Команда Linux curl має значно ширші можливості, ніж просто завантаження файлів. Розглянемо глибше, на що здатна ця утиліта та в яких ситуаціях доцільніше використовувати її, а не wget.
Відмінності між curl і wget
Часто виникає плутанина щодо переваг використання wget або curl. Хоча ці команди мають певні перехрестя у функціональності, їхні можливості та призначення відрізняються. Обидві команди можуть отримувати файли з віддалених джерел, але на цьому подібність закінчується.
wget – це чудовий інструмент для завантаження різноманітного контенту, включаючи файли, веб-сторінки та каталоги. Він здатен аналізувати посилання на веб-сторінках та рекурсивно завантажувати контент з цілого веб-сайту. Його можна вважати неперевершеним менеджером завантажень в командному рядку.
З іншого боку, curl призначений для іншого спектру завдань. Він також може отримувати файли, але не має можливості рекурсивно досліджувати веб-сайт для завантаження контенту. Натомість curl дозволяє взаємодіяти з віддаленими системами, надсилаючи запити та отримуючи відповіді. Ці відповіді можуть включати веб-сторінки, файли, а також дані, отримані через веб-сервіси або API в результаті запитів, надісланих curl.
Важливо відзначити, що curl не обмежений лише веб-сайтами. Він підтримує понад 20 протоколів, включаючи HTTP, HTTPS, SCP, SFTP і FTP. Завдяки потужній обробці каналів в Linux, curl можна інтегрувати з іншими командами та скриптами.
Автор curl на своїй веб-сторінці докладно описує різницю між curl і wget.
Встановлення curl
У системах Fedora 31 та Manjaro 18.1.0, які використовувалися для написання цієї статті, curl вже був встановлений. На Ubuntu 18.04 LTS його необхідно встановити. Для цього виконайте наступну команду:
sudo apt-get install curl

Перевірка версії curl
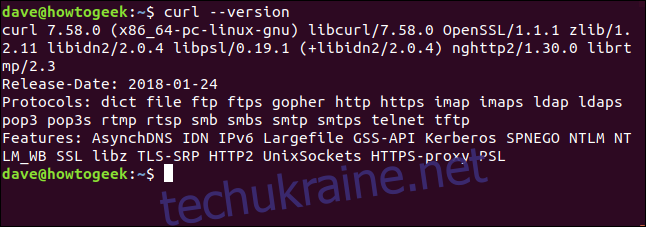
Щоб переглянути версію curl та список підтримуваних протоколів, використовуйте параметр –version:
curl --version
Отримання веб-сторінки
Якщо ви вкажете curl на веб-сторінку, він її отримає.
curl https://www.bbc.com

За замовчуванням curl виводить вихідний код сторінки у вікно терміналу.
Увага: якщо ви не вкажете curl зберегти отримані дані у файл, він завжди виводитиме їх у вікно терміналу. У випадку з двійковими файлами, це може призвести до непередбачуваних результатів, оскільки оболонка може спробувати інтерпретувати деякі байти як керуючі символи.
Збереження даних у файл
Давайте навчимо curl перенаправляти вихід у файл:
curl https://www.bbc.com > bbc.html

Інформація про прогрес включає:
- % Total: загальний обсяг даних, які потрібно отримати.
- % Received: відсоток та фактичний обсяг отриманих даних.
- % Xferd: відсоток та фактичний обсяг переданих даних, якщо дані завантажуються.
- Avg Speed Download: середня швидкість завантаження.
- Avg Speed Upload: середня швидкість завантаження.
- Total Time: орієнтовна загальна тривалість передачі.
- Time Spent: час, що пройшов з початку передачі.
- Time Left: орієнтовний час, що залишився до завершення передачі.
- Current Speed: поточна швидкість передачі.
Оскільки вихід з curl було перенаправлено у файл, тепер у нас є файл під назвою “bbc.html”.

Відкривши цей файл, ви побачите веб-сторінку у своєму браузері за замовчуванням.
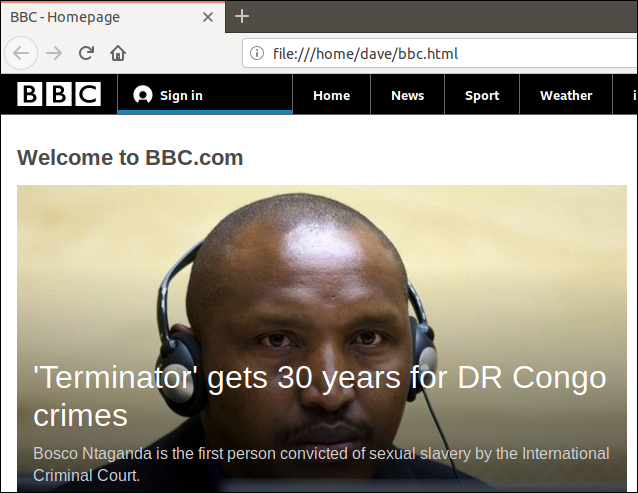
Зверніть увагу, що адреса в адресному рядку браузера вказує на локальний файл на вашому комп’ютері, а не на віддалений веб-сайт.
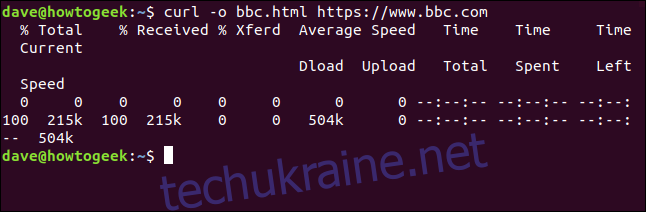
Для створення файлу не обов’язково використовувати перенаправлення виводу. Можна скористатися параметром -o (output) та вказати curl створити файл. У наступному прикладі ми використовуємо параметр -o і вказуємо ім’я файлу “bbc.html”, який потрібно створити.
curl -o bbc.html https://www.bbc.com
Використання індикатора прогресу завантаження
Щоб замість текстової інформації про завантаження відображався простий індикатор прогресу, використовуйте параметр -# (індикатор прогресу).
curl -# -o bbc.html https://www.bbc.com

Відновлення перерваного завантаження
Перерване завантаження можна легко відновити. Розпочнемо завантаження великого файлу. Скористаємося останньою версією Ubuntu 18.04 з довгостроковою підтримкою. Параметр –output вкаже curl зберегти завантажений файл з ім’ям “ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Завантаження розпочнеться і триватиме до завершення.
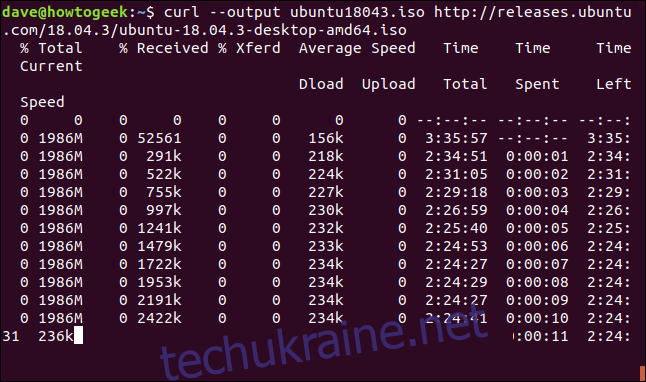
Якщо ми перервемо завантаження, натиснувши Ctrl+C, ми повернемося до командного рядка, а завантаження зупиниться.
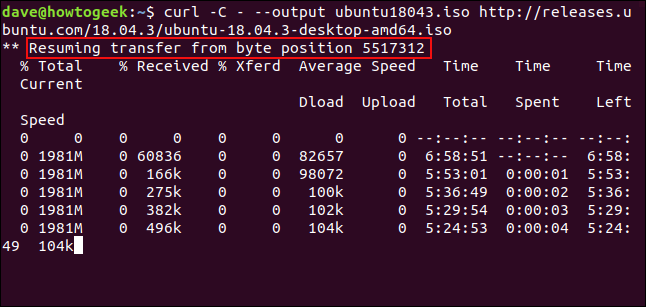
Для відновлення завантаження використовуйте опцію -C (continue at). Це змусить curl відновити завантаження з визначеної точки або зсуву в цільовому файлі. Якщо використовувати дефіс (-) як значення зсуву, curl перевірить вже завантажену частину файлу та визначить правильний зсув для відновлення.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Завантаження було відновлено. curl повідомляє про зсув, з якого він відновив завантаження.
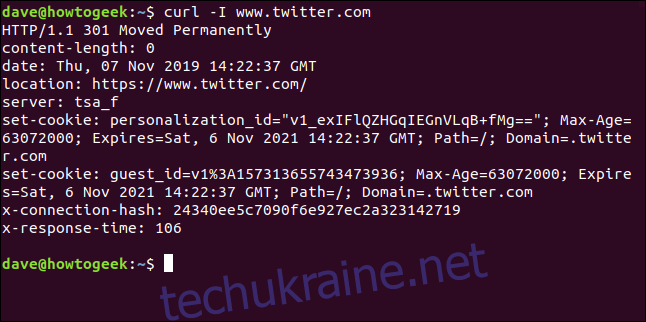
Отримання HTTP-заголовків
За допомогою параметра -I (head) ви можете отримати лише HTTP-заголовки. Це аналогічно надсиланню команди HTTP HEAD на веб-сервер.
curl -I www.twitter.com

Ця команда отримує лише інформацію; вона не завантажує веб-сторінки чи файли.
Завантаження кількох URL-адрес
За допомогою xargs можна завантажити декілька URL-адрес за один раз. Наприклад, якщо потрібно завантажити серію веб-сторінок, які складають одну статтю або навчальний посібник.
Скопіюйте наступні URL-адреси в текстовий редактор і збережіть їх у файл “urls-to-download.txt”. Команда xargs обробляє кожен рядок текстового файлу як параметр для curl.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Для передачі URL-адрес в curl, скористайтеся наступною командою:
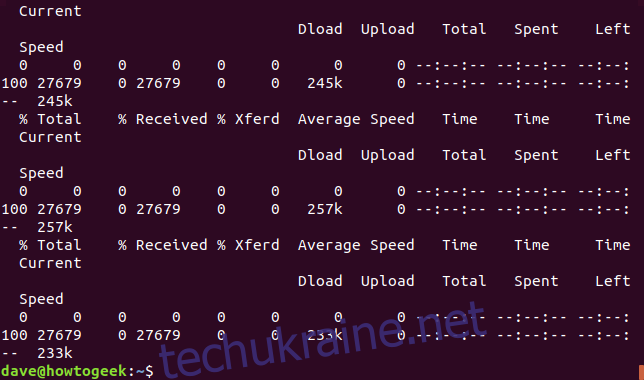
xargs -n 1 curl -O < urls-to-download.txt
Зверніть увагу, що ця команда використовує опцію -O (remote file), що дозволяє curl зберігати отриманий файл з тим самим ім’ям, що він має на віддаленому сервері.
Опція -n 1 вказує xargs обробляти кожен рядок текстового файлу як окремий параметр.
Після виконання цієї команди, ви побачите, як декілька завантажень розпочнуться і завершаться одне за одним.
В менеджері файлів ви побачите, що завантажено декілька файлів. Кожен з них має ім’я, яке він мав на віддаленому сервері.
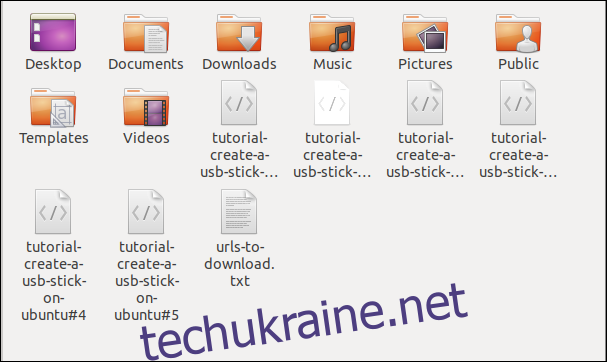
Завантаження файлів з FTP-сервера
Використовувати curl з протоколом FTP (File Transfer Protocol) дуже легко, навіть якщо потрібно пройти аутентифікацію з ім’ям користувача та паролем. Для передачі імені користувача та пароля скористайтеся опцією -u (user), ввівши ім’я користувача, двокрапку “:” та пароль. Не ставте пробіл перед або після двокрапки.
Розглянемо безкоштовний тестовий FTP-сервер, розміщений Rebex. Цей тестовий сайт має попередньо встановлене ім’я користувача “demo” та пароль “password”. Не використовуйте подібні слабкі імена користувачів та паролі на робочому або “реальному” FTP-сервері.
curl -u demo:password ftp://test.rebex.net

curl визначає, що ми вказали FTP-сервер, та повертає список файлів, які там знаходяться.

Єдиний файл на цьому сервері – це “readme.txt” розміром 403 байти. Завантажимо його. Використаємо ту саму команду з додаванням імені файлу:
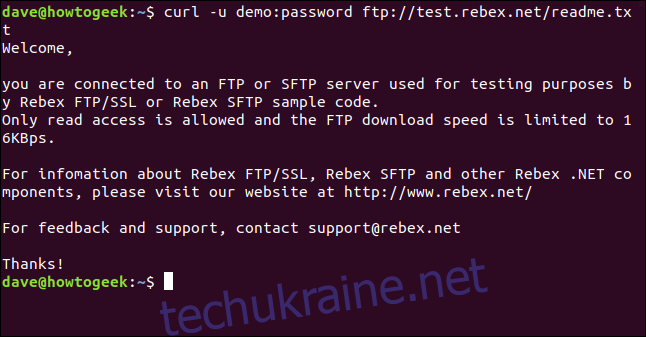
curl -u demo:password ftp://test.rebex.net/readme.txt

Файл буде завантажено, а curl відобразить його вміст у вікні терміналу.
У більшості випадків зручніше зберігати отриманий файл на диск, а не відображати у терміналі. Для цього скористаємося опцією -O (remote file), щоб зберегти файл на диску з тим самим ім’ям, що він має на віддаленому сервері.
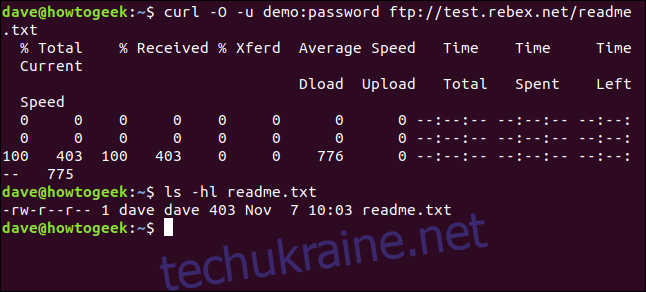
curl -O -u demo:password ftp://test.rebex.net/readme.txt

Файл буде завантажено та збережено на диск. Перевіримо деталі файлу командою ls. Він має те саме ім’я, що й файл на FTP-сервері, та той самий розмір – 403 байти.
ls -hl readme.txt
Надсилання параметрів на віддалені сервери
Деякі віддалені сервери приймають параметри в запитах, які їм надсилаються. Ці параметри можуть використовуватись, наприклад, для форматування повернених даних, або для вибору конкретних даних, які бажає отримати користувач. Часто, за допомогою curl можна взаємодіяти з інтерфейсами прикладного програмування (API).
Для прикладу, веб-сайт ipify надає API, що дозволяє визначити зовнішню IP-адресу.
curl https://api.ipify.org
Додавши параметр format зі значенням “json”, ми можемо знову запросити нашу зовнішню IP-адресу, але на цей раз дані будуть закодовані у форматі JSON.
curl https://api.ipify.org?format=json

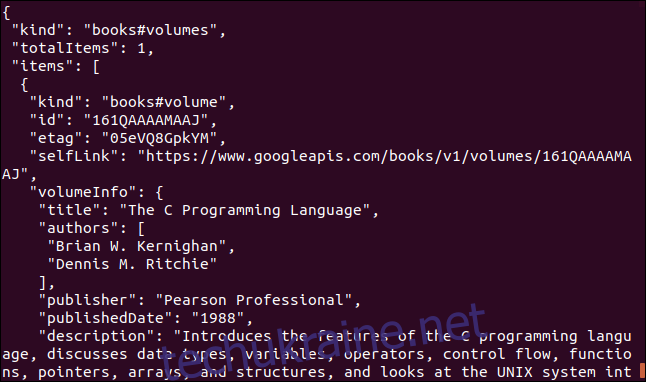
Ось ще один приклад, що використовує API Google. Він повертає об’єкт JSON, що описує книгу. Параметром, який потрібно вказати, є міжнародний стандартний номер книги (ISBN). Його можна знайти на задній обкладинці більшості книг, зазвичай під штрих-кодом. Використаємо параметр “0131103628”.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Отримані дані є дуже вичерпними:
Використовуємо curl або wget залежно від ситуації
Якщо потрібно завантажити контент з веб-сайту та рекурсивно дослідити його структуру, варто використовувати wget.
Якщо потрібно взаємодіяти з віддаленим сервером або API, можливо, завантажувати файли або веб-сторінки, краще скористатися curl. Особливо, якщо протокол не підтримується wget.