
Якщо ви новачок у аналізі великих даних, на вашому радарі може бути безліч інструментів apache; однак цілий набір різних інструментів може заплутати, а іноді й приголомшити.
Ця публікація розв’яже цю плутанину та пояснить, що таке Apache Hive та Impala та чим вони відрізняються один від одного!
Apache Hive
Apache Hive — це інтерфейс доступу до даних SQL для платформи Apache Hadoop. Hive дозволяє запитувати, агрегувати та аналізувати дані за допомогою синтаксису SQL.
Для даних у файловій системі HDFS використовується схема доступу для читання, що дозволяє обробляти дані як звичайні таблиці або реляційні СУБД. Запити HiveQL транслюються в код Java для завдань MapReduce.
Запити Hive написані мовою запитів HiveQL, яка базується на мові SQL, але не має повної підтримки стандарту SQL-92.
Однак ця мова дозволяє програмістам використовувати свої запити, коли використовувати функції HiveQL незручно або неефективно. HiveQL можна розширити за допомогою визначених користувачем скалярних функцій (UDF), агрегацій (кодів UDAF) і табличних функцій (UDTF).
Як працює Apache Hive
Apache Hive перекладає програми, написані мовою HiveQL (наближеною до SQL), в одне або кілька завдань MapReduce, Apache Tez або Apache Spark. Це три механізми виконання, які можна запустити на Hadoop. Потім Apache Hive організовує дані в масив для файлу розподіленої файлової системи Hadoop (HDFS), щоб виконувати завдання в кластері для отримання відповіді.
Таблиці Apache Hive схожі на реляційні бази даних, а одиниці даних організовані від найбільш значущої одиниці до найбільш детальної. Бази даних — це масиви, що складаються з розділів, які можна розбити на «відра».
Дані доступні через HiveQL. У кожній базі даних дані пронумеровані, і кожна таблиця відповідає каталогу HDFS.
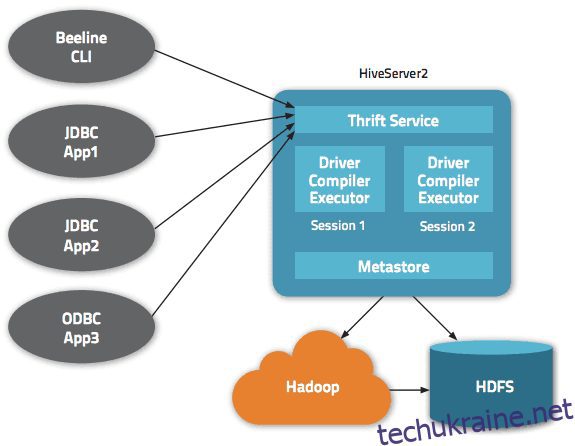
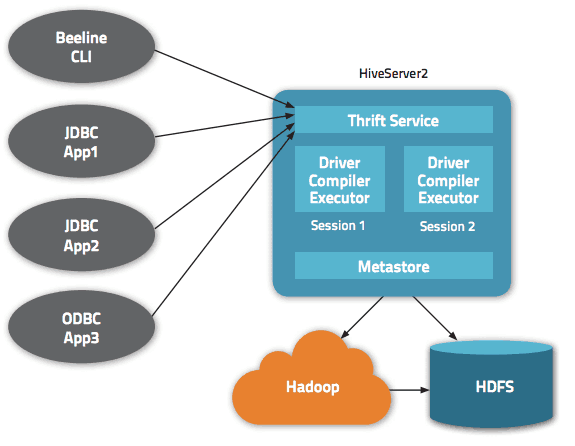
В архітектурі Apache Hive доступно кілька інтерфейсів, наприклад веб-інтерфейс, CLI або зовнішні клієнти.
Дійсно, сервер «Apache Hive Thrift» дозволяє віддаленим клієнтам надсилати команди та запити до Apache Hive за допомогою різних мов програмування. Центральний каталог Apache Hive є «метасховищем», що містить всю інформацію.
Механізм, який забезпечує роботу Hive, називається «драйвер». Він об’єднує компілятор і оптимізатор для визначення оптимального плану виконання.
Нарешті, безпеку забезпечує Hadoop. Тому він покладається на Kerberos для взаємної автентифікації між клієнтом і сервером. Дозвіл на щойно створені файли в Apache Hive диктується HDFS, дозволяючи користувачам, групам або іншим авторизаціям.
Особливості Hive
- Підтримує обчислювальний механізм як Hadoop, так і Spark
- Використовує HDFS і працює як сховище даних.
- Використовує MapReduce і підтримує ETL
- Завдяки HDFS він має відмовостійкість, подібну до Hadoop
Apache Hive: переваги
Apache Hive — ідеальне рішення для запитів і аналізу даних. Це дає змогу отримати якісну інформацію, забезпечуючи конкурентну перевагу та полегшуючи реагування на ринковий попит.
Серед головних переваг Apache Hive можна відзначити простоту використання, пов’язану з його «зручною для SQL» мовою. Крім того, це прискорює початкове введення даних, оскільки дані не потрібно зчитувати або нумерувати з диска у форматі внутрішньої бази даних.
Знаючи, що дані зберігаються в HDFS, можна зберігати великі набори даних розміром до сотень петабайт даних у Apache Hive. Це рішення є набагато більш масштабованим, ніж традиційна база даних. Знаючи, що це хмарна служба, Apache Hive дозволяє користувачам швидко запускати віртуальні сервери на основі коливань робочого навантаження (тобто завдань).
Безпека також є аспектом, де Hive працює краще, завдяки своїй здатності відтворювати критичні для відновлення робочі навантаження у разі виникнення проблеми. Нарешті, продуктивність не має собі рівних, оскільки він може виконувати до 100 000 запитів на годину.
Apache Impala
Apache Impala — це система масових паралельних SQL-запитів для інтерактивного виконання SQL-запитів до даних, що зберігаються в Apache Hadoop, написана на C++ і розповсюджується за ліцензією Apache 2.0.
Impala також називають двигуном MPP (Massively Parallel Processing), розподіленою СУБД і навіть стековою базою даних SQL-on-Hadoop.

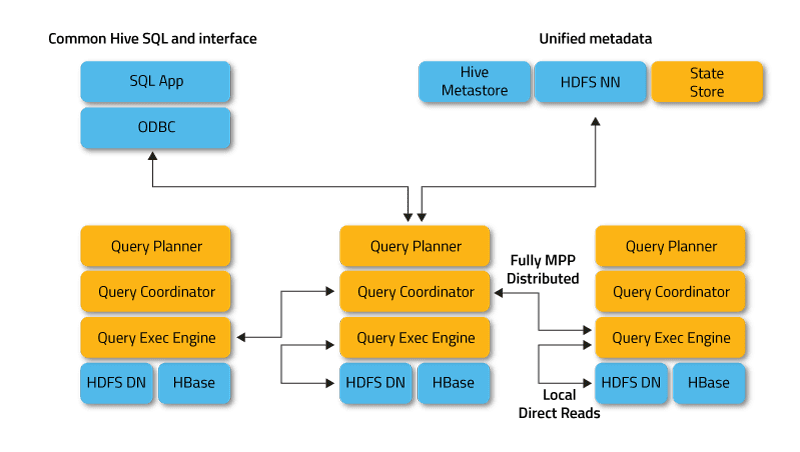
Impala працює в розподіленому режимі, де екземпляри процесів виконуються на різних вузлах кластера, отримуючи, плануючи та координуючи запити клієнтів. У цьому випадку можливе паралельне виконання фрагментів SQL-запиту.
Клієнти — це користувачі та програми, які надсилають запити SQL щодо даних, що зберігаються в Apache Hadoop (HBase та HDFS) або Amazon S3. Взаємодія з Impala відбувається через веб-інтерфейс HUE (Hadoop User Experience), ODBC, JDBC і оболонку командного рядка Impala Shell.
Impala інфраструктурно залежить від іншого популярного інструменту SQL-on-Hadoop, Apache Hive, використовуючи його сховище метаданих. Зокрема, Hive Metastore повідомляє Impala про доступність і структуру баз даних.
Під час створення, модифікації та видалення об’єктів схеми або завантаження даних у таблиці за допомогою операторів SQL відповідні зміни метаданих автоматично поширюються на всі вузли Impala за допомогою спеціалізованої служби каталогів.
Ключовими компонентами Impala є такі виконувані файли:
- Impalad або Impala daemon — це системна служба, яка планує та виконує запити до даних HDFS, HBase та Amazon S3. На кожному вузлі кластера виконується один процес impalad.
- Statestore — це служба імен, яка відстежує розташування та статус усіх примірників impalad у кластері. Один екземпляр цієї системної служби працює на кожному вузлі та головному сервері (Name Node).
- Каталог — це служба координації метаданих, яка поширює зміни з операторів Impala DDL і DML на всі зачеплені вузли Impala, щоб нові таблиці або щойно завантажені дані були негайно видимі для будь-якого вузла в кластері. Рекомендується, щоб один екземпляр Catalog запускався на тому самому хості кластера, що й демон Statestored.
Як працює Apache Impala
Impala, як і Apache Hive, використовує подібну декларативну мову запитів Hive Query Language (HiveQL), яка є підмножиною SQL92 замість SQL.
Фактичне виконання запиту в Impala виглядає наступним чином:
Клієнтська програма надсилає SQL-запит, підключаючись до будь-якого impalad через стандартизовані інтерфейси драйверів ODBC або JDBC. Підключений impalad стає координатором поточного запиту.
SQL-запит аналізується для визначення завдань для екземплярів impalad у кластері; потім будується оптимальний план виконання запиту.
Impalad отримує прямий доступ до HDFS і HBase, використовуючи локальні екземпляри системних служб для надання даних. На відміну від Apache Hive, така пряма взаємодія значно економить час виконання запиту, оскільки проміжні результати не зберігаються.
У відповідь кожен демон повертає дані координаційній імпаладі, надсилаючи результати назад клієнту.
Особливості Impala
- Підтримка обробки в пам’яті в реальному часі
- Дружній до SQL
- Підтримує такі системи зберігання, як HDFS, Apache HBase та Amazon S3
- Підтримує інтеграцію з такими інструментами BI, як Pentaho та Tableau
- Використовує синтаксис HiveQL
Apache Impala: переваги
Impala дозволяє уникнути можливих витрат на запуск, оскільки всі процеси системного демона запускаються безпосередньо під час завантаження. Це значно економить час виконання запиту. Додаткове збільшення швидкості Impala пов’язане з тим, що цей інструмент SQL для Hadoop, на відміну від Hive, не зберігає проміжні результати та безпосередньо звертається до HDFS або HBase.
Крім того, Impala генерує програмний код під час виконання, а не під час компіляції, як це робить Hive. Однак побічним ефектом високої швидкості Impala є зниження надійності.
Зокрема, якщо вузол даних вийде з ладу під час виконання запиту SQL, екземпляр Impala перезапуститься, а Hive продовжить підтримувати з’єднання з джерелом даних, забезпечуючи відмовостійкість.
Інші переваги Impala включають вбудовану підтримку безпечного мережевого протоколу автентифікації Kerberos, визначення пріоритетів і можливість керувати чергою запитів і підтримку популярних форматів великих даних, таких як LZO, Avro, RCFile, Parquet і Sequence.
Вулик проти Імпала: Подібності
Hive і Impala вільно поширюються за ліцензією Apache Software Foundation і відносяться до інструментів SQL для роботи з даними, що зберігаються в кластері Hadoop. Крім того, вони також використовують розподілену файлову систему HDFS.
Impala та Hive реалізують різні завдання зі спільним фокусом на SQL-обробці великих даних, що зберігаються в кластері Apache Hadoop. Impala надає інтерфейс, схожий на SQL, що дозволяє читати та записувати таблиці Hive, що забезпечує легкий обмін даними.
У той же час Impala робить SQL-операції на Hadoop досить швидкими та ефективними, дозволяючи використовувати цю СУБД в дослідницьких проектах аналітики великих даних. За можливості Impala працює з існуючою інфраструктурою Apache Hive, яка вже використовується для виконання тривалих пакетних запитів SQL.
Крім того, Impala зберігає визначення своїх таблиць у метасховищі, традиційній базі даних MySQL або PostgreSQL, тобто в тому самому місці, де Hive зберігає подібні дані. Це дозволяє Impala отримувати доступ до таблиць Hive, якщо всі стовпці використовують підтримувані Impala типи даних, формати файлів і кодеки стиснення.
Вулик проти Імпала: відмінності

Мова програмування
Hive написаний на Java, тоді як Impala на C++. Однак Impala також використовує деякі Hive UDF на основі Java.
Випадки використання
Інженери обробки даних використовують Hive у процесах ETL (видобуток, перетворення, завантаження), наприклад, для тривалих пакетних завдань над великими наборами даних, наприклад, у туристичних агрегаторах та інформаційних системах аеропортів. У свою чергу Impala призначена в основному для аналітиків і спеціалістів із обробки даних і в основному використовується в таких завданнях, як бізнес-аналітика.
Продуктивність
Impala виконує SQL-запити в реальному часі, а Hive характеризується низькою швидкістю обробки даних. За допомогою простих запитів SQL Impala може працювати в 6-69 разів швидше, ніж Hive. Однак Hive краще обробляє складні запити.
Затримка/пропускна здатність
Пропускна здатність Hive значно вища, ніж у Impala. Функція LLAP (Live Long and Process), яка дозволяє кешувати запити в пам’яті, забезпечує Hive хорошу продуктивність на низькому рівні.
LLAP включає довгострокові системні служби (демони), які дозволяють безпосередньо взаємодіяти з вузлами даних HDFS і замінюють тісно інтегровану структуру запитів DAG (спрямований ациклічний граф) – графову модель, яка активно використовується в обчисленнях великих даних.
Відмовостійкість
Hive — це відмовостійка система, яка зберігає всі проміжні результати. Це також позитивно впливає на масштабованість, але призводить до зниження швидкості обробки даних. У свою чергу Impala не можна назвати відмовостійкою платформою, тому що вона більше прив’язана до пам’яті.
Перетворення коду
Hive генерує вирази запиту під час компіляції, тоді як Impala генерує їх під час виконання. Hive характеризується проблемою «холодного запуску» під час першого запуску програми; запити перетворюються повільно через необхідність встановлення підключення до джерела даних.
У Impala немає таких витрат на запуск. Необхідні системні служби (демони) для обробки SQL-запитів запускаються під час завантаження, що прискорює роботу.
Підтримка зберігання
Impala підтримує формати LZO, Avro та Parquet, тоді як Hive працює з Plain Text та ORC. Однак обидва підтримують формати RCFIle і Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Випадки використанняІнженерна розробка данихАналіз і аналітикаВисока продуктивність для простих запитів Порівняно низька затримка Більша затримка через кешування Менш прихована відмовостійкістьБільша толерантність завдяки MapReduceМенш толерантна через MPPConversionПовільна через холодний старт Швидша конверсіяПідтримка зберіганняPlain Text і ORCLZO, Avro, Parquet
Заключні слова
Hive та Impala не конкурують, а скоріше ефективно доповнюють один одного. Незважаючи на значні відмінності між ними, є також багато спільного, і вибір одного над іншим залежить від даних і конкретних вимог проекту.
Ви також можете ознайомитися з прямими порівняннями між Hadoop і Spark.
.