Переваги використання формату Apache Parquet для зберігання даних
Apache Parquet виступає значною перевагою у сфері зберігання та обробки даних, особливо в порівнянні з традиційними методами, такими як CSV. Його структура розроблена для оптимізації швидкості обробки складних типів даних. Ця стаття розгляне, як формат Parquet відповідає зростаючим вимогам сучасної обробки даних.
Перед тим, як ми перейдемо до детального аналізу Parquet, давайте розглянемо формат CSV та проблеми, які він створює при зберіганні великих обсягів інформації.
Що таке CSV зберігання?
CSV (значення, розділені комами) є одним з найпоширеніших способів організації даних. Цей формат зберігає дані по рядках, де кожен рядок відповідає запису, а значення розділені комами. Файли CSV зберігаються з розширенням .csv і можуть бути переглянуті за допомогою програм, таких як Excel, Google Sheets або звичайного текстового редактора. Дані легко читаються після відкриття файлу, що робить CSV зручним для базових операцій.
Однак, такий формат не є оптимальним для зберігання даних у базах даних. Зі збільшенням обсягу даних, запити, управління та отримання потрібної інформації стають все більш складними.
Ось приклад представлення даних у файлі .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
У табличному вигляді в Excel, дані відображаються у вигляді рядків та стовпців.
Проблеми з форматом зберігання CSV
Формати зберігання на основі рядків, такі як CSV, добре підходять для операцій створення, оновлення та видалення даних. Але як щодо операції читання?
Уявіть собі файл .csv з мільйоном рядків. Відкриття такого файлу і пошук потрібної інформації займе значний час, що не є ефективним. Більшість хмарних провайдерів, такі як AWS, стягують плату за обсяг сканованих або збережених даних. CSV файли займають багато місця, що збільшує вартість зберігання.
Крім того, формат CSV не дозволяє зберігати метадані, що робить пошук даних складним та виснажливим.
Яке ж економічно ефективне та оптимальне рішення для виконання всіх операцій CRUD? Розглянемо далі.
Що таке Parquet зберігання даних?
Parquet – це відкритий формат зберігання даних, який широко використовується в екосистемах Hadoop і Spark. Файли Parquet мають розширення .parquet.
Parquet є структурованим форматом, який дозволяє оптимізувати обробку складних необроблених даних у сховищах великих даних, що значно скорочує час виконання запитів. Він поєднує в собі переваги рядкового та стовпцевого зберігання, розділяючи дані як горизонтально, так і вертикально. Такий підхід значно зменшує накладні витрати на розбір даних.
Формат Parquet зменшує загальну кількість операцій вводу/виводу, що знижує вартість зберігання та обробки даних. Parquet також зберігає метадані, включаючи схему даних, кількість значень, розташування стовпців, мінімальні та максимальні значення, кількість груп рядків та тип кодування. Метадані зберігаються на різних рівнях файлу, що прискорює доступ до даних.
У форматах на основі рядків, таких як CSV, пошук даних вимагає перегляду кожного рядка, тоді як Parquet дозволяє отримувати доступ до всіх необхідних стовпців одночасно.
Підсумовуючи, Parquet:
- Базується на стовпцевій структурі для зберігання даних.
- Оптимізований для масового зберігання складних даних.
- Включає різні методи стиснення та кодування.
- Значно скорочує час сканування даних і запитів, займаючи менше місця на диску.
- Мінімізує операції вводу-виводу, знижуючи вартість зберігання та обробки.
- Включає метадані для полегшення пошуку даних.
- Має відкритий вихідний код.
Структура даних Parquet
Розглянемо детальніше, як зберігаються дані у форматі Parquet.
Файл може містити кілька горизонтальних розділів, які називаються групами рядків. Кожна група рядків має вертикальний поділ, де стовпці поділяються на блоки стовпців. Дані зберігаються як сторінки всередині блоків стовпців. Кожна сторінка містить закодовані значення даних та метадані. Метадані для всього файлу також зберігаються в нижньому колонтитулі файлу на рівні групи рядків.
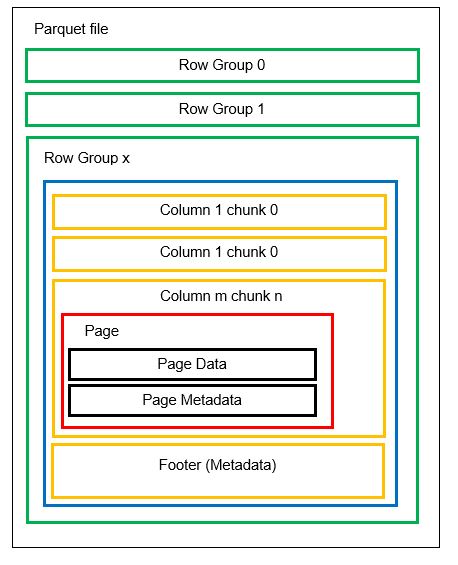
Оскільки дані розбиті на фрагменти стовпців, додавання нових даних шляхом кодування нових значень у новий фрагмент і файл є простим процесом. Метадані оновлюються для відповідних файлів і груп рядків. Parquet є гнучким форматом, що дозволяє легко масштабувати та оновлювати дані.
Parquet підтримує стиснення даних за допомогою методів стиснення сторінок і кодування словника. Розглянемо простий приклад стиснення словника:
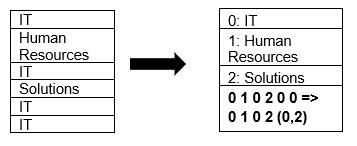
У наведеному прикладі, розділ “IT” повторюється 4 рази. Під час зберігання, формат кодує дані за допомогою інших значень (0,1,2…), і фіксує кількість повторень. Наприклад, “IT, IT” перетворюється на “0,2”, що економить місце. Запит стиснутих даних займає менше часу.
Порівняння CSV та Parquet
Настав час порівняти формати CSV та Parquet за ключовими параметрами:
| Характеристика | CSV | Parquet |
| Формат зберігання | Рядковий | Гібридний (рядково-стовпцевий) |
| Використання місця | Великий розмір через відсутність стиснення за замовчуванням. Файл розміром 1 ТБ займає 1 ТБ. | Стискає дані під час зберігання, зменшуючи обсяг. Файл розміром 1 ТБ може займати лише 130 ГБ. |
| Час запиту | Повільний через пошук по рядках. Потрібно зчитувати кожен рядок для кожного стовпця. | Значно швидший (приблизно в 34 рази) завдяки стовпцевому зберігання і метаданим. |
| Обсяг сканованих даних | Для кожного запиту сканується великий обсяг даних. | Сканується приблизно на 99% менше даних, оптимізуючи продуктивність. |
| Вартість зберігання | Висока через великий обсяг даних. | Нижча вартість зберігання, дані зберігаються у стисненому форматі. |
| Схема файлу | Схему потрібно або виводити, що може призводити до помилок, або задавати вручну. | Схема зберігається в метаданих. |
| Типи даних | Підходить для простих типів даних. | Підходить для складних типів даних, таких як вкладені схеми, масиви, словники. |
Висновок
Аналізуючи наведені приклади, можна зробити висновок, що Parquet є більш ефективним, ніж CSV, з точки зору вартості, гнучкості та продуктивності. Це оптимальний механізм для зберігання та обробки даних, особливо в умовах переходу до хмарних технологій. Усі основні платформи, такі як Azure, AWS та BigQuery, підтримують формат Parquet.