Prometheus — це відкрита система для моніторингу, яка базується на зборі та аналізі метрик. Вона працює, надсилаючи HTTP-запити до спеціальних кінцевих точок, де розташовані дані про метрики різних служб і хостів. Отримані результати зберігаються в базі даних часових рядів для подальшого аналізу та налаштування оповіщень.
Навіщо потрібен моніторинг?
- Він дозволяє отримувати сповіщення про проблеми, бажано ще до того, як вони виникнуть, щоб можна було вчасно зреагувати.
- Надає необхідну інформацію для аналізу, налагодження та вирішення різних проблем.
- Допомагає відстежувати тенденції та зміни з плином часу, наприклад, кількість активних сеансів у будь-який момент, що сприяє прийняттю обґрунтованих рішень та плануванню потужностей.
Моніторинг зазвичай охоплює події, такі як отримання HTTP-запиту, надсилання відповіді, читання з диску або введення даних користувачем. Системний моніторинг може включати профілювання, журналювання, трасування, аналіз метрик, оповіщення та візуалізацію даних.
Моніторинг за принципами “чорної скриньки” та “білої скриньки”
Моніторинг можна розділити на дві основні категорії:
Моніторинг “чорної скриньки”
У цьому підході моніторинг здійснюється на рівні програми або хоста, спостерігаючи за ними ззовні. Цей метод може мати певні обмеження, оскільки не дає доступу до внутрішніх процесів.
Моніторинг “білої скриньки”
Моніторинг “білої скриньки” передбачає спостереження за внутрішньою роботою служби. Він розкриває дані про стан та продуктивність внутрішніх компонентів.
Чотири основні сигнали
Згідно з рекомендаціями Google, якщо необхідно вимірювати лише кілька показників вашої системи, що орієнтована на користувача, варто зосередитися на чотирьох ключових сигналах:
#1. Затримка
Час, необхідний для обробки запиту, незалежно від того, успішний він чи ні. Важливо відстежувати як успішні, так і невдалі запити, щоб мати повну картину.
#2. Трафік
Показує рівень навантаження на систему. Для веб-сервісів це зазвичай вимірюється в кількості HTTP-запитів за секунду.
#3. Помилки
Відсоток невдалих запитів.
#4. Насиченість
Показує, наскільки завантажена ваша служба. Зростання затримки часто є ознакою насичення. Багато систем починають працювати повільніше задовго до того, як їх завантаження досягне 100%.
Типи метрик в Prometheus
В Prometheus існує чотири основні типи метрик:
#1. Лічильник
Значення лічильника завжди зростає. Воно ніколи не може зменшитися, але його можна скинути до нуля. Якщо дані не вдається зібрати, це означає лише пропущену точку, а загальне збільшення буде доступним при наступному зборі. Приклади:
- Загальна кількість отриманих HTTP-запитів
- Кількість винятків.
#2. Датчик
Датчик відображає поточне значення в будь-який момент часу. Його значення може як збільшуватися, так і зменшуватися. У разі невдалого збору даних, ви просто втрачаєте цей знімок; наступний збір може показати інше значення. Приклади: обсяг вільного місця на диску, використання пам’яті.
#3. Гістограма
Гістограма збирає дані та підраховує їх у попередньо визначених діапазонах. Вона використовується для вимірювання таких показників, як тривалість запитів або розмір відповідей. Наприклад, можна виміряти тривалість певного HTTP-запиту. Гістограма має набір сегментів, наприклад, 1 мс, 10 мс і 25 мс. Замість зберігання тривалості для кожного запиту, Prometheus зберігає частоту запитів, що потрапляють у певний діапазон.
#4. Зведення
Подібно до гістограм, зведення аналізує дані, зазвичай тривалість запитів або розміри відповідей. Воно надає загальну кількість вимірювань і суму всіх виміряних значень, що дозволяє розрахувати середнє значення. Наприклад, за хвилину було 3 запити, що зайняли 2, 3 і 4 секунди. Сума буде 9, а кількість — 3. Середня затримка складе 3 секунди.
Компоненти екосистеми Prometheus
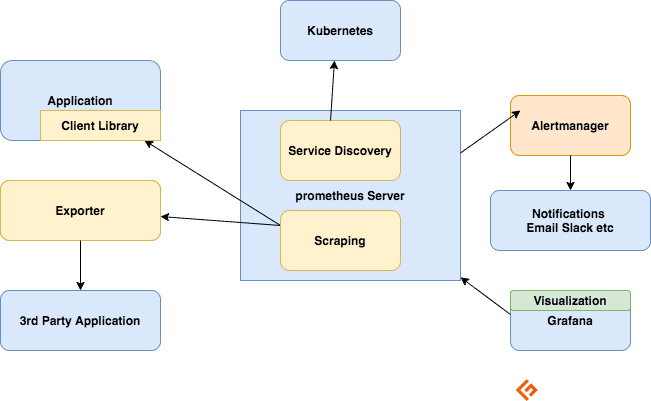
Сервер Prometheus
Збирає метрики, зберігає їх та надає доступ для запитів. Також відправляє оповіщення на основі зібраних даних.
Збір даних (Scraping)
Prometheus використовує модель “витягування” даних. Для отримання метрик Prometheus надсилає HTTP-запити, які називаються “скрейпінгом” (scraping). Він надсилає такі запити до цілей, що визначені в його конфігурації.
Кожна ціль (статично визначена або динамічно знайдена) перевіряється через певні інтервали. Під час кожного сканування зчитується кінцева точка HTTP /metrics, щоб отримати поточні значення метрик клієнта та зберегти їх у базі даних часових рядів Prometheus.
Існує багато інших баз даних часових рядів, які можна використовувати для моніторингу.
Клієнтські бібліотеки
Для моніторингу служб потрібно додати інструментарій до коду. Існують клієнтські бібліотеки для багатьох популярних мов та середовищ виконання. З їхньою допомогою можна додати кілька рядків коду, і ваш код почне видавати метрики. Це називається прямим інструментуванням. Ці бібліотеки дозволяють визначати внутрішні метрики та показувати їх через HTTP-кінцеву точку. Коли Prometheus сканує цю кінцеву точку, клієнтська бібліотека відправляє метрики на сервер.
Prometheus пропонує офіційні клієнтські бібліотеки для Go, Java, Python та Ruby. Існує також велика кількість клієнтських бібліотек, створених спільнотою, для C, PHP, Node.js, C#/.NET та інших мов.
Експортери
Багато програм надають метрики в іншому форматі, відмінному від Prometheus. Для таких програм, а також для програм, до яких ви не маєте доступу до коду, пряме інструментування неможливе. Наприклад, сервери MySQL, Kafka, JMX, HAProxy та NGINX. В таких випадках використовуються експортери.
Експортер — це окрема програма, яку потрібно розгорнути разом із цільовою програмою. Він діє як проксі між програмою та Prometheus. Він отримує запити від сервера Prometheus, збирає дані з логів доступу, логів помилок програми, перетворює їх у потрібний формат і передає на сервер Prometheus.
Приклади популярних експортерів:
- Windows – для метрик серверів Windows
- Node – для метрик серверів Linux
- Blackbox – для моніторингу DNS та продуктивності вебсайтів
- JMX – для моніторингу Java-додатків
Після інструментування додатків або встановлення експортерів потрібно вказати Prometheus, де їх знайти. Це можна зробити за допомогою статичної конфігурації. У випадку динамічних середовищ використовується виявлення служб.
Оповіщення
Система оповіщень Prometheus складається з двох частин:
Правила сповіщень надсилають оповіщення в Alertmanager.
Alertmanager керує цими сповіщеннями. Він може надсилати повідомлення різними способами, наприклад, електронною поштою, Slack, Hipchat та PagerDuty. Alertmanager також може виконувати заглушення або агрегацію, щоб зменшити кількість сповіщень.
Ось посібник з моніторингу Linux-сервера за допомогою Prometheus і Dashboard.
Візуалізація за допомогою панелей
Prometheus має ряд API, які дозволяють PromQL-запитам витягувати дані для візуалізації.
Хоча Prometheus має вбудований браузер виразів, найкращим інструментом для візуалізації є Grafana. Grafana повністю інтегрується з Prometheus та дозволяє створювати різноманітні панелі для аналізу.
Для цього потрібно налаштувати Prometheus як джерело даних для Grafana.
Панелі інструментів можна додавати різними способами:
- Імпортувати панелі інструментів, розроблені спільнотою
- Створити власні
- Використовувати готові панелі
Ось приклад готової панелі експортера вузлів:
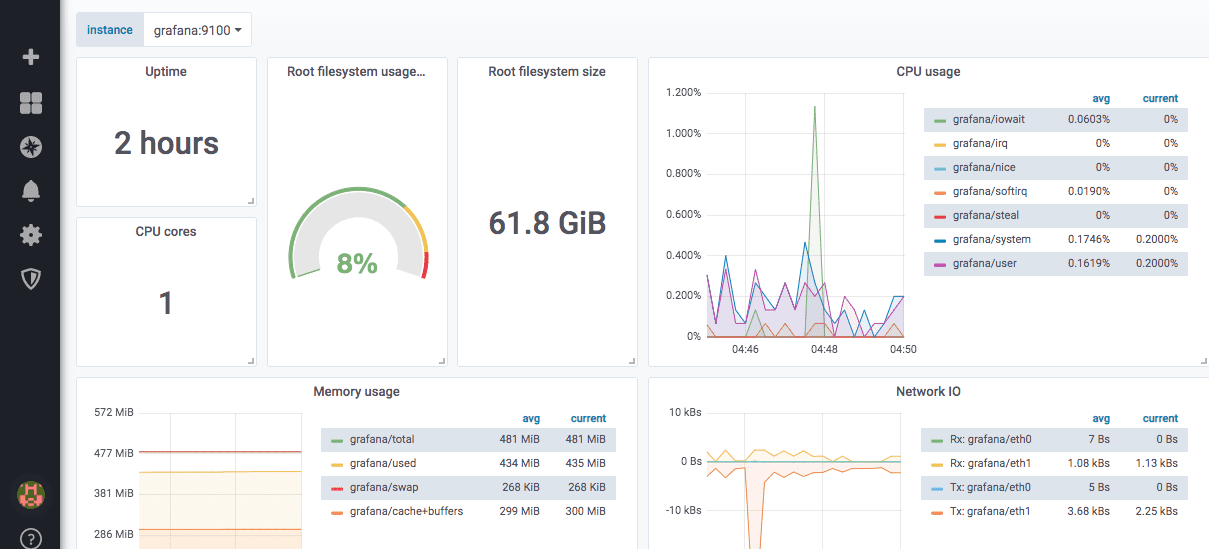
Grafana має модуль worldPing, який дозволяє відстежувати продуктивність сайту та DNS в різних точках світу.
Підсумки
Prometheus має досить низькі вимоги. Його досить легко запустити, оскільки це один виконуваний файл з файлом конфігурації. Він може обробляти тисячі цілей та мільйони зразків за секунду. Prometheus призначений для відстежування загального стану системи, її поведінки та працездатності.
Grafana є найкращим інструментом для візуалізації показників і легко інтегрується з Prometheus.