Сучасні Платформи для Обробки Потокових Даних у Реальному Часі
Світ, у якому ми функціонуємо, активно використовує інформацію. Можливість отримувати аналітичні відомості з актуальних даних в режимі реального часу є значною перевагою для будь-якого бізнесу. Технології потокової передачі даних дозволяють постійно збирати та обробляти інформацію з різних джерел, тому надійні платформи для цього є надзвичайно важливими.
Платформи потокового передавання даних являють собою масштабовані, розподілені та високопродуктивні системи, які забезпечують надійну обробку інформаційних потоків. Вони надають інструменти для агрегації та аналізу даних, а також часто включають зручні інформаційні панелі для візуалізації отриманих результатів.
На ринку представлений широкий вибір рішень для потокової передачі даних – від повністю керованих, таких як Confluent Cloud і Amazon Kinesis, до рішень з відкритим кодом, таких як Arroyo та Fluvio.
Області Застосування Потокової Передачі Даних
Платформи для обробки потокових даних мають широкий спектр застосувань. Розглянемо деякі з них:
- Виявлення шахрайства за допомогою безперервного аналізу транзакцій, поведінки користувачів та виявлення закономірностей.
- Обробка даних фондового ринку, де високошвидкісні системи здійснюють велику кількість угод на основі миттєвого аналізу ринкових даних.
- Аналіз користувацької статистики у реальному часі допомагає ринкам електронної комерції знаходити потрібну аудиторію для своїх товарів.
- Збір даних з мільйонів датчиків, які надають інформацію в режимі реального часу для прогнозних систем, наприклад, для прогнозування погоди.
Нижче представлені провідні платформи для аналізу та обробки даних у реальному часі.
Confluent Cloud

Confluent Cloud – це повністю керована хмарна пропозиція Apache Kafka, що забезпечує стабільність, масштабованість і високу продуктивність. Платформа використовує спеціально розроблений двигун Kora, що дозволяє досягти в 10 разів кращої продуктивності у порівнянні з самостійним розгортанням кластера Kafka. Вона має такі ключові характеристики:
- Безсерверні кластери забезпечують масштабованість та гнучкість. Завдяки автоматичному масштабуванню можна миттєво задовольнити вимоги до потокової передачі даних.
- Необмежене зберігання даних гарантує їх цілісність, дозволяючи Confluent Cloud бути вашим єдиним джерелом достовірної інформації.
- Confluent Cloud забезпечує високу надійність роботи (SLA) на рівні 99,99%, що є одним з найкращих показників у галузі. Разом з багатозонною реплікацією, це гарантує захист від втрати або пошкодження даних.
Stream Designer пропонує зручний інтерфейс для візуального створення конвеєрів обробки даних. За допомогою попередньо вбудованих конекторів Kafka можна підключитися до будь-якого додатку або джерела даних.
Confluent Cloud також надає Stream Governance – унікальну комплексну систему управління даними. Захист даних та контроль доступу гарантується завдяки хмарній безпеці корпоративного рівня та відповідності нормативним вимогам.
Confluent Cloud пропонує різні варіанти ціноутворення. Також є велика кількість ресурсів для ознайомлення з платформою.
Aiven

Aiven дозволяє керувати потоковими даними за допомогою повністю керованого хмарного сервісу Apache Kafka. Він підтримує усіх основних провайдерів хмарних послуг, включаючи AWS, Google Cloud, Microsoft Azure, Digital Ocean та UpCloud.
Налаштування власного сервісу Kafka можна здійснити менш ніж за 10 хвилин через веб-консоль або програмно, за допомогою API та CLI. Крім того, є можливість запускати сервіс у контейнерах.
З Aiven ви можете забути про клопоти, пов’язані з управлінням Kafka. Легко налаштуйте канал даних та отримайте доступ до інформаційної панелі. Переваги Aiven:
- Автоматичні оновлення кластера та керування версіями та обслуговуванням лише кількома кліками миші.
- Aiven гарантує 99,99% безвідмовної роботи та майже нульові простої.
- Можливість збільшити об’єм пам’яті за вимогою, додати нові вузли Kafka або розгорнути сервіс у різних регіонах.
Ціни на місячну підписку Aiven починаються від $200, залежно від вашого розташування та обраного хмарного провайдера.
Arroyo
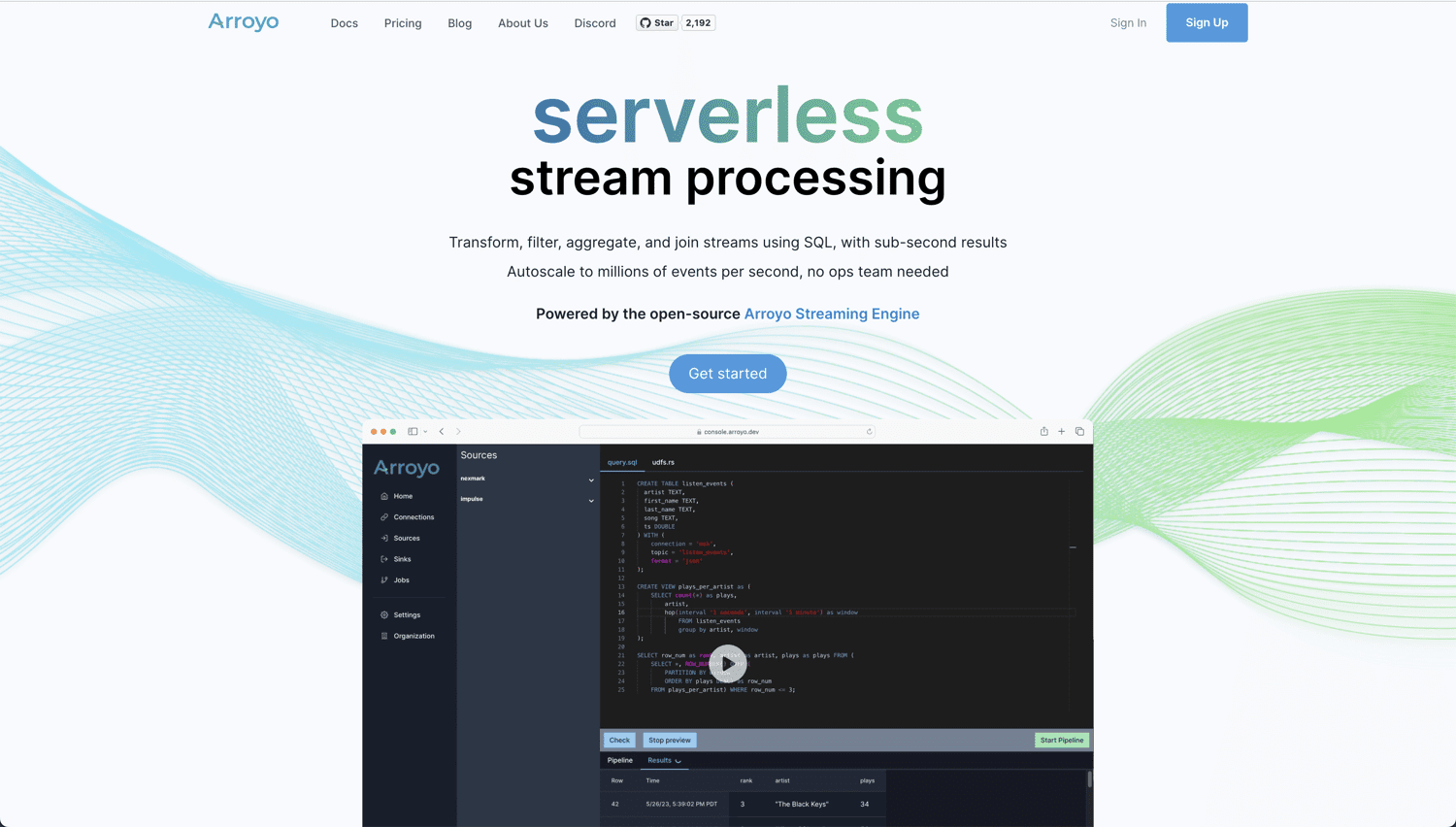
Якщо ви шукаєте справжнє хмарне рішення з відкритим кодом для аналізу та обробки даних у реальному часі, то Arroyo – чудовий вибір. Платформа працює на базі Arroyo Streaming Engine, рішення для обробки розподілених потоків, яке забезпечує результати в реальному часі з мінімальними затримками.
Arroyo розроблено таким чином, щоб зробити обробку даних в реальному часі настільки ж простою, як і пакетну обробку. Зручний інтерфейс не вимагає від користувача експертних знань. Можливості Arroyo:
- Вбудована підтримка різних конекторів, включаючи Kafka, Pulsar, Redpanda, WebSockets і Server Sent Events.
- Збереження результатів обробки в різних системах, таких як Kafka, Amazon S3 і Postgres.
- Сучасний, ефективний і високопродуктивний компілятор, який перетворює SQL-запити для максимальної ефективності.
- Горизонтальне масштабування потоку даних для підтримки мільйонів подій за секунду.
Ви можете запустити безкоштовний екземпляр Arroyo на власному хостингу або скористатися Arroyo Cloud, вартість якого починається від $200 на місяць. Arroyo наразі перебуває на стадії альфа-версії, тому деякі функції можуть бути відсутні.
Amazon Kinesis

Amazon Kinesis Data Streams дозволяє збирати та обробляти великі потоки даних для швидкого та безперервного прийому. Він характеризується високою масштабованістю, надійністю та низькою вартістю. Основні можливості:
- Amazon Kinesis працює в хмарі AWS у безсерверному режимі за вимогою. Запустити потоки даних Kinesis можна кількома кліками в консолі управління AWS.
- Можливість запуску Kinesis максимум у 3 зонах доступності (AZ). Зберігання даних до 365 днів.
- Kinesis Data Streams дозволяє підключати до 20 споживачів, кожен з яких має виділену пропускну здатність читання. Публікація даних відбувається протягом 70 мілісекунд після прийому.
- Захист даних за допомогою шифрування на стороні сервера.
- Легка інтеграція з іншими службами AWS, такими як Cloudwatch, DynamoDB та AWS Lambda.
В Amazon Kinesis оплата відбувається за фактичне використання. Наприклад, при обробці 1000 записів на секунду по 3 КБ кожен, щоденна вартість за використання “на вимогу” становитиме близько $30,61. Для розрахунку вартості виходячи з вашого використання, скористайтеся Калькулятором AWS.
Databricks

Якщо вам потрібна єдина платформа для пакетної та потокової обробки даних, то Databricks Lakehouse Platform є чудовим вибором. Ця платформа також підтримує аналітику в реальному часі, машинне навчання та створення додатків.
Databricks Lakehouse Platform має власне представлення даних під назвою Delta Live Tables (DLT) з наступними перевагами:
- DLT дозволяє легко визначити наскрізний конвеєр даних.
- Автоматизоване тестування якості даних з можливістю відстежувати тенденції якості з часом.
- Покращене автомасштабування DLT дозволяє впоратися з непередбачуваними навантаженнями.
Платформа Databricks Lakehouse використовує Spark Structured Streaming як основну технологію. Вона також включає Delta Lake, єдину платформу зберігання з відкритим кодом, яка підтримує як потокові, так і пакетні дані.
Databricks Lakehouse Platform пропонує 14-денну безкоштовну пробну версію, після чого ви автоматично підписуєтесь на план, яким користувались.
Qlik Data Streaming (CDC)

CDC (Change Data Capture) – це техніка, за допомогою якої повідомлення про будь-які зміни в даних передаються іншим системам. Qlik Data Streaming (CDC) – це просте та універсальне рішення, яке дозволяє легко переміщувати дані від джерела до місця призначення в реальному часі. Все керується через простий графічний інтерфейс.
Qlik Data Streaming (CDC) забезпечує спрощену та автоматизовану конфігурацію, що дозволяє легко налаштовувати, контролювати та керувати конвеєром даних у реальному часі.
Платформа підтримує широкий спектр джерел, цілей та платформ, що дозволяє отримувати різноманітні дані та синхронізувати їх в локальних, хмарних та гібридних середовищах.
Qlik Enterprise Manager – це центральна командна панель для зручного масштабування та моніторингу потоку даних з використанням сповіщень.
Існує гнучкий варіант розгортання конвеєра CDC. Залежно від вимог, ви можете обрати:
Ви можете почати з безкоштовної пробної версії без необхідності завантаження та встановлення.
Fluvio

Шукаєте хмарне рішення для потокової передачі з відкритим кодом, низькою затримкою та високою продуктивністю? Fluvio відповідає цим вимогам. Платформа дозволяє виконувати вбудовані обчислення за допомогою SmartModules, що розширюють її функціональні можливості.
Fluvio має обробку розподілених потоків з перевірками для запобігання втраті даних і простоям. Платформа має нативну підтримку API для таких мов програмування, як Rust, Node.js, Python, Java та Go. Можливості Fluvio:
- Об’єднання обчислень з потоковою передачею в єдиному кластері мінімізує затримки.
- Динамічне завантаження власних модулів, які розширюють обчислювальні можливості.
- Висока масштабованість для підтримки різних систем, від невеликих пристроїв IoT до багатоядерних систем.
- Можливості автоматичного відновлення за допомогою декларативного управління, узгодження та реплікації.
- Потужний CLI для ефективної роботи.
Fluvio можна встановити на будь-якій платформі, будь то ноутбук, корпоративний центр обробки даних або публічна хмара.
Fluvio є відкритим програмним забезпеченням, тому його використання є безкоштовним.
Cloudera Stream Processing (CSP)

Базуючись на Apache Flink та Apache Kafka, Cloudera Stream Processing (CSP) надає інструменти для аналізу та отримання цінних відомостей з потокових даних. Платформа має вбудовану підтримку стандартних технологій, таких як SQL та REST. CSP також пропонує комплексне рішення для управління потоками, розроблене спеціально для великих підприємств.
Cloudera Stream Processing зчитує та аналізує великі обсяги даних в реальному часі, забезпечуючи результати з мінімальними затримками. Платформа має підтримку багатохмарних та гібридних середовищ, а також інструменти для створення складної аналітики на основі даних. Інструменти та функції CSP:
- Масштабована потокова передача для підтримки мільйонів повідомлень за секунду.
- Streams Messaging Manager забезпечує наскрізний перегляд переміщення даних у конвеєрі обробки.
- Streams Replication Manager пропонує реплікацію, доступність та аварійне відновлення.
- Schema Registry дозволяє керувати усіма схемами у спільному сховищі, усуваючи розбіжності та збої.
- Cloudera SDX забезпечує централізовану безпеку з автоматичним примусовим керуванням та уніфікованим контролем усіх компонентів.
З Cloudera Stream Processing ви можете розгорнути конвеєр потокової обробки менш ніж за 10 хвилин на обраній хмарній платформі – будь то AWS, Azure або Google Cloud Platform.
Striim Cloud
Для платформи даних та аналізу в реальному часі, яка потребує різноманітних джерел та споживачів даних, Striim Cloud може бути ідеальним вибором. Платформа має вбудовану підтримку понад 100 конекторів. Легка інтеграція з існуючими сховищами даних та передача даних у реальному часі за допомогою повністю керованої платформи SaaS, розробленої для хмари.
Striim Cloud пропонує простий інтерфейс перетягування для створення конвеєра та візуалізації даних. Платформа підтримує найпопулярніші інструменти аналітики, включаючи Google BigQuery, Snowflake, Azure Synapse та Databricks. Додаткові можливості:
- Можливості управління змінами в структурі даних, з можливістю автоматичного або ручного вирішення проблем.
- Виконання безперервних запитів на базі платформи розподілених потоків SQL.
- Висока масштабованість та пропускна здатність.
- Метод “ReadOnlyWriteMany” для додавання та видалення нових цілей без впливу на існуючі сховища даних.
Оплата Striim відбувається тільки за фактичне використання. Безкоштовне середовище розробника Striim дозволяє випробувати платформу з 10 мільйонами подій на місяць. Для хмарного рішення масштабу підприємства вартість починається від $2500 на місяць.
Платформа потокових даних VK
VK (Vertical Knowledge) завдяки високим стандартам даних та аналітики допомагає приватним особам та компаніям приймати важливі масштабні рішення. Платформа потокових даних VK дозволяє обробляти великі обсяги даних через веб-середовище потокової передачі даних.
Отримуйте корисну статистику за допомогою автоматичного виявлення даних. Основні переваги платформи потокових даних VK:
- Надійна кібербезпека завдяки стабільній інфраструктурі VK, що захищає від шкідливого контенту. Завантаження даних у віртуальному середовищі.
- Автоматизовані потоки даних для легкої роботи з багатьма джерелами.
- Швидке виявлення даних, скорочення ручних процесів.
- Створення глибоких збірок даних, одночасний запуск конвеєрів з кількох джерел.
- Експорт збірок даних у форматі JSON або CSV або використання API для інтеграції зі сторонніми системами.
Платформа HStream
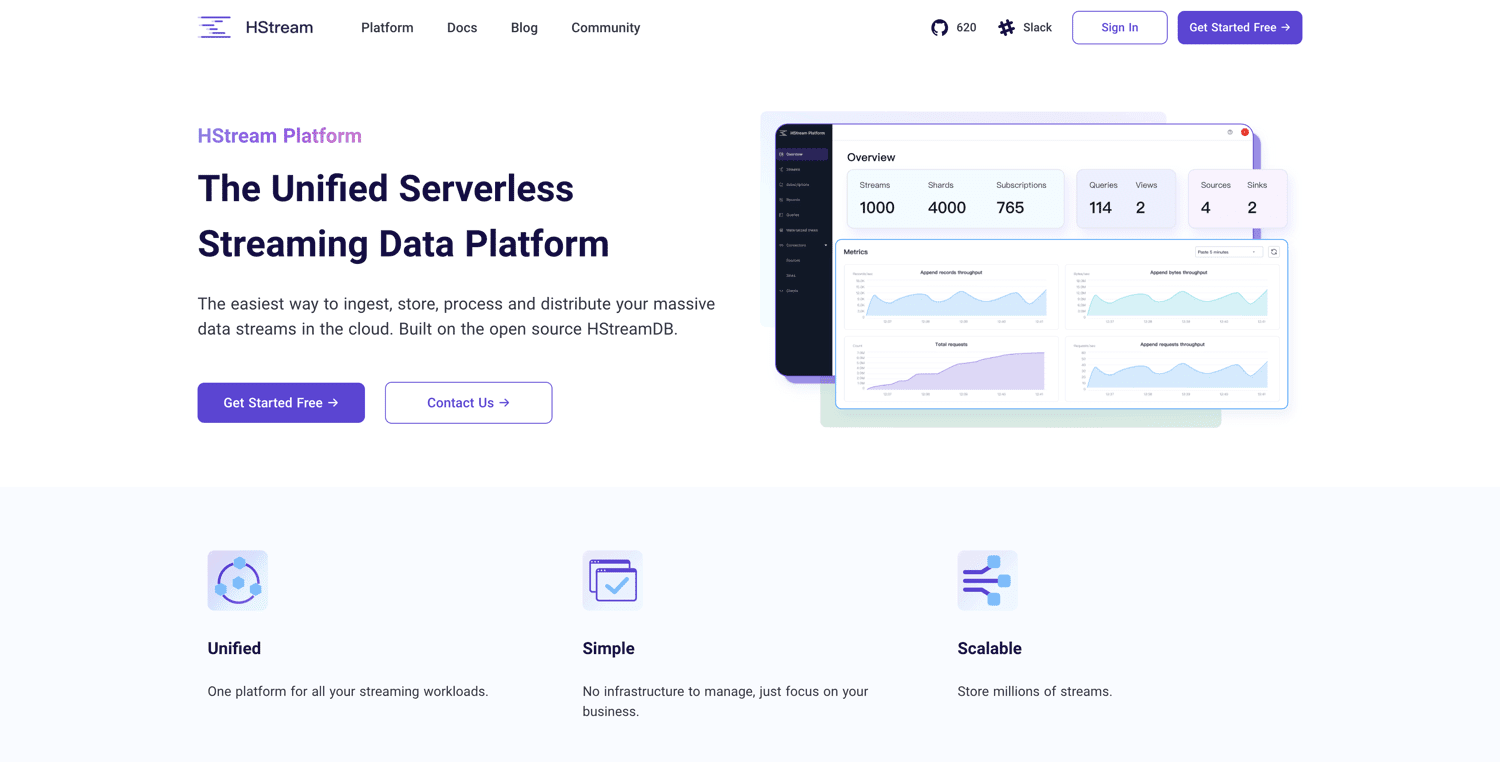
Базуючись на HStreamDB з відкритим кодом, Платформа HStream пропонує безсерверну платформу потокових даних. Платформа дозволяє отримувати великі обсяги даних та надійно зберігати мільйони потоків даних. HStreamDB така ж швидка, як Kafka. Є можливість відтворення історичних даних.
Для фільтрації, трансформації, агрегування та об’єднання даних можна використовувати SQL, що дозволяє отримувати інформацію в режимі реального часу. Платформа HStream дозволяє розпочати з малого і є економічно вигідною. Ключові особливості:
- Безсерверна робота.
- Відсутність потреби у Kafka.
- Обробка потоків на місці за допомогою стандартного SQL.
- Споживання та виробництво даних у різні системи, бази даних, сховища даних або озера даних.
- Ефективне управління робочим навантаженням на одній єдиній потоковій платформі.
- Хмарна архітектура дозволяє масштабувати потреби в обчисленнях і сховищах.
Платформа HStream зараз знаходиться на стадії публічного бета-тестування. Використовувати її можна безкоштовно, потрібно лише зареєструватися.
Висновок
Вибір правильної платформи для потокової передачі даних залежить від вашого масштабу, необхідних конекторів, часу безвідмовної роботи та надійності.
Деякі платформи є повністю керованими сервісами, в той час як інші мають відкритий вихідний код і пропонують різноманітні можливості налаштування. Враховуйте ваші потреби та бюджет при виборі оптимального рішення.
Замислюєтесь, як краще використовувати усі ці дані? Спробуйте інструменти прогнозування та аналізу даних на основі штучного інтелекту.