
Статистика Forbes стверджує, що до 90% світових організацій використовують аналітику великих даних для створення своїх інвестиційних звітів.
Зі зростанням популярності Big Data, як наслідок, спостерігається сплеск можливостей працевлаштування в Hadoop більше, ніж раніше.
Тому, щоб допомогти вам отримати роль експерта Hadoop, ви можете скористатися цими запитаннями та відповідями на співбесіді, які ми зібрали для вас у цій статті, щоб допомогти вам пройти співбесіду.
Можливо, знання таких фактів, як діапазон зарплати, які роблять посади в Hadoop і Big Data прибутковими, спонукає вас пройти цю співбесіду, чи не так? 🤔
- За даними indeed.com, американський розробник Big Data Hadoop отримує середню зарплату 144 000 доларів.
- За даними itjobswatch.co.uk, середня зарплата розробника Big Data Hadoop становить £66 750.
- Джерело indeed.com стверджує, що в Індії вони отримували б середню зарплату ₹ 16 00 000.
Прибутково, вам не здається? А тепер приступимо до вивчення Hadoop.
Що таке Hadoop?
Hadoop — це популярна платформа, написана мовою Java, яка використовує моделі програмування для обробки, зберігання та аналізу великих наборів даних.
За замовчуванням його дизайн дозволяє масштабувати від одного сервера до кількох машин, які пропонують локальні обчислення та зберігання. Крім того, його здатність виявляти та обробляти збої прикладного рівня, що призводить до високодоступних служб, робить Hadoop досить надійним.
Давайте відразу перейдемо до поширених питань співбесіди Hadoop і правильних відповідей на них.
Запитання та відповіді на інтерв’ю Hadoop
Що таке одиниця зберігання в Hadoop?
Відповідь: Блок зберігання даних Hadoop називається розподіленою файловою системою Hadoop (HDFS).
Чим мережеве сховище відрізняється від розподіленої файлової системи Hadoop?
Відповідь: HDFS, яка є основним сховищем Hadoop, є розподіленою файловою системою, яка зберігає великі файли за допомогою стандартного обладнання. З іншого боку, NAS — це сервер зберігання комп’ютерних даних на рівні файлів, який забезпечує різнорідним групам клієнтів доступ до даних.
У той час як зберігання даних у NAS здійснюється на спеціальному обладнанні, HDFS розподіляє блоки даних між усіма машинами в кластері Hadoop.
NAS використовує пристрої зберігання високого класу, що є досить дорогим, тоді як стандартне обладнання, яке використовується в HDFS, є економічно ефективним.
NAS окремо зберігає дані обчислень, тому не підходить для MapReduce. Навпаки, дизайн HDFS дозволяє працювати з фреймворком MapReduce. Обчислення переходять до даних у структурі MapReduce замість даних до обчислень.
Поясніть MapReduce у Hadoop і Shuffling
Відповідь: MapReduce відноситься до двох різних завдань, які виконують програми Hadoop, щоб забезпечити широку масштабованість на сотнях і тисячах серверів у кластері Hadoop. Перетасування, з іншого боку, передає вихідні дані карти від Mappers до необхідного Reducer у MapReduce.
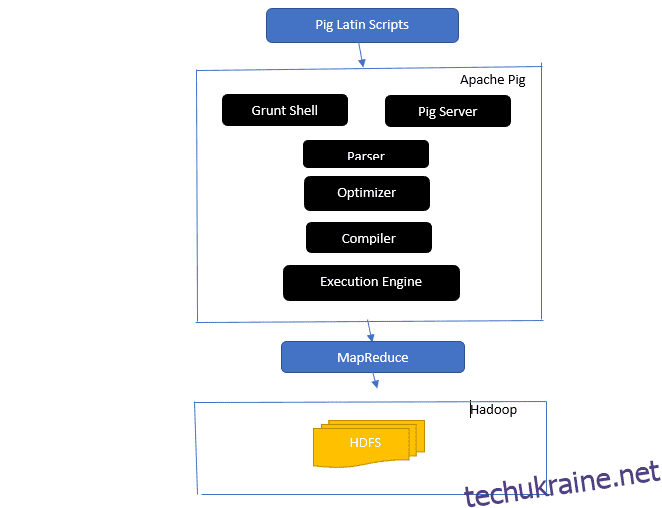
Погляньте на архітектуру Apache Pig
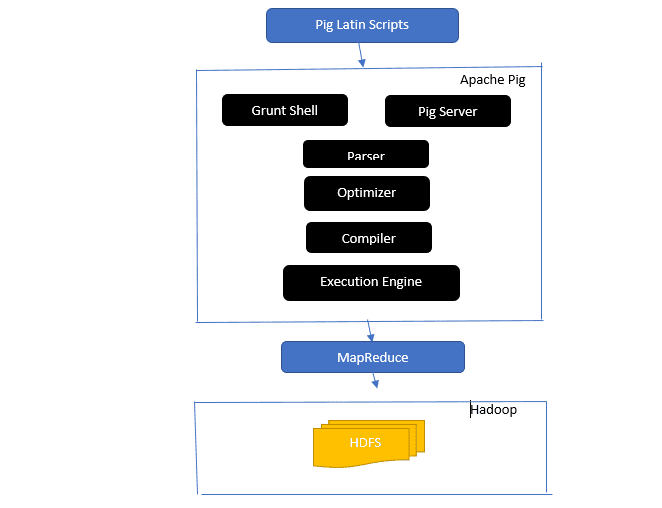 Архітектура Apache Pig
Архітектура Apache Pig
Відповідь: Архітектура Apache Pig має інтерпретатор Pig Latin, який обробляє та аналізує великі набори даних за допомогою сценаріїв Pig Latin.
Apache pig також складається з наборів наборів даних, над якими виконуються такі операції, як об’єднання, завантаження, фільтрування, сортування та групування.
Мова Pig Latin використовує такі механізми виконання, як оболонки Grant, UDF і вбудовані для написання сценаріїв Pig, які виконують необхідні завдання.
Pig полегшує роботу програмістів, перетворюючи ці написані сценарії в серію завдань Map-Reduce.
Компоненти архітектури Apache Pig включають:
- Парсер – обробляє сценарії Pig, перевіряючи синтаксис сценарію та виконуючи перевірку типу. Вихід синтаксичного аналізатора представляє оператори та логічні оператори Pig Latin і називається DAG (спрямований ациклічний граф).
- Оптимізатор – оптимізатор реалізує логічні оптимізації, такі як проекція та натискання на DAG.
- Компілятор – компілює оптимізований логічний план із оптимізатора в серію завдань MapReduce.
- Механізм виконання – тут відбувається остаточне виконання завдань MapReduce у потрібний результат.
- Режим виконання – Режими виконання в Apache pig в основному включають локальний і Map Reduce.
Відповідь: Служба Metastore у Local Metastore працює в тій самій JVM, що й Hive, але підключається до бази даних, що працює в окремому процесі на тій самій або віддаленій машині. З іншого боку, Metastore у Remote Metastore працює у своїй JVM окремо від JVM служби Hive.
Що таке п’ять V великих даних?
Відповідь: ці п’ять V позначають основні характеристики Big Data. Вони включають:
- Цінність: Великі дані прагнуть забезпечити значні вигоди від високої рентабельності інвестицій (ROI) для організації, яка використовує великі дані у своїх операціях з даними. Великі дані приносять цю цінність завдяки своєму глибокому розумінню та розпізнаванню шаблонів, що, серед інших переваг, сприяє зміцненню зв’язків із клієнтами та більш ефективній роботі.
- Різноманітність: це означає неоднорідність типів зібраних даних. Різні формати включають CSV, відео, аудіо тощо.
- Обсяг: це визначає значний обсяг і розмір даних, якими керує та аналізує організація. Ці дані демонструють експоненціальне зростання.
- Швидкість: це експоненціальна швидкість зростання даних.
- Правдивість: правдивість означає, наскільки «невизначеними» або «неточними» дані є через те, що вони неповні або суперечливі.
Поясніть різні типи даних Pig Latin.
Відповідь: Типи даних у Pig Latin включають атомарні типи даних і складні типи даних.
Типи даних Atomic є основними типами даних, які використовуються в усіх інших мовах. Вони включають наступне:
- Int – цей тип даних визначає 32-розрядне ціле число зі знаком. Приклад: 13
- Довгий – Довгий визначає 64-розрядне ціле число. Приклад: 10 л
- Float – визначає 32-розрядне число з плаваючою точкою зі знаком. Приклад: 2,5F
- Подвійний – визначає 64-розрядне число з плаваючою комою зі знаком. Приклад: 23.4
- Логічне значення – визначає логічне значення. Він включає: True/False
- Дата й час – визначає значення дати й часу. Приклад: 1980-01-01T00:00.00.000+00:00
Складні типи даних включають:
- Карта – карта відноситься до набору пари ключ-значення. приклад: [‘color’#’yellow’, ‘number’#3]
- Сумка – це колекція набору кортежів із використанням символу “{}”. Приклад: {(Генрі, 32), (Кіті, 47)}
- Кортеж – кортеж визначає впорядкований набір полів. Приклад : (Вік, 33)
Що таке Apache Oozie і Apache ZooKeeper?
Відповідь: Apache Oozie — це планувальник Hadoop, який відповідає за планування та об’єднання завдань Hadoop у єдину логічну роботу.
Apache Zookeeper, з іншого боку, координує роботу з різними службами в розподіленому середовищі. Це економить час розробників, просто відкриваючи прості служби, такі як синхронізація, групування, обслуговування конфігурації та іменування. Apache Zookeeper також надає готову підтримку для черги та виборів лідера.
Яка роль об’єднувача, RecordReader і Partitioner в операції MapReduce?
Відповідь: суматор діє як міні-редуктор. Він отримує та обробляє дані із завдань карти, а потім передає вихідні дані до фази редуктора.
RecordHeader зв’язується з InputSplit і перетворює дані в пари ключ-значення для відповідного читання картографом.
Розділювач відповідає за визначення кількості скорочених завдань, необхідних для підсумовування даних, і підтвердження того, як вихідні дані об’єднувача надсилаються до редюсера. Partitioner також керує розділенням ключів проміжних виходів карти.
Згадайте різні дистрибутиви Hadoop для окремих постачальників.
Відповідь: різні постачальники, які розширюють можливості Hadoop, включають:
- Відкрита платформа IBM.
- Cloudera CDH Hadoop Distribution
- Розповсюдження MapR Hadoop
- Amazon Elastic MapReduce
- Платформа даних Hortonworks (HDP)
- Ключовий пакет великих даних
- Datastax Enterprise Analytics
- HDInsight від Microsoft Azure – хмарне розповсюдження Hadoop.
Чому HDFS є відмовостійким?
Відповідь: HDFS реплікує дані на різних DataNodes, що робить його відмовостійким. Зберігання даних у різних вузлах дозволяє отримувати дані з інших вузлів у разі збою в одному режимі.
Розрізняйте федерацію та високу доступність.
Відповідь: Федерація HDFS пропонує відмовостійкість, яка дозволяє безперервний потік даних в одному вузлі, коли інший виходить з ладу. З іншого боку, висока доступність потребує двох окремих машин, які окремо налаштовують активний NameNode і вторинний NameNode на першій і другій машинах.
Федерація може мати необмежену кількість непов’язаних вузлів імен, тоді як у режимі високої доступності доступні лише два пов’язані вузли імен, активний і резервний, які працюють постійно.
NameNodes в об’єднанні спільно використовують пул метаданих, причому кожен NameNode має свій виділений пул. Однак у High Availability активні NameNodes запускаються кожен по одному, тоді як резервні NameNodes залишаються бездіяльними та лише час від часу оновлюють свої метадані.
Як дізнатися стан блоків і справність файлової системи?
Відповідь: Ви використовуєте команду hdfs fsck / як на рівні користувача root, так і в окремому каталозі, щоб перевірити стан справності файлової системи HDFS.
Використовується команда HDFS fsck:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Опис команди:
- -files: надрукувати файли, які ви перевіряєте.
- –locations: друкує розташування всіх блоків під час перевірки.
Команда перевірки стану блоків:
hdfs fsck <path> -files -blocks
- <шлях>: починається перевірка з переданого тут шляху.
- – блоки: друкує блоки файлів під час перевірки
Коли ви використовуєте команди rmadmin-refreshNodes і dfsadmin-refreshNodes?
Відповідь: Ці дві команди корисні для оновлення інформації про вузол під час введення в експлуатацію або після завершення введення в експлуатацію вузла.
Команда dfsadmin-refreshNodes запускає клієнт HDFS і оновлює конфігурацію вузла NameNode. З іншого боку, команда rmadmin-refreshNodes виконує адміністративні завдання ResourceManager.
Що таке контрольно-пропускний пункт?
Відповідь: контрольна точка — це операція, яка об’єднує останні зміни файлової системи з останнім FSImage, щоб файли журналу редагування залишалися достатньо малими для прискорення процесу запуску NameNode. Контрольна точка виникає у Secondary NameNode.
Чому ми використовуємо HDFS для програм із великими наборами даних?
Відповідь: HDFS забезпечує архітектуру DataNode і NameNode, яка реалізує розподілену файлову систему.
Ці дві архітектури забезпечують високопродуктивний доступ до даних через високомасштабовані кластери Hadoop. Його NameNode зберігає метадані файлової системи в оперативній пам’яті, що призводить до того, що обсяг пам’яті обмежує кількість файлів файлової системи HDFS.
Що робить команда ‘jps’?
Відповідь: команда Java Virtual Machine Process Status (JPS) перевіряє, чи запущені певні демони Hadoop, зокрема NodeManager, DataNode, NameNode і ResourceManager, чи ні. Ця команда потрібна для запуску з кореня, щоб перевірити робочі вузли на хості.
Що таке «спекулятивне виконання» в Hadoop?
Відповідь: це процес, у якому головний вузол у Hadoop замість того, щоб виправляти виявлені повільні завдання, запускає інший екземпляр того самого завдання як резервне завдання (спекулятивне завдання) на іншому вузлі. Спекулятивне виконання економить багато часу, особливо в умовах інтенсивного робочого навантаження.
Назвіть три режими, в яких може працювати Hadoop.
Відповідь: Три основні вузли, на яких працює Hadoop, включають:
- Автономний вузол — це режим за замовчуванням, який запускає служби Hadoop за допомогою локальної файлової системи та одного процесу Java.
- Псевдорозподілений вузол виконує всі служби Hadoop за допомогою єдиного розгортання Hadoop.
- Повністю розподілений вузол запускає головні та підлеглі служби Hadoop за допомогою окремих вузлів.
Що таке UDF?
Відповідь: UDF (функції, визначені користувачем) дозволяє кодувати власні функції, які можна використовувати для обробки значень стовпців під час запиту Impala.
Що таке DistCp?
Відповідь: Коротше кажучи, DistCp або Distributed Copy — це корисний інструмент для великого між- або внутрішньокластерного копіювання даних. Використовуючи MapReduce, DistCp ефективно реалізує розподілене копіювання великої кількості даних, серед інших завдань, таких як обробка помилок, відновлення та звітування.
Відповідь: Метасховище Hive — це служба, яка зберігає метадані Apache Hive для таблиць Hive у реляційній базі даних, наприклад MySQL. Він надає API служби metastore, який надає центовий доступ до метаданих.
Визначте RDD.
Відповідь: RDD, що означає Resilient Distributed Datasets, — це структура даних Spark і незмінна розподілена колекція ваших елементів даних, яка виконує обчислення на різних вузлах кластера.
Як рідні бібліотеки можна включити до завдань YARN?
Відповідь: Ви можете реалізувати це за допомогою -Djava.library. шлях у команді або шляхом встановлення LD+LIBRARY_PATH у файлі .bashrc у такому форматі:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Поясніть «WAL» у HBase.
Відповідь: Write Ahead Log (WAL) — це протокол відновлення, який записує зміни даних MemStore у HBase у файлове сховище. WAL відновлює ці дані у разі збою RegionalServer або перед очищенням MemStore.
Чи є YARN заміною Hadoop MapReduce?
Відповідь: Ні, YARN не є заміною Hadoop MapReduce. Натомість потужна технологія під назвою Hadoop 2.0 або MapReduce 2 підтримує MapReduce.
Яка різниця між ORDER BY і SORT BY у HIVE?
Відповідь: хоча обидві команди отримують дані впорядковано в Hive, результати від використання SORT BY можуть бути впорядковані лише частково.
Крім того, для SORT BY потрібен редуктор для впорядкування рядків. Цих редукторів, необхідних для кінцевого виходу, також може бути кілька. У цьому випадку кінцевий вихід може бути частково впорядкованим.
З іншого боку, ORDER BY вимагає лише одного редуктора для загального порядку виведення. Ви також можете використовувати ключове слово LIMIT, яке зменшує загальний час сортування.
Яка різниця між Spark і Hadoop?
Відповідь: Хоча і Hadoop, і Spark є розподіленими платформами обробки, їх ключовою відмінністю є їхня обробка. Там, де Hadoop ефективний для пакетної обробки, Spark ефективний для обробки даних у реальному часі.
Крім того, Hadoop переважно читає та записує файли в HDFS, тоді як Spark використовує концепцію Resilient Distributed Dataset для обробки даних в оперативній пам’яті.
Виходячи з їх затримки, Hadoop — це обчислювальна структура з високою затримкою без інтерактивного режиму обробки даних, тоді як Spark — це обчислювальна структура з низькою затримкою, яка обробляє дані в інтерактивному режимі.
Порівняйте Sqoop і Flume.
Відповідь: Sqoop і Flume — це інструменти Hadoop, які збирають дані, зібрані з різних джерел, і завантажують дані в HDFS.
- Sqoop (SQL-to-Hadoop) витягує структуровані дані з баз даних, включаючи Teradata, MySQL, Oracle тощо, тоді як Flume корисний для вилучення неструктурованих даних із джерел бази даних і завантаження їх у HDFS.
- З точки зору керованих подій, Flume керується подіями, тоді як Sqoop не керується подіями.
- Sqoop використовує архітектуру на основі конекторів, де конектори знають, як підключитися до іншого джерела даних. Flume використовує агентну архітектуру, де написаний код є агентом, відповідальним за отримання даних.
- Завдяки розподіленій природі Flume він може легко збирати та агрегувати дані. Sqoop корисний для паралельної передачі даних, у результаті чого вихідні дані зберігаються у кількох файлах.
Поясніть BloomMapFile.
Відповідь: BloomMapFile — це клас, що розширює клас MapFile і використовує динамічні фільтри розквіту, які забезпечують швидку перевірку членства для ключів.
Перелічіть різницю між HiveQL і PigLatin.
Відповідь: Хоча HiveQL є декларативною мовою, подібною до SQL, PigLatin є високорівневою процедурною мовою потоку даних.
Що таке очищення даних?
Відповідь: Очищення даних — це важливий процес усунення або виправлення виявлених помилок даних, зокрема неправильних, неповних, пошкоджених, дублікатів і неправильно відформатованих даних у наборі даних.
Цей процес спрямований на покращення якості даних і надання більш точної, послідовної та надійної інформації, необхідної для ефективного прийняття рішень в організації.
Висновок💃
У зв’язку з поточним різким зростанням можливостей роботи в Big data та Hadoop, ви можете підвищити свої шанси потрапити. Запитання та відповіді на співбесіді з Hadoop у цій статті допоможуть вам успішно пройти майбутню співбесіду.
Далі ви можете переглянути хороші ресурси, щоб дізнатися про великі дані та Hadoop.
Удачі! 👍