Pandas — це надзвичайно популярний інструмент для обробки та аналізу даних у Python. Його активно використовують фахівці з аналізу даних, дослідники та інженери, що працюють з машинним навчанням.
Разом із бібліотекою NumPy, Pandas є однією з ключових бібліотек, знання яких необхідне кожному, хто працює у сфері обробки даних та штучного інтелекту.
У цій статті ми розглянемо, що таке Pandas, та з’ясуємо, які особливості роблять його таким затребуваним у світі аналізу даних.
Що ж таке Pandas?
Pandas — це спеціалізована бібліотека для аналізу даних, розроблена для мови програмування Python. Вона надає потужні засоби для роботи та маніпулювання даними безпосередньо у вашому коді Python. За допомогою Pandas ви можете ефективно зчитувати, змінювати, візуалізувати, аналізувати та зберігати різні типи даних.
Назва “Pandas” походить від словосполучення “Panel Data”, що є терміном з економетрики, який описує дані, отримані в результаті спостережень за кількома об’єктами протягом певного періоду часу. Бібліотеку Pandas вперше було випущено в січні 2008 року Весом Кінні, і з того часу вона стала лідером серед інструментів для обробки даних.
В основі Pandas лежать дві ключові структури даних: DataFrame (кадр даних) та Series (серія). Коли ви завантажуєте або створюєте набір даних в Pandas, він автоматично представляється у вигляді однієї з цих структур.
Далі ми детальніше розглянемо ці структури даних, з’ясуємо їх відмінності та визначимо, коли яка з них є найбільш підходящою.
Основні структури даних
Як вже зазначалося, усі дані в Pandas представлені у вигляді однієї з двох структур: DataFrame або Series. Розгляньмо ці структури детальніше.
Кадр даних (DataFrame)
Приклад кадру даних, створений за допомогою коду, наведеного нижче:
DataFrame в Pandas — це двовимірна структура даних, яка має стовпці та рядки. Її можна порівняти з електронною таблицею в програмі для роботи з таблицями або таблицею в реляційній базі даних.
Вона складається зі стовпців, де кожен стовпець представляє окремий атрибут або характеристику у вашому наборі даних. Кожен стовпець, у свою чергу, містить набір окремих значень. Ці набори окремих значень представлені як об’єкти Series. Детальніше про структуру даних Series ми поговоримо далі у статті.
Стовпці в DataFrame мають описові імена, що дозволяє легко їх ідентифікувати. Ці імена присвоюються під час створення або завантаження кадру даних, але їх можна легко змінити в будь-який момент.
Значення в одному стовпці повинні мати однаковий тип даних, хоча стовпці в одному DataFrame можуть мати різні типи. Наприклад, стовпець з іменами в наборі даних міститиме лише рядкові значення, тоді як інший стовпець, наприклад, з віком, може зберігати цілочислові значення (int).
DataFrame також має індекс, який використовується для посилання на рядки. Значення в різних стовпцях, що мають однаковий індекс, формують рядок. За замовчуванням індекси є числовими, але їх можна перепризначити відповідно до потреб набору даних. У наведеному прикладі (зображеному вище, закодовано нижче), ми встановили стовпець “місяці” як індекс.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Серія (Series)
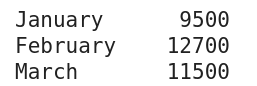
Приклад серії, створений за допомогою коду, наведеного нижче:
Як вже зазначалось, Series використовується для представлення стовпця даних в Pandas. Таким чином, Series є одновимірною структурою даних, на відміну від DataFrame, яка є двовимірною.
Хоча Series зазвичай використовується як стовпець у DataFrame, вона також може представляти набір даних самостійно, якщо цей набір даних містить лише один атрибут, представлений в одному стовпці. Іншими словами, набір даних є просто списком значень.
Оскільки Series є лише одним стовпцем, їй не обов’язково мати назву. Проте значення в Series індексуються. Аналогічно індексу DataFrame, індекс Series можна змінити, відійшовши від нумерації за замовчуванням.
У наведеному прикладі (зображеному вище, закодовано нижче) індекс було встановлено на різні місяці за допомогою методу `set_axis` об’єкта Pandas Series.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Функціональні можливості Pandas
Тепер, коли ви маєте чітке уявлення про те, що таке Pandas та які основні структури даних вона використовує, ми можемо перейти до обговорення функцій, які роблять цю бібліотеку настільки потужним інструментом для аналізу даних, і, як наслідок, надзвичайно популярною в екосистемах Data Science та машинного навчання.
#1. Маніпулювання даними
Об’єкти DataFrame та Series є змінними. Ви можете додавати або видаляти стовпці в міру необхідності. Крім того, Pandas дозволяє додавати рядки та навіть об’єднувати різні набори даних.
Ви можете виконувати різні математичні операції, такі як нормалізація даних, та логічні порівняння поелементно. Pandas також дозволяє групувати дані та застосовувати агрегатні функції, такі як середнє значення, медіана, максимум та мінімум. Це значно спрощує роботу з даними в Pandas.
#2. Очищення даних
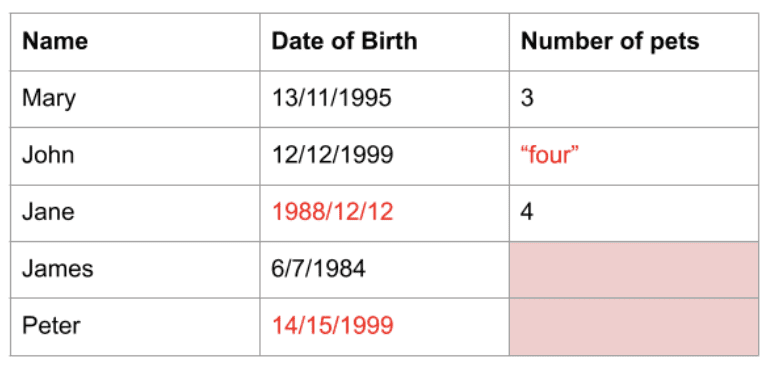
Дані, отримані з реальних джерел, часто мають значення, які ускладнюють їх обробку або не підходять для аналізу чи використання в моделях машинного навчання. Дані можуть мати неправильний тип, некоректний формат або взагалі можуть бути відсутніми. У будь-якому випадку, такі дані потребують попередньої обробки, що називається очищенням, перед тим як їх можна буде використовувати.
Pandas пропонує набір функцій, які допоможуть вам очистити ваші дані. Наприклад, у Pandas можна видалити повторювані рядки, прибрати стовпці чи рядки з відсутніми даними, а також замінити відсутні значення значеннями за замовчуванням або, наприклад, середнім значенням стовпця. Існують й інші розширення та бібліотеки, які працюють з Pandas, дозволяючи виконувати більш складні операції з очищення даних.
#3. Візуалізація даних
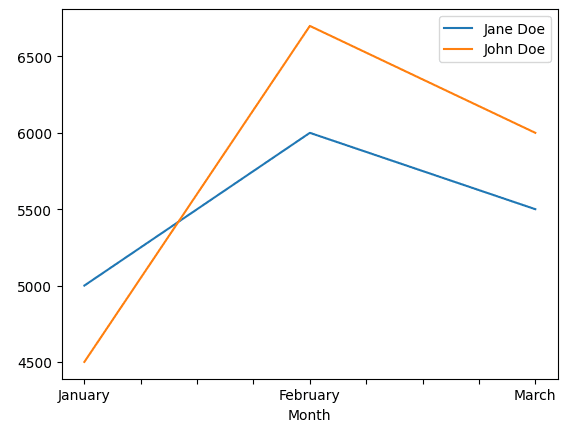
Цей графік було згенеровано за допомогою коду, наведеного нижче.
Хоча Pandas не є спеціалізованою бібліотекою для візуалізації, як Matplotlib, вона має функціонал для створення базових візуалізацій даних. І хоча вони є досить простими, у більшості випадків їх достатньо для основних потреб.
За допомогою Pandas ви можете легко будувати стовпчикові діаграми, гістограми, матриці розсіювання та інші типи діаграм. Поєднуючи це з можливостями маніпуляцій з даними в Python, ви можете створювати більш складні візуалізації для кращого розуміння своїх даних.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Аналіз часових рядів
Pandas також надає інструменти для роботи з даними, що мають часові мітки. Коли Pandas розпізнає стовпець як такий, що містить значення дати й часу, ви можете виконувати різноманітні операції, корисні при роботі з даними часових рядів.
До них належать групування спостережень за певними періодами часу та застосування до них агрегатних функцій, таких як сума або середнє значення, або отримання найраніших або останніх спостережень за допомогою `min` та `max`. Звичайно, є багато інших операцій, які можна виконувати з даними часових рядів у Pandas.
#5. Введення/виведення даних у Pandas
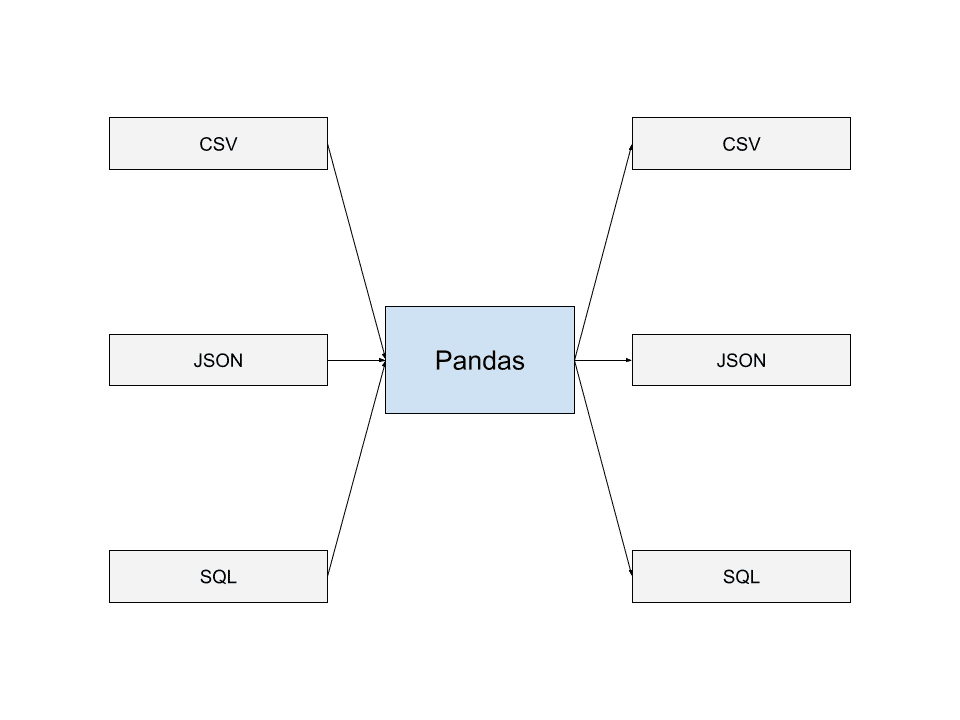
Pandas може зчитувати дані з більшості популярних форматів зберігання даних, таких як JSON, дампи SQL та CSV. Ви також можете зберігати дані у файли в багатьох з цих форматів.
Ця здатність зчитувати та записувати файли різних форматів дозволяє Pandas без проблем взаємодіяти з іншими програмами та створювати конвеєри даних, що добре інтегруються з Pandas. Це одна з причин, чому Pandas так широко використовується розробниками.
#6. Інтеграція з іншими бібліотеками
Pandas має розгалужену екосистему інструментів і бібліотек, створених на її основі, які розширюють її функціональність. Це робить Pandas ще більш потужною та корисною бібліотекою.
Інструменти в екосистемі Pandas покращують її можливості в різних областях, зокрема, очищення даних, візуалізація, машинне навчання, введення/виведення та розпаралелювання. Pandas підтримує реєстр таких інструментів у своїй документації.
Продуктивність та ефективність у Pandas
Хоча Pandas чудово справляється з більшістю операцій, в деяких випадках вона може бути досить повільною. Хорошою новиною є те, що ви можете оптимізувати свій код та пришвидшити його виконання. Для цього важливо розуміти, як влаштована Pandas.
Pandas побудована на основі NumPy, популярної бібліотеки Python для числових та наукових обчислень. Тому, як і NumPy, Pandas працює більш ефективно, коли операції векторизовані, а не коли відбувається вибірка окремих клітинок або рядків за допомогою циклів.
Векторизація — це форма паралелізації, коли одна і та ж операція застосовується до декількох точок даних одночасно. Це називається SIMD – “одна інструкція, кілька даних”. Використання переваг векторизованих операцій значно збільшить швидкість та продуктивність коду на Pandas.
Оскільки під капотом вони використовують масиви NumPy, структури даних DataFrame та Series працюють швидше, ніж їхні альтернативні словники та списки.
Стандартна реалізація Pandas використовує лише одне ядро процесора. Іншим способом пришвидшити ваш код є використання бібліотек, що дозволяють Pandas використовувати всі доступні ядра процесора. До таких бібліотек належать Dask, Vaex, Modin та IPython.
Спільнота та ресурси
Як популярна бібліотека однієї з найпопулярніших мов програмування, Pandas має велику спільноту користувачів та учасників. Як наслідок, існує багато ресурсів для вивчення цієї бібліотеки, починаючи з офіційної документації Pandas та закінчуючи численними курсами, навчальними матеріалами та книгами.
Існують також онлайн-спільноти на таких платформах як Reddit у субредітах r/Python та r/Data Science, де можна ставити питання та отримувати на них відповіді. Оскільки це бібліотека з відкритим вихідним кодом, ви можете повідомляти про проблеми на GitHub та навіть робити внесок у код.
Насамкінець
Pandas є неймовірно корисним та потужним інструментом для обробки даних. У цій статті ми спробували пояснити її популярність, розглянувши особливості, які роблять її незамінним інструментом для науковців та розробників.
Далі рекомендуємо ознайомитись з тим, як створити Pandas DataFrame.