
Дані стають дедалі важливішими для побудови моделей машинного навчання, тестування додатків і отримання ділових ідей.
Однак для відповідності численним нормам щодо даних їх часто приховують і суворо захищають. Доступ до таких даних може зайняти місяці, щоб отримати необхідні підписи. Крім того, підприємства можуть використовувати синтетичні дані.
Що таке синтетичні дані?
Фото: Twinify
Синтетичні дані – це штучно створені дані, які статистично нагадують старий набір даних. Його можна використовувати з реальними даними для підтримки та вдосконалення моделей штучного інтелекту або взагалі використовувати як заміну.
Оскільки вони не належать жодному суб’єкту даних і не містять інформації, що ідентифікує особу, або конфіденційних даних, таких як номери соціального страхування, їх можна використовувати як альтернативу захисту конфіденційності реальним виробничим даним.
Відмінності між реальними та синтетичними даними
- Найважливіша різниця полягає в тому, як генеруються ці два типи даних. Реальні дані надходять від реальних суб’єктів, чиї дані були зібрані під час опитувань або під час використання вашої програми. З іншого боку, синтетичні дані генеруються штучно, але все ще нагадують вихідний набір даних.
- Друга відмінність полягає в правилах захисту даних, що стосуються реальних і синтетичних даних. Маючи реальні дані, суб’єкти повинні мати можливість знати, які дані про них збираються та чому вони збираються, а також існують обмеження щодо того, як їх можна використовувати. Однак ці правила більше не застосовуються до синтетичних даних, оскільки дані не можуть бути пов’язані з суб’єктом і не містять особистої інформації.
- Третя відмінність полягає в кількості доступних даних. З реальними даними ви можете мати лише стільки, скільки вам надають користувачі. З іншого боку, ви можете генерувати скільки завгодно синтетичних даних.
Чому вам слід розглянути можливість використання синтетичних даних
- Це відносно дешевше у виробництві, тому що ви можете створити набагато більші набори даних, схожі на менший набір даних, який у вас уже є. Це означає, що ваші моделі машинного навчання матимуть більше даних для навчання.
- Згенеровані дані автоматично позначаються та очищаються для вас. Це означає, що вам не доведеться витрачати час на виконання трудомісткої роботи з підготовки даних для машинного навчання чи аналітики.
- Проблем із конфіденційністю немає, оскільки дані не ідентифікують особу та не належать суб’єкту даних. Це означає, що ви можете використовувати його та вільно ним ділитися.
- Ви можете подолати упередження ШІ, переконавшись, що класи меншин добре представлені. Це допоможе вам створити чесний і відповідальний ШІ.
Як генерувати синтетичні дані
Хоча процес генерації залежить від того, який інструмент ви використовуєте, зазвичай процес починається з підключення генератора до наявного набору даних. Після цього ви визначаєте особисті поля у своєму наборі даних і позначаєте їх для виключення або обфускації.
Потім генератор починає ідентифікувати типи даних решти стовпців і статистичні шаблони в цих стовпцях. Відтоді ви можете генерувати стільки синтетичних даних, скільки вам потрібно.
Зазвичай ви можете порівняти згенеровані дані з вихідним набором даних, щоб побачити, наскільки синтетичні дані схожі на реальні.
Тепер ми дослідимо інструменти для генерації синтетичних даних для навчання моделей машинного навчання.
Переважно ШІ

Переважно ШІ має генератор синтетичних даних на основі штучного інтелекту, який вивчає статистичні шаблони вихідного набору даних. Потім ШІ створює вигаданих персонажів, які відповідають вивченим шаблонам.
За допомогою Mostly AI ви можете створювати цілі бази даних із посилальною цілісністю. Ви можете синтезувати всі види даних, щоб допомогти вам створити кращі моделі ШІ.
Synthesized.io

Synthesized.io використовується провідними компаніями для своїх ініціатив ШІ. Щоб використовувати synthesize.io, ви вказуєте вимоги до даних у файлі конфігурації YAML.
Потім ви створюєте завдання та запускаєте його як частину конвеєра даних. Він також має дуже щедрий безкоштовний рівень, який дозволяє експериментувати та перевіряти, чи відповідає він вашим потребам у даних.
YData

За допомогою YData ви можете генерувати табличні, часові ряди, транзакції, багатотабличні та реляційні дані. Це дозволяє уникнути проблем, пов’язаних зі збором, обміном і якістю даних.
Він постачається з AI та SDK для взаємодії з їхньою платформою. Крім того, у них є щедрий безкоштовний рівень, який ви можете використовувати для демонстрації продукту.
Гретель А.І

Gretel AI пропонує API для створення необмеженої кількості синтетичних даних. Gretel має генератор даних з відкритим кодом, який ви можете встановити та використовувати.
Крім того, ви можете використовувати їхній REST API або CLI, що буде коштувати. Однак їх ціна розумна і залежить від розміру бізнесу.
Копули
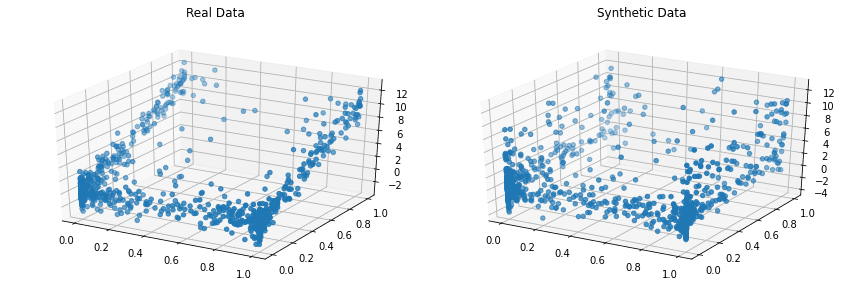
Copulas — це бібліотека Python з відкритим вихідним кодом для моделювання багатовимірних розподілів за допомогою функцій копули та генерування синтетичних даних, які відповідають тим самим статистичним властивостям.
Проект стартував у 2018 році в MIT в рамках проекту Synthetic Data Vault.
CTGAN
CTGAN складається з генераторів, які можуть навчатися з однотабличних реальних даних і генерувати синтетичні дані з ідентифікованих шаблонів.
Він реалізований як бібліотека Python з відкритим кодом. CTGAN разом із Copulas є частиною проекту Synthetic Data Vault.
DoppelGANger
DoppelGANger — це реалізація Generative Adversarial Networks із відкритим вихідним кодом для створення синтетичних даних.
DoppelGANger корисний для створення даних часових рядів і використовується такими компаніями, як Gretel AI. Бібліотека Python доступна безкоштовно та є відкритою.
Синт

Synth — це генератор даних із відкритим кодом, який допомагає створювати реалістичні дані відповідно до ваших вимог, приховувати особисту інформацію та розробляти тестові дані для ваших програм.
Ви можете використовувати Synth для створення рядів у реальному часі та реляційних даних для потреб машинного навчання. Synth також не залежить від баз даних, тому ви можете використовувати його з базами даних SQL і NoSQL.
SDV.dev
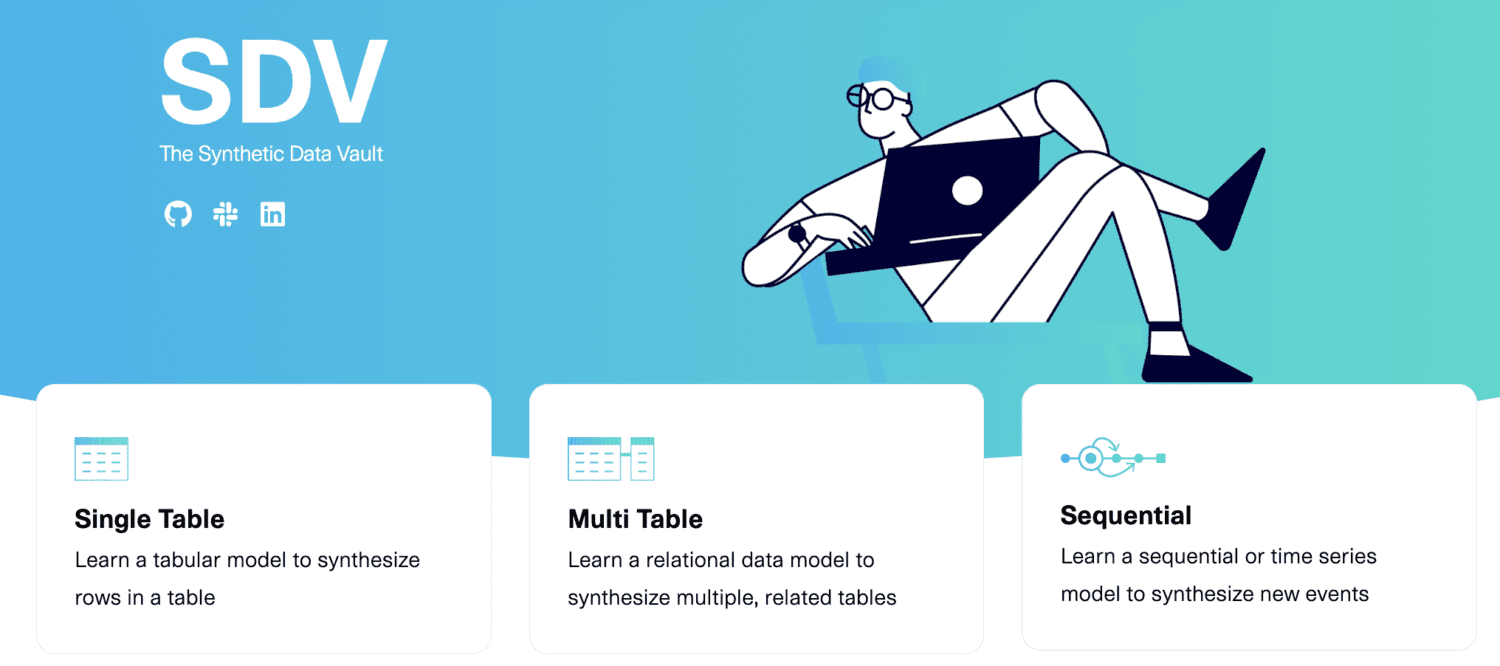
SDV означає Synthetic Data Vault. SDV.dev — це програмний проект, який розпочався в MIT у 2016 році та створив різні інструменти для генерації синтетичних даних.
Ці інструменти включають Copulas, CTGAN, DeepEcho та RDT. Ці інструменти реалізовано як бібліотеки Python з відкритим кодом, якими ви можете легко користуватися.
Тофу
Tofu — це бібліотека Python з відкритим кодом для створення синтетичних даних на основі даних біобанку Великобританії. На відміну від згаданих раніше інструментів, які допоможуть вам генерувати будь-які дані на основі наявного набору даних, Tofu генерує дані, схожі лише на дані біобанку.
UK Biobank — це дослідження фенотипічних і генотипічних характеристик 500 000 дорослих людей середнього віку з Великобританії.
Twinify
Twinify — це програмний пакет, який використовується як бібліотека або інструмент командного рядка для подвоєння конфіденційних даних шляхом створення синтетичних даних з ідентичним статистичним розподілом.

Щоб використовувати Twinify, ви надаєте реальні дані у вигляді файлу CSV, і він вивчає дані для створення моделі, яку можна використовувати для створення синтетичних даних. Його можна використовувати абсолютно безкоштовно.
Datanamic
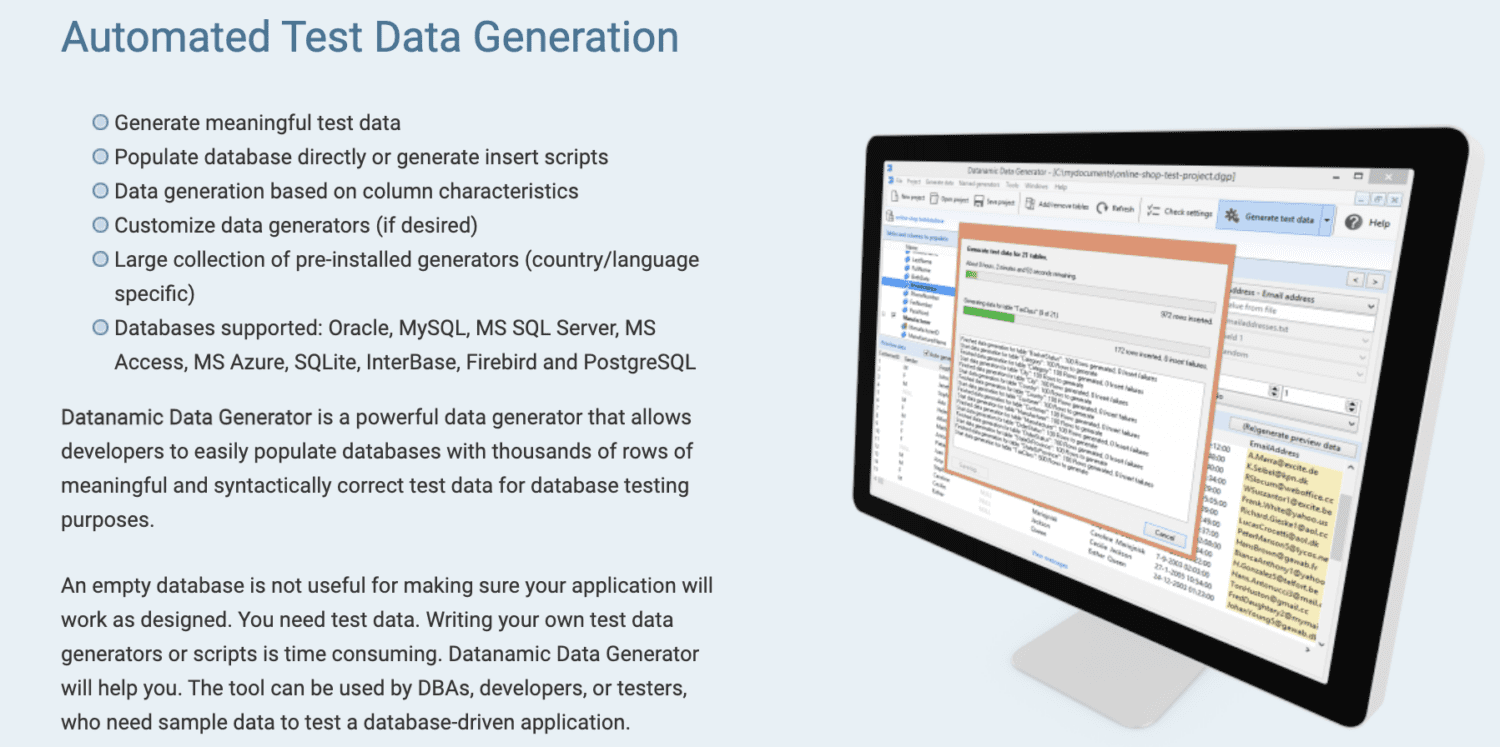
Datanamic допомагає створювати тестові дані для додатків, керованих даними та машинного навчання. Він генерує дані на основі таких характеристик стовпців, як електронна адреса, ім’я та номер телефону.
Генератори даних Datanamic можна налаштувати та підтримують більшість баз даних, таких як Oracle, MySQL, MySQL Server, MS Access і Postgres. Він підтримує та забезпечує посилальну цілісність у створених даних.
Бенератор
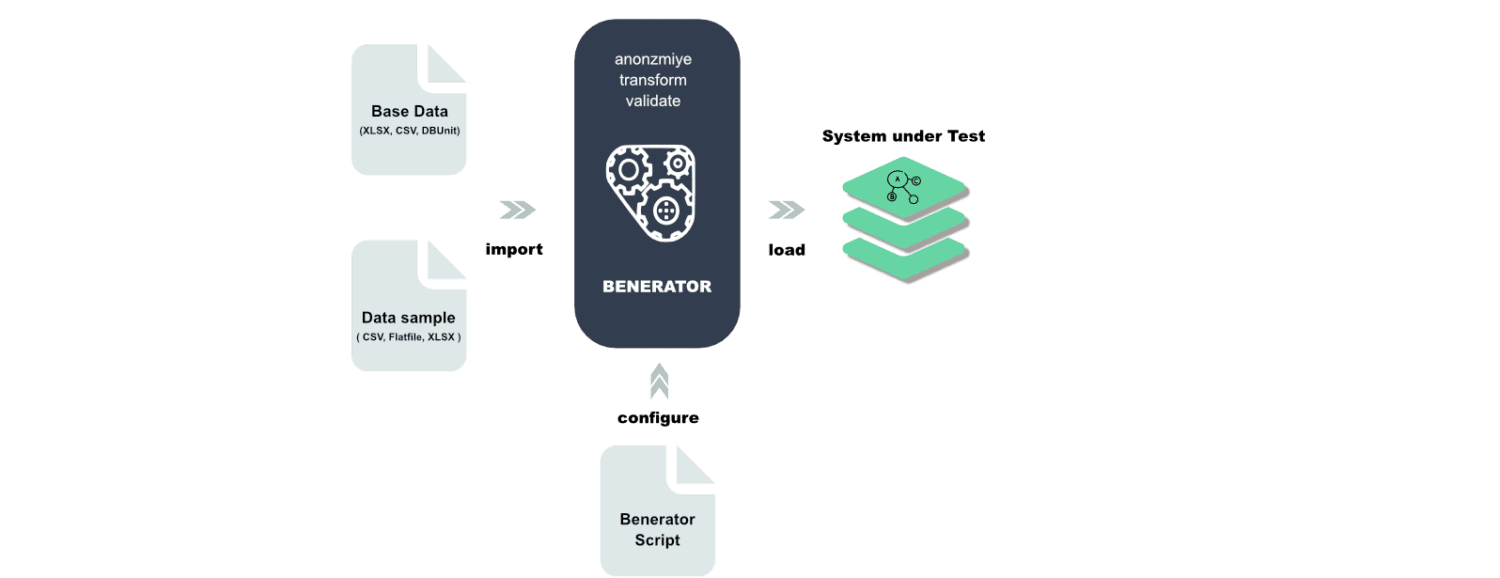
Benerator — це програмне забезпечення для обфускації, генерації та міграції даних з метою тестування та навчання. Використовуючи Benerator, ви описуєте дані за допомогою XML (розширювана мова розмітки) і генеруєте їх за допомогою інструмента командного рядка.
Він призначений для використання не розробниками, і з ним ви можете генерувати мільярди рядків даних. Benerator є безкоштовним і має відкритий код.
Заключні слова
За оцінками Gartner, до 2030 року для машинного навчання використовуватиметься більше синтетичних даних, ніж реальних.
Неважко зрозуміти чому, враховуючи вартість і проблеми конфіденційності використання реальних даних. Тому необхідно, щоб підприємства дізналися про синтетичні дані та різні інструменти, які допоможуть їм у їх створенні.
Далі ознайомтеся зі синтетичними інструментами моніторингу для вашого онлайн-бізнесу.