

У цю епоху Інтернету існують терабайти та петабайти даних із експоненціальним зростанням. Але як ми споживаємо ці дані та перетворюємо їх на корисну інформацію для покращення доступності послуг?
Достовірні, нові та зрозумілі дані – це все, що потрібно компаніям для їх моделей виявлення знань.
З цієї причини компанії застосовують аналітику різними способами, щоб отримати якісні дані.
Але з чого все починається? Відповідь полягає в суперечці даних.
Давайте розпочнемо!
Що таке Data Wrangling?
Обробка даних — це очищення, структурування та перетворення необроблених даних у формати, які спрощують процеси аналізу даних. Сперечання даних часто передбачає роботу з брудними та складними наборами даних, які не готові для процесів конвеєра даних. Розбір даних переводить необроблені дані в уточнений стан або уточнені дані в оптимізований стан і рівень готовності до виробництва.
Деякі з відомих завдань у суперечці даних включають:
- Об’єднання кількох наборів даних в один великий набір для аналізу.
- Вивчення відсутніх/прогалин у даних.
- Видалення викидів або аномалій у наборах даних.
- Стандартизація входів.
Великі сховища даних, задіяні в процесах обробки даних, зазвичай не налаштовуються вручну, що вимагає автоматизованих методів підготовки даних для отримання більш точних і якісних даних.
Цілі боротьби з даними
Крім підготовки даних для аналізу як більшої мети, інші цілі включають:
- Створення дійсних і нових даних із заплутаних даних для прийняття рішень у бізнесі.
- Стандартизація необроблених даних у формати, які можуть приймати системи великих даних.
- Зменшення часу, витраченого аналітиками даних на створення моделей даних, шляхом представлення впорядкованих даних.
- Створення послідовності, повноти, зручності використання та безпеки для будь-якого набору даних, що споживається або зберігається в сховищі даних.
Загальні підходи до Data Wrangling
Відкриття
Перш ніж інженери з даних розпочнуть завдання підготовки даних, вони повинні зрозуміти, як вони зберігаються, розмір, які записи зберігаються, формати кодування та інші атрибути, що описують будь-який набір даних.
Структурування
Цей процес передбачає організацію даних у зручних для використання форматах. Необроблені набори даних можуть потребувати структуризації щодо вигляду стовпців, кількості рядків і налаштування інших атрибутів даних для спрощення аналізу.
прибирання
Структуровані набори даних потрібно позбутися внутрішніх помилок і всього, що може спотворити дані всередині. Таким чином, очищення передбачає видалення кількох записів клітинок із подібними даними, видалення порожніх клітинок і даних, що виходять за межі, стандартизацію вхідних даних, перейменування заплутаних атрибутів тощо.
Збагачення
Після того, як дані пройшли етапи структурування та очищення, необхідно оцінити корисність даних і доповнити їх значеннями з інших наборів даних, яких бракує, щоб забезпечити бажану якість даних.
Перевірка
Процес перевірки передбачає ітераційні аспекти програмування, які проливають світло на якість даних, послідовність, зручність використання та безпеку. Етап перевірки гарантує виконання всіх завдань трансформації та позначає набори даних як готові до етапів аналітики та моделювання.
Презентація
Після того, як усі етапи пройдено, суперечливі набори даних представляють/розповсюджують в організації для аналітики. Документація етапів підготовки та метадані, створені під час процесу суперечок, також надаються на цьому етапі.
Талант
Талант це уніфікована платформа керування даними, об’єднана в 3 структури даних для надання надійних і здорових даних. Talend представляє інтеграцію даних, застосування та інтеграцію, а також цілісність даних і управління. Обробка даних у Talend здійснюється за допомогою інструмента «вказати та клацнути» на базі браузера, який дозволяє групову, групову та оперативну підготовку даних – профілювання даних, очищення та документування.
Структура даних Talend обробляє кожен етап життєвого циклу даних, ретельно збалансовуючи доступність даних, зручність використання, безпеку та цілісність усіх бізнес-даних.
Чи хвилювалися ви коли-небудь про різноманітні джерела даних? Уніфікований підхід Talend забезпечує швидку інтеграцію даних з усіх ваших джерел даних (баз даних, хмарних сховищ і кінцевих точок API), дозволяючи трансформувати та зіставляти всі дані з плавною перевіркою якості.
Інтеграція даних у Talend можлива за допомогою інструментів самообслуговування, таких як конектори, які дозволяють розробникам автоматично отримувати дані з будь-якого джерела та відповідним чином класифікувати дані.
Особливості Talend
Універсальна інтеграція даних
Talend дозволяє компаніям отримувати будь-які типи даних із різноманітних джерел даних – хмарних або локальних середовищ.
гнучкий
Talend виходить за рамки постачальника чи платформи, створюючи канали даних із ваших інтегрованих даних. Щойно ви створите конвеєри даних із отриманих даних, Talend дозволить вам запускати конвеєри будь-де.
Якість даних
Завдяки можливостям машинного навчання, таким як дедуплікація даних, перевірка та стандартизація, Talend автоматично очищає отримані дані.
Підтримка інтеграції програм і API
Після того, як інструменти самообслуговування Talend нададуть значення вашим даним, ви зможете поділитися своїми даними через зручні API. Кінцеві точки Talend API можуть надавати ваші активи даних платформам SaaS, JSON, AVRO та B2B за допомогою розширених інструментів відображення та трансформації даних.
Р

Р це добре розроблена та ефективна мова програмування для аналізу дослідницьких даних для наукових і бізнес-додатків.
Створений як безкоштовне програмне забезпечення для статистичних обчислень і графіки, R є одночасно мовою та середовищем для обробки даних, моделювання та візуалізації. Середовище R надає набір програмних пакетів, тоді як мова R об’єднує серію статистичних, кластеризаційних, класифікаційних, аналізувальних і графічних методів, які допомагають маніпулювати даними.
Особливості Р
Багатий набір пакетів
Розробники даних мають понад 10 000 стандартизованих пакетів і розширень для вибору з Comprehensive R Archive Network (CRAN). Це спрощує суперечки та аналіз даних.
Надзвичайно потужний
Завдяки пакетам розподілених обчислень R може виконувати складні та прості маніпуляції (математичні та статистичні) з об’єктами та наборами даних за лічені секунди.
Кросплатформна підтримка
R не залежить від платформи, може працювати на багатьох операційних системах. Він також сумісний з іншими мовами програмування, які допомагають виконувати важкі обчислювальні завдання.
Вивчити R легко.
Trifacta

Trifacta це інтерактивне хмарне середовище для профілювання даних, які обробляються моделями машинного навчання та аналітики. Цей інструмент розробки даних спрямований на створення зрозумілих даних незалежно від того, наскільки заплутаними чи складними є набори даних. Користувачі можуть видаляти подвійні записи та заповнювати порожні клітинки в наборах даних за допомогою дедуплікації та перетворень лінійного перетворення.
Цей інструмент боротьби з даними враховує викиди та недійсні дані в будь-якому наборі даних. Лише клацніть і перетягніть дані, які є під рукою, ранжуються та інтелектуально трансформуються за допомогою пропозицій на основі машинного навчання для прискорення підготовки даних.
Перебір даних у Trifacta здійснюється за допомогою переконливих візуальних профілів, які можуть вмістити нетехнічний і технічний персонал. Завдяки візуалізованим та інтелектуальним трансформаціям Trifacta пишається своїм дизайном, який орієнтований на користувачів.
Незалежно від того, чи збираються дані з вітрин даних, сховищ даних або озер даних, користувачі захищені від складнощів підготовки даних.
Особливості Trifacta
Безпроблемна інтеграція з хмарою
Підтримує робочі навантаження підготовки в будь-якому хмарному або гібридному середовищі, щоб дозволити розробникам отримувати набори даних для суперечок незалежно від того, де вони живуть.
Методи стандартизації кількох даних
Trifacta wrangler має кілька механізмів для визначення шаблонів у даних і стандартизації результатів. Інженери обробки даних можуть вибрати стандартизацію за зразком, за функцією або комбінувати та поєднувати.
Простий робочий процес
Trifacta організовує роботи з підготовки даних у вигляді потоків. Потік містить один або кілька наборів даних і пов’язані з ними рецепти (визначені кроки, які перетворюють дані).
Таким чином, потік зменшує час, який розробники витрачають на імпорт, суперечку, профілювання та експорт даних.
OpenRefine
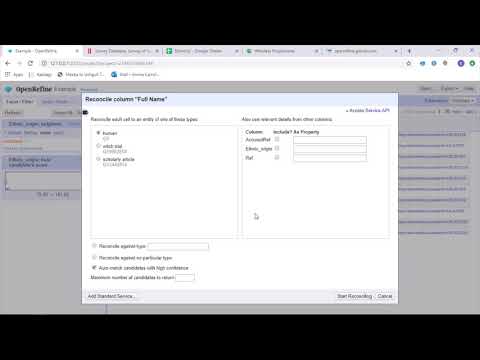
OpenRefine це зрілий інструмент із відкритим кодом для роботи з брудними даними. Як інструмент очищення даних OpenRefine досліджує набори даних за лічені секунди, одночасно застосовуючи складні перетворення клітинок для представлення бажаних форматів даних.
OpenRefine підходить до обробки даних через фільтри та розділи на наборах даних за допомогою регулярних виразів. Використовуючи вбудовану мову General Refine Expression Language, розробники даних можуть вивчати та переглядати дані за допомогою фасетів, фільтрів і методів сортування перед виконанням розширених операцій із даними для вилучення об’єктів.
OpenRefine дозволяє користувачам працювати над даними як проектами, де набори даних із багатьох комп’ютерних файлів, веб-URL-адрес і баз даних можна залучати до таких проектів із можливістю запуску локально на машинах користувачів.
За допомогою виразів розробники можуть розширити очищення та перетворення даних до таких завдань, як розділення/об’єднання багатозначних комірок, налаштування фасетів і отримання даних у стовпці за допомогою зовнішніх URL-адрес.
Особливості OpenRefine
Кросплатформний інструмент
OpenRefine створено для роботи з операційними системами Windows, Mac і Linux за допомогою завантажуваних інсталяторів.
Багатий набір API
Включає API OpenRefine, API розширення даних, API узгодження та інші API, які підтримують взаємодію користувачів із даними.
Datameer

Datameer — це інструмент перетворення даних SaaS, створений для спрощення обміну та інтеграції даних за допомогою процесів розробки програмного забезпечення. Datameer дозволяє видобувати, трансформувати та завантажувати набори даних у хмарні сховища даних, такі як Snowflake.
Цей інструмент обробки даних добре працює зі стандартними форматами наборів даних, такими як CSV і JSON, дозволяючи інженерам імпортувати дані в різних форматах для агрегації.
Datameer пропонує документування даних, як у каталозі, глибоке профілювання даних і виявлення для задоволення всіх потреб у перетворенні даних. Інструмент зберігає глибокий візуальний профіль даних, який дозволяє користувачам відстежувати недійсні, відсутні або несхожі поля та значення, а також загальну форму даних.
Працюючи в масштабованому сховищі даних, Datameer перетворює дані для значущої аналітики за допомогою ефективних стеків даних і функцій, схожих на Excel.
Datameer представляє гібридний користувальницький інтерфейс із використанням коду та без коду для роботи з широкими групами аналізу даних, які можуть легко створювати складні конвеєри ETL.
Особливості Datameer
Багатокористувацькі середовища
Містить середовища перетворення даних для кількох осіб – низький код, код і гібрид для підтримки технічно підкованих і нетехнічних людей.
Спільні робочі області
Datameer дозволяє командам повторно використовувати та співпрацювати над моделями для прискорення проектів.
Багата документація даних
Datameer підтримує як системну, так і створену користувачем документацію даних через метадані та описи, теги та коментарі у стилі вікі.
Заключні слова 👩🏫
Аналіз даних – це складний процес, який вимагає належної організації даних, щоб робити значущі висновки та робити прогнози. Інструменти Data Wrangling допомагають форматувати великі обсяги необроблених даних, щоб виконувати розширену аналітику. Виберіть найкращий інструмент, який відповідає вашим вимогам, і станьте професіоналом Analytics!
Вам може сподобатися:
Найкращі інструменти CSV для перетворення, форматування та перевірки.