Веб-скрапінг – це процес вилучення інформації з веб-сайтів для подальшого використання у різних цілях.
Уявіть собі ситуацію, коли потрібно отримати дані з таблиці на веб-сторінці, конвертувати їх у формат JSON, а потім використати цей JSON для створення внутрішніх інструментів. Завдяки веб-скрапінгу ви можете точно видобувати необхідні дані, звертаючись до конкретних елементів веб-сторінки. Python є популярним вибором для веб-скрапінгу, оскільки пропонує ряд бібліотек, таких як BeautifulSoup або Scrapy, які спрощують ефективне вилучення даних.
Навички ефективного видобутку даних є важливими для розробників та дослідників даних. Ця стаття допоможе вам зрозуміти, як правильно здійснювати веб-скрапінг і отримувати необхідну інформацію для подальшої обробки. У цьому керівництві ми будемо використовувати бібліотеку BeautifulSoup, відому своїми можливостями у сфері веб-скрапінгу на Python.
Чому Python є вибором для веб-скрапінгу?
Python є першим вибором для багатьох розробників, коли йдеться про створення веб-скраперів. Існує безліч причин, чому саме Python обирають для цих цілей, але ми зосередимося на трьох основних:
Велика підтримка бібліотек та спільноти: Python має кілька потужних бібліотек, таких як BeautifulSoup, Scrapy та Selenium, які надають розширений функціонал для ефективного сканування веб-сторінок. Це створює чудову екосистему для веб-скрапінгу, а велика кількість розробників, що використовують Python по всьому світу, забезпечує швидку підтримку у разі виникнення труднощів.
Автоматизація: Python відомий своїми можливостями в галузі автоматизації. Якщо ви плануєте розробляти складні інструменти, які використовують веб-скрапінг, вам знадобиться не тільки вміння видобувати дані, а й автоматизувати цей процес. Наприклад, якщо вам потрібно розробити інструмент для відстеження цін на товари в інтернет-магазині, потрібна буде автоматизація для щоденного відстеження цін та їх додавання до бази даних. Python дозволяє легко автоматизувати такі процеси.
Візуалізація даних: Веб-скрапінг широко використовується фахівцями з обробки даних, яким часто потрібно отримувати дані з веб-сторінок. Завдяки бібліотекам, таким як Pandas, Python спрощує візуалізацію видобутих даних.
Бібліотеки для веб-скрапінгу в Python
Python пропонує декілька бібліотек, що спрощують процес веб-скрапінгу. Розглянемо три найпопулярніші:
#1. BeautifulSoup
Це одна з найпопулярніших бібліотек для веб-скрапінгу, яка допомагає розробникам обробляти веб-сторінки з 2004 року. Вона надає прості методи для навігації, пошуку та модифікації дерева аналізу HTML. BeautifulSoup також обробляє кодування вхідних та вихідних даних. Бібліотека активно підтримується та має велику спільноту.
#2. Scrapy
Ще один популярний фреймворк для видобутку даних. Scrapy має понад 43 000 зірок на GitHub. Його можна використовувати не тільки для веб-скрапінгу, але і для отримання даних з API. Фреймворк також має корисні вбудовані засоби, наприклад, для відправки електронних листів.
#3. Selenium
Selenium – це, скоріше, інструмент для автоматизації браузерів, ніж суто бібліотека для веб-скрапінгу. Однак, його функціонал можна використовувати для копіювання веб-сторінок. Selenium використовує протокол WebDriver для керування різними браузерами. Цей інструмент присутній на ринку вже близько 20 років. За допомогою Selenium можна легко автоматизувати процеси та видобувати дані з веб-сторінок.
Проблеми, пов’язані з веб-скрапінгом на Python
При спробах вилучення даних з веб-сайтів можна зіткнутися з різними труднощами, такими як низька швидкість мережі, наявність інструментів для захисту від скрапінгу, блокування на основі IP-адреси, використання капчі тощо. Ці проблеми можуть ускладнити процес скрапінгу.
Однак, можна ефективно обійти ці труднощі, дотримуючись певних стратегій. Наприклад, веб-сайти часто блокують IP-адреси, з яких надходить велика кількість запитів за короткий проміжок часу. Щоб уникнути блокування IP-адреси, потрібно налаштувати скрапер таким чином, щоб він робив паузи між запитами.

Розробники веб-сайтів також створюють пастки для скраперів. Ці пастки часто невидимі для звичайних користувачів, але скрапер може їх виявити. Якщо ви збираєте дані з веб-сайту, що використовує такі пастки, необхідно налаштувати скрапер відповідним чином.
Капча є ще однією серйозною проблемою для скраперів. Більшість сучасних веб-сайтів використовують капчу для захисту від ботів. У таких випадках може знадобитися використання інструментів для розпізнавання капчі.
Скрапінг веб-сайту з використанням Python
Як зазначалося раніше, ми будемо використовувати BeautifulSoup для веб-скрапінгу. У цьому прикладі ми зберемо історичні дані про Ethereum з Coingecko і збережемо табличні дані у форматі JSON. Розпочнемо створення скрапера.
Першим кроком буде встановлення бібліотек BeautifulSoup та Requests. У цьому прикладі ми будемо використовувати Pipenv, менеджер віртуального середовища для Python. Ви також можете використовувати Venv, якщо бажаєте, але ми радимо Pipenv. Детальний опис використання Pipenv виходить за рамки цієї статті. Але, якщо ви хочете дізнатися більше, ви можете ознайомитися з цим посібником. Або, якщо ви хочете зрозуміти, як працюють віртуальні середовища Python, ви можете скористатися цим посібником.
Запустіть оболонку Pipenv у каталозі вашого проекту, виконавши команду `pipenv shell`. Це відкриє під-оболонку у вашому віртуальному середовищі. Тепер, щоб встановити BeautifulSoup, виконайте наступну команду:
pipenv install beautifulsoup4
А для встановлення requests, виконайте аналогічну команду:
pipenv install requests
Після встановлення, імпортуйте необхідні пакети у ваш основний файл. Створіть файл під назвою main.py та імпортуйте пакети, як показано нижче:
from bs4 import BeautifulSoup import requests import json
Наступний крок – отримати вміст сторінки з історичними даними та проаналізувати її за допомогою HTML-аналізатора, доступного у BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
У наведеному коді, доступ до сторінки здійснюється за допомогою методу `get` з бібліотеки requests. Проаналізований вміст зберігається у змінній `soup`.
Тепер починається основна частина скрапінгу. Спочатку необхідно правильно визначити таблицю в DOM-структурі сторінки. Якщо ви відкриєте сторінку та перевірите її за допомогою інструментів розробника у браузері, ви побачите, що таблиця має класи `table table-striped text-sm text-lg-normal`.
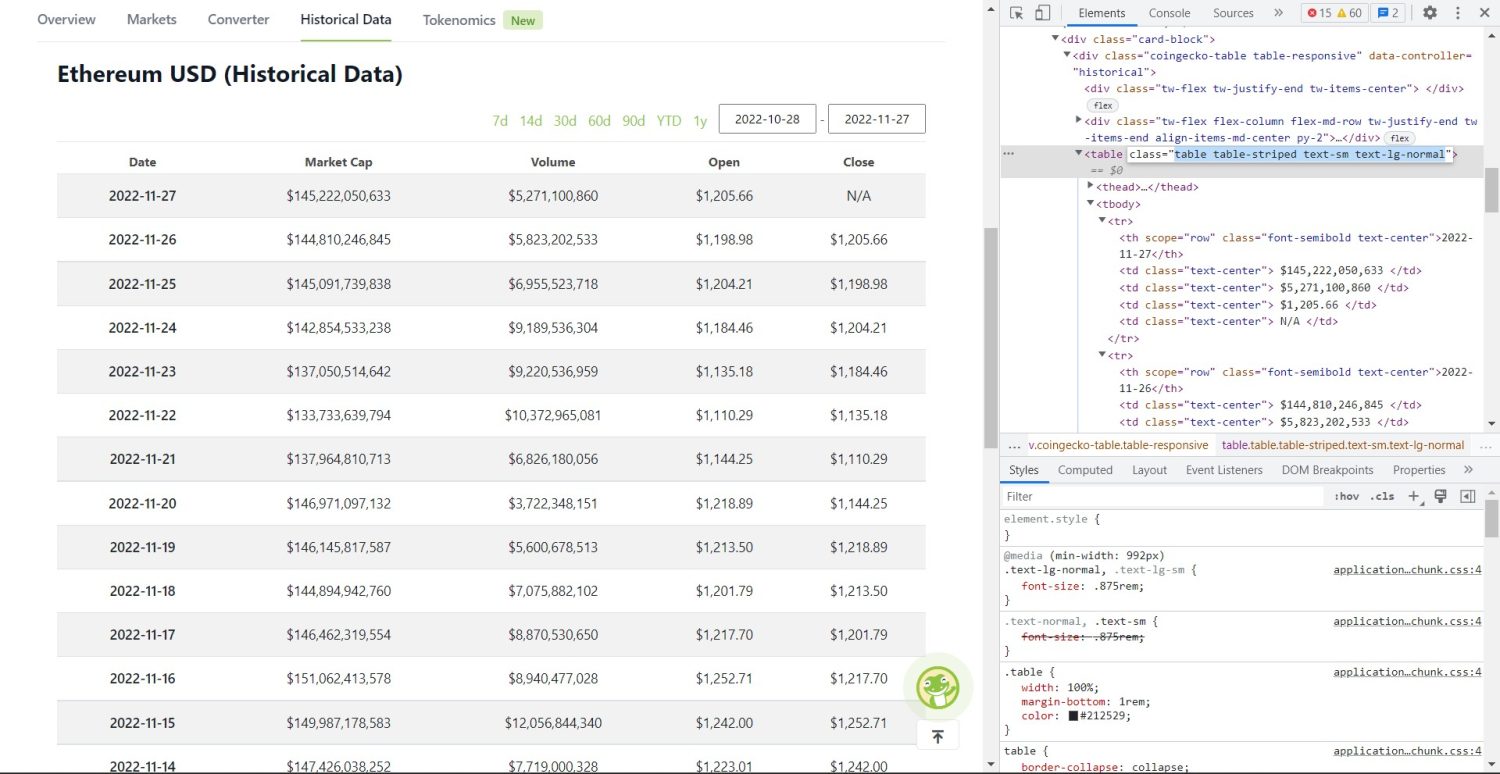 Таблиця історичних даних Coingecko Ethereum
Таблиця історичних даних Coingecko Ethereum
Для точного вибору цієї таблиці, можна використовувати метод `find`.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
У наведеному коді, спочатку таблиця знаходиться за допомогою методу `soup.find`, а потім методом `find_all` знаходяться усі елементи `tr` всередині таблиці. Ці елементи `tr` зберігаються у змінній `table_data`. Таблиця містить елементи заголовків. Створюється нова змінна `table_headings` для зберігання заголовків у списку.
Далі запускається цикл `for` для першого рядка таблиці. У цьому рядку знаходяться усі елементи `th`, а їх текстові значення додаються до списку `table_headings`. Текст видобувається за допомогою методу `text`. Якщо ви виведете змінну `table_headings` на екран, то побачите наступний результат:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Наступним кроком є обробка решти елементів, створення словника для кожного рядка, а потім додавання цих рядків до списку.
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Це є ключовою частиною коду. Для кожного елемента `tr` у змінній `table_data` спочатку шукаються елементи `th`. Ці елементи – це дата, показана в таблиці. Елементи `th` зберігаються в змінній `th`. Аналогічно, усі елементи `td` зберігаються у змінній `td`.
Створюється порожній словник `data`. Після ініціалізації ми проходимося по діапазону елементів `td`. Для кожного рядка, спочатку ми оновлюємо перше поле словника, використовуючи перший елемент `th`. Код `data.update({table_headings[0]: th[0].text})` встановлює пару ключ-значення дати та першого елемента `th`.
Після встановлення першого елемента, інші елементи призначаються за допомогою `data.update({table_headings[i+1]: td[i].text.replace(‘n’, ”)})`. Тут, спочатку видобувається текст елементів `td` за допомогою методу `text`, а потім усі символи `n` замінюються на порожній рядок за допомогою методу `replace`. Потім, значення присвоюється i+1-му елементу списку `table_headings`, оскільки i-й елемент вже призначено.
Далі, якщо довжина словника `data` більша за нуль, ми додаємо словник до списку `table_details`. Ви можете вивести список `table_details` на екран для перевірки. Але ми запишемо значення у файл JSON. Погляньмо на код для цього:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Тут, ми використовуємо метод `json.dump` для запису значень у файл JSON з назвою `table.json`. Після закінчення запису, на консоль виводиться повідомлення “Data saved to json file…”.
Тепер запустіть файл за допомогою наступної команди:
python main.py
Через деякий час, ви побачите на консолі повідомлення “Data saved to json file…”. Також у каталозі проекту з’явиться файл з назвою `table.json`. Вміст цього файлу буде виглядати приблизно так:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Ви успішно реалізували веб-скрапер на Python. Щоб переглянути повний код, ви можете відвідати це сховище на GitHub.
Висновок
У цій статті ми розглянули, як можна реалізувати простий веб-скрапер за допомогою Python. Ми обговорили, як використовувати BeautifulSoup для швидкого видобування даних з веб-сайту. Також, ми розглянули інші доступні бібліотеки та з’ясували, чому Python є кращим вибором для веб-скрапінгу для багатьох розробників.
Ви можете також ознайомитися з цими фреймворками для веб-скрапінгу.