MapReduce надає продуктивний, прискорений та економічно вигідний спосіб розробки застосунків.
Ця модель використовує сучасні концепції, такі як паралельна обробка, локалізація даних та інші, щоб забезпечити значні переваги розробникам і організаціям.
Проте, на ринку існує безліч моделей програмування та фреймворків, що ускладнює вибір.
Особливо, коли мова йде про великі обсяги інформації, вибір не може бути випадковим. Необхідно обирати технології, здатні обробляти значні масиви даних.
MapReduce є ефективним рішенням у такому випадку.
У цій публікації ми розглянемо, що являє собою MapReduce та які переваги він може надати.
Розпочнімо!
Що таке MapReduce?
MapReduce – це програмна модель або платформа, що входить до складу Apache Hadoop. Вона використовується для створення застосунків, здатних обробляти великі обсяги даних паралельно на тисячах вузлів (кластерів або сіток) з високим рівнем відмовостійкості та надійності.
Обробка даних відбувається безпосередньо в базі даних або файловій системі, де зберігаються дані. MapReduce може взаємодіяти з файловою системою Hadoop (HDFS) для доступу та управління значними обсягами даних.
Цей фреймворк був представлений Google у 2004 році і отримав подальшу популяризацію завдяки Apache Hadoop. Він виступає як рівень обробки або механізм у Hadoop, що запускає програми MapReduce, розроблені різними мовами, включаючи Java, C++, Python та Ruby.
Програми MapReduce, що виконуються в хмарних обчисленнях, працюють паралельно, тому є придатними для аналізу даних у великих масштабах.
Основна мета MapReduce – розподілити велике завдання на менші підзавдання за допомогою функцій “map” і “reduce”. Спочатку відбувається розбиття на незалежні задачі, а потім їхнє об’єднання, що зменшує обчислювальну потужність та витрати на мережу кластера.
Наприклад, уявіть, що ви готуєте їжу для великої кількості гостей. Якщо ви спробуєте приготувати все самостійно, це буде виснажливим і потребуватиме багато часу.
Але якщо ви залучите друзів або колег (не гостей), розподіливши між ними різні етапи приготування, ви зможете приготувати їжу швидше та легше. Кожен виконує свою частину роботи одночасно.
MapReduce працює аналогічно, використовуючи розподіл завдань і паралельну обробку, щоб забезпечити більш швидкий та ефективний спосіб виконання певного завдання.
Apache Hadoop дозволяє програмістам використовувати MapReduce для обробки великих розподілених наборів даних та застосовувати передові методи машинного навчання та статистичного аналізу для пошуку закономірностей, прогнозування, виявлення кореляцій та інших цілей.
Ключові характеристики MapReduce
Основні особливості MapReduce:
- Інтерфейс користувача: інтуїтивно зрозумілий інтерфейс надає детальну інформацію про кожен аспект фреймворка. Це полегшує налаштування, застосування та оптимізацію завдань.

- Обробка даних: програми використовують інтерфейси Mapper і Reducer для реалізації функцій map і reduce. Mapper перетворює вхідні пари ключ-значення на проміжні пари ключ-значення. Reducer використовується для зведення проміжних пар ключ-значення з однаковим ключем до меншого набору значень. Він виконує три функції: сортування, перемішування та зменшення.
- Роздільник: керує розподілом проміжних ключів виводу карти.
- Репортер: функція для відстеження прогресу, оновлення лічильників та встановлення повідомлень про стан виконання.
- Лічильники: глобальні лічильники, що їх визначає програма MapReduce.
- OutputCollector: ця функція збирає вихідні дані від Mapper або Reducer, а не проміжні виходи.
- RecordWriter: записує вихідні дані або пари ключ-значення у вихідний файл.
- DistributedCache: ефективно поширює великі файли, призначені лише для читання, які потрібні для роботи програми.
- Стиснення даних: розробник може налаштувати стиснення як вихідних даних завдань, так і проміжних вихідних даних карти.
- Пропуск невдалих записів: під час обробки вхідних даних карти можна пропускати пошкоджені або невірні записи. Ця функція керується за допомогою класу SkipBadRecords.
- Налагодження: можливість запускати користувацькі скрипти та вмикати налагодження. У випадку збою виконання завдання MapReduce, можна скористатися налагодженням для пошуку проблеми.
Архітектура MapReduce
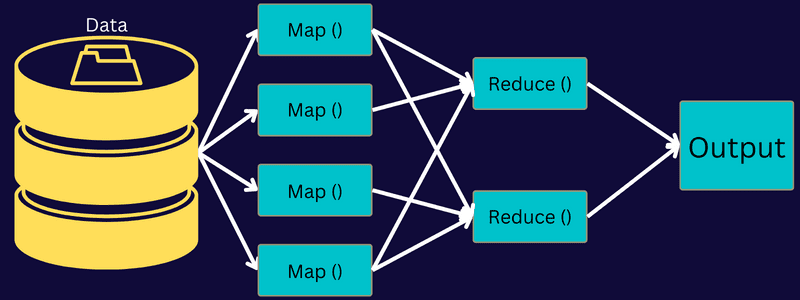
Розглянемо архітектуру MapReduce, аналізуючи її складові:
- Завдання: Завдання у MapReduce – це фактичне завдання, яке клієнт хоче виконати. Воно складається з декількох менших підзавдань, які об’єднуються в кінцеве завдання.
- Сервер історії завдань: Демон-процес для зберігання всіх історичних даних про програму чи завдання, наприклад журналів, створених до або після виконання завдання.
- Клієнт: Клієнт (програма або API) відправляє завдання до MapReduce для виконання або обробки. У MapReduce один або декілька клієнтів можуть постійно надсилати завдання до менеджера MapReduce.
- MapReduce Master: MapReduce Master розподіляє завдання на менші частини, забезпечуючи паралельне виконання.
- Частини завдання: Підзавдання, отримані шляхом поділу основного завдання. Вони обробляються і з’єднуються для отримання кінцевого результату.
- Вхідні дані: Набір даних, що передається до MapReduce для обробки завдань.
- Вихідні дані: Кінцевий результат, отриманий після обробки завдання.
Отже, в архітектурі клієнт надсилає завдання до MasterReduce Master, який розподіляє його на менші частини. Це дозволяє прискорити обробку, оскільки маленькі підзавдання обробляються швидше, ніж одне велике.
Однак важливо уникати надмірного поділу завдання на дуже дрібні частини, оскільки це може призвести до зростання накладних витрат на управління розподілом.
Далі підзавдання передаються для виконання функцій Map і Reduce. Крім того, завдання Map і Reduce використовують відповідний код, розроблений програмістом на основі конкретного випадку застосування.
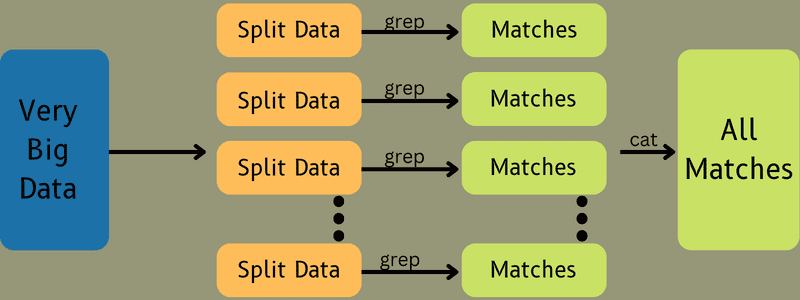
Вхідні дані передаються до Map Task, де функція Map генерує вихідні дані у вигляді пар ключ-значення. Ці дані зберігаються на локальному диску, а не в HDFS, щоб запобігти реплікації.
Після виконання завдання його результат може бути видалений. Реплікація стає надлишковою, якщо зберігати вихідні дані в HDFS. Вихідні дані кожного завдання map подаються до завдання reduce, при цьому дані передаються на машину, де виконується завдання reduce.
Далі вихідні дані об’єднуються та передаються до функції reduce, визначеної користувачем. Нарешті, результат зберігається в HDFS.
Процес може містити кілька завдань Map і Reduce для обробки даних, в залежності від кінцевої мети. Алгоритми Map і Reduce оптимізовані для досягнення мінімальної складності за часом і простором.
Оскільки MapReduce в основному включає завдання Map і Reduce, важливо детальніше розглянути їх. Отже, обговоримо фази MapReduce, щоб глибше зрозуміти ці теми.
Фази MapReduce
Карта
На цьому етапі вхідні дані перетворюються на вихідні пари ключ-значення. Ключ може вказувати на ідентифікатор адреси, а значення — на фактичне значення цієї адреси.
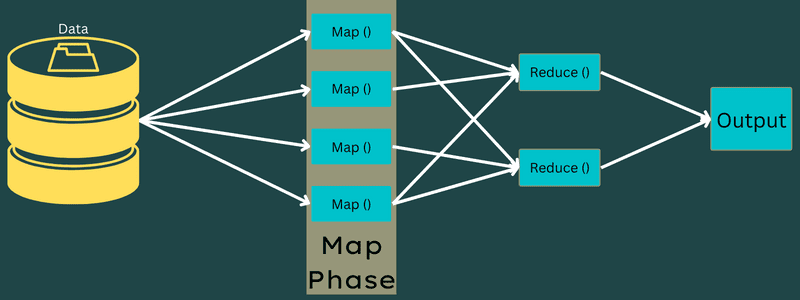
На цьому етапі є два завдання: розділення і відображення. Розділення – це підчастини або частини роботи, відокремлені від основної роботи, також відомі як вхідні розділи. Розділення вхідних даних можна представити як блок вхідних даних, який обробляє карта.
Далі виконується завдання відображення, яке є першою фазою під час виконання програми reduce карти. Дані, що містяться в кожному розділі, передаються функції карти для обробки та генерації виходу.
Функція Map() виконується з парами ключ-значення, що знаходяться у сховищі пам’яті, генеруючи проміжні пари ключ-значення. Ці пари є вхідними даними для функції Reduce() або Reducer.
Зменшити
Проміжні пари ключ-значення, отримані на етапі зіставлення, є вхідними даними для функції Reduce або Reducer. Як і на етапі зіставлення, тут є два завдання: перетасування та зменшення.
Отримані пари ключ-значення сортуються та перемішуються для подальшої передачі в Reducer. Reducer групує або агрегує дані відповідно до пар ключ-значення, використовуючи алгоритм Reducer, розроблений програмістом.
Значення з фази перемішування об’єднуються для повернення вихідного значення, підсумовуючи весь набір даних.
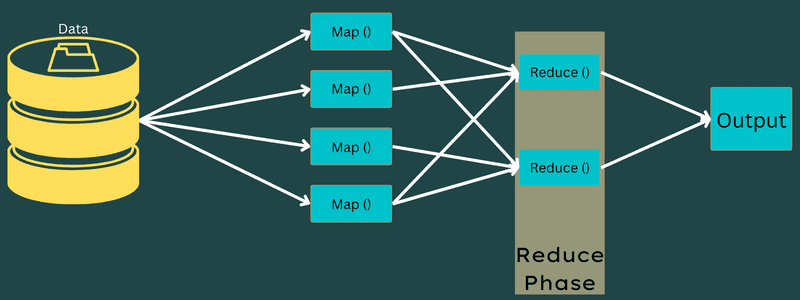
Процес виконання завдань Map and Reduce контролюється:
- Job Tracker: Забезпечує управління повним виконанням завдання, керує ресурсами кластера та планує завдання. Job Tracker планує кожне завдання map у відстеження завдань, які працюють на певному вузлі даних.
- Task Trackers: Відстежувачі завдань виконують завдання згідно з інструкціями Job Tracker. Відстежувач завдань розгортається на кожному вузлі кластера, виконуючи завдання Map і Reduce.
Завдання поділяються на підзавдання, які виконуються на різних вузлах кластера. Job Tracker координує виконання завдань, а Task Tracker на кожному вузлі виконує частину завдання та відстежує процес.
Task Tracker надсилає звіти про прогрес до Job Tracker, а також регулярно надсилає сигнал “серцебиття”, щоб повідомити про стан системи. У випадку помилки Job Tracker може перепланувати завдання на інший Task Tracker.
Фаза виводу: На цьому етапі генеруються пари ключ-значення з Reducer. За допомогою засобу форматування виводу пари ключ-значення перетворюються та записуються у файл.
Навіщо використовувати MapReduce?
Переваги MapReduce:
Паралельна обробка
Завдання поділяється між різними вузлами, де кожен обробляє частину завдання паралельно. Розподіл великих завдань на менші зменшує складність, а паралельне виконання на різних машинах прискорює обробку.
Локальність даних
MapReduce передбачає переміщення обробки даних, а не самих даних.
Традиційно дані доставлялися до блоку обробки, що створювало проблеми при роботі з великими обсягами даних. Серед таких проблем – висока вартість, збільшення часу, навантаження на головний вузол, часті збої та зниження продуктивності мережі.
MapReduce розв’язує ці проблеми, підключаючи блок обробки безпосередньо до даних. Дані розподіляються між вузлами, і кожен вузол обробляє свою частину.
Це підвищує економічну ефективність, скорочує час обробки та запобігає перевантаженню вузлів.
Безпека

MapReduce забезпечує високий рівень безпеки, захищаючи програму від неавторизованих даних і підвищуючи безпеку кластера.
Масштабованість і гнучкість
MapReduce є масштабованою структурою, що дозволяє запускати програми на кількох машинах з обробкою даних об’ємом у тисячі терабайт. Забезпечує гнучку обробку даних будь-якого типу, формату та розміру.
Простота
Програми MapReduce можна розробляти на різних мовах програмування, таких як Java, R, Perl, Python тощо. Це полегшує вивчення та написання програм.
Сфери застосування MapReduce
- Повнотекстове індексування: MapReduce використовується для створення повнотекстового індексу. Функція Mapper зіставляє кожне слово або фразу в документі, а Reducer записує всі зіставлені елементи в індекс.
- Розрахунок Pagerank: Google використовує MapReduce для обчислення Pagerank.
- Аналіз журналу: MapReduce аналізує файли журналу, розбиваючи великий файл на частини, а картограф шукає доступні веб-сторінки.
При виявленні веб-сторінки в журналі, вона передається як пара ключ-значення до Reducer, де веб-сторінка є ключем, а значення 1 – індексом. Далі, в Reducer, агрегуються різні веб-сторінки. Кінцевим результатом є загальна кількість відвідувань для кожної веб-сторінки.

- Зворотний графік веб-посилань: MapReduce використовується для створення зворотного графіка веб-посилань. Map() дає цільову URL-адресу та джерело, беручи дані з веб-сторінки.
Reduce() збирає список вихідних URL-адрес, пов’язаних з цільовою URL-адресою. Нарешті, виводить джерела та ціль.
- Підрахунок слів: MapReduce використовується для підрахунку кількості входжень слова в документі.
- Глобальне потепління: MapReduce може використовуватися для аналізу даних про глобальне потепління, наприклад, для вивчення підвищення температури океану. Збираючи тисячі точок даних (температура, широта, довгота, дата тощо) і застосовуючи MapReduce для обробки, можна отримати цінну інформацію.
- Випробування ліків: MapReduce може допомогти у випробуванні ефективності препаратів, аналізуючи дані про групу пацієнтів.
- Інші застосування: MapReduce підходить для обробки великих наборів даних, що не вміщаються в реляційну базу даних. Він дозволяє запускати аналітичні інструменти на розподілених наборах даних, які раніше оброблялися лише на одному комп’ютері.
Завдяки надійності та простоті MapReduce використовується у військовій сфері, бізнесі, науці та інших областях.
Висновок
MapReduce є важливим технологічним проривом, який не тільки прискорює обробку даних, але й робить її економічнішою та менш трудомісткою. Зважаючи на його переваги та поширення, можна очікувати подальшого впровадження MapReduce в різних галузях.
Для глибшого розуміння великих даних та Hadoop, рекомендуємо ознайомитися з додатковими ресурсами.