Створення автоматизованих систем: перехід до безсерверної архітектури
Раніше, щоб створити автоматизовану систему, потрібно було налаштувати декілька серверів з визначеними параметрами процесора, пам’яті, сховища та іншими ресурсами. Це був процес, розрахований на багато років. Потім формувалася команда адміністраторів, яка займалася управлінням цими системами. Після цього до роботи приступала команда розробників, яка створювала інфраструктуру та розробляла процеси для з’єднання цих серверів.
Такий процес міг бути досить складним, оскільки в ньому брали участь різні групи людей, які працювали разом для досягнення спільної мети. Це часто призводило до конфліктів інтересів, що ускладнювало роботу.
Крім того, цей процес був досить дорогим. Потрібно було утримувати штат адміністраторів, а сервери, навіть якщо вони не використовувалися, споживали ресурси. Для забезпечення оптимальної продуктивності з часом потрібне рішення для автоматичного масштабування, яке б автоматично регулювало ресурси сервера.
Хмарні платформи пропонують альтернативу: вони дозволяють створювати наскрізну архітектуру без необхідності налаштування кластера серверів. З точки зору адміністрування, тут немає нічого, що потрібно підтримувати.
Це економічно вигідний варіант для стартапів і проектів на стадії MVP (мінімально життєздатного продукту). Це гарний вибір, якщо важко передбачити майбутнє навантаження та активність користувачів, а визначення оптимальної конфігурації кластера серверів є складним завданням.
Ключовою особливістю безсерверної архітектури є автоматизація процесів за допомогою безсерверних хмарних служб. Вона об’єднує служби і надає результати, аналогічні тим, що отримують від традиційних кластерних серверів.
Нижче розглянемо приклад створення такої архітектури, використовуючи лише власні сервіси AWS.
Вибір безсерверного потоку служб
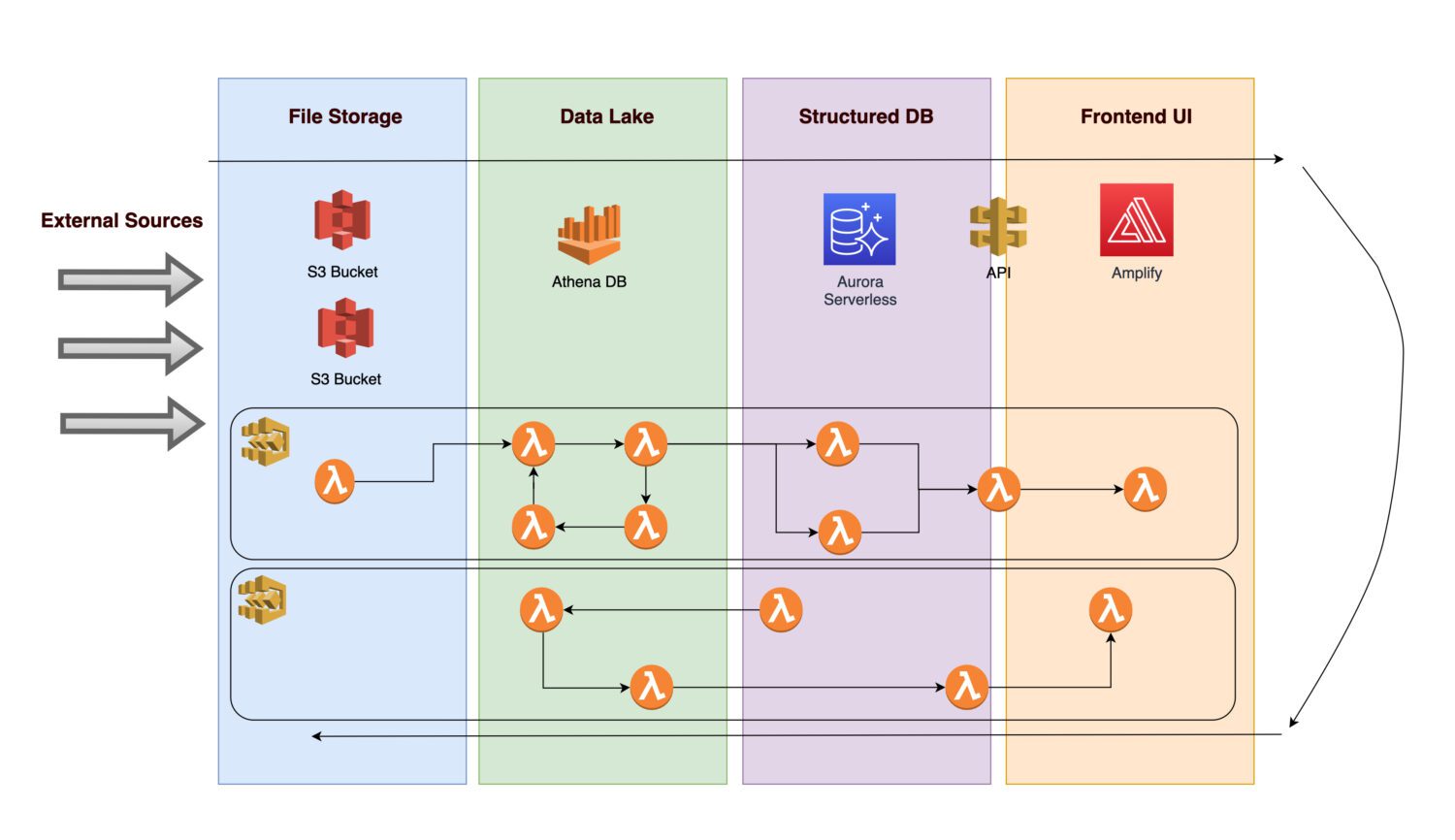
Уявімо, що ви хочете створити платформу для збору різноманітних даних та зображень інфраструктури певних об’єктів (наприклад, виробничих або комунальних).
- Для проведення майбутнього аналізу важливо, щоб вхідні дані спочатку були прийняті.
- Після застосування бізнес-правил, серверна процедура зберігає обчислені результати як нормалізовану інформацію в реляційній базі даних.
- Інтерфейс програми відображає нормалізовані дані, дозволяючи користувачам переглядати результати.
Давайте подивимось, які компоненти може включати така архітектура.
Відра AWS S3
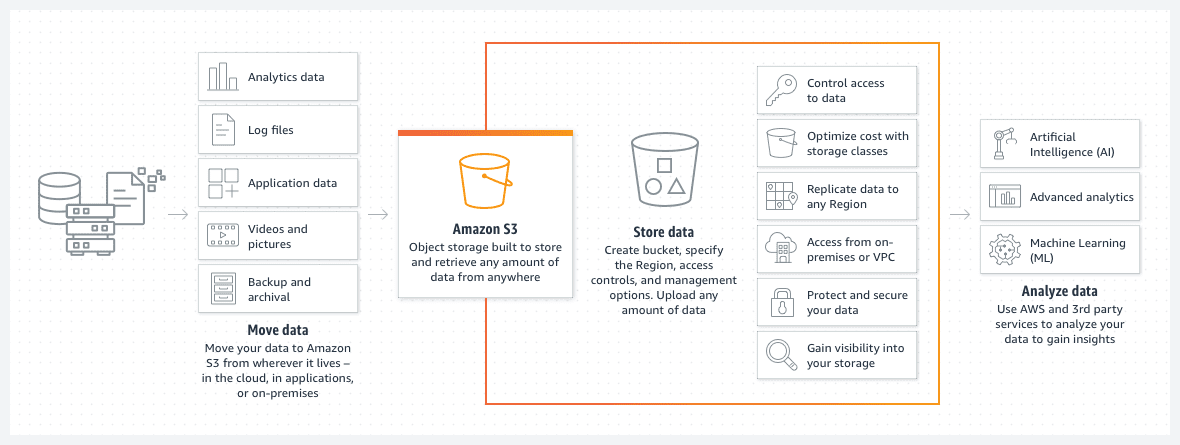
Відра Amazon S3 – це зручний спосіб зберігання файлів та зображень у хмарі AWS. Зберігання даних у S3 є економічно вигідним. Крім того, впровадження політики життєвого циклу відра S3 дозволяє ще більше знизити витрати.
Ця політика автоматично переміщує старі файли до різних класів сегментів S3, таких як архів або глибокий доступ до архіву. Ці класи відрізняються швидкістю доступу, але для старих даних це не є проблемою. Такий підхід корисний для доступу до архівних даних у разі термінової потреби, а не для стандартних операційних процесів.
- Можна впорядковувати дані у вкладених папках.
- Необхідно встановлювати відповідні обмеження дозволів.
- Додавайте теги до сегментів для їхньої легкої ідентифікації та використання в динамічних політиках пакетів S3.
- Відро є безсерверним за своєю суттю – це просто місце для зберігання ваших даних.
Відро S3 за своєю конструкцією є безсерверним, це просто сховище для даних.
База даних AWS Athena
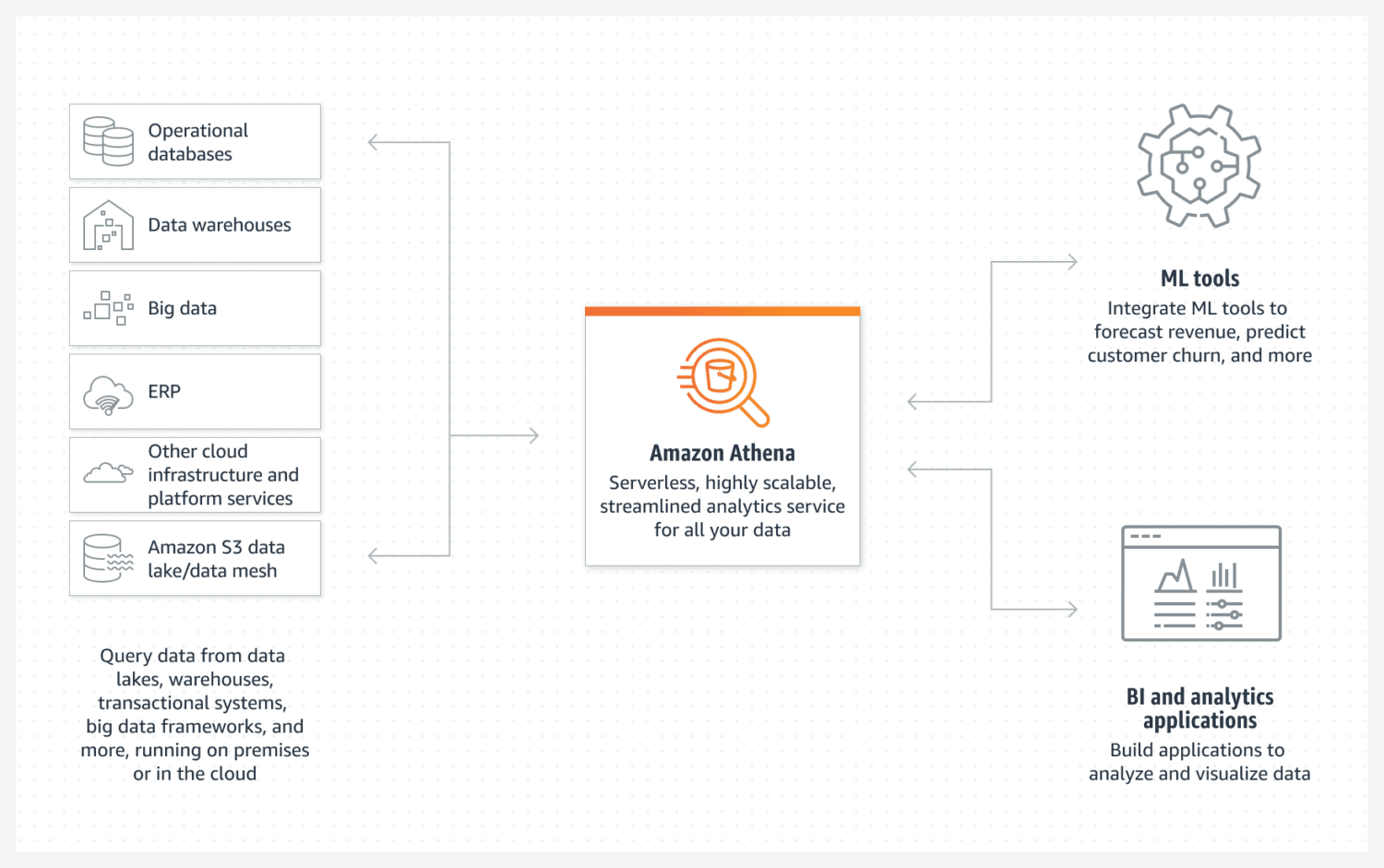
Athena дозволяє створити просте озеро даних AWS. Це безсерверна база даних, яка використовує відро S3 для зберігання своїх даних. Дані організовуються у структурованих форматах, таких як CSV. Відро S3 містить файли, а Athena звертається до них при кожному запиті даних з бази.
Слід пам’ятати, що Athena не підтримує деякі стандартні функції, такі як оператори оновлення. Тому Athena слід розглядати як дуже простий варіант бази даних.
Однак, вона підтримує індексування та розділення. Athena легко масштабується горизонтально, додавання нових сегментів не є складним процесом. Для простого, але функціонального створення озера даних цього може бути достатньо в більшості випадків.
Для досягнення високої продуктивності важливо обрати найкращу структуру даних, враховуючи майбутнє використання. Потрібно чітко визначити спосіб вибору даних. Повторне створення таблиць пізніше, коли вони вже заповнені великою кількістю інформації, є складним завданням.
Athena DB є відмінним вибором для створення простого та незмінного пулу даних, який легко масштабувати горизонтально з часом.
База даних AWS Aurora
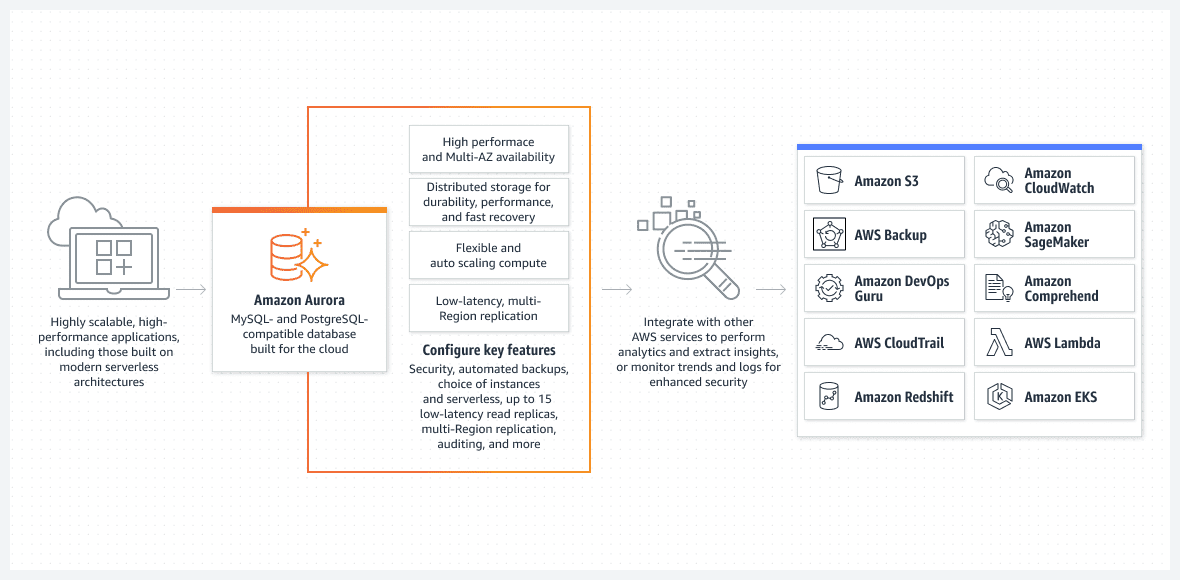
Athena DB чудово підходить для зберігання необроблених даних. Однак надання вибіркових результатів у зовнішню програму може бути повільним.
Одним з найкращих варіантів є база даних Aurora, яка може працювати в безсерверному режимі. Це є просте рішення з точки зору встановлення та налаштування.
Aurora – це одне з найсучасніших власних рішень реляційної бази даних в AWS. Вона постійно вдосконалюється з кожним оновленням.
Aurora унікальна тим, що може працювати в безсерверному режимі, що виділяє її серед інших реляційних служб. Ось як працює цей режим:
- Для налаштування кластера Aurora використовуйте консоль AWS. Потрібно буде вказати стандартні рівні процесора та оперативної пам’яті, а також максимальний інтервал автоматичного масштабування. Це вплине на продуктивність, яку кластер Aurora може динамічно додавати або видаляти. На основі поточного використання бази даних AWS вирішує збільшити або зменшити масштаб.
- Кластер Aurora не запускається, поки користувач або процес не ініціює справжній запит. Наприклад, при початку запланованої пакетної обробки або коли програма виконує внутрішній виклик API для отримання даних з бази. База даних автоматично відкриється та залишатиметься активною протягом певного часу після завершення процесів запиту.
- Кластер Aurora автоматично вимикається, якщо база даних не обробляє жодного запиту.
Безсерверна Aurora DB працює лише тоді, коли їй потрібно виконувати реальну роботу. Кластер, що був запущений, знову вимикається, якщо немає активності. Ви платите лише за реальну роботу, а не за простій.
Безсерверна Aurora повністю керується AWS і не потребує адміністрування.
AWS Amplify
Amplify пропонує безсерверну платформу для швидкого розгортання інтерфейсних програм, створених за допомогою бібліотек JavaScript і React. Немає потреби налаштовувати сервери. Використовуйте консоль AWS для безпосереднього розгортання коду або застосовуйте автоматизований конвеєр DevOps.
Ви можете викликати серверні API для доступу до даних, що зберігаються в базах даних. Ці виклики дозволяють отримати фактичні дані у зовнішній програмі. Основну оптимізацію продуктивності на сервері повинна виконувати команда розробників. Якщо створити ефективні запити, то можна ще більше зменшити ймовірність повільної відповіді в інтерфейсі користувача.
Покрокові функції AWS
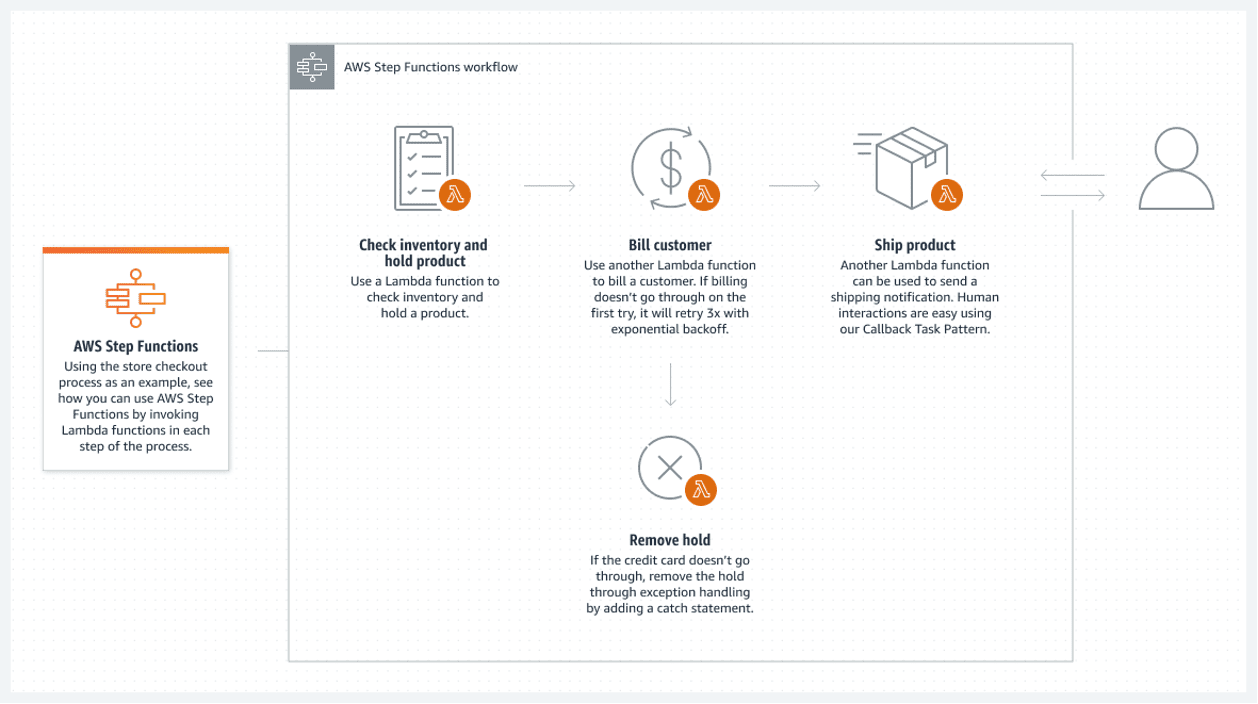
Навіть якщо всі основні компоненти системи є безсерверними, це не гарантує повної безсерверної архітектури. Це можливо, лише якщо всі пакетні процеси між компонентами також будуть безсерверними.
Функції AWS Step пропонують найкраще рішення в хмарі AWS. Зв’язаний список функцій AWS Lambda складає функцію кроку. Ці функції створюють блок-схему, яка має чіткі початковий та кінцевий стани. Lambda-функція, зазвичай написана на Python або Node.js, є кодом, який обробляє необхідні дії.
Ось приклад виконання функції кроку:
- AWS запускає автоматичну функцію Lambda щоразу, коли в папку S3 додається новий файл. Після аналізу файлу Lambda завантажує його в Athena. Lambda зберігає результати у форматі CSV у сегменті S3 (або в таблиці відстеження бази даних) перед завершенням.
- Потім цей результат використовується наступною Lambda для виконання подальших кроків. Це може включати виклик моделі машинного навчання та перетворення частини нових даних у нормалізовані таблиці. Останнім кроком може бути завантаження даних до бази даних Aurora.
- Функція кроку зв’язує ці Lambda-вирази разом, щоб створити пакетний потік. Можливо навіть запустити іншу функцію кроку замість кроку у іншій кореневій функції кроку. Це дозволяє охопити багато сценаріїв.
Цей безсерверний потік має один суттєвий недолік: кожна Lambda-функція може працювати максимум 15 хвилин. Розбиття потоку на менші Lambda-функції може допомогти вирішити цю проблему.
Можна викликати кілька Lambda-функцій одночасно на одному кроці. Це означає паралелізацію кроку з декількома Lambda-функціями, що виконуються одночасно. Слід дочекатися завершення всієї паралельної обробки, перш ніж перейти до наступної Lambda-обробки.
Заключні слова
Безсерверна архітектура пропонує унікальну можливість створити хмарну платформу, яка охоплює всю систему. Така платформа є горизонтально масштабованою та має низькі експлуатаційні витрати.
Це ідеальне рішення для проектів з обмеженим бюджетом, особливо на етапі дослідження, коли невідомі реальні обсяги виробництва. Команди проекту можуть отримати загальне уявлення про роботу системи без будь-яких компромісів.
Таке рішення підходить не для всіх випадків, особливо тих, що пов’язані з високим використанням процесора. Проте хмара AWS постійно розвивається в напрямку безсерверних технологій. Завжди доцільно провести ретельне дослідження, перш ніж приймати рішення про безсерверний варіант для вашого наступного хмарного проекту AWS.
Далі ви можете ознайомитися з найкращими безсерверними базами даних для сучасних програм.