Цікавитеся аналізом власних даних за допомогою природної мови? Дізнайтеся про можливості бібліотеки Python PandasAI.
У сучасному світі, де дані відіграють ключову роль, їхнє розуміння та аналіз є вкрай важливими. Проте, традиційні методи аналізу можуть бути складними. Саме тут на допомогу приходить PandasAI. Він значно спрощує цей процес, надаючи можливість взаємодіяти з даними через запити природною мовою.
PandasAI працює, трансформуючи ваші питання у програмний код, необхідний для аналізу даних. Він базується на відомій бібліотеці Python – pandas. PandasAI – це бібліотека Python, що розширює функціонал pandas, відомого інструменту для аналізу та обробки даних, за допомогою можливостей Generative AI. Її мета – доповнити pandas, а не замінити його.
PandasAI впроваджує розмовний підхід у pandas (а також інші популярні бібліотеки для аналізу даних), дозволяючи вам взаємодіяти з вашими даними за допомогою запитів, сформульованих природною мовою.
У цьому посібнику ви знайдете інструкції щодо налаштування PandasAI, його використання з реальними наборами даних, створення графіків, вивчення корисних ярликів, а також розгляд сильних і слабких сторін цього потужного інструменту.
Після ознайомлення з матеріалом, ви зможете виконувати аналіз даних природною мовою набагато легше та інтуїтивніше.
Тож давайте зануримося у захоплюючий світ аналізу даних природною мовою за допомогою Pandas AI!
Налаштування робочого середовища
Для початку роботи з PandasAI, необхідно встановити відповідну бібліотеку.
Для цього проєкту я використовую Jupyter Notebook. Проте, ви можете застосовувати Google Colab або VS Code, залежно від ваших потреб.
Якщо ви плануєте використовувати великі мовні моделі (LLM) від Open AI, необхідно також встановити Open AI Python SDK для коректної роботи.
# Встановлення Pandas AI !pip install pandas-ai # Pandas AI використовує мовні моделі OpenAI, тому необхідно встановити OpenAI Python SDK !pip install openai
Тепер імпортуємо необхідні бібліотеки:
# Імпорт необхідних бібліотек import pandas as pd import numpy as np # Імпорт PandasAI та його компонентів from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Ключовим елементом для аналізу даних з PandasAI є ключ API. Інструмент підтримує кілька великих мовних моделей (LLM) та моделей LangChain, що використовуються для генерації коду на основі запитів, сформульованих природною мовою. Це робить аналіз даних доступнішим та зручнішим для користувача.
PandasAI є універсальним інструментом, який може взаємодіяти з різними моделями. Серед них є моделі Hugging Face, Azure OpenAI, Google PALM та Google VertexAI. Кожна з них має свої переваги, що розширює можливості PandasAI.
Зверніть увагу, що для використання цих моделей необхідні відповідні ключі API. Ці ключі автентифікують ваші запити і дозволяють використовувати можливості передових мовних моделей у ваших задачах аналізу даних. Отже, переконайтеся, що ваші ключі API під рукою, коли налаштовуєте PandasAI для ваших проєктів.
Ви можете отримати свій ключ API та експортувати його як змінну середовища.
Далі ми розглянемо, як використовувати PandasAI з різними типами великих мовних моделей (LLM) від OpenAI та Hugging Face Hub.
Використання великих мовних моделей
Ви можете обрати LLM, створивши екземпляр та передавши його до конструктора SmartDataFrame або SmartDatalake, або ж вказати його у файлі pandasai.json.
Якщо модель потребує один або більше параметрів, ви можете передати їх у конструктор або вказати у файлі pandasai.json у параметрі llm_options, як показано нижче:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Як використовувати моделі OpenAI?
Щоб використовувати моделі OpenAI, вам потрібен ключ OpenAI API. Ви можете отримати його тут.
Отримавши ключ API, ви можете створити екземпляр об’єкту OpenAI:
# Ми імпортували всі необхідні бібліотеки на попередньому кроці
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Не забудьте замінити “my-api-key” на ваш особистий ключ API.
Альтернативно, ви можете встановити змінну середовища OPENAI_API_KEY та створити екземпляр об’єкту OpenAI без передачі ключа API:
# Встановіть змінну середовища OPENAI_API_KEY
llm = OpenAI() # немає необхідності передавати ключ API, він буде зчитаний зі змінної середовища
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Якщо ви працюєте через проксі-сервер, ви можете вказати openai_proxy під час створення екземпляра об’єкта OpenAI або налаштувати передачу змінної середовища OPENAI_PROXY.
Важливе зауваження: Використовуючи PandasAI для аналізу даних з вашим ключем API, важливо відстежувати використання токенів для управління витратами.
Хочете дізнатися, як це зробити? Просто виконайте код лічильника токенів, щоб отримати чітке розуміння використання ваших токенів та відповідних витрат. Так ви зможете ефективно керувати своїми ресурсами і уникнути несподіваних рахунків.
Ви можете підрахувати кількість токенів, використаних у вашому запиті, наступним чином:
"""Приклад використання PandasAI з pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False призначений для відображення нижчого використання та вартості
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Розрахуй суму ВВП країн Північної Америки")
print(response)
print(cb)
Ви отримаєте приблизно такі результати:
# Сума ВВП країн Північної Америки становить 19 294 482 071 552. # Використано токенів: 375 # Токенів у підказці: 210 # Токенів у відповіді: 165 # Загальна вартість (USD): $0.000750
Не забувайте відстежувати загальні витрати, якщо у вас є обмежений кредит!
Як використовувати моделі Hugging Face?
Для використання моделей HuggingFace, необхідний ключ HuggingFace API. Ви можете створити обліковий запис HuggingFace тут, та отримати ключ API тут.
Отримавши ключ API, можна використовувати його для створення екземпляра однієї з моделей HuggingFace.
Наразі PandasAI підтримує такі моделі HuggingFace:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# або
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Альтернативно, можна встановити змінну середовища HUGGINGFACE_API_KEY і створити об’єкт HuggingFace без передачі ключа API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # немає необхідності передавати ключ API, він буде зчитаний зі змінної середовища
# або
llm = Falcon() # немає необхідності передавати ключ API, він буде зчитаний зі змінної середовища
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder та Falcon – це моделі LLM, доступні на Hugging Face.
Ми успішно налаштували середовище та вивчили, як використовувати моделі OpenAI та Hugging Face LLMs. Тепер перейдемо до аналізу даних.
Ми будемо використовувати набір даних Big Mart Sales data, який містить інформацію про продажі різних товарів у різних магазинах Big Mart. Набір даних складається з 12 стовпців та 8524 рядків. Посилання на нього ви знайдете в кінці статті.
Аналіз даних за допомогою PandasAI
Тепер, коли ми успішно встановили та імпортували всі необхідні бібліотеки, завантажимо наш набір даних.
Завантаження набору даних
Ви можете вибрати LLM, створивши екземпляр і передавши його в SmartDataFrame. Посилання на набір даних ви знайдете в кінці статті.
# Завантаження набору даних з пристрою path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Використання моделі LLM OpenAI
Після завантаження даних, я буду використовувати модель LLM OpenAI для роботи з PandasAI
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Все готово! Тепер спробуємо скористатися підказками.
Відображення перших 6 рядків набору даних
Спробуємо завантажити перші 6 рядків, надавши відповідні інструкції:
Result = pandas_ai(df, "Покажи перші 6 рядків даних у табличній формі") Result
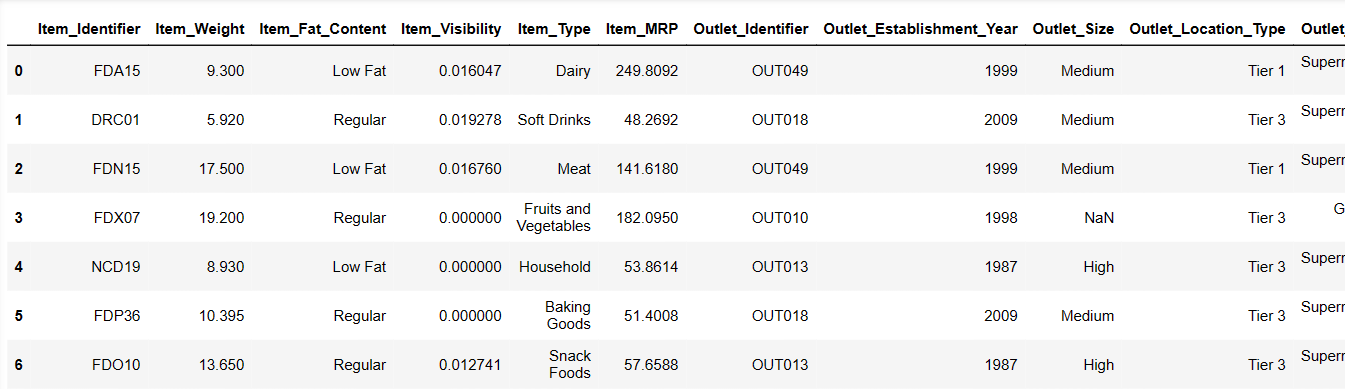
Перші 6 рядків з набору даних
Це було дуже швидко! Давайте розглянемо наш набір даних детальніше.
Генерація описової статистики DataFrame
# Для отримання описової статистики Result = pandas_ai(df, "Покажи опис даних у табличній формі") Result
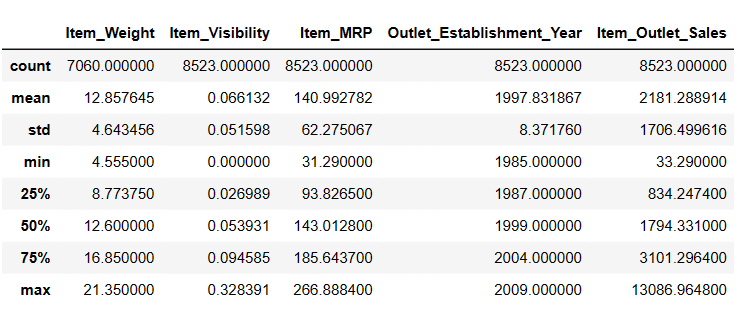
Опис
У Item_Weigth є 7060 значень; можливо, відсутні деякі дані.
Пошук відсутніх значень
Є два способи знайти відсутні значення за допомогою pandas ai.
#Пошук відсутніх значень Result = pandas_ai(df, "Покажи відсутні значення в даних у табличній формі") Result
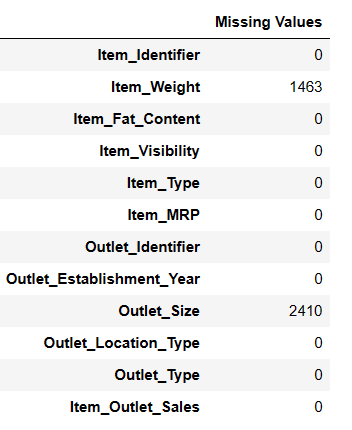
Пошук відсутніх значень
# Ярлик для очищення даних
df = SmartDataframe('data.csv')
df.clean_data()
Цей ярлик дозволить виконати очищення даних у кадрі даних.
Тепер заповнимо відсутні нульові значення.
Заповнення відсутніх значень
#Заповнення відсутніх значень result = pandas_ai(df, "Заповни Item Weight медіаною, а відсутні значення Item outlet size модою, та покажи відсутні значення даних у табличній формі") result
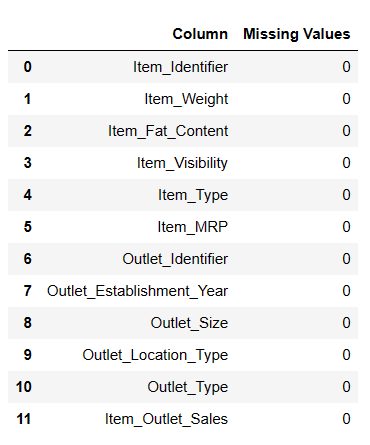
Заповнені нульові значення
Це корисний метод для заповнення нульових значень, хоча під час його використання виникали певні складності.
# Ярлик для заповнення нульових значень
df = SmartDataframe('data.csv')
df.impute_missing_values()
Цей ярлик додасть відсутні значення в кадр даних.
Видалення нульових значень
Якщо ви бажаєте видалити всі рядки з нульовими значеннями з вашого df, ви можете скористатися цим методом.
result = pandas_ai(df, "Видали рядки з відсутніми значеннями з inplace=True") result
Аналіз даних важливий для виявлення трендів, як короткострокових, так і довгострокових, що може бути безцінним для бізнесу, урядів, дослідників та окремих осіб.
Спробуємо виявити загальну тенденцію продажів за роки з моменту заснування магазинів.
Виявлення тенденції продажів
# виявлення тенденції продажів result = pandas_ai(df, "Яка загальна тенденція продажів за роки з моменту заснування магазинів?") result
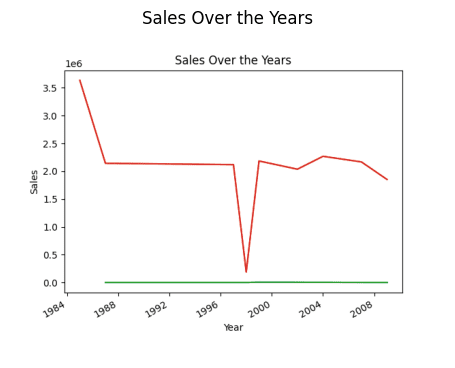
Продажі за рік (лінійний графік)
Початковий процес створення графіку був трохи повільним, але після перезапуску ядра та виконання всього цього він працював швидше.
# Ярлик для побудови лінійних графіків
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Цей ярлик збудує лінійну діаграму кадру даних.
Можливо, вам цікаво, чому спостерігається спадний тренд. Це тому, що у нас немає даних з 1989 по 1994 роки.
Пошук року з найбільшими продажами
А тепер дізнаємося, в якому році були найбільші продажі.
# пошук року з найбільшими продажами result = pandas_ai(df, "Поясни, у які роки були найбільші продажі") result

Отже, найбільші продажі були у 1985 році.
Але я хотів би дізнатися, який тип товару має найбільші середні продажі, а який – найменші.
Найвищі та найнижчі середні продажі
# пошук найвищих та найнижчих середніх продажів result = pandas_ai(df, "Який тип товару має найбільші середні продажі, а який – найменші?") result

Продукти з крохмалем мають найбільші середні продажі, а інші – найменші. Якщо вам не подобається, що “інші” мають найнижчі продажі, ви можете покращити свій запит відповідно до ваших потреб.
Чудово! Тепер я хотів би дізнатися про розподіл продажів між різними торговими точками.
Розподіл продажів по різних торгових точках
Існує чотири типи торгових точок: супермаркети типів 1/2/3 та продуктові магазини.
# розподіл продажів по різних типах торгових точок з моменту заснування response = pandas_ai(df, "Візуалізуй розподіл продажів по різних типах торгових точок з моменту заснування за допомогою гістограми, розмір графіку=(13,10)") response
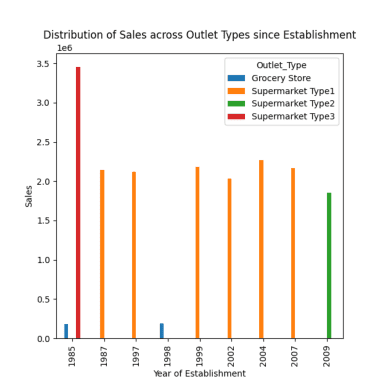
Розподіл продажів по різних торгових точках
Як вже було виявлено, пік продажів припав на 1985 рік, і цей графік показує найбільші продажі у 1985 році в супермаркетах типу 3.
# Ярлик для побудови гістограми
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Цей ярлик побудує гістограму кадру даних.
# Ярлик для побудови гістограми
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Цей ярлик збудує гістограму кадру даних.
А тепер дізнаємося про середні продажі товарів з вмістом жиру “з низьким вмістом жиру” і “звичайним”.
Пошук середніх продажів для товарів із різним вмістом жиру
# пошук індексу рядка за значенням стовпця result = pandas_ai(df, "Які середні продажі товарів з вмістом жиру 'з низьким вмістом жиру' та 'звичайним'?") result
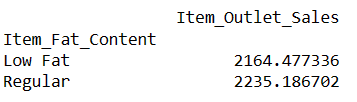
Складання таких запитів дає можливість порівнювати два або більше продуктів.
Середні продажі для кожного типу товару
Я хотів би порівняти всі продукти за їхніми середніми продажами.
# Середні продажі для кожного типу товару result = pandas_ai(df, "Які середні продажі для кожного типу товару за останні 5 років? Покажи на круговій діаграмі, розмір=(6,6)") result
Кругова діаграма середніх продажів
Усі розділи кругової діаграми виглядають подібними, оскільки мають майже однакові показники продажів.
# Ярлик для побудови кругової діаграми
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Цей ярлик збудує кругову діаграму кадру даних.
Топ 5 типів товарів з найбільшими продажами
Хоча ми вже порівняли всі продукти за середніми продажами, тепер я хотів би визначити 5 найкращих товарів з найбільшими продажами.
# Визначення топ 5 товарів з найбільшими продажами result = pandas_ai(df, "Які 5 типів товарів мають найбільші середні продажі? Покажи в табличній формі") result
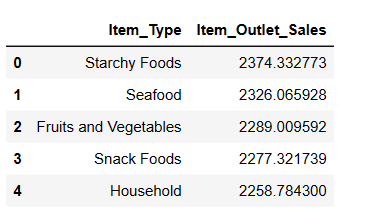
Як і очікувалося, виходячи з середнього обсягу продажів, найбільш популярним є товар з крохмалем.
Топ 5 типів товарів з найменшими продажами
result = pandas_ai(df, "Які 5 типів товарів мають найменші середні продажі?") result
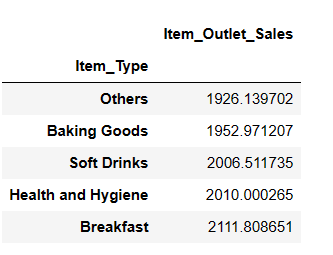
Ви можете здивуватися, побачивши безалкогольні напої в категорії найменших продажів. Однак, важливо зазначити, що ці дані стосуються лише 2008 року, а тенденція щодо безалкогольних напоїв з’явилася через кілька років.
Продаж категорій продуктів
Тут я використав вираз “категорія продукту” замість “тип товару”, і PandasAI все одно згенерував графіки, що демонструє його здатність розуміти схожі терміни.
result = pandas_ai(df, "Покажи велику стовпчасту діаграму з накопиченням продажів різних категорій продуктів за останній фінансовий рік") result
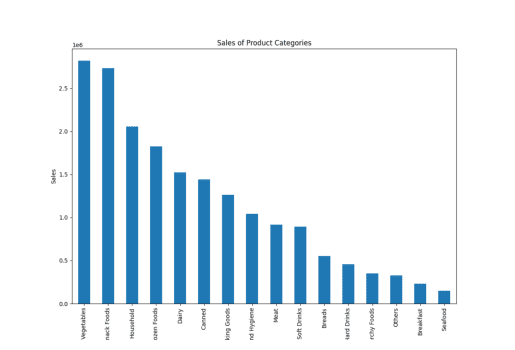
Продаж типу товару
Ви можете знайти інші ярлики тут.
Ви можете помітити, що коли ми пишемо запит та надаємо інструкції PandasAI, він надає результати виключно на основі цього запиту. Він не аналізує попередні запити, щоб запропонувати точніші відповіді.
Однак, з агентом чату можна досягти і цього.
Агент чату
За допомогою агента чату ви можете вести динамічні розмови, де агент зберігає контекст під час обговорення. Це забезпечує більш інтерактивну та змістовну взаємодію.
Основні функції, що забезпечують цю взаємодію, включають збереження контексту, коли агент запам’ятовує історію розмов, що забезпечує безперервну взаємодію, враховуючи контекст. Ви можете використовувати метод уточнюючих питань, щоб отримати пояснення з будь-якого аспекту розмови, гарантуючи повне розуміння наданої інформації.
Крім того, метод “Пояснити” дозволяє отримати докладні пояснення того, як агент дійшов до певного рішення або відповіді, забезпечуючи прозорість та розуміння процесу прийняття рішень агентом.
Не соромтеся розпочинати розмови, шукати пояснень та вивчати інформацію, щоб покращити вашу взаємодію з агентом чату!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Які 5 товарів мають найвищі ціни?")
result
На відміну від SmartDataframe або SmartDatalake, агент відстежує стан розмови та може відповідати на багатоступеневі запити.
Перейдемо до переваг та обмежень PandasAI.
Переваги PandasAI
Використання Pandas AI має ряд переваг, які роблять його цінним інструментом для аналізу даних, зокрема:
- Доступність: PandasAI спрощує аналіз даних, роблячи його доступним для широкого кола користувачів. Кожен, незалежно від свого технічного досвіду, може використовувати його для отримання інформації з даних та відповідей на бізнес-питання.
- Запити природною мовою: можливість задавати питання напряму та отримувати відповіді з даних за допомогою запитів природною мовою робить дослідження та аналіз даних зручнішими для користувача. Ця функція дозволяє навіть нетехнічним користувачам ефективно взаємодіяти з даними.
- Функціонал чат-агента: функція чату дозволяє користувачам взаємодіяти з даними в інтерактивному режимі, тоді як функція чат-агента використовує історію попередніх чатів для надання відповідей, що враховують контекст. Це сприяє динамічному та розмовному підходу до аналізу даних.
- Візуалізація даних: PandasAI надає різноманітні варіанти візуалізації даних, включаючи теплові карти, точкові діаграми, стовпчасті діаграми, кругові діаграми, лінійні графіки тощо. Ці візуалізації допомагають зрозуміти та представити закономірності та тренди в даних.
- Швидкі клавіші для економії часу: наявність ярликів та функцій для економії часу оптимізує процес аналізу даних, допомагаючи користувачам працювати більш ефективно та результативно.
- Сумісність файлів: PandasAI підтримує різні формати файлів, включаючи CSV, Excel, Google Sheets тощо. Ця гнучкість дозволяє користувачам працювати з даними з різних джерел та форматів.
- Спеціальні запити: користувачі можуть створювати власні запити за допомогою простих інструкцій та коду Python. Ця функція дозволяє користувачам адаптувати свою взаємодію з даними відповідно до конкретних потреб та запитів.
- Збереження змін: можливість зберігати зміни, внесені до кадрів даних, гарантує, що ваша робота буде збережена, і ви зможете в будь-який час переглянути свій аналіз та поділитися ним.
- Спеціальні відповіді: можливість створення власних відповідей дозволяє користувачам визначати конкретну поведінку або взаємодію, що робить інструмент ще більш універсальним.
- Інтеграція моделей: PandasAI підтримує різноманітні мовні моделі, включно з моделями Hugging Face, Azure, Google Palm, Google VertexAI та LangChain. Ця інтеграція розширює можливості інструменту та забезпечує розширену обробку та розуміння природної мови.
- Вбудована підтримка LangChain: вбудована підтримка моделей LangChain розширює спектр доступних моделей та функцій, підвищуючи глибину аналізу та розуміння, яке можна отримати з даних.
- Розуміння назв: PandasAI демонструє здатність розуміти взаємозв’язок між назвами стовпців та їхньою реальною термінологією. Наприклад, навіть якщо ви використовуєте такі терміни, як “категорія продукту” замість “тип товару” у своїх запитах, інструмент все одно зможе надати відповідні та точні результати. Ця гнучкість у розпізнаванні синонімів та їх співвіднесенні з відповідними стовпцями даних підвищує зручність використання та адаптивність інструменту до запитів природною мовою.
Хоча PandasAI має багато переваг, він також має певні обмеження та проблеми, про які користувачі повинні знати:
Обмеження PandasAI
Ось деякі обмеження, які я помітив:
- Необхідність ключа API: для використання PandasAI потрібен