Принципи роботи алгоритмів обробки природної мови (NLP)
Розуміння людської мови є складним завданням для машин. Це пов’язано з наявністю великої кількості абревіатур, різноманітних значень, підтекстів, граматичних правил, контексту, сленгу та багатьох інших мовних особливостей.
Однак, багато сучасних бізнес-процесів і операцій залежать від машинної обробки та вимагають ефективної взаємодії між людьми та комп’ютерами.
Тому виникла потреба в технології, яка б допомагала комп’ютерам декодувати людську мову та спрощувала її аналіз.
Саме тут на допомогу приходить обробка природної мови, або алгоритми NLP. Ці алгоритми дозволяють комп’ютерним програмам розуміти різні людські мови, незалежно від того, чи вони записані, чи вимовлені.
NLP використовує різноманітні алгоритми для аналізу мови. З розвитком цих алгоритмів, NLP став важливою складовою штучного інтелекту (ШІ), допомагаючи оптимізувати роботу з неструктурованими даними.
У цій статті ми детальніше розглянемо NLP та деякі з найпопулярніших алгоритмів, які використовуються в цій сфері.
Отже, почнемо!
Що таке NLP?
Обробка природної мови (NLP) – це міждисциплінарна галузь, що об’єднує інформатику, лінгвістику та штучний інтелект. Вона спрямована на забезпечення взаємодії між людською мовою та комп’ютерами. NLP допомагає програмувати машини для аналізу та обробки великих обсягів даних, пов’язаних з природною мовою.
Іншими словами, NLP – це передова технологія, що дозволяє комп’ютерам розуміти, аналізувати та інтерпретувати людську мову. Вона надає машинам можливість опрацьовувати як письмові тексти, так і розмовну мову. Завдяки NLP комп’ютери можуть виконувати різноманітні завдання, такі як переклад, розпізнавання мовлення, створення резюме, сегментація тем та багато інших.
Однією з ключових переваг NLP є здатність виконувати всі ці завдання в режимі реального часу за допомогою різних алгоритмів. Ця технологія об’єднує машинне навчання, глибоке навчання та статистичні моделі з обчислювальним моделюванням на основі лінгвістичних правил.
Алгоритми NLP дозволяють комп’ютерам обробляти людську мову, використовуючи текстові або голосові дані, та декодувати їхній зміст для різних цілей. Здатність комп’ютерів до інтерпретації настільки розвинулась, що вони можуть навіть розпізнавати емоції та наміри, що стоять за текстом. NLP також може передбачати наступні слова або фрази, які людина може використовувати під час написання або розмови.
Ця технологія існує вже кілька десятиліть, і за цей час вона значно покращила свою точність. Коріння NLP сягають лінгвістики та навіть допомогли розробникам створити пошукові системи для інтернету. З розвитком технологій сфера застосування NLP постійно розширюється.
Сьогодні NLP використовується у багатьох галузях, від фінансів, пошукових систем та бізнес-аналітики до охорони здоров’я та робототехніки. Крім того, NLP є невід’ємною частиною багатьох сучасних систем, включаючи GPS з голосовим управлінням, чат-ботів для обслуговування клієнтів, цифрових помічників, перетворення мови в текст та багато іншого.
Принцип дії NLP
NLP – це динамічна технологія, яка використовує різноманітні методи для перетворення складної людської мови у форму, зрозумілу для комп’ютерів. Вона використовує штучний інтелект для обробки та перекладу письмових або усних слів, щоб їх могли зрозуміти машини.
Подібно до того, як люди використовують мозок для обробки вхідних даних, комп’ютери застосовують спеціалізоване програмне забезпечення для обробки вхідних даних і отримання зрозумілого результату. NLP працює в два етапи: обробка даних та розробка алгоритму.
Обробка даних – це початковий етап, на якому вхідні текстові дані готуються та очищуються, щоб машина могла їх проаналізувати. Дані обробляються таким чином, щоб виділити всі особливості введеного тексту та зробити його придатним для використання комп’ютерними алгоритмами. По суті, етап обробки даних готує дані у формі, яку може зрозуміти машина.
На цьому етапі використовуються такі техніки:
Джерело: Амазин
- Токенізація: вхідний текст поділяється на малі блоки (токени), щоб NLP міг з ними працювати.
- Видалення стоп-слів: ця техніка видаляє загальновживані слова (стоп-слова) з тексту, залишаючи лише важливу інформацію.
- Лемматизація та стемінг: ці процеси зводять слова до їх кореневої форми, що полегшує їх обробку комп’ютерами.
- Позначення частин мови: слова ідентифікуються як іменники, прикметники, дієслова тощо, що допомагає у подальшій обробці.
Після першого етапу, на наступному етапі розробляється алгоритм, за яким машина може остаточно обробити дані. Серед усіх алгоритмів NLP, що використовуються для обробки попередньо підготовлених слів, широко застосовуються системи на основі правил та машинного навчання:
- Системи на основі правил: ці системи використовують лінгвістичні правила для остаточної обробки слів. Це старий, але досі актуальний алгоритм.
- Системи на основі машинного навчання: це більш прогресивний підхід, що поєднує нейронні мережі, глибоке навчання та машинне навчання для автоматичного визначення правил обробки слів. Використовуючи статистичні методи, алгоритм самостійно налаштовує процес обробки на основі навчальних даних.
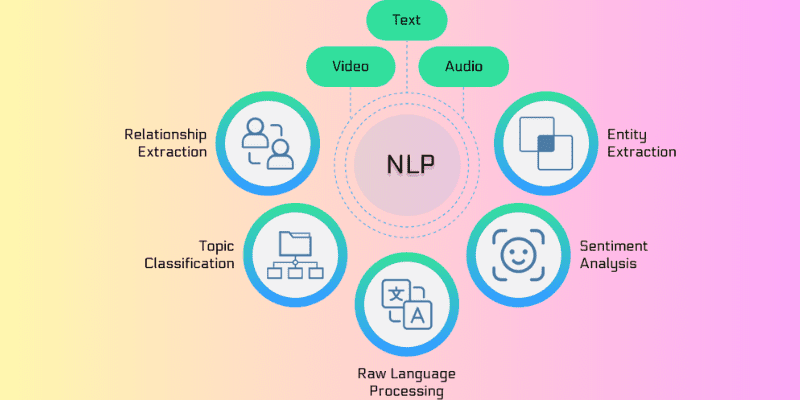
Різні категорії алгоритмів NLP
Алгоритми NLP – це набори інструкцій, заснованих на машинному навчанні, які застосовуються під час обробки природної мови. Вони відповідають за розробку протоколів і моделей, що дозволяють машинам інтерпретувати людську мову.

Алгоритми NLP можуть змінюватися в залежності від підходу штучного інтелекту, а також від тренувальних даних, які вони отримують. Основне завдання цих алгоритмів – ефективно перетворювати неструктуровані вхідні дані в корисну інформацію, на якій може навчатися машина.
Алгоритми NLP використовують принципи природної мови, щоб зробити вхідні дані більш зрозумілими для машини. Вони допомагають машинам розуміти контекстне значення введених даних; інакше машина не зможе правильно виконати запит.
Алгоритми NLP поділяються на три основні категорії, і моделі ШІ вибирають одну з них залежно від підходу дослідника даних. Ці категорії:
#1. Символічні алгоритми
Символічні алгоритми є одним з основних елементів NLP. Вони аналізують значення кожного введеного тексту і використовують цю інформацію для встановлення зв’язків між різними поняттями.
Символічні алгоритми використовують символи для представлення знань та зв’язків між поняттями. Оскільки ці алгоритми використовують логіку та призначають значення словам на основі контексту, можна досягти високої точності.
Графи знань відіграють важливу роль у визначенні концепцій мови введення разом зі зв’язком між цими концепціями. Завдяки здатності правильно визначати поняття та легко розуміти контексти слів, цей алгоритм допомагає створювати XAI (Explainable AI).
Однак символічні алгоритми мають обмеження і не можуть легко розширювати набір правил.
#2. Статистичні алгоритми
Статистичні алгоритми допомагають машинам обробляти тексти, розуміти їхній зміст і виявляти значення. Це ефективний підхід, що допомагає машинам вивчати людську мову шляхом розпізнавання закономірностей та тенденцій у великих обсягах текстових даних. Такий аналіз дозволяє машинам передбачати, яке слово, ймовірно, буде використане після поточного в режимі реального часу.
Від розпізнавання мовлення, аналізу настроїв та машинного перекладу до підказок при наборі тексту, статистичні алгоритми застосовуються у багатьох сферах. Основною причиною їх популярності є можливість роботи з великими масивами даних.
Крім того, статистичні алгоритми можуть визначити, чи схожі два речення в абзаці за змістом і яке з них краще використати. Однак основним недоліком цього алгоритму є його залежність від розробки складних функцій.
#3. Гібридні алгоритми
Гібридні алгоритми поєднують можливості символічних та статистичних підходів для досягнення кращих результатів. Використовуючи переваги обох підходів, можна мінімізувати їхні недоліки, що важливо для забезпечення високої точності.
Існує декілька способів поєднання цих підходів:
- Символічна підтримка машинного навчання
- Машинне навчання підтримує символіку
- Символічне та машинне навчання працюють паралельно
Символічні алгоритми можуть підтримувати машинне навчання, допомагаючи моделі навчатися мові ефективніше. Машинне навчання, у свою чергу, може створювати початковий набір правил для символічного підходу, що спрощує роботу фахівця з даних.
Коли символічний та машинний підходи працюють разом, вони забезпечують кращі результати, гарантуючи правильне розуміння тексту моделями.
Найкращі алгоритми NLP
Існує багато алгоритмів NLP, які допомагають комп’ютерам імітувати розуміння людської мови. Ось деякі з найефективніших алгоритмів:
#1. Моделювання теми
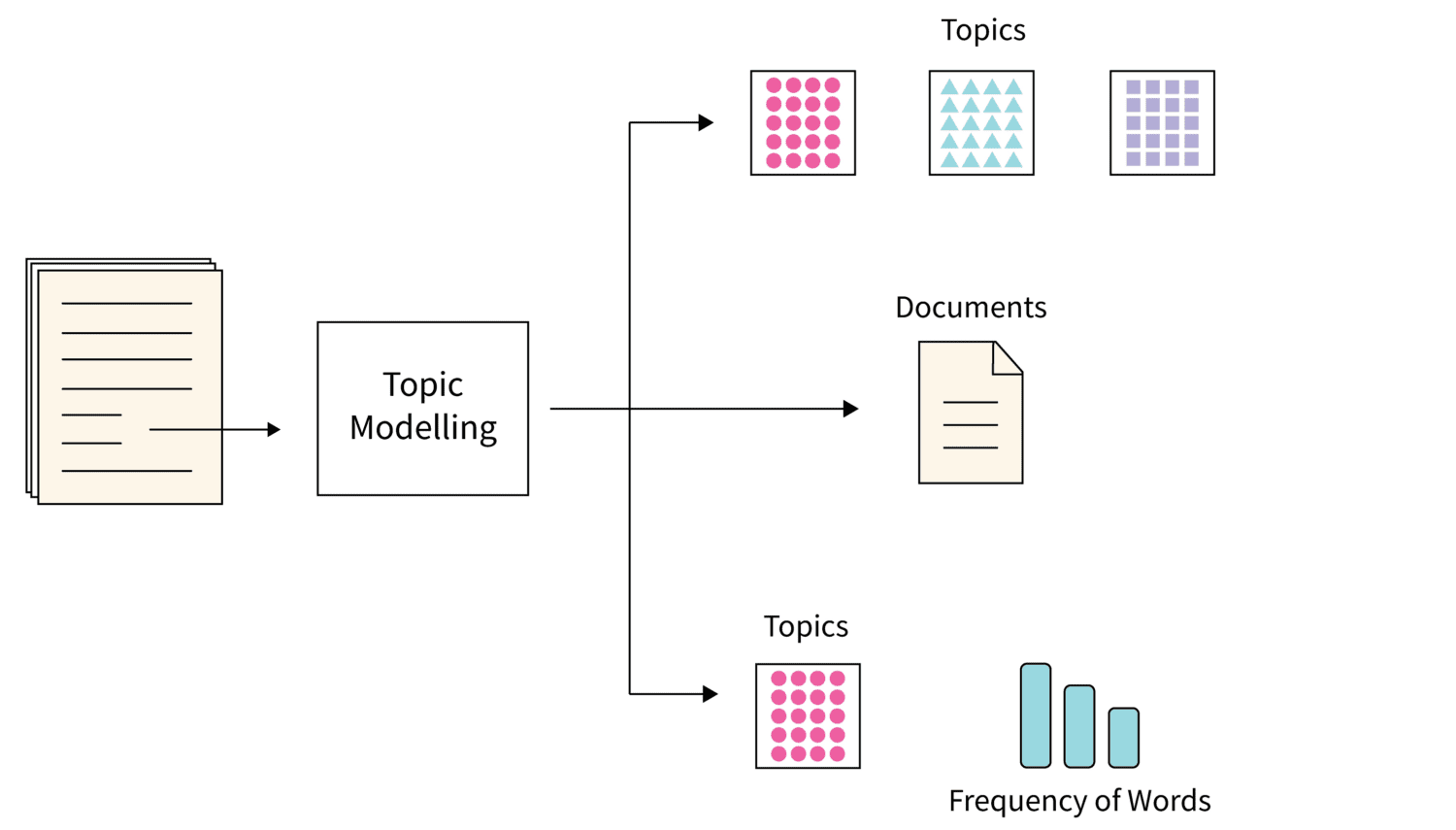
Джерело зображення: Scaler
Моделювання теми – це алгоритм, що використовує статистичні методи NLP для виявлення тем або основних ідей у великих масивах текстових документів.
По суті, він допомагає машинам знаходити загальну тему, що об’єднує певний набір текстів. Оскільки кожен набір документів може містити кілька тем, цей алгоритм аналізує набори слів для їх виявлення.
Розподіл Діріхле (LDA) є популярним вибором для моделювання тем. Це алгоритм машинного навчання без учителя, що допомагає аналізувати та організовувати великі обсяги даних, які складно обробити людині.
#2. Короткий виклад тексту
Це важлива техніка NLP, де алгоритм створює короткий, але змістовний виклад тексту. Це дозволяє швидко отримати всю необхідну інформацію, не читаючи кожен рядок.
Узагальнення тексту можна здійснити двома способами:
- Екстрактивне узагальнення: машина витягує ключові слова та фрази з документа без зміни їх структури.
- Абстрактне узагальнення: створюються нові слова та фрази, що відображають основний зміст тексту.
#3. Аналіз настроїв
Цей алгоритм NLP допомагає машинам зрозуміти емоційне забарвлення або наміри користувача в тексті. Він популярний у різних бізнес-моделях ШІ, оскільки допомагає компаніям аналізувати відгуки клієнтів.
Розуміючи наміри клієнтів у текстових або голосових повідомленнях, моделі ШІ можуть аналізувати їхні почуття та допомагати компаніям ефективно реагувати на їхні потреби.
#4. Вилучення ключових слів
Вилучення ключових слів – це алгоритм NLP, що допомагає ідентифікувати важливі слова та фрази у великих масивах текстових даних.
Існують різні алгоритми вилучення ключових слів, такі як TextRank, Term Frequency та RAKE. Деякі алгоритми можуть виділяти додаткові слова, а інші – зосереджуватися на вилученні ключових слів на основі змісту тексту.
Кожен з алгоритмів вилучення ключових слів використовує різні теоретичні та фундаментальні методи. Це корисна технологія для зберігання, пошуку та отримання інформації з неструктурованих даних.
#5. Графи знань
Багато хто вважає графи знань одними з найкращих алгоритмів NLP. Це потужна техніка, що використовує трійки для зберігання інформації.
Цей алгоритм поєднує три елементи – суб’єкт, предикат та сутність. Створення графа знань не обмежується однією технікою; для більшої ефективності використовуються численні методи NLP.
#6. TF-IDF
TF-IDF – це статистичний алгоритм NLP, що оцінює важливість слова для конкретного документа. Ця техніка передбачає множення двох значень:
- Частота термінів (TF): показує, скільки разів слово з’являється в документі. Стоп-слова зазвичай мають високу частоту.
- Обернена частота документа (IDF): виділяє слова, що є специфічними для певного документа, та рідко зустрічаються в цілому наборі документів.
#7. Хмара слів
Хмара слів – це візуалізаційний алгоритм NLP, де важливі слова виділяються та відображаються у вигляді таблиці.
Основні слова у документі друкуються великим шрифтом, а менш важливі – дрібним. Іноді найменш важливі слова навіть не відображаються.
Навчальні матеріали
Якщо ви хочете дізнатися більше про обробку природної мови (NLP), ви можете звернути увагу на наступні курси та книги:
#1. Наука про дані: обробка природної мови в Python

Цей курс від Udemy отримав високу оцінку від студентів та розроблений Lazy Programmer Inc. Він охоплює основи NLP та алгоритми NLP, а також навчає аналізу настроїв. Загальна тривалість курсу становить 11 годин 52 хвилини і включає 88 лекцій.
#2. Обробка природної мови: NLP із трансформаторами на Python
Цей популярний курс від Udemy навчає не тільки NLP з використанням моделей трансформаторів, а й дає змогу створювати власні моделі. Курс повністю висвітлює NLP, включаючи 11,5 годин відео та 5 статей. Також розглядаються методи створення векторів та попередньої обробки текстових даних для NLP.
#3. Обробка природної мови за допомогою трансформаторів
Книга була випущена в 2017 році і призначена для дослідників та програмістів, які хочуть вивчити NLP. Після її прочитання ви зможете будувати та оптимізувати моделі трансформаторів для різних завдань NLP. Також розглянуто застосування трансформаторів для міжмовного трансферного навчання.
#4. Практична обробка природної мови
У цій книзі автори пояснюють завдання, проблеми та підходи до розв’язання задач NLP. Також розглядаються питання впровадження та оцінки різних застосувань NLP.
Висновок
NLP є невід’ємною частиною сучасного світу штучного інтелекту, допомагаючи машинам розуміти та інтерпретувати людську мову. Алгоритми NLP використовуються в різних сферах, від пошукових систем та ІТ до фінансів та маркетингу.
На додаток до вищезгаданої інформації, я також перерахував деякі з найкращих курсів і книг з NLP, які допоможуть вам поглибити свої знання в цій області.