Google Search Console (GSC) є надзвичайно корисним інструментом для фахівців з SEO, які прагнуть глибоко аналізувати ефективність веб-сайту.
Впровадження регулярних виразів (REGEX) значно розширило можливості отримання цінних даних з контенту, одночасно відкриваючи нові перспективи для його створення.
Функція REGEX була довгоочікуваною в сфері веб-аналітики, оскільки вона дозволяє фільтрувати конкретні елементи з будь-якої URL-адреси, що раніше було складним або навіть неможливим.
У цій статті ми розглянемо поради та рекомендації щодо ефективного використання REGEX в Google Search Console. Ви також ознайомитеся з різними наборами операторів, які можна комбінувати з кодами REGEX для досягнення бажаного аналізу.
REGEX, або регулярний вираз: детальний огляд
Google Search Console – це безкоштовний сервіс, розроблений для веб-майстрів з метою моніторингу продуктивності їхніх веб-сайтів. Він надає вичерпні звіти про клікабельність сайту, покази, кількість кліків🖱️ та рейтинги ключових слів, що дозволяє оцінити ефективність SEO-кампаній.
Раніше існували певні обмеження щодо фільтрації даних про ефективність URL-адрес. GSC дозволяв експортувати лише до 1000 рядків для аналізу. Можна було фільтрувати лише окремі частини URL-адреси, такі як шлях, властивості домену або префікси, але складніші структури та варіації були недоступні.
Регулярні вирази (Regex) є цінним доповненням до GSC. Їхня мета полягає в тому, щоб надати SEO-спеціалістам інструмент, за допомогою якого вони могли б отримати глибше розуміння роботи та ефективності веб-сайту.
Регулярний вираз дозволяє виявляти важливі деталі SEO веб-сайту, застосовуючи ці коди до сторінок або фільтрів запитів. Коди складаються з метасимволів, які містять рядок, пов’язаний з параметром фільтрації. Після введення регулярного виразу на панелі відображається відповідний результат, який можна зберегти для подальшого використання.
Переваги використання Regex в GSC
Головною метою роботи в Google Search Console є аналіз сайту з технічної точки зору. SEO-фахівці використовують різноманітні інструменти та методи для створення ефективної стратегії оптимізації, яка допомагає веб-сайту займати високі позиції📈 в пошукових системах і залучати трафік.
Регулярні вирази надають додаткову перевагу, спрощуючи процес збору корисних даних, які можна використовувати для вдосконалення стратегій оптимізації. Ось деякі з можливостей аналізу за допомогою звітів Regex:
✨ Застосовуючи коди регулярних виразів у запитах, ви можете визначити обсяг пошуку для конкретних ключових слів або фраз. Це допоможе вам генерувати нові ідеї для контенту вашого блогу та збільшувати трафік.
✨ Коди регулярних виразів економлять час SEO-фахівцям, які працюють у великих компаніях і мають справу з великими обсягами веб-даних. Для сортування запитів або сторінок відповідно до певних критеріїв достатньо лише кількох метасимволів і рядків у правильному синтаксисі.
✨ Однією з ключових переваг є можливість працювати з типовими комбінаціями слів, речень та URL-адрес. Ці символи потрібно правильно розташувати, щоб створити робочий регулярний вираз.
✨ Безсумнівно, це дозволяє отримувати глибшу інформацію про ваш веб-сайт, включаючи ефективні та неефективні сторінки, а також аналізувати тенденції.
✨ Ви можете застосовувати коди регулярних виразів до спеціальних звітів, щоб відстежувати потік трафіку на веб-сторінках за конкретними запитами. Це дозволить вашій команді працювати більш цілеспрямовано.
Ви можете створити різні комбінації символів Regex для визначення коду та використовувати їх для аналізу та оптимізації вашого веб-сайту.
Де використовувати Regex в Google Search Console?
Щоб використовувати функцію регулярних виразів у GSC, вам потрібен доступ до права власності на ваш веб-сайт. Це обов’язкова умова, оскільки ви не зможете додати його як свою власність на Google Search Console для інших аналітичних процедур.
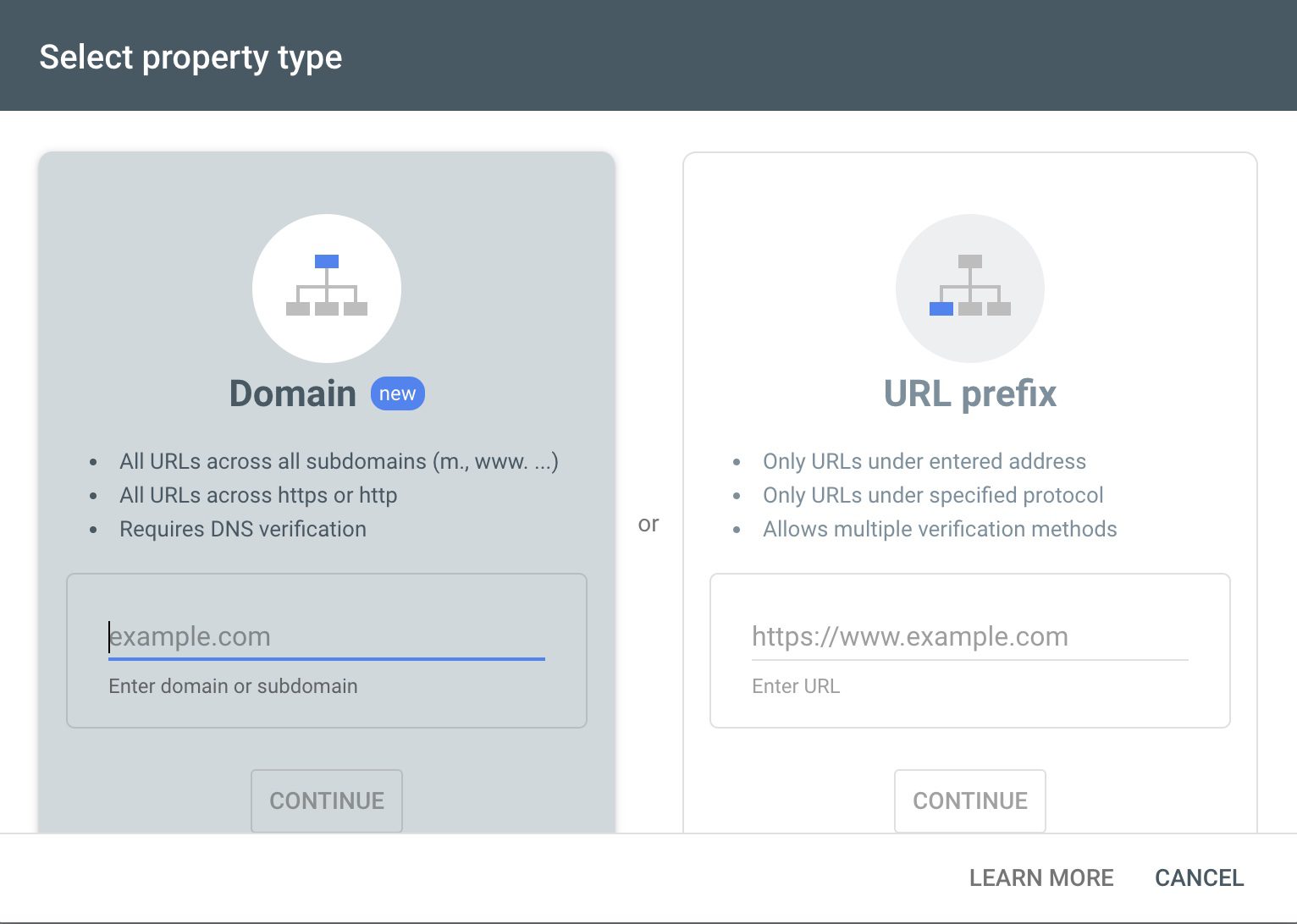
Вам потрібно увійти до Google Search Console за допомогою свого ідентифікатора Gmail і почати з додавання ресурсу, використовуючи відповідну опцію на бічній панелі. Ресурс – це веб-сайт, яким ви володієте або маєте дозвіл на доступ у консолі.
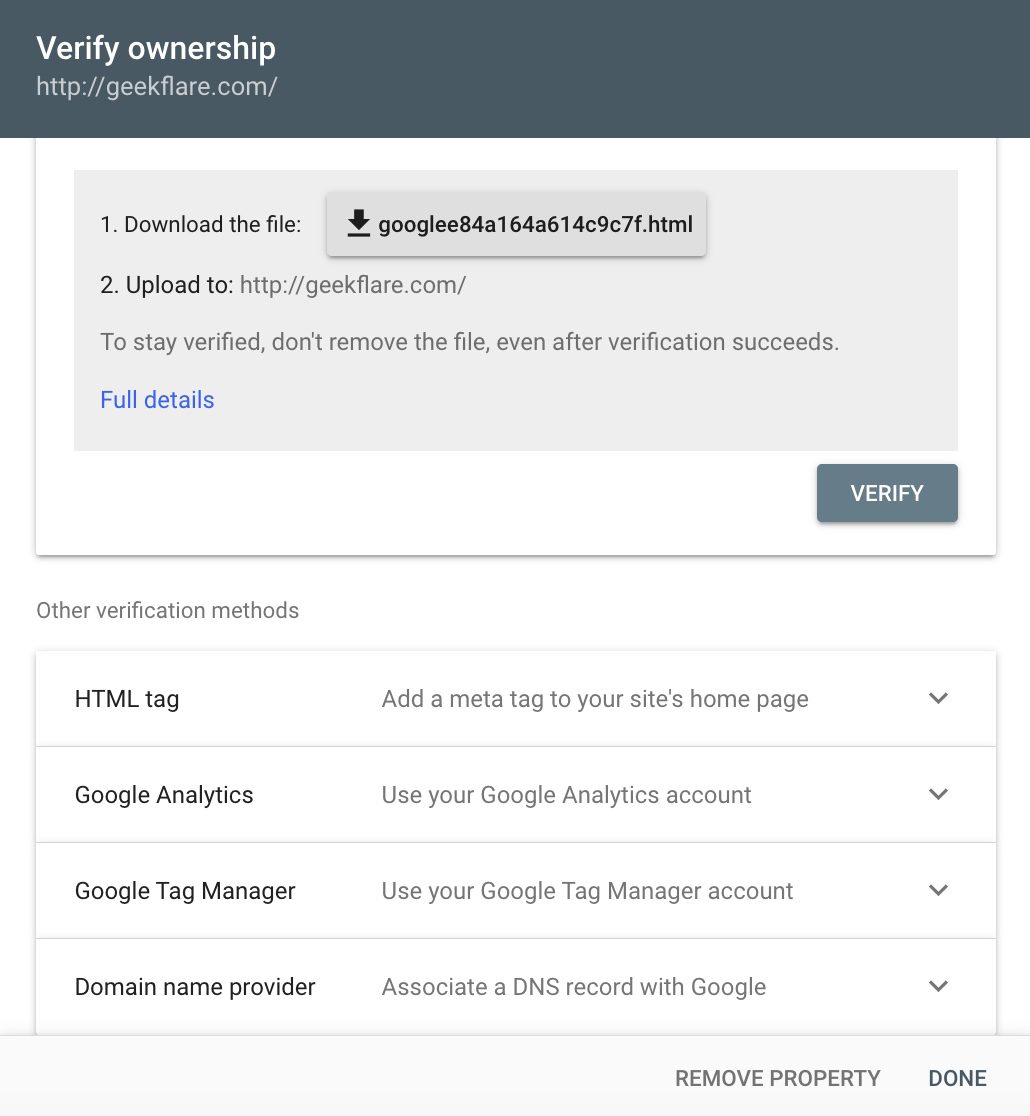
Після додавання веб-сайту або URL-адреси в наданій опції, панель попросить вас підтвердити✅ це. Процедура перевірки описана у відповідному стовпці, і після її завершення ви можете вибрати свій ресурс для подальших дій.
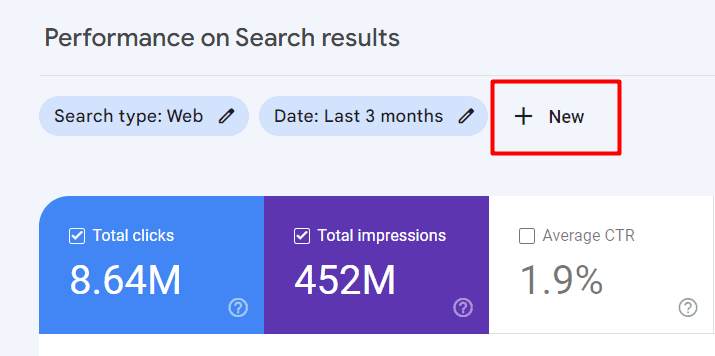
Під назвою вашого ресурсу натисніть опцію “Продуктивність” і потім кнопку “Новий” над графіком для налаштування фільтрів.
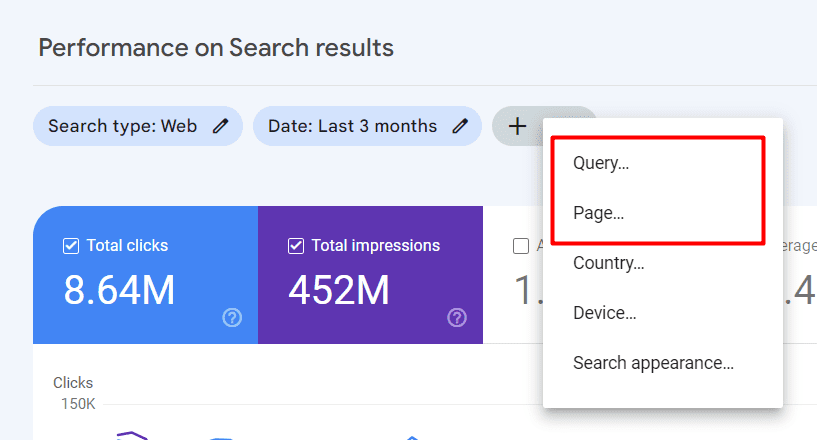
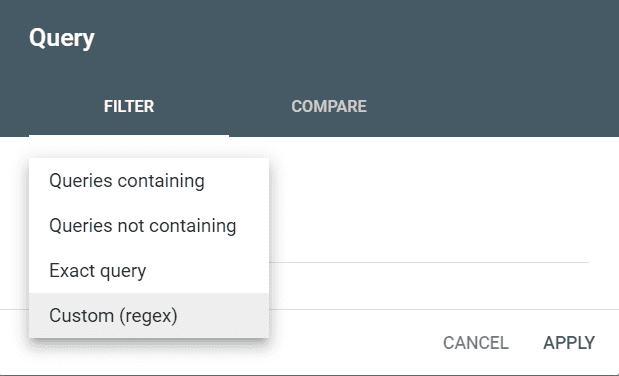
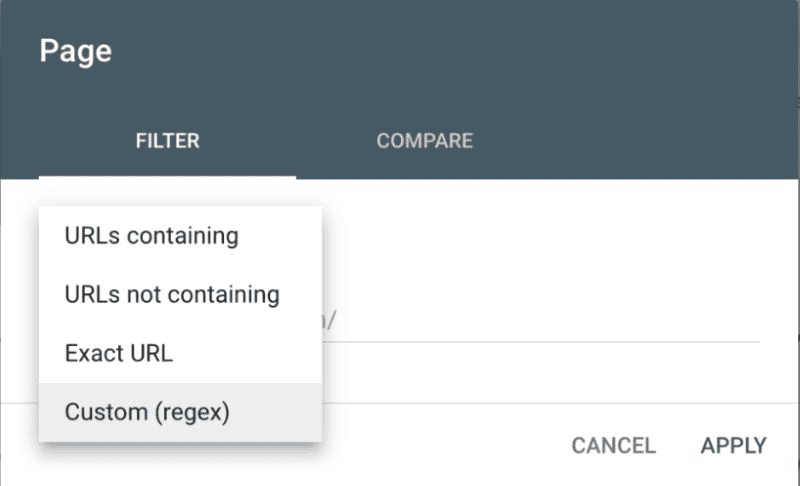
Ви можете вибрати “Запит” або “Сторінки”, щоб використовувати код регулярного виразу для фільтрації результатів.
Розшифровка символів регулярних виразів
Існує кілька наборів символів, які використовуються як регулярні вирази під час фільтрації запитів і сторінок у Google Search Console. Кожен метасимвол має різне значення в фільтрі. Якщо ви їх добре розумієте, то аналіз за допомогою Regex в GSC стане легким завданням.
У наведеній нижче таблиці представлені деякі символи та їхнє значення в коді регулярних виразів, а також відповідні приклади:
| Символ | Використання | Приклад |
| () | Круглі дужки використовуються для групування символів або виразів, також відомих як групи захоплення. | (Geek) – Ви отримаєте всі веб-сторінки зі словом “Mobile” на початку заголовка або тегу. |
| [^\mobile] | Якщо зворотна скісна риска слідує за вставкою, URL-адреси з вказаним словом mobile будуть фільтруватися. | |
| | | Символ АБО, який використовується для застосування варіантів у коді. | Мобільний|ПК – Звіт отримає всі сторінки з будь-яким із двох слів. |
| ^ | Символ вставки відповідатиме лише слову або фразі на початку рядка. | ^Мобільний – Ви отримаєте всі веб-сторінки зі словом “Мобільний” на початку заголовка чи тегу. |
| [^\mobile] | Якщо зворотна скісна риска слідує за вставкою, вона фільтруватиме URL-адреси з вказаним словом mobile. | |
| $ | Символ долара відповідатиме лише слову або фразі в кінці рядка. | Mobile$ – Ви отримаєте всі веб-сторінки зі словом “Mobile” на початку заголовка чи тегу. |
| [^\mobile] | Якщо зворотна скісна риска слідує за вставкою, URL-адреси з вказаним словом mobile будуть фільтруватися. | |
| . | Символ крапки використовується для зіставлення будь-якого окремого символу в string. | to. – Ви отримаєте всі веб-сторінки зі словом “Mobile” у кінці заголовка або тегу. |
| \ | Зворотний слеш використовується для пропуску буквального значення символів. | |
| \d | Відповідатиме сторінкам із цифрами 0-9. | |
| [xyz] | Цей код RegEx відповідатиме запиту з одним або всіма цими символами в дужках; x, y або z. | Mobile[xyz] – Код відповідатиме сторінкам, які містять усі слова в поєднанні mobile з x, y або z, наприклад mobilex, mobilezy та mobilezxy. |
| [c-m] | Цей код RegEx відповідатиме запиту з будь-якими літерами нижнього чи великого регістру між c і m. | Mobile[c-m] – Код буде співпадати зі сторінками, на яких усі слова містяться у комбінації mobile з літерами між c і m; наприклад, mobilecjg, mobileeel, mobilecdf. |
| [3-7] | Цей код RegEx відповідатиме запиту з числами від 3 до 7. | Mobile[0-9] – Код буде відповідати сторінкам, на яких усі слова містяться в поєднанні mobile з цифрами від 3 до 7; наприклад, mobile73, mobile654, mobile445. |
| [\w] | Зіставлятиме кожне слово на веб-сторінках із літерами “до”, наприклад, до, у, до. | [\w]*Мобільний[\w] – Зворотна коса риска, за якою йде літера “w” у нижньому регістрі в дужці. Це відповідатиме будь-якому слову чи символу, наприклад букві (малій і великій), цифрі чи підкресленню. |
| [\W] | Цей код регулярного виразу зіставлятиме сторінки зі словом “мобільний” з іншими словами в заголовку, мета-файлі чи статті, як-от мобільний телефон, мобільний додаток. | [\W]*Мобільний[\W] – Зворотна коса риска, за якою йде літера “W” у верхньому регістрі в дужці. Це відповідатиме всім, за винятком літер і цифр. Це символи пробілу та такі символи, як; ?:#@$%. |
Ви можете створювати різноманітні коди з цими символами для фільтрації складних запитів у GSC.
Конкретні регулярні вирази в Google Search Console
Ви можете використовувати метасимволи в Google Search Console для створення унікальних шаблонів або кодів для виконання конкретних цілей. Ось деякі з них, які ви можете спробувати у своєму порталі GSC:
🔶 ^[\w\W\s\S]{70,}$
Цей код послідовно зіставляє усі слова, цифри, символи, символи не слова, спеціальні символи, пробіли та небілі або нові рядки на сторінці. Квантор “70” вказує, що рядок повинен мати довжину не менше 70 символів.
Приклад: ці коди можна використовувати для перевірки паролів, сортування списків продуктів з детальним описом тощо.
🔶 (\w+\s){6,}\w+
Цей код регулярного виразу складається з трьох розділів. Він призначений для зіставлення слів і чисел із пробілами між ними. Таким чином, код буде витягувати рядки, які містять принаймні 6 слів або більше, наприклад, це речення; «Рядки, які містять щонайменше 6 слів або більше».
Приклад: ці коди використовуються для фільтрації статей з довгими заголовками, довгими коментарями в соціальних мережах тощо.
🔶 ^(хто|що|де|коли|чому|як)[“ “]
Цей код регулярного виразу є простим та корисним для блогерів і SEO-спеціалістів. Він зіставляє всі запити в пошукових системах, які починаються з одного із цих слів: хто, що, де, коли, чому або як. Рядок має починатися з будь-якого з цих слів, за яким слідує пробіл. Таким чином, він не витягуватиме такі слова, як “проте” або “цілий” тощо.
Приклад: ці коди підходять для вивчення ринкових тенденцій та обговорень користувачів, що дозволяє отримати ідеї для створення нового контенту.
🔶 «хто|що|де|коли|чому|як»
Цей код схожий на попередній, але тут функція шукатиме усі рядки, які містять будь-яке з цих слів, незалежно від того, чи починається рядок з цих слів, чи ні.
Приклад: код підходить для виділення сумнівних тверджень, фільтрації введених користувачем даних тощо.
🔶 .*
Крапка, за якою слідує зірочка, часто називають виразом підстановки, оскільки ви можете використовувати її для зіставлення будь-якого конкретного рядка, поставивши його під цей код.
Приклад: регулярний вираз .*Android.* витягне усі сторінки вашого ресурсу, які містять слово “Android”. Безпосереднє використання коду .* у фільтрі витягне усі сторінки, які з’явилися в пошуковій системі протягом місяця.
🔶 [^\/\.\-:0-9A-Za-z_]
Після символу вставки йде зворотна коса риска, яка виключає символи, вказані в коді. Тут код зіставляє рядки, які не містять похилої риски, цифр, крапки, двокрапки, дефіса та всіх літер у верхньому та нижньому регістрі.
Приклад: тому цей код можна використовувати для витягування URL-адрес, мета-описів або контенту, який містить спеціальні символи, наприклад &%$@.
🔶 ?i)(((є|є).(бренд|сайт|компанія)|(бренд|сайт|компанія).(є|є)).*(негідник|надійний))
Це довгий регулярний код, який містить кілька розділів. Символ “?i”, який використовується на початку коду, є прапором ігнорування регістру. Це означає, що код зіставлятиме рядки, незалежно від того, чи вони написані у верхньому чи нижньому регістрі. У дужках, що йдуть за ним, міститься кілька слів, розділених вертикальною лінією (АБО).
Код регулярного виразу виявляє запити без урахування регістру букв, які містять слова is або are, brand, company або site, а також scum або надійний.
Приклад: цей код регулярного виразу можна обережно використовувати для пошуку шаблонів запитів клієнтів. Ви зможете дізнатися, чи має ваш веб-сайт позитивні чи негативні відгуки.
🔶 (kwd1|kwd2).*
Це спрощене використання коду регулярних виразів диз’юнкції, де GSC фільтрує сторінки або запити, які містять слово kwd1 або kwd2, за яким слідує будь-яка інша літера або цифра.
Приклад: ви можете використати цей шаблон, щоб отримати сторінки на своєму веб-сайті, які містять будь-яке з цих слів, пов’язаних з іншими словами чи числами в URL-адресі, заголовку, мета-файлах або контенті.
🔶 (Ключове слово1 І Ключове слово2)
Цей код є яскравим прикладом виразу кон’юнкції. “AND” є оператором, який використовується в коді Regex. Він використовується для витягування сторінок, які містять ці два слова в одному порядку.
Приклад: ви можете застосувати цей код у GSC, щоб отримати сторінки, заголовок або мета-опис з двома конкретними словами в певному порядку.
🔶 “ключове слово1 ключове слово2”
Код підходить для пошуку фрази або точного порядку слів на веб-сторінці.
Приклад: застосуйте код у GSC, щоб знайти сторінки з назвою, описом або контентом, який містить певну фразу.
🔶 (Ключове слово1 | Ключове слово2)
Цей код складається з двох слів і вертикальної лінії. Це означає, що GSC відображатиме сторінки вашого веб-сайту, які містять або “Keyword1”, або “Keyword2”, але не обидва.
Приклад: застосуйте код, щоб отримати сторінки з вашого веб-сайту, які містять одне з двох або більше слів, розділених вертикальною лінією.
🔶 (Ключове слово1)\b(Ключове слово2)\b
Цей код регулярних виразів містить два певних слова з символом “\b”, який є символом межі слова. Він надасть сторінки з цими двома словами і жодним іншим словом, цифрою або символом між ними.
Приклад: використовуйте цей код у фільтрі GSC, щоб дізнатися про сторінки, які містять два окремих слова поспіль.
🔶 (Ключове слово1)\w+(Ключове слово2)
Код містить два слова з метасимволом “\w+” між ними, де “w” є у нижньому регістрі. Таким чином, він отримає всі сторінки, які містять ці два слова, чи то в заголовку, описі, чи в контенті, незалежно від кількості слів між ними.
Приклад: ви можете застосувати цей код, щоб витягти усі сторінки вашого веб-сайту, які містять хоча б ці два слова в заголовку, контенті або мета-файлі.
🔶 (Ключове слово)\bфраза
Це простий код регулярних виразів для зіставлення рядка зі словом у дужках, за яким слідує фраза слова. Метасимвол “\b” означає межу слова або відсутність іншого символу між заданими словами.
Приклад: цей код регулярних виразів у GSC відображатиме сторінки, які містять вказані слова в послідовності будь-де в статті, наприклад, “ключова фраза”.
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Цей код регулярних виразів містить кілька URL-адрес “a, b, c, e, g…”, розділених вертикальною лінією. Тому він фільтрує рядки з будь-якою з цих URL-адрес.
Приклад: ви можете застосувати такі шаблони у своїй панелі GSC, щоб отримати веб-сторінки, які мають певні URL-адреси в заголовку або статті.
🔶 ^(яблуко|м’яч|кіт|качина ферма)$
Цей код призначений для зіставлення початку рядка з одним із заданих слів “яблуко, м’яч, кіт або качина ферма”, оскільки символ вертикальної лінії розділяє їх. Він також гарантує відсутність інших слів або символів.
Приклад: ви можете використовувати код для отримання докладної інформації про сторінки, які починаються з певних ключових слів.
🔶 .*/$
Цей код регулярних виразів має на меті охопити кожен рядок, будь то слова чи числа, але він повинен закінчуватися похилою рискою.
Приклад: ви можете використовувати його для зіставлення сторінок, URL-адреси яких закінчуються похилою рискою.
🔶 .(найкращий|топ|порівняно|огляд).*
Цей код зіставляє рядки, які мають крапку на початку разом з одним із заданих слів (розділених вертикальною лінією) та іншими словами, цифрами або спеціальними символами в продовженні.
Приклад: ви можете використовувати такі шаблони регулярних виразів у комерційних звітах, щоб зрозуміти ринкові тенденції.
🔶 (купити|дешево|ціна|купити|замовити).
Цей код відповідатиме рядкам, що містять одне з наведених слів, розділених вертикальною лінією та супроводжуваних іншими словами, числами або символами.
Приклад: такі коди корисні для зіставлення транзакційних пошуків або запитів, пов’язаних з продуктами вашого веб-сайту.
🔶 (face(b|be)ook) 🔶 (f(a|e)ce(b|be)ook 🔶 (fa(c|s)(e|i)book)
Ці коди містять комбінацію слів у круглих дужках разом із символами вертикальної лінії між ними.
Перший регулярний вираз відповідатиме рядкам, які містять слово “face”, за яким слідують “b” або “be” і закінчуються на “ook”. Отже, отримані сторінки матимуть слово facebook або facebeook.
Другий регулярний вираз відповідатиме рядкам, у яких є слово “f”, за яким слідує “a” або “e”, потім “ce”, потім “b” або “be”, і закінчується на “ook”. Отже, отримані сторінки матимуть будь-яку з цих комбінацій, наприклад, facebook, fecebook, facebeook або fecebeook.
Третій регулярний вираз відповідає рядкам, у яких є слово “fa”, за яким слідує “c” або “s”, а потім “e” або “I” і закінчується на “book”. Отже, отримані сторінки матимуть будь-яку з цих комбінацій, наприклад, facebook, facibook, fasebook або fasibook.
Приклад: ви можете використовувати ці коди для зіставлення можливих орфографічних помилок на ваших веб-сторінках.
🔶 .wp-.
Цей код відповідає рядкам з крапкою, за якою слідує “wp-” та інші символи.
Приклад: підходить для вилучення сторінок з URL-адресами WordPress.
🔶 .*/url-1/.* проти .*/url-2/.*
Цей код містить дві різні URL-адреси з символом регулярного виразу порівняння. Він витягне дві конкретні URL-адреси з вашого веб-сайту для порівняння їхніх показників.
Приклад: ви можете застосувати цей код для порівняння трафіку, кількості користувачів та іншого прогресу між двома конкретними веб-сторінками на вашому сайті.
Інші нестандартні регулярні вирази
🔺 (?i)\bключове слово\b
Цей код зіставляє рядок, який містить слово “ключове слово”. Пошук виконується незалежно від чутливості до регістру слова на веб-сторінках.
🔺 “фраза”
Цей код просто зіставляє сторінки, які містять задану фразу.
🔺 \w{5}
Код зіставляє запити, які містять символи з 5 слів.
🔺 \d{3}
Цей код відповідає запитам, що містять рівно 3 цифри.
🔺 ([^” “]*)
Цей код регулярних виразів зіставляє рядки, які не містять жодних символів у лапках.
🔺 (?i)\b(ключове слово1|ключове слово2|ключове слово3)\b
Цей наданий код зіставляє рядки, в яких є будь-яке зі слів, розділених вертикальною лінією, у верхньому або нижньому регістрі.
🔺 \W+
Код зіставляє будь-яку кількість несловесних символів, зазвичай, спеціальних символів.
🔺 \d{3,5}
Код зіставляє усі рядки, які містять числа від 3 до 5 цифр.
🔺 \b\w+\b
Код зіставляє будь-яку кількість символів слова з межами слів.
Заключні слова
Пошукова система Google стала джерелом величезної кількості інформації після введення регулярних виразів у фільтри продуктивності. Для цього потрібне лише розуміння структури кодів для отримання аналітичних звітів.
Ви можете створювати різноманітні коди регулярних виразів на своїй панелі, щоб отримувати точну інформацію про продуктивність вашого веб-сайту та використовувати її для покращення результатів.
Дізнайтеся більше про хитрощі пошуку Google, які допоможуть вам покращити пошук в Інтернеті.