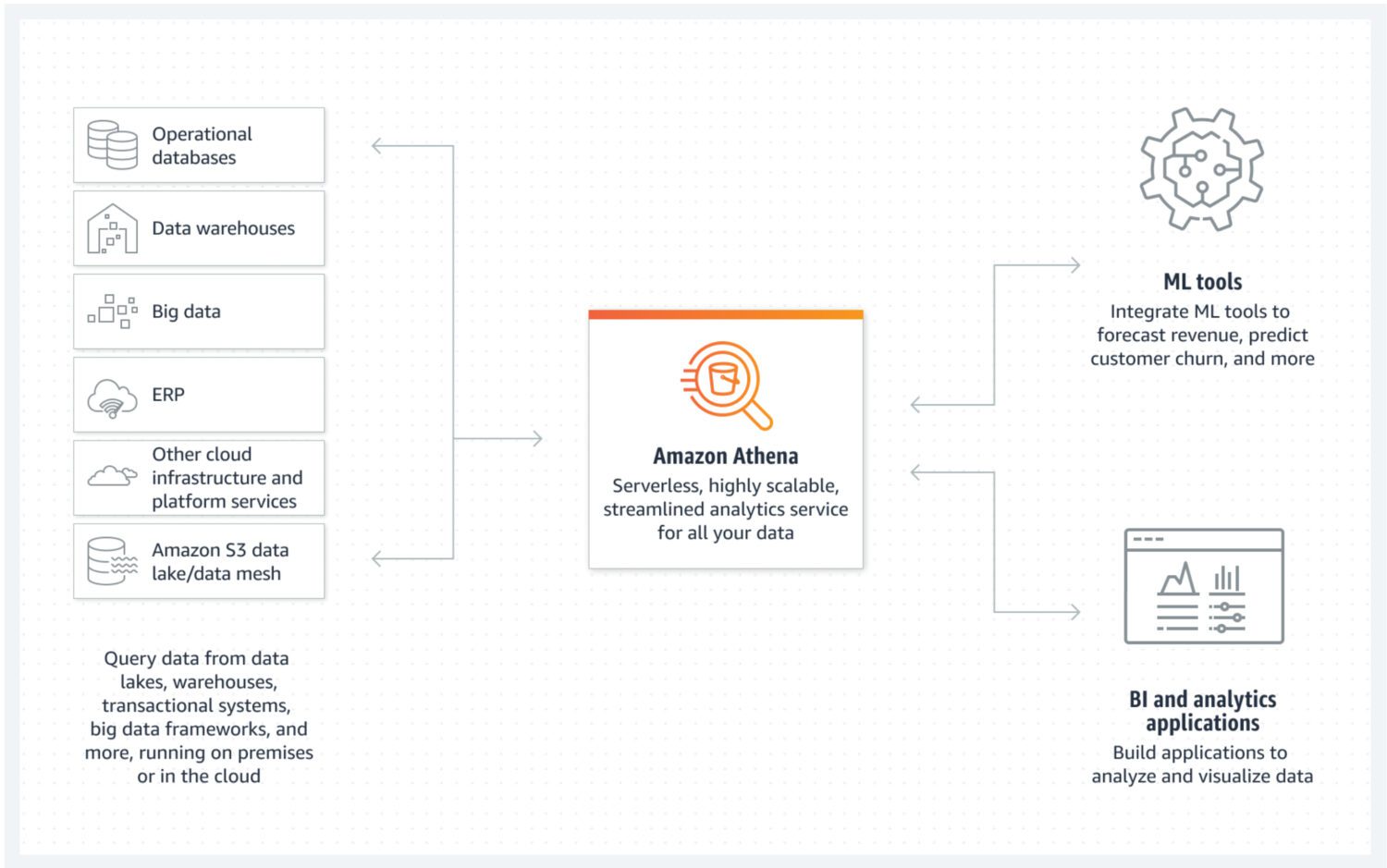
Озеро даних з AWS Athena
 Джерело: aws.amazon.com
Джерело: aws.amazon.com
Озеро даних – це місце, де вхідні дані можна швидко зберігати у неструктурованому, напівструктурованому або структурованому форматі. При цьому не очікується, що ці дані будуть змінюватися після їх збереження. Натомість, вони повинні бути максимально атомарними та незмінними. Це забезпечить найбільші можливості для їхнього повторного використання на наступних етапах. Якщо цю атомарну властивість даних втратити одразу після першого завантаження в озеро, відновити цю втрачену інформацію буде неможливо.
AWS Athena – це база даних, що використовує сховище безпосередньо в сегментах S3 і не має кластерів серверів, що працюють у фоновому режимі. Це робить її дійсно недорогим сервісом для створення озера даних. Структуровані формати файлів, такі як parquet або CSV, підтримують організацію даних. S3-відро містить файли, і Athena звертається до них кожного разу, коли процеси вибирають дані з бази даних.
Athena не підтримує деякі функції, які зазвичай вважаються стандартними, наприклад, оператори оновлення. Тому Athena слід розглядати як дуже простий варіант. З іншого боку, це запобігає модифікації вашого атомарного озера даних, оскільки ви просто не маєте такої можливості 😐.
Athena підтримує індексування та розділення, що робить її придатною для ефективного виконання операторів select та створення логічно відокремлених фрагментів даних (наприклад, за датою або ключовими стовпцями). Вона також легко масштабується горизонтально, оскільки це так само просто, як додавання нових сегментів до інфраструктури.

Переваги та недоліки
Переваги, які варто врахувати:
- Найбільша перевага Athena – її низька вартість (складається лише з витрат на S3-сегменти та використання SQL для кожного запиту). Це ідеальне рішення для створення доступного озера даних в AWS.
- Як нативний сервіс, Athena легко інтегрується з іншими корисними сервісами AWS, такими як Amazon QuickSight для візуалізації даних або AWS Glue Data Catalog для створення постійних структурованих метаданих.
- Найкраще підходить для виконання спеціальних запитів до великої кількості структурованих або неструктурованих даних без потреби підтримки великої інфраструктури.
Недоліки, які варто врахувати:
- Athena не дуже ефективна у швидкому поверненні складних запитів, особливо якщо вони не відповідають припущенням моделі даних про спосіб отримання даних з озера.
- Це також робить її менш гнучкою щодо майбутніх змін у моделі даних.
- Athena не підтримує додаткових розширених функцій “з коробки”. Якщо вам потрібна якась специфічна функціональність, її необхідно реалізувати додатково.
- Якщо дані з озера плануються використовувати на більш просунутому рівні, часто єдиним виходом буде поєднання Athena з іншою службою бази даних, більш придатною для цієї мети, як-от AWS Aurora або AWS Dynamo DB.
Призначення та приклади використання
Обирайте Athena, якщо ваша мета – створити просте озеро даних без розширених функцій, притаманних сховищам даних. Наприклад, якщо ви не очікуєте серйозних високопродуктивних аналітичних запитів, що регулярно виконуються в озері. Натомість, пріоритетом є наявність пулу незмінних даних з легким розширенням для зберігання.
Вам не потрібно турбуватися про брак місця. Вартість зберігання S3-відер можна ще зменшити, застосувавши політику життєвого циклу даних. Це означає переміщення даних між різними типами S3-сегментів, орієнтованими на архівні цілі, з повільнішим часом відгуку, але меншими витратами.
Чудова особливість Athena – вона автоматично створює файл з даними, які є результатом SQL-запиту. Цей файл можна використовувати для будь-яких цілей. Тож це хороший варіант, якщо у вас є багато лямбда-сервісів, які обробляють дані в кілька етапів. Кожен результат лямбди автоматично буде представлений у форматі структурованого файлу, готового до подальшої обробки.
Athena є гарним вибором, коли велика кількість необроблених даних надходить у вашу хмарну інфраструктуру, і вам не потрібно обробляти їх під час завантаження. Потрібно лише швидке зберігання в хмарі у зрозумілій структурі.
Інший варіант використання – створення спеціального простору для архівування даних для іншого сервісу. У цьому випадку Athena DB стане дешевим місцем резервного копіювання даних, які наразі не потрібні, але можуть знадобитися в майбутньому. У цей момент ви просто витягуєте дані та відправляєте їх далі.
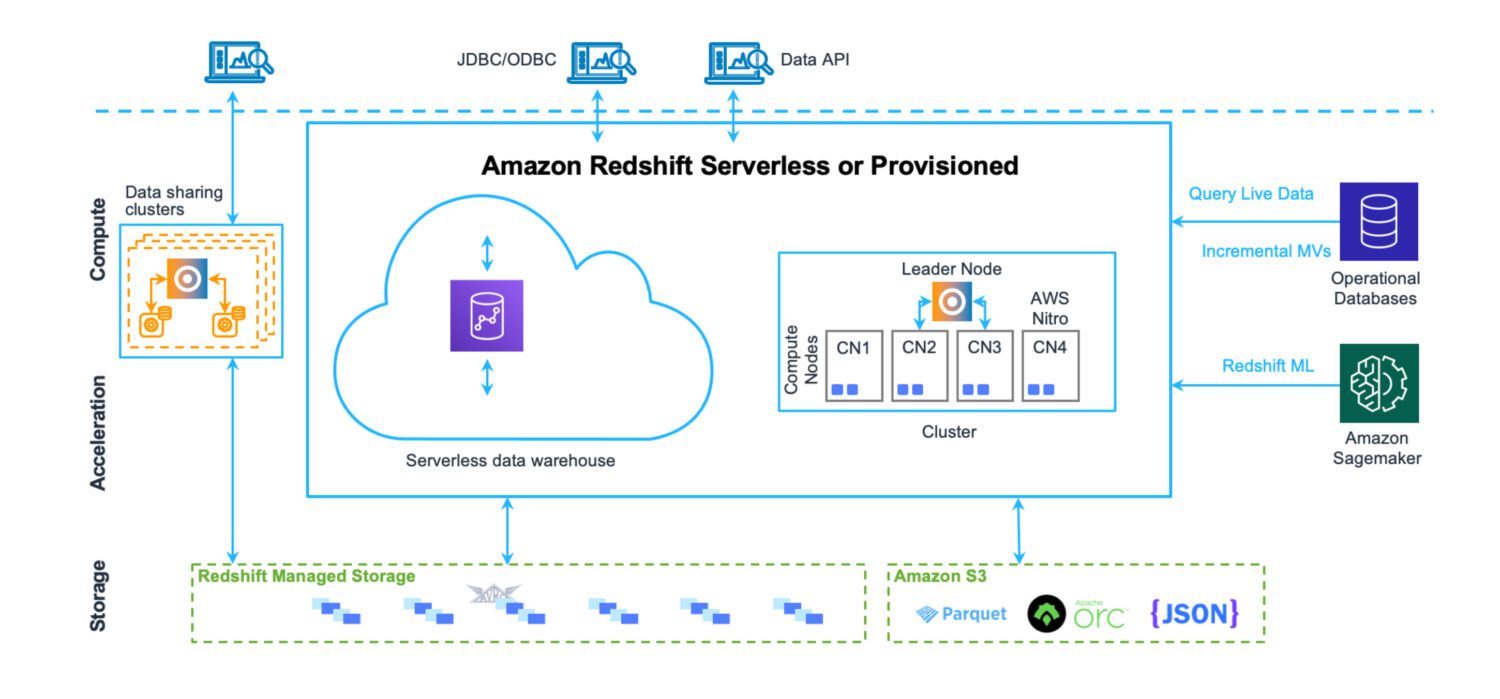
Сховище даних від AWS Redshift
 Джерело: aws.amazon.com
Джерело: aws.amazon.com
Сховище даних – це місце, де дані зберігаються у структурованому вигляді. Їх легко завантажувати та витягувати. Основна мета – виконання великої кількості складних запитів, об’єднання багатьох таблиць за допомогою складних join-операцій. Існують різноманітні аналітичні функції для обчислення різних статистичних даних на основі наявних даних. Кінцева мета – отримання прогнозів та висновків для подальшого використання у бізнесі.
Redshift – це повноцінна система сховища даних з кластерними серверами для налаштування та масштабування (горизонтально та вертикально) і системою зберігання, оптимізованою для швидкого виконання складних запитів. Хоча сьогодні Redshift можна запустити і в безсерверному режимі. Тут немає файлів на S3, це стандартний кластерний сервер бази даних із власним форматом зберігання.
Redshift має готові інструменти моніторингу продуктивності та настроювані інформаційні панелі, які можна використовувати для точного налаштування продуктивності для конкретних потреб. Адміністрування також здійснюється через окремі панелі керування. Потрібні зусилля, щоб зрозуміти всі можливі функції та налаштування, а також їхній вплив на кластер. Але це все одно простіше, ніж адміністрування серверів Oracle у випадку локальних рішень.
Хоча Redshift має певні обмеження AWS, які накладають певні ліміти на щоденне використання (наприклад, обмеження на кількість одночасних активних користувачів в одному кластері бази даних), швидкість виконання операцій певною мірою компенсує ці обмеження.

Переваги та недоліки
Переваги, які варто врахувати:
- Власний сервіс хмарного сховища даних AWS, який легко інтегрується з іншими службами.
- Центральне місце для зберігання, моніторингу та прийому різних типів джерел даних з різних систем.
- Можливість мати безсерверне сховище даних без потреби інфраструктури.
- Оптимізований для високопродуктивного аналізу та звітності. На відміну від озера даних, тут є реляційна модель даних для зберігання всіх вхідних даних.
- Механізм Redshift походить від PostgreSQL, що забезпечує високу сумісність з іншими системами баз даних.
- Корисні оператори COPY і UNLOAD для завантаження та вивантаження даних у S3-сегменти.
Недоліки, які варто врахувати:
- Redshift не підтримує велику кількість одночасних активних сеансів. Сеанси обробляються послідовно. Хоча в більшості випадків це не є проблемою через швидкість операцій, це може бути обмежуючим фактором для систем з великою кількістю активних користувачів.
- Хоча Redshift підтримує багато функцій, відомих зрілим системам Oracle, він ще не досяг їхнього рівня. Деякі з очікуваних функцій можуть бути відсутні (наприклад, тригери БД). Або Redshift підтримує їх у досить обмеженій формі (наприклад, матеріалізовані представлення).
- Якщо потрібна розширена обробка даних, її необхідно створювати з нуля. Зазвичай для цього використовують Python або Javascript. Це не так природно, як PL/SQL у випадку Oracle, де навіть функції та процедури використовують мову, дуже схожу на SQL.
Призначення та приклади використання
Redshift може стати вашим центральним сховищем для всіх різноманітних джерел даних, що раніше існували поза хмарою. Це надійна заміна попередніх рішень для сховищ даних Oracle. Оскільки це реляційна база даних, міграція з Oracle є досить простою операцією.
Якщо у вас є існуючі рішення для сховищ даних у багатьох місцях, які не є уніфікованими з точки зору підходу, структури чи набору загальних процесів для роботи з даними, Redshift – чудовий вибір.
Він дозволить об’єднати всі різноманітні системи зберігання даних з різних локацій під одним дахом. Можна розділити їх за країнами, щоб дані залишалися безпечними та доступними лише для тих, кому вони потрібні. Але водночас це дозволить створити уніфіковане складське рішення для всіх корпоративних даних.
Інший випадок – створення платформи сховища даних з широкою підтримкою самообслуговування. Йдеться про набір обробок, які створюють окремі користувачі системи. Але при цьому вони не є частиною спільного платформного рішення. Такі сервіси залишаються доступними лише для їх творця або групи осіб, визначених при створенні. Вони ніяк не впливають на інших користувачів.
Ознайомтеся з нашим порівнянням між Datalake і Datawarehouse.
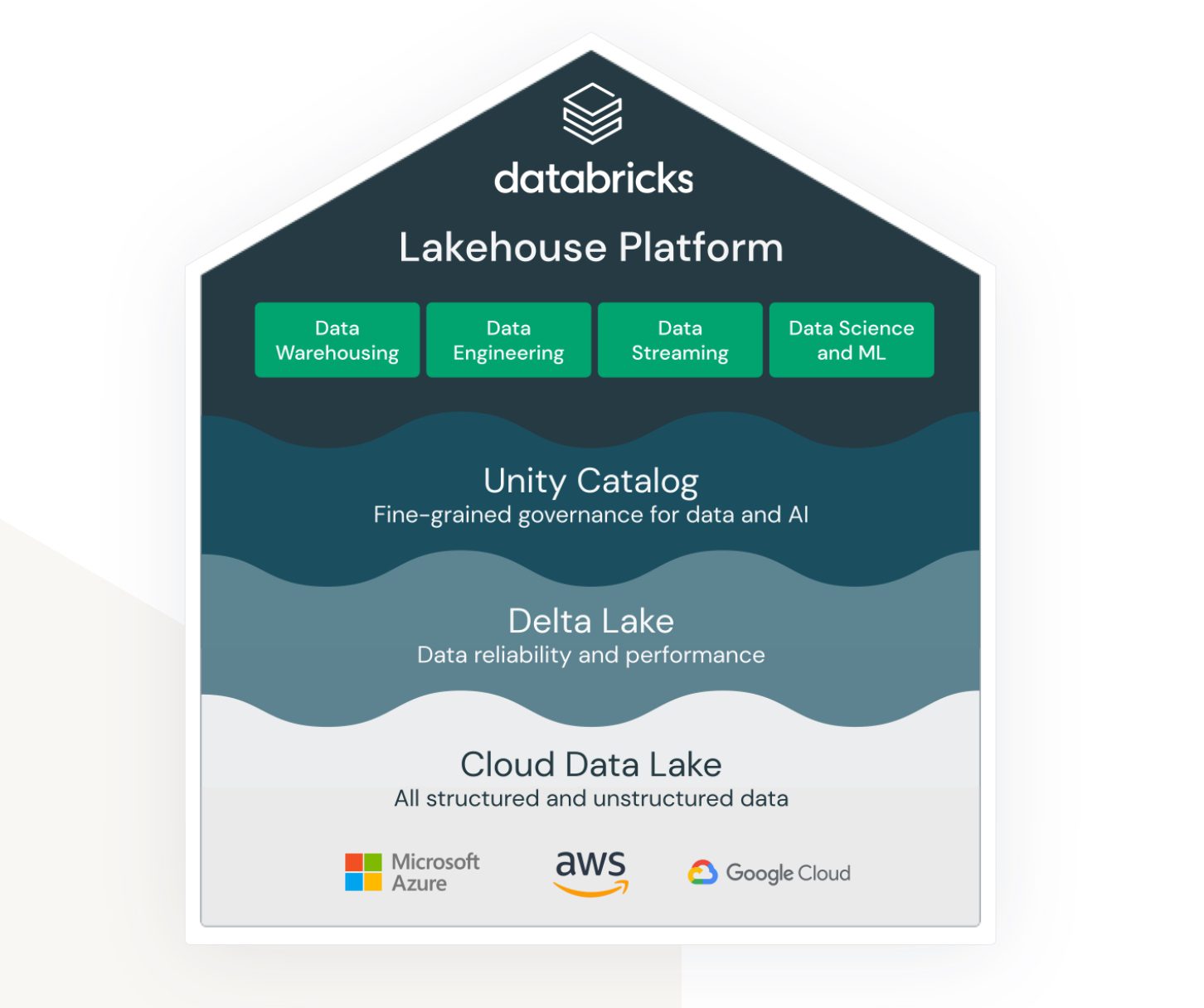
Lakehouse від Databricks на AWS
 Джерело: databricks.com
Джерело: databricks.com
Lakehouse – це термін, тісно пов’язаний із сервісом Databricks. Хоч це і не нативний сервіс AWS, він чудово працює в екосистемі AWS і надає різні можливості підключення та інтеграції з іншими сервісами AWS.
Databricks прагне об’єднати (раніше) дуже різні області:
- Рішення для зберігання неструктурованих, напівструктурованих та структурованих даних в озері даних.
- Рішення для сховища даних зі структурованими та швидкодоступними даними для запитів (також називається Delta Lake).
- Рішення для підтримки аналітики та машинного навчання з використанням озера даних.
- Управління даними для всіх вищезазначених областей із централізованим адмініструванням та готовими інструментами підтримки продуктивності для різних типів розробників та користувачів.
Це спільна платформа, яку можуть використовувати інженери даних, розробники SQL і спеціалісти з машинного навчання. Кожна з цих груп має свій набір інструментів для виконання своїх завдань.
Databricks прагне стати універсальним рішенням, поєднуючи переваги озера та сховища даних в одному рішенні. Крім того, він надає інструменти для тестування та запуску моделей машинного навчання безпосередньо на вже створених сховищах даних.

Переваги та недоліки
Переваги, які варто врахувати:
- Databricks – це високомасштабована платформа даних. Вона масштабується залежно від розміру робочого навантаження, навіть автоматично.
- Це середовище для співпраці вчених, інженерів даних і бізнес-аналітиків. Можливість працювати в одному середовищі є значною перевагою. Це не тільки спрощує організаційні питання, але й допомагає заощадити кошти, необхідні для окремих середовищ.
- AWS Databricks легко інтегрується з іншими сервісами AWS, такими як Amazon S3, Amazon Redshift і Amazon EMR. Це дозволяє легко передавати дані між службами та використовувати всі переваги хмарних сервісів AWS.
Недоліки, які варто врахувати:
- Databricks може бути складним у налаштуванні та управлінні, особливо для користувачів, незнайомих з обробкою великих даних. Потрібен значний рівень технічної експертизи, щоб використовувати платформу на повну.
- Хоча Databricks є економічно ефективним з точки зору моделі “оплата за використання”, він все одно може бути дорогим для великомасштабних проектів обробки даних. Вартість використання платформи може швидко зрости, особливо якщо користувачам потрібно збільшити обсяг ресурсів.
- Databricks надає ряд готових інструментів і шаблонів, але це може бути обмеженням для користувачів, яким потрібні додаткові можливості налаштування. Платформа може не підходити користувачам, яким потрібна більша гнучкість та контроль над робочими процесами обробки великих даних.
Призначення та приклади використання
AWS Databricks найкраще підходить для великих корпорацій з великим обсягом даних. Тут платформа може задовольнити вимоги щодо завантаження та контекстуалізації різних джерел даних з різних зовнішніх систем.
Часто вимогою є надання даних у режимі реального часу. Це означає, що з моменту появи даних у вихідній системі процеси негайно запускаються, обробляють і зберігають дані в Databricks миттєво або з мінімальною затримкою. Якщо затримка перевищує одну хвилину, це вважається обробкою майже в реальному часі. В обох випадках, платформа Databricks часто може це забезпечити, завдяки великій кількості адаптерів та інтерфейсів реального часу, що підключаються до різноманітних інших нативних служб AWS.
Databricks також легко інтегрується з системами Informatica ETL. Якщо організація вже активно використовує екосистему Informatica, Databricks виглядає як хороше доповнення до платформи.
На завершення
Оскільки обсяг даних продовжує зростати, корисно знати, що існують рішення, здатні ефективно з цим впоратися. Те, що колись було кошмаром для адміністрування та підтримки, тепер вимагає мінімальної адміністративної роботи. Команда може зосередитися на створенні цінності з даних.
Залежно від ваших потреб, оберіть сервіс, що найкраще їх задовольняє. Хоча AWS Databricks – це рішення, якого, ймовірно, доведеться дотримуватися, інші альтернативи є досить гнучкими, особливо в безсерверних режимах. Згодом можна легко перейти до іншого рішення.