MLOps: Ключ до ефективної розробки моделей машинного навчання
Створення однієї моделі машинного навчання – завдання відносно нескладне. Проте, розробка сотень або тисяч моделей, а також відтворення вже існуючих, стає значно складнішим процесом.
У такому розмаїтті дій легко втратити контроль. Ця ситуація ускладнюється, коли над проектом працює команда, де необхідно відстежувати дії кожного учасника. Для впорядкування процесу необхідний узгоджений підхід, де кожен член команди дотримується встановлених процедур та документує свою роботу. Саме в цьому полягає суть MLOps.
Що таке MLOps?
Згідно з ml-ops.org, Machine Learning Operationalization (MLOps) – це підхід, спрямований на створення наскрізного процесу розробки машинного навчання. Цей процес охоплює проектування, створення та управління програмним забезпеченням на основі машинного навчання, яке є відтворюваним, тестованим та здатним до розвитку. По суті, MLOps – це застосування принципів DevOps до сфери машинного навчання.
Як і DevOps, MLOps робить акцент на автоматизації з метою зменшення ручних операцій та підвищення ефективності. Подібно до DevOps, MLOps включає безперервну інтеграцію (CI) та безперервну доставку (CD). Крім цих двох аспектів, MLOps також передбачає безперервне навчання (CT), яке полягає в перенавчанні моделей з використанням нових даних та їх подальшому перерозподілі.
Отже, MLOps – це інженерна культура, що сприяє систематичному підходу до розробки моделей машинного навчання та автоматизації різних етапів цього процесу. Цей процес зазвичай охоплює такі етапи, як вилучення даних, їх аналіз, підготовка, навчання моделі, оцінка, підтримка та моніторинг.
Переваги MLOps
Застосування принципів MLOps має переваги, схожі з перевагами використання стандартних операційних процедур. Основні переваги включають:
- Чітко визначений процес надає детальну карту всіх важливих кроків, необхідних для розробки моделі, що гарантує відсутність пропущених критичних етапів.
- Етапи процесу, які підлягають автоматизації, можуть бути ідентифіковані та автоматизовані. Це зменшує обсяг повторюваної роботи, прискорює розробку та мінімізує людські помилки.
- Оцінка прогресу розробки моделі стає простішою, оскільки завжди відомо, на якому етапі знаходиться проект.
- Комунікація між членами команди спрощується завдяки спільному розумінню необхідних кроків розробки.
- Процес може бути багаторазово застосований до розробки різних моделей, що забезпечує контроль над процесом.
Таким чином, головна роль MLOps полягає в забезпеченні методичного підходу до розробки моделей машинного навчання з максимальною автоматизацією процесу.
Платформи для побудови конвеєрів MLOps
Для впровадження MLOps існують різноманітні платформи, які допоможуть вам у створенні конвеєрів. Хоча конкретні функції цих платформ можуть відрізнятися, всі вони допомагають у таких аспектах:
- Зберігання моделей разом із метаданими (конфігурації, код, точність, експерименти) та версіями моделей для забезпечення контролю версій.
- Зберігання метаданих наборів даних, що використовуються для навчання моделей.
- Відстеження моделей у процесі експлуатації для виявлення проблем (наприклад, дрейф моделі).
- Розгортання моделей.
- Створення моделей за допомогою середовищ з низьким або нульовим кодом.
Давайте розглянемо деякі з провідних платформ MLOps:
MLFlow

MLFlow є однією з найпопулярніших платформ для управління життєвим циклом машинного навчання. Це безкоштовна платформа з відкритим вихідним кодом. Основні функції MLFlow:
- Відстеження експериментів з машинним навчанням (код, дані, конфігурації, результати).
- Упаковка коду у формат, придатний для відтворення.
- Розгортання моделей машинного навчання.
- Централізоване зберігання моделей.
MLFlow інтегрується з популярними бібліотеками машинного навчання (TensorFlow, PyTorch) та різними платформами (Apache Spark, H20.asi, Google Cloud, Amazon Sage Maker, Azure Machine Learning, Databricks), а також з хмарними постачальниками (AWS, Google Cloud, Microsoft Azure).
Машинне навчання Azure
Azure Machine Learning (AML) – це комплексна платформа машинного навчання, що охоплює всі етапи життєвого циклу моделі. Вона включає підготовку даних, створення, навчання, валідацію та розгортання моделей, а також управління та моніторинг розгортань.
AML дає змогу розробляти моделі за допомогою будь-якої IDE та фреймворка на вибір (PyTorch, TensorFlow). Інтеграція з ONNX Runtime та Deepspeed дозволяє оптимізувати навчання та висновки, підвищуючи продуктивність. Платформа використовує інфраструктуру штучного інтелекту Microsoft Azure з графічними процесорами NVIDIA та мережею Mellanox для створення кластерів машинного навчання.
AML також дозволяє створювати центральний реєстр для зберігання та обміну моделями і наборами даних. Інтеграція з Git та GitHub Actions забезпечує автоматизацію робочих процесів. AML підтримує гібридні та мультихмарні рішення, а також інтегрується з іншими службами Azure (Synapse Analytics, Data Lake, Databricks, Security Center).
Google Vertex AI

Google Vertex AI – це уніфікована платформа для даних та штучного інтелекту. Вона надає інструменти для створення індивідуальних та попередньо навчених моделей, а також служить наскрізним рішенням для впровадження MLOps. Інтеграція з BigQuery, Dataproc та Spark забезпечує легкий доступ до даних під час навчання.
Крім API, Google Vertex AI пропонує середовище розробки з низьким та нульовим кодом, що дозволяє використовувати його не лише розробникам, а й аналітикам та інженерам. API дозволяє інтегрувати платформу з існуючими системами. Google Vertex AI також дозволяє створювати генеративні програми штучного інтелекту за допомогою Generative AI Studio. Платформа спрощує розгортання інфраструктури та управління нею. Vertex AI підтримує всі етапи розробки моделей машинного навчання: від підготовки даних до моніторингу та управління моделями.
Databricks

Databricks – це платформа, що дозволяє готувати та обробляти дані, а також управляти всім життєвим циклом машинного навчання від експериментів до виробництва. Databricks надає керований MLFlow, включаючи реєстрацію версій моделей, відстеження експериментів, обслуговування моделей, реєстр моделей та моніторинг показників. Реєстр моделей забезпечує відтворюваність моделей, а реєстр допомагає відстежувати версії та етапи життєвого циклу моделей.
Розгортання моделей у Databricks виконується одним кліком, створюючи REST API для прогнозування. Databricks інтегрується з існуючими попередньо навченими генеративними та великими мовними моделями (зокрема, з бібліотеки transformers). Платформа надає спільні блокноти Databricks, що підтримують Python, R, SQL та Scala. Databricks також спрощує управління інфраструктурою, надаючи попередньо налаштовані кластери, оптимізовані для завдань машинного навчання.
AWS SageMaker
AWS SageMaker – це хмарна служба AWS, що надає інструменти для розробки, навчання та розгортання моделей машинного навчання. Основна мета SageMaker – автоматизація рутинних та повторюваних процесів, пов’язаних зі створенням моделей. SageMaker пропонує інструменти для створення виробничих конвеєрів для моделей машинного навчання з використанням різних сервісів AWS (Amazon EC2, Amazon S3).
SageMaker працює з блокнотами Jupyter, встановленими на екземплярі EC2, разом із усіма необхідними пакетами та бібліотеками. Дані можуть бути отримані з Amazon Simple Storage Service. Платформа надає реалізації поширених алгоритмів машинного навчання (лінійна регресія, класифікація зображень). SageMaker також має монітор моделей, що забезпечує автоматичне налаштування для пошуку оптимальних параметрів. Розгортання моделей спрощено, їх можна легко розгорнути на AWS як захищену HTTP кінцеву точку, що контролюється за допомогою CloudWatch.
DataRobot
DataRobot – це популярна платформа MLOps, що дозволяє керувати різними етапами життєвого циклу машинного навчання, від підготовки даних до експериментів, валідації та управління моделями. Платформа пропонує інструменти для автоматизації експериментів з різними джерелами даних, тестування тисяч моделей та оцінки найкращих для розгортання. DataRobot підтримує створення моделей для вирішення різноманітних завдань (часові ряди, обробка природної мови, комп’ютерний зір).
DataRobot дозволяє створювати моделі як за допомогою готових компонентів без написання коду, так і реалізовувати моделі за допомогою власного коду. Платформа надає блокноти для написання та редагування коду, а також API для розробки моделей в IDE на вибір. За допомогою графічного інтерфейсу можна відстежувати експерименти моделей.
Run AI

Run AI фокусується на вирішенні проблеми недостатнього використання інфраструктури штучного інтелекту, особливо графічних процесорів (GPU). Платформа забезпечує видимість всієї інфраструктури та гарантує її ефективне використання під час навчання. Run AI знаходиться між програмним забезпеченням MLOps та апаратним забезпеченням, виконуючи роль рівня абстракції для команд машинного навчання. Всі навчальні завдання виконуються через Run AI, а платформа планує їх виконання.
Run AI не накладає обмежень на тип апаратного забезпечення: хмарне (AWS, Google Cloud), локальне або гібридне рішення. Платформа функціонує як платформа віртуалізації GPU. Завдання можна запускати з Jupyter Notebook, bash-терміналу або віддалено з PyCharm.
H2O.ai
H2O.ai – це розподілена платформа машинного навчання з відкритим кодом. Вона дозволяє командам співпрацювати, створювати центральне сховище для моделей та експериментувати. Як платформа MLOps, H2O.ai надає ряд ключових функцій. Розгортання моделей спрощено, їх можна розгорнути як кінцеві точки REST. H2O.ai підтримує різні стратегії розгортання, зокрема A/B тестування, моделі Champoion-Challenger.
Платформа зберігає дані, артефакти, експерименти, моделі та розгортання, що дозволяє відтворювати моделі. H2O.ai також забезпечує управління дозволами на рівні групи та користувача. Під час роботи моделей, платформа забезпечує моніторинг дрейфу моделі та інших операційних показників у реальному часі.
Градієнт Paperspace
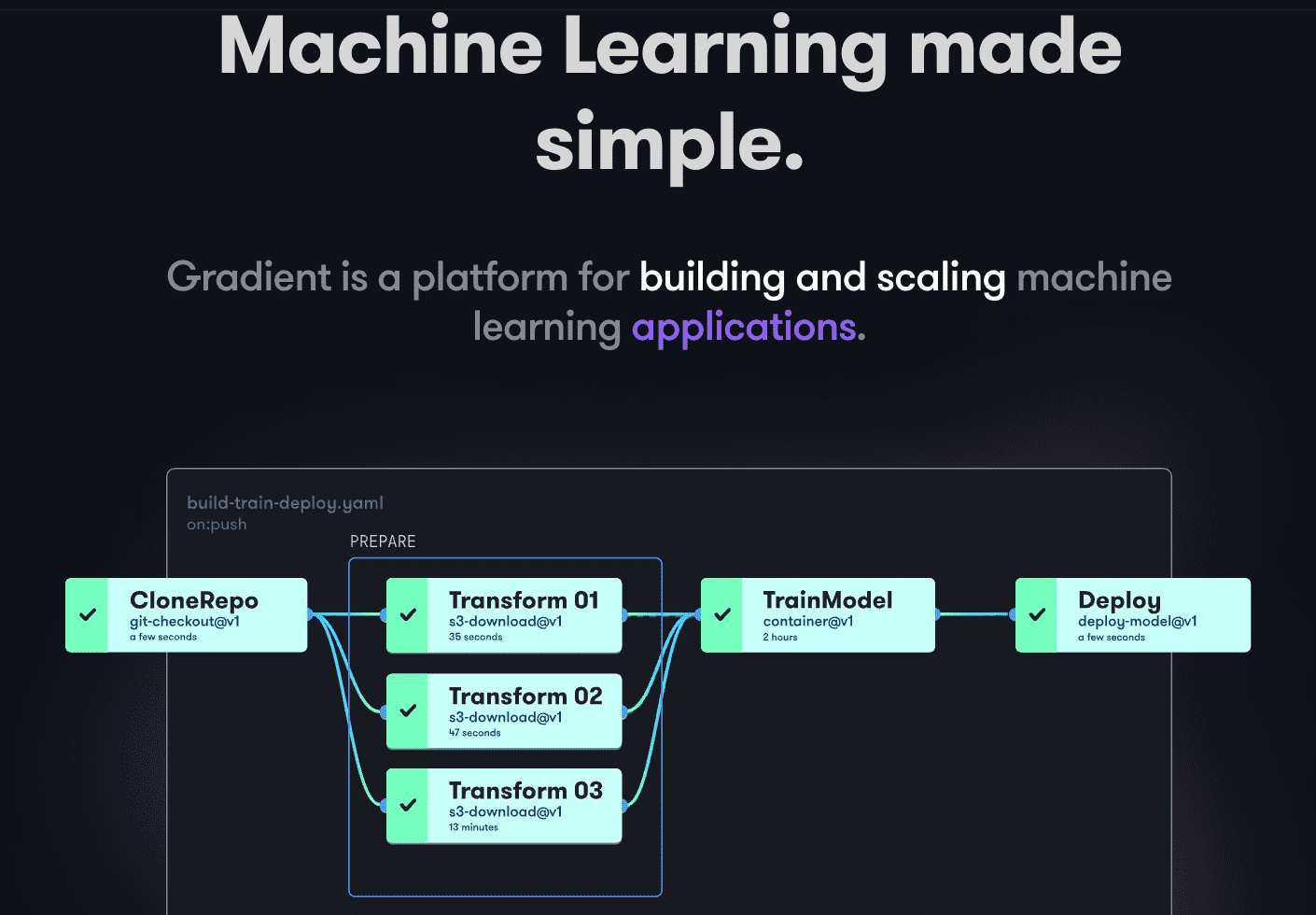
Gradient допомагає розробникам на всіх етапах розробки машинного навчання. Платформа надає блокноти Jupyter з відкритим кодом для розробки моделей та навчання в хмарі за допомогою потужних GPU. Це дозволяє швидко досліджувати та створювати прототипи моделей. Конвеєри розгортання можна автоматизувати, створюючи робочі процеси, описані в YAML. Використання робочих процесів робить створення, розгортання та обслуговування моделей простим та масштабованим.
Gradient надає контейнери, машини, дані, моделі, показники, журнали та секрети для управління різними етапами конвеєра розробки моделей. Конвеєри працюють на кластерах Gradiet, розташованих на Paperspace Cloud, AWS, GCP, Azure або інших серверах. Взаємодія з Gradient можлива через CLI або SDK програмно.
Заключні слова
MLOps – це потужний та універсальний підхід до створення, розгортання та управління моделями машинного навчання в масштабі. Простота використання, масштабованість та безпека роблять MLOps хорошим вибором для організацій будь-якого розміру.
У цій статті ми розглянули основні аспекти MLOps, їх важливість, а також огляд популярних платформ MLOps.
Далі ви можете ознайомитися з нашим порівнянням Dataricks та Snowflake.