Комбінування рішень, отриманих від кількох моделей, дозволяє ансамблевому навчанню надавати більш обґрунтовані висновки та розв’язувати широкий спектр реальних задач.
Машинне навчання (ML) дедалі глибше проникає в різноманітні сфери, від фінансів та охорони здоров’я до розробки програмного забезпечення та кібербезпеки.
Ефективне навчання моделей ML є ключем до успіху у вашій професійній діяльності або бізнесі, і існує багато підходів для досягнення цієї мети.
У цій публікації ми зосередимося на ансамблевому навчанні, його важливості, застосуваннях та технічних аспектах.
Слідкуйте за нами!
Що таке ансамблеве навчання?
У контексті машинного навчання та статистики термін “ансамбль” відноситься до методологій, що створюють різноманітні гіпотези на основі спільної навчальної бази.
Ансамблеве навчання є стратегією машинного навчання, що передбачає створення та об’єднання декількох моделей (наприклад, експертів або класифікаторів) для розв’язання обчислювальних завдань або отримання точніших прогнозів.
Метою цього підходу є підвищення точності прогнозування, покращення апроксимації функцій, класифікації та інших аспектів продуктивності моделі. Також він використовується для мінімізації ризику вибору неефективної моделі. Застосування декількох алгоритмів навчання сприяє досягненню більш точних результатів.
Значення ансамблевого навчання в ML
Помилки в моделях машинного навчання можуть виникати через такі фактори, як зміщення, дисперсія та шум. Ансамблеве навчання допомагає зменшити вплив цих факторів, забезпечуючи стабільність та точність алгоритмів ML.
Ось чому ансамблеве навчання широко застосовується у різних ситуаціях:
Вибір оптимального класифікатора
Ансамблеве навчання допомагає визначити найкращу модель або класифікатор, зменшуючи ймовірність помилки через неправильний вибір.

Існують різні типи класифікаторів, придатних для різних завдань, включаючи машини опорних векторів (SVM), багатошарові персептрони (MLP), наївні баєсівські класифікатори, дерева рішень та інші. Також доступні різні реалізації алгоритмів класифікації. Ефективність цих алгоритмів може відрізнятися залежно від навчальних даних.
Замість вибору єдиної моделі, застосування ансамблю всіх цих моделей та об’єднання їхніх результатів дозволяє уникнути використання менш ефективних варіантів.
Обробка обсягу даних
Багато методів і моделей ML можуть бути неефективними при роботі з недостатнім або надмірним обсягом даних.
Ансамблеве навчання, навпаки, може ефективно працювати в обох цих ситуаціях.
- При недостатній кількості даних можна використовувати початкове завантаження для навчання різних класифікаторів на різних зразках даних.
- При обробці великих обсягів даних, що може ускладнити навчання окремого класифікатора, дані можна розділити на менші підмножини.
Розв’язання складних задач

Один класифікатор може бути недостатнім для вирішення складних завдань. Межі рішень, які відокремлюють дані різних класів, можуть бути дуже нелінійними. Застосування лінійного класифікатора до такої нелінійної межі може виявитися неефективним.
Однак, комбінуючи ансамбль відповідних лінійних класифікаторів, можна навчити систему розпізнавати нелінійні межі. Класифікатор поділить дані на менші, простіші для вивчення частини, і кожен класифікатор опрацює лише один такий розділ. Потім результати різних класифікаторів об’єднуються для створення апроксимованої межі рішення.
Оцінка достовірності
В ансамблевому навчанні рішення оцінюється на основі рівня довіри. Якщо більшість класифікаторів згодні з рішенням, то результат вважається достовірним. З іншого боку, якщо думки розділяються, рівень довіри знижується.
Низький або високий рівень довіри не завжди гарантує правильність рішення. Проте рішення з високим рівнем довіри, отримане від правильно навченого ансамблю, найімовірніше є вірним.
Підвищення точності за допомогою злиття даних
Об’єднання даних з різних джерел може підвищити точність рішень класифікації порівняно з використанням даних з одного джерела.
Принцип роботи ансамблевого навчання
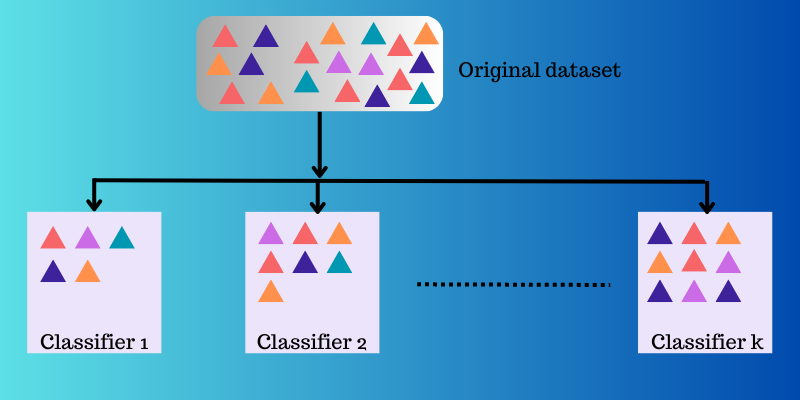
Ансамблеве навчання застосовує декілька функцій відображення, отриманих різними класифікаторами, і об’єднує їх для створення єдиної функції відображення.
Розглянемо приклад:
Припустимо, ви розробляєте додаток для замовлення їжі. Для забезпечення високої якості обслуговування, ви збираєте відгуки користувачів щодо проблем, помилок та інших недоліків.
Ви можете запитати думку своїх друзів, родини, колег та інших людей, яких ви часто зустрічаєте, щодо їхніх уподобань у їжі та досвіду онлайн-замовлень. Крім того, ви можете випустити бета-версію програми, щоб отримувати відгуки в реальному часі.
Таким чином, ви розглядаєте різноманітні думки та ідеї різних людей для покращення взаємодії з користувачем.
Ансамблеве навчання працює за подібним принципом. Воно використовує набір моделей і об’єднує їхні результати для підвищення точності прогнозування та продуктивності.
Основні методи ансамблевого навчання
#1. Мода
Мода – це значення, яке найчастіше зустрічається в наборі даних. В ансамблевому навчанні фахівці з машинного навчання використовують кілька моделей для створення прогнозів для кожної точки даних. Ці прогнози вважаються окремими голосами, а прогноз, який підтримує більшість моделей, стає остаточним. Цей метод часто застосовується в задачах класифікації.
Приклад: якщо чотири користувачі оцінили вашу програму на 4, а один – на 3, то модою буде 4, оскільки ця оцінка була обрана більшістю.
#2. Середнє/середнє арифметичне
У цьому методі враховуються всі прогнози моделей, а потім обчислюється їхнє середнє значення для отримання остаточного прогнозу. Цей метод використовується для створення прогнозів у задачах регресії, розрахунку ймовірностей у задачах класифікації тощо.
Приклад: у наведеному вище прикладі, де чотири користувачі оцінили додаток на 4, а один – на 3, середнє значення буде (4+4+4+4+3)/5=3.8
#3. Зважене середнє
У цьому методі ансамблевого навчання моделям присвоюються різні ваги для прогнозування. Вага вказує на значущість кожної моделі.
Приклад: припустимо, що 5 користувачів залишили відгук про ваш додаток. З них 3 є розробниками, а 2 не мають досвіду в розробці. Тому, відгуки розробників матимуть більшу вагу, ніж відгуки інших користувачів.
Поглиблені методи ансамблевого навчання
#1. Бегінг (Bagging)
Бегінг (Bootstrap AGGregatING) – це інтуїтивно зрозуміла та ефективна техніка ансамблевого навчання. Як видно з назви, вона поєднує поняття “Bootstrap” та “aggregation”.
Бутстрапінг – це метод вибірки, де підмножини спостережень створюються з вихідного набору даних із заміною. Розмір кожної підмножини дорівнює розміру вихідного набору даних.
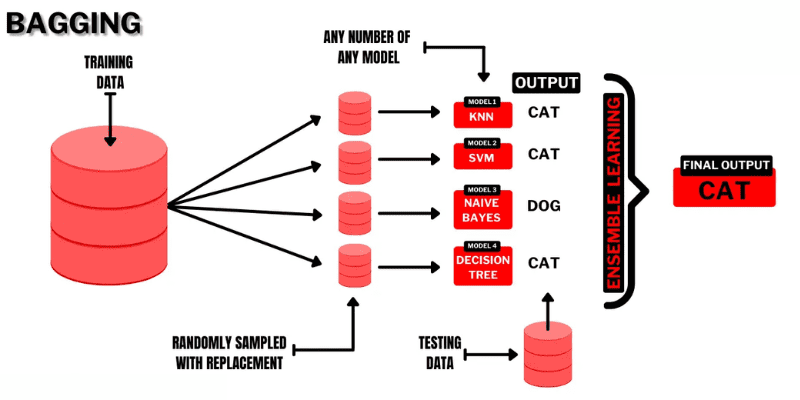 Джерело: Buggy programmer
Джерело: Buggy programmer
Таким чином, у бегінгу підмножини використовуються для аналізу розподілу повного набору даних. Підмножини можуть бути меншими за вихідний набір. Цей метод використовує один алгоритм машинного навчання. Метою об’єднання результатів різних моделей є отримання узагальненого результату.
Принцип роботи бегінгу:
- З вихідного набору даних генерується декілька підмножин зі заміною. Ці підмножини використовуються для навчання моделей або дерев рішень.
- Для кожної підмножини створюється базова модель. Моделі є незалежними та працюють паралельно.
- Остаточний прогноз отримується шляхом поєднання прогнозів кожної моделі з використанням статистичних методів, таких як усереднення або голосування.
Популярні алгоритми, що застосовуються в бегінгу:
- Випадковий ліс
- Дерева рішень, навчені з бегінгом
Перевагою цього методу є мінімізація помилок дисперсії в деревах рішень.
#2. Стекінг (Stacking)
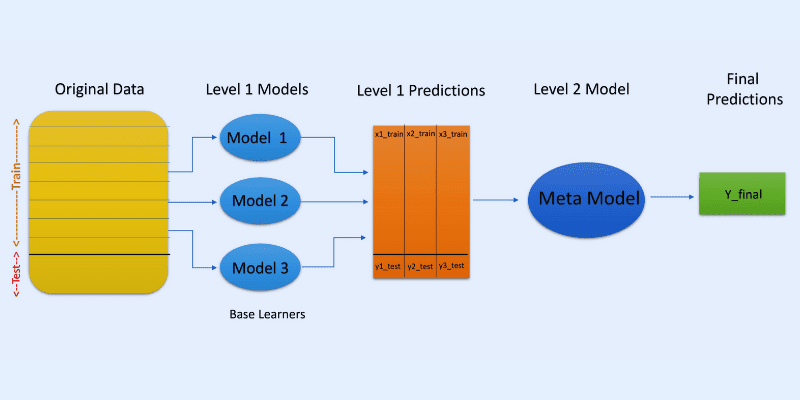 Джерело зображення: OpenGenus IQ
Джерело зображення: OpenGenus IQ
У стекінгу або стекованому узагальненні прогнози різних моделей, наприклад дерева рішень, використовуються для створення нової моделі для прогнозування тестового набору.
Стекінг передбачає створення завантажувальних підмножин даних для навчання моделей, подібно до бегінгу. Але в цьому випадку вихідні дані моделей використовуються як вхідні дані для іншого класифікатора, який називається метакласифікатором, для остаточного прогнозування вибірок.
Використання двох шарів класифікаторів допомагає визначити, чи правильно навчаються набори даних. Хоча двошаровий підхід є поширеним, можна використовувати і більше шарів.
Наприклад, можна використовувати 3-5 моделей на першому рівні та одну модель на другому. Модель другого рівня об’єднає прогнози, отримані на першому рівні, для створення остаточного прогнозу.
Для агрегування прогнозів можна використовувати будь-яку модель машинного навчання. Лінійні моделі, такі як лінійна регресія або логістична регресія, є загальноприйнятими.
Популярні алгоритми машинного навчання, що використовуються в стекінгу:
- Змішування
- Супер ансамбль
- Багатошарові моделі
Примітка: Змішування використовує набір затримок з навчального набору даних для створення прогнозів. На відміну від стекінгу, змішування створює прогнози лише з затриманих даних.
#3. Бустинг (Boosting)
Бустинг – це ітеративний метод ансамблевого навчання, який регулює вагу конкретного спостереження залежно від його останньої класифікації. Це означає, що кожна наступна модель намагається виправити помилки попередньої.
Якщо спостереження класифіковано неправильно, то бустинг збільшує його вагу.
У бустингу професіонали навчають перший алгоритм на повному наборі даних. Потім наступні алгоритми ML будуються на основі залишків попереднього алгоритму бустингу. Таким чином, неправильно передбачені спостереження отримують більшу вагу.
Поетапний принцип роботи:
- З вихідного набору даних генерується підмножина. Кожна точка даних спочатку має однакову вагу.
- На підмножині створюється базова модель.
- Прогноз створюється на повному наборі даних.
- На основі фактичних та прогнозованих значень обчислюються помилки.
- Неправильно передбачені спостереження отримують більшу вагу.
- Створюється нова модель, яка намагається виправити попередні помилки. Цей процес повторюється кілька разів, і кожна модель виправляє помилки попередніх.
- Остаточний прогноз створюється на основі кінцевої моделі, яка є середньозваженим значенням усіх моделей.
Популярні алгоритми бустингу:
- CatBoost
- Light GBM
- AdaBoost
Перевагою бустингу є створення точніших прогнозів та зменшення помилок через упередження.
Інші техніки ансамблевого навчання

Суміш експертів: передбачає навчання декількох класифікаторів, а їхні результати об’єднуються за допомогою загального лінійного правила. Ваги для комбінацій визначаються моделлю, яку можна навчити.
Мажоритарне голосування: передбачає вибір непарної кількості класифікаторів. Прогнози обчислюються для кожної вибірки. Клас, який отримає найбільше голосів, стає прогнозованим класом ансамблю. Цей метод використовується для розв’язання задач бінарної класифікації.
Правило максимуму: використовує розподіл імовірностей кожного класифікатора та впевненість для створення прогнозів. Застосовується для задач багатокласової класифікації.
Реальні приклади застосування ансамблевого навчання
#1. Розпізнавання облич та емоцій
Ансамблеве навчання застосовує такі методи, як аналіз незалежних компонентів (ICA), для розпізнавання облич.
Також ансамблеве навчання використовується для розпізнавання емоцій за допомогою аналізу мовлення, а також розпізнавання емоцій за виразом обличчя.
#2. Безпека
Виявлення шахрайства: ансамблеве навчання допомагає підвищити ефективність моделювання нормальної поведінки, що робить його ефективним у виявленні шахрайських дій, наприклад, у кредитних картах, банківських системах, телекомунікаціях, відмиванні грошей тощо.

DDoS: розподілена відмова в обслуговуванні (DDoS) є серйозною загрозою для інтернет-провайдерів. Класифікатори ансамблю можуть зменшити кількість помилок виявлення та відрізнити атаки від звичайного трафіку.
Виявлення вторгнень: ансамблеве навчання використовується в системах моніторингу, таких як системи виявлення вторгнень, для виявлення шкідливого коду, моніторингу мереж, виявлення аномалій тощо.
Виявлення шкідливого програмного забезпечення: ансамблеве навчання ефективно виявляє та класифікує шкідливе програмне забезпечення, наприклад віруси, черв’яки, програми-вимагачі, трояни, шпигунське програмне забезпечення тощо, за допомогою методів машинного навчання.
#3. Поступове навчання
У поетапному навчанні алгоритм ML вивчає новий набір даних, зберігаючи попередні знання, але без доступу до попередніх даних. Ансамблеві системи використовуються в поетапному навчанні, оскільки вони можуть додавати нові класифікатори для кожного набору даних.
#4. Медицина
Ансамблеві класифікатори використовуються у медичній діагностиці для виявлення нейрокогнітивних розладів, таких як хвороба Альцгеймера. Вони аналізують дані МРТ як вхідні дані та класифікують цервікальну цитологію. Також ансамблеве навчання застосовується у протеоміці, нейронауці та інших галузях.
#5. Дистанційне зондування
Виявлення змін: ансамблеві класифікатори використовуються для виявлення змін за допомогою методів, таких як баєсівське усереднення та мажоритарне голосування.
Картографування ґрунтового покриву: для ефективного виявлення та картографування ґрунтового покриву застосовуються методи ансамблевого навчання, такі як бустинг, дерева рішень, аналіз основних компонентів ядра (KPCA) тощо.
#6. Фінанси
Точність є важливим аспектом фінансів. Вона впливає на якість рішень, які приймаються. Ансамблеві моделі можуть аналізувати зміни на фондовому ринку, виявляти маніпуляції з цінами акцій тощо.
Додаткові ресурси для навчання

#1. Ансамблеві методи машинного навчання
Ця книга допоможе вам вивчити та застосувати важливі методи ансамблевого навчання з нуля.
#2. Ансамблеві методи: основи та алгоритми
У цій книзі ви знайдете основи ансамблевого навчання та його алгоритми, а також приклади їх застосування в реальному світі.
#3. Навчання в ансамблі
Пропонує ознайомлення з уніфікованим методом ансамблю, його завданнями та застосуваннями.
#4. Методи та застосування ансамблевого машинного навчання:
Забезпечує широкий огляд сучасних методів ансамблевого навчання.
Висновок
Сподіваюся, що ця стаття допомогла вам зрозуміти ансамблеве навчання, його методи та застосування. Ансамблеве навчання може вирішувати широкий спектр реальних задач у сферах безпеки, розробки програмного забезпечення, фінансів, медицини тощо. Його використання постійно розширюється, тому в майбутньому ця концепція, ймовірно, буде вдосконалюватися.
Також ви можете дослідити деякі інструменти для створення синтетичних даних для навчання моделей машинного навчання.