Нова Ера в Управлінні Даними: Data Lakehouse
Data Lakehouse – це інноваційна архітектура для управління даними, яка об’єднує в собі переваги озер даних та сховищ даних. Завдяки використанню цієї структури, ви отримуєте можливість зберігати різноманітні типи даних в єдиній платформі, а також виконувати аналітику та запити, що відповідають вимогам ACID.
Чому варто обрати Data Lakehouse? Як розробник з досвідом, я чудово розумію, наскільки складно керувати двома окремими системами, підтримувати їхню працездатність та забезпечувати безперебійний потік даних між ними.
Якщо ваша мета – використовувати дані для бізнес-аналізу та створення звітів, то вам необхідно зберігати структуровані дані у сховищі. З іншого боку, для зберігання всіх даних з різних джерел у їхньому первинному форматі, потрібне озеро даних. Data Lakehouse усуває потребу в підтримці різних систем, оскільки вона поєднує в собі найкращі характеристики обох підходів.
Значення Data Lakehouse

Для розвитку вашої організації та бізнесу, необхідно мати можливість зберігати та аналізувати дані незалежно від їхньої структури та формату. Data Lakehouse є важливим елементом сучасного управління даними, адже вона нівелює обмеження, характерні для озер та сховищ даних.
Іноді озера даних можуть перетворюватися на “болота даних”, куди інформація скидається без належної структури чи управління. Це ускладнює пошук та використання даних, а також може призвести до проблем з їх якістю. З іншого боку, сховища даних часто є надмірно жорсткими та дорогими.
Data Lakehouse має свої особливості. Розгляньмо їх докладніше.
Характеристики Data Lakehouse
Перш ніж заглибитись в архітектуру Data Lakehouse, давайте розглянемо її ключові функції та характеристики:
- Підтримка транзакцій: При роботі з базами даних у великому масштабі, процеси читання та запису виконуються одночасно. Відповідність ACID гарантує, що ці паралельні операції не впливають на цілісність даних.
- Підтримка бізнес-аналітики: Інструменти BI можна інтегрувати безпосередньо з проіндексованими даними, що усуває необхідність копіювання інформації в іншу систему. Це дозволяє отримувати актуальні дані швидше та за меншу вартість.
- Розділення рівнів зберігання та обчислень: Розділення цих рівнів дозволяє масштабувати кожен з них незалежно. Наприклад, якщо потрібне більше місця для зберігання, ви можете додати його, не збільшуючи обчислювальні ресурси.
- Підтримка різноманітних типів даних: Data Lakehouse, базуючись на озері даних, підтримує різні типи та формати інформації. Ви можете зберігати та аналізувати аудіо, відео, зображення, текст та інші формати.
- Відкритість форматів зберігання даних: Data Lakehouse використовує відкриті та стандартизовані формати зберігання, такі як Apache Parquet, що забезпечує сумісність з різними інструментами та бібліотеками.
- Підтримка різноманітних робочих навантажень: З даними, що зберігаються в Data Lakehouse, можна виконувати широкий спектр задач, від запитів SQL до BI, аналітики та машинного навчання.
- Підтримка потокової обробки в реальному часі: Немає потреби створювати окреме сховище та конвеєр для аналізу даних в режимі реального часу.
- Управління схемою: Data Lakehouse забезпечує надійне керування та аудит даних.
Архітектура Data Lakehouse
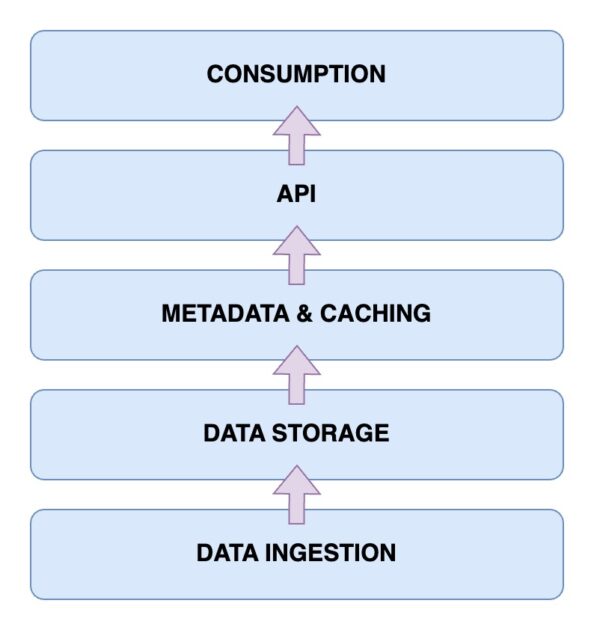
Розуміння архітектури Data Lakehouse є ключовим для розуміння її функціонування. Загалом, архітектура Data Lakehouse складається з п’яти основних компонентів, які ми розглянемо докладніше:
Рівень прийому даних
Це рівень, на якому фіксуються всі дані різних форматів. Сюди можуть входити зміни даних в основній базі, інформація з IoT-датчиків, або дані користувачів у режимі реального часу, отримані через потоки даних.
Рівень зберігання даних
Після отримання даних з різних джерел, їх необхідно зберегти у відповідних форматах. Тут в гру вступає рівень зберігання даних. Дані можуть зберігатися на різних носіях, таких як AWS S3. По суті, це ваше озеро даних.
Рівень метаданих і кешування
Після створення рівня зберігання, вам потрібні метадані та рівень управління даними. Він забезпечує єдине представлення всіх даних в озері. Цей рівень також додає транзакції ACID до озера даних, перетворюючи його на Data Lakehouse.
Рівень API
Доступ до проіндексованих даних з рівня метаданих можна отримати через рівень API. Це можуть бути драйвери баз даних для запуску запитів через код, або кінцеві точки, доступні з будь-якого клієнта.
Рівень споживання даних
Цей рівень включає аналітичні інструменти та інструменти бізнес-аналітики, які є основними споживачами даних з Data Lakehouse. Тут можна запускати програми машинного навчання для отримання корисної інформації з даних.
Отже, ви тепер маєте чітке розуміння архітектури Data Lakehouse. Але як її побудувати?
Кроки для побудови Data Lakehouse
Розглянемо процес створення власної Data Lakehouse. Незалежно від того, чи є у вас вже озеро або сховище даних, чи ви починаєте з нуля, кроки залишаються схожими:
- Визначте вимоги: Визначте типи даних, які ви будете зберігати, та цілі їхнього використання. Це можуть бути моделі машинного навчання, бізнес-звіти або аналітика.
- Створіть конвеєр прийому: Він відповідає за передачу даних до вашої системи. В залежності від джерел даних, можна використовувати шини обміну повідомленнями, наприклад Apache Kafka, або API-кінцеві точки.
- Створіть рівень зберігання: Якщо у вас вже є озеро даних, його можна використовувати як рівень зберігання. В іншому випадку, ви можете обрати різні варіанти, такі як AWS S3, HDFS або Delta Lake.
- Застосуйте обробку даних: На цьому етапі дані витягуються та перетворюються відповідно до потреб вашого бізнесу. Можна використовувати інструменти з відкритим кодом, наприклад Apache Spark, для запуску періодичних завдань з обробки даних з рівня зберігання.
- Створіть управління метаданими: Необхідно відстежувати та зберігати дані про різні типи інформації та їхні властивості для легкого каталогізування та пошуку. Також можна створити рівень кешування.
- Забезпечте інтеграцію: Після створення Data Lakehouse, необхідно надати інтеграційні інструменти для підключення та доступу до даних. Це можуть бути SQL запити, інструменти машинного навчання або рішення для бізнес-аналітики.
- Запровадьте управління даними: Необхідно встановити політику управління даними, включаючи контроль доступу, шифрування та аудит для забезпечення якості даних, їхньої цілісності та відповідності нормативним вимогам.
Далі розглянемо, як можна перейти до Data Lakehouse, якщо у вас вже є існуюче рішення для управління даними.
Етапи переходу до Data Lakehouse
При міграції робочого навантаження даних до Data Lakehouse, важливо враховувати наступні кроки. Наявність плану дій дозволить уникнути проблем в останній момент.
Крок 1: Аналіз даних
Аналіз даних – це початковий та один з найважливіших кроків для успішної міграції. З його допомогою ви можете визначити обсяг міграції, залежності та пріоритезувати завдання.
Крок 2: Підготовка даних до міграції
Наступний крок – підготовка даних до міграції. Це включає як самі дані, так і допоміжні структури. Знаючи, які набори даних та стовпці вам потрібні, ви зможете заощадити час та ресурси.
Крок 3: Перетворення даних у необхідний формат
Рекомендовано використовувати інструменти автоматичного перетворення. Перетворення даних при міграції до Data Lakehouse може бути складним. На щастя, більшість інструментів мають простий інтерфейс або рішення з низьким кодом. Такі інструменти, як Alchemist, можуть допомогти в цьому.
Крок 4: Перевірка даних після міграції
Після завершення міграції необхідно перевірити дані. Процес перевірки варто максимально автоматизувати, оскільки ручна міграція є виснажливою. Важливо переконатися, що ваші бізнес-процеси залишаються незмінними після міграції.
Основні характеристики Data Lakehouse
🔷 Повне керування даними: Data Lakehouse надає функції управління, що дозволяють ефективно використовувати дані. Це включає очищення даних, ETL-процеси, застосування схем. Таким чином, ви можете легко підготувати дані для аналітики та BI.
🔷 Відкриті формати зберігання: Формат зберігання даних є відкритим та стандартизованим, що дозволяє працювати з ними з самого початку. Підтримуються формати, такі як AVRO, ORC або Parquet, а також табличні дані.
🔷 Розділення сховища: Ви можете відокремити сховище від обчислювальних ресурсів за допомогою окремих кластерів, що дозволяє окремо збільшувати обсяг пам’яті за потреби, не змінюючи обчислювальні ресурси.
🔷 Підтримка потокової передачі даних: Data Lakehouse підтримує прийом даних в реальному часі, що є важливим для прийняття рішень на основі актуальної інформації.
🔷 Управління даними: Data Lakehouse підтримує ефективне управління, а також можливості аудиту, що важливо для підтримки цілісності даних.
🔷 Зниження витрат на дані: Експлуатаційні витрати Data Lakehouse є нижчими, ніж для сховищ даних. Ви можете використовувати хмарне сховище об’єктів за нижчою ціною та отримати гібридну архітектуру, що дозволяє уникнути потреби в підтримці кількох систем.
Data Lake проти Data Warehouse проти Data Lakehouse
| Характеристика | Data Lake | Data Warehouse | Data Lakehouse |
| Зберігання даних | Зберігає необроблені або неструктуровані дані | Зберігає оброблені та структуровані дані | Зберігає як необроблені, так і структуровані дані |
| Схема даних | Не має фіксованої схеми | Має фіксовану схему | Використовує схему з відкритим вихідним кодом для інтеграції |
| Перетворення даних | Дані не трансформуються | Потрібна розширена ETL | ETL виконується за потреби |
| Відповідність ACID | Не відповідає ACID | ACID-compliant | ACID-Compliant |
| Швидкість запитів | Як правило, повільніша, оскільки дані неструктуровані | Дуже швидка завдяки структурованим даним | Швидка завдяки напівструктурованим даним |
| Вартість зберігання | Економічно ефективна | Вищі витрати на зберігання та запити | Збалансована вартість зберігання та запитів |
| Управління даними | Потребує ретельного управління | Потребує надійного управління | Підтримує заходи управління |
| Аналітика в реальному часі | – | Підтримує аналітику в реальному часі | Підтримує аналітику в реальному часі |
| Випадки використання | Зберігання даних, дослідження, ML та AI | Звіти та аналіз за допомогою BI | Машинне навчання та аналітика |
Висновок
Data Lakehouse, поєднуючи переваги озер та сховищ даних, вирішує важливі проблеми, пов’язані з управлінням та аналізом даних.
Тепер ви знаєте про особливості та архітектуру Data Lakehouse. Її важливість полягає у здатності працювати як зі структурованими, так і з неструктурованими даними, пропонуючи уніфіковану платформу для зберігання, запитів та аналізу. Крім того, ви отримуєте підтримку ACID.
Завдяки крокам, описаним в цій статті, ви зможете розкрити переваги уніфікованої та економічно ефективної платформи управління даними, що сприяє прийняттю рішень на основі даних, аналітиці та розвитку бізнесу.
Рекомендуємо також ознайомитися з нашою статтею про реплікацію даних.