
Графічні бази даних зберігають щільні дані з високим зв’язком і ефективно обробляють запити. Але чи знаєте ви, яку базу даних графів використовувати? Прочитайте, щоб дізнатися більше.
«Дані — це нова нафта». Зростання будь-якої організації залежить від того, наскільки вони ефективно зберігають і використовують дані. Щодня генерується 2,5 квінтильйона байт даних. Отже, нам потрібні відмовостійкі системи та сховища, де дані можна зберігати та ефективно керувати ними. Спочатку використовувалися реляційні бази даних.
Але з часом кількість і тип даних швидко змінювалися. Тому виникла потреба зберігати відео, аудіо, зображення тощо. Це стало пусковою точкою для розробки баз даних SQL, NoSQL, Hadoop, баз даних графів тощо. Кожна з них має власні варіанти використання та має справу з різними форматами даних. Графові бази даних були розроблені для спрощення операцій з даними та ефективного зберігання.
Графові бази даних
Граф — це структура даних, представлена у вигляді вузлів і ребер. База даних — це набір таблиць, у якому зберігаються дані та зв’язки між ними. База даних графів — це база даних, яка зберігає дані у вузлах і зв’язки, які існують у даних у формі ребер. Графічні бази даних допомагають обробляти запити в реальному часі та ефективно керувати зв’язками «багато-до-багатьох» між об’єктами.
До популярних графових моделей даних належать графи властивостей і RDF-графи. Аналітика та запити здебільшого виконуються за допомогою графіків властивостей. Інтеграція даних здійснюється за допомогою RDF-графів. Різниця між властивостями та графами RDF полягає в тому, що графи RDF представлені у формі трійок, тобто суб’єкта, предиката та об’єкта.
Графові бази даних зберігають дані у вузлах і зв’язки між даними у формі ребер між вузлами. Ребра в графі можуть бути спрямованими (односпрямованими) або ненаправленими (двонаправленими).
Обробка запиту здійснюється шляхом проходження по графу. Для ефективної відповіді на запити використовуються алгоритми обходу графа, які допомагають знайти шлях від одного вузла до іншого, відстань між вузлами, знайти шаблони, цикли в межах графа, можливість формування кластерів тощо.
Застосування графових баз даних
Графові бази даних використовуються для виявлення шахрайства. Вузли/сутності можуть бути іменами людей, адресами, датою народження тощо, а також деякими шахрайськими IP-адресами, номерами пристроїв тощо. Коли шахрайський вузол взаємодіє з нешахрайським вузлом, між ними утворюються зв’язки, які позначаються як підозрілий.
Веб-сайти соціальних медіа використовують бази даних графіків, щоб показати рекомендації людей, з якими ми хотіли б спілкуватися, і вміст, який ми хочемо переглянути. Він робить це за допомогою обходу графа в базі даних.
Відображення мережі та керування інфраструктурою, елементи конфігурації тощо також ефективно зберігаються та керуються за допомогою графових баз даних.
Графічна база даних проти реляційної бази даних
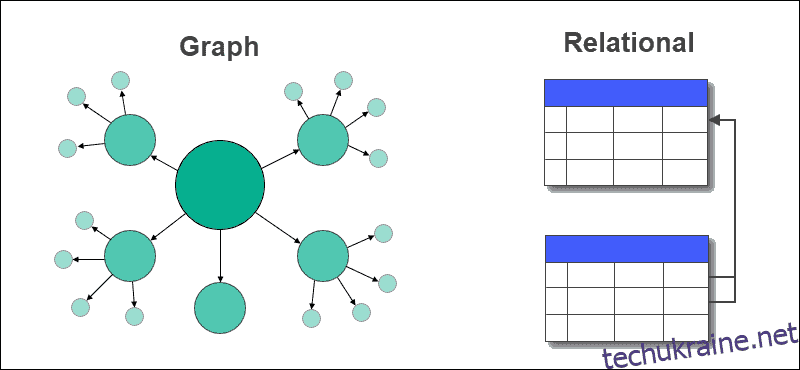
У графовій базі даних таблиці з рядками та стовпцями замінюються вузлами та ребрами. Зв’язки між даними зберігаються на ребрах бази даних графів.
Реляційна база даних зберігає зв’язки між таблицями за допомогою зовнішніх ключів та іншими таблицями. Видобувати дані або надсилати запити легко і не вимагає складних об’єднань у графовій базі даних, але це не стосується реляційних баз даних.
Реляційні бази даних найбільше підходять для варіантів використання, які передбачають транзакції, тоді як бази даних із графами підходять для додатків, у яких багато зв’язків і даних.
Графові бази даних підтримують структуровані, напівструктуровані та неструктуровані дані, тоді як реляційні бази даних повинні мати фіксовану схему.
Графові бази даних задовольняють динамічні вимоги, тоді як реляційні бази даних зазвичай використовуються для відомих і статичних проблем.
 Графік проти реляційних баз даних
Графік проти реляційних баз даних
Давайте тепер розглянемо найкращі рішення для баз даних графів.
Кейлі
Cayley — це графова база даних із відкритим кодом, розроблена Apache 2.0. Він створений за допомогою Go і працює на пов’язаних даних. Cayley — це база даних, яка використовується під час побудови Google Freebase і графіка знань. Він підтримує кілька мов запитів, таких як MQL і Javascript, з графічним об’єктом на основі Gremlin.
Він простий у використанні, швидкий і має модульну конструкцію. Він може інтегруватися та взаємодіяти з різними серверними сховищами, такими як LevelDB, MongoDB і Bolt. Він підтримує різні сторонні API, написані кількома мовами, наприклад Java, .NET, Rust, Haskell, Ruby, PHP, Javascript і Clojure. Його можна розгорнути в Docker і Kubernetes. Ключовими сферами, в яких використовується Cayley, є інформаційні технології, комп’ютерне програмне забезпечення та фінансові послуги.
Амазонка Нептун
Amazon Neptune відомий тим, що надзвичайно добре працює на високопідключених наборах даних. Він надійний, безпечний, повністю керований і підтримує API відкритих графів. Він може зберігати мільярди зв’язків і запитувати дані з надзвичайно низькою затримкою в кілька мілісекунд.
Модель даних графа Нептуна складається з 4 позицій, а саме суб’єкта (S), предиката (P), об’єкта (O) і графіка (G). Кожна з цих позицій використовується для зберігання позиції вихідного вузла, цільового вузла, зв’язку між ними та їхніх властивостей.
Він також використовує кеш, який прискорює виконання запитів на читання. Дані зберігаються у вигляді кластерів БД. Кожен кластер містить основний екземпляр БД і репліки для читання екземплярів БД. Neptune дуже безпечний, оскільки використовує автентифікацію IAM, сертифікацію SSL і моніторинг журналів. Також легко перенести дані з інших джерел в Amazon Neptune. Він також забезпечує відмовостійкість шляхом створення реплік і періодичного резервного копіювання. Деякі компанії, які використовують Neptune, включають Herren, Onedot, Juncture і Hi Platform.
Neo4j
Neo4j — це масштабована, безпечна, надійна графічна база даних, що працює на вимогу. Neo4j було створено з використанням Java, використовуючи Cypher як мову запитів. Він використовує протокол Bolt, і всі транзакції відбуваються через кінцеву точку HTTP. Він набагато швидше відповідає на запити порівняно з іншими реляційними базами даних. У нього немає накладних витрат на складні об’єднання, і його оптимізація добре працює, коли розмір набору даних великий і з високою зв’язністю. Він пропонує перевагу зберігання графів разом із властивостями ACID реляційної бази даних.

Neo4j підтримує різні мови, такі як Java, .NET, Node.js, Ruby, Python тощо, за допомогою драйверів. Він також використовується в графових даних, аналітиці та робочих процесах машинного навчання. Neo4j Aura DB — це відмовостійка та повністю керована база даних хмарних графів. Такі компанії, як Microsoft, Cisco, Adobe, eBay, IBM, Samsung тощо, використовують Neo4j.
ArangoDB
ArangoDB — це багатомодельна база даних з відкритим кодом. Багатомодельний підхід дозволяє користувачам запитувати дані на будь-якій мові запитів на свій вибір. Вузли та межі ArangoDB є документами JSON. Кожен документ має унікальний ідентифікатор. Відносини між двома вузлами позначаються у вигляді ребер, а їхні унікальні ідентифікатори зберігаються. Його хороша продуктивність пояснюється наявністю хеш-індексу.

Покращено проходження, об’єднання та пошук у базах даних. Це допомагає в проектуванні, масштабуванні та адаптації до різних архітектур. Він відіграє важливу роль у складних наукових завданнях, таких як виділення ознак і розширений пошук.
ArrangoDB може працювати в хмарному середовищі та сумісний із Mac OS, Linux та Windows. Автентифікація LDAP, маскування даних і алгоритми шифрування забезпечують безпеку бази даних. Він використовується для управління ризиками, IAM, виявлення шахрайства, мережевої інфраструктури, механізмів рекомендацій тощо. Accenture, Cisco, Dish і VMware є деякими організаціями, які використовують ArangoDB.
DataStax
DataStax — це хмарна база даних NoSQL як послуга, побудована на Apache Cassandra. Він дуже масштабований і використовує хмарну архітектуру. Він надійний і безпечний. Кожен документ, що зберігається в DataStax, має індекс, який допомагає легко шукати та швидко отримувати дані. Шарди створюються над індексованими даними. Різні джерела даних можна використовувати для створення програм за допомогою інструментів Datastax Enterprise, Kafka і Docker.
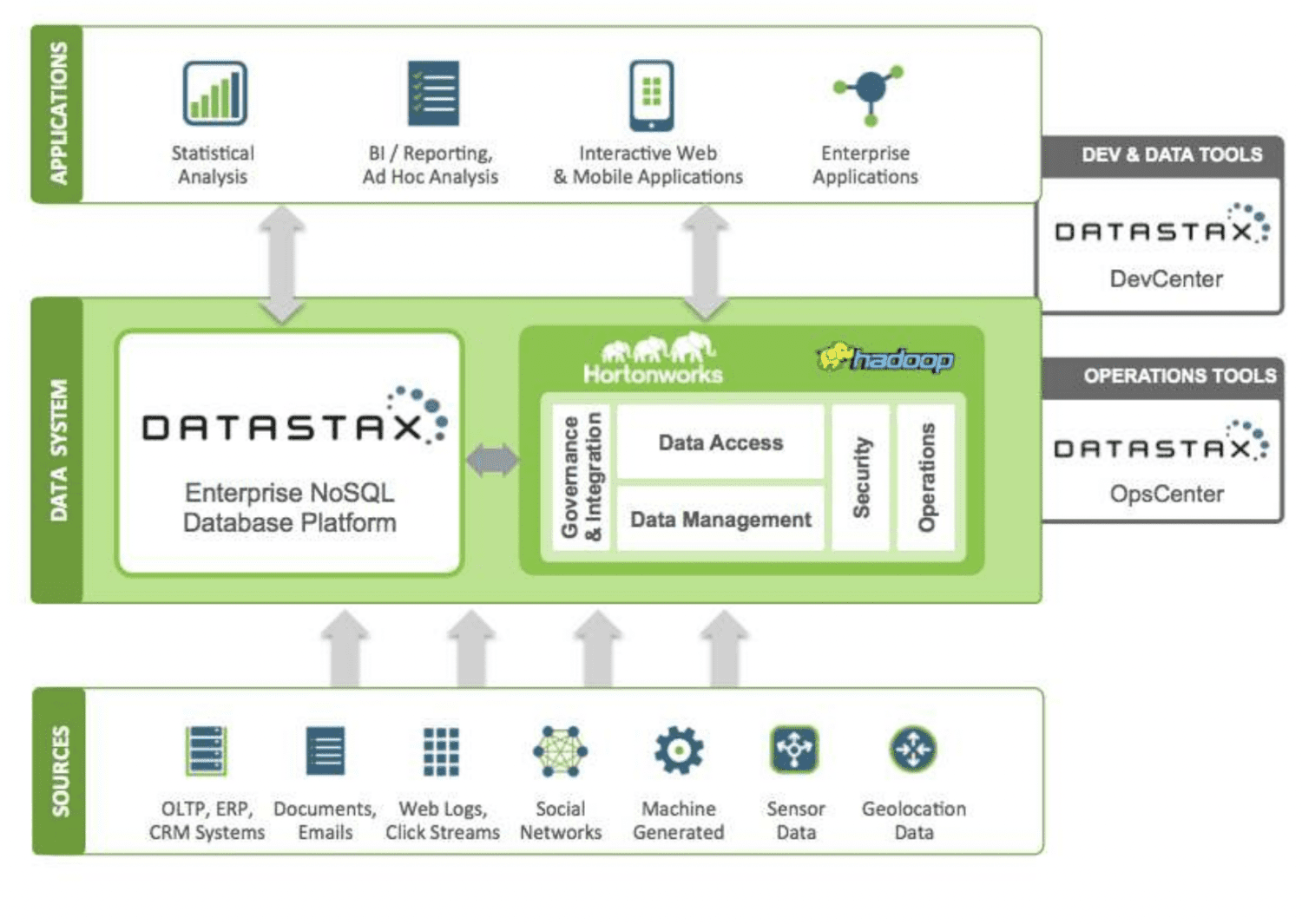
Дані, зібрані з джерел, надсилаються в екосистему Hadoop і DataStax. Hadoop керує безпекою, операціями, доступом до даних і керуванням, взаємодіючи з DataStax. Дані уточнюються за допомогою інструментів розробки та операцій Datastax.
Проаналізована інформація потім використовується для статистичного аналізу, корпоративних додатків, звітності тощо. Оскільки він базується на хмарі, клієнти платять за те, що вони використовують, і ціна є прийнятною. Verizon, CapitalOne, TMobile і Overstock є деякими компаніями, які використовують DataStax.
Орієнтувати БД
OrientDB — це графічна база даних, яка ефективно керує даними та допомагає створювати візуальні представлення для демонстрації даних. Це багатомодельна графова база даних, створена за допомогою Java. Він зберігає дані у формі пар ключ-значення, документи, об’єктні моделі тощо. Він складається з 3 важливих компонентів: графічного редактора, студійного запиту та консолі командного рядка.
Графічний редактор використовується для візуалізації та взаємодії з даними. Інтерфейс запитів Studio використовується для виконання запитів і негайного надання вихідних даних у графічному та табличному форматі. Консоль командного рядка використовується для запиту даних з OrientDB. Він має розподілену архітектуру з кількома серверами, які можуть виконувати операції читання та запису. Сервери-копії використовуються для виконання операцій читання та запитів. Він підтримує індексування, а також сумісний з ACID. Деякі з компаній, які використовують OrientDB, це Comcast Corporation і Blackfriars Group.
Дграф
Dgraph — це база даних хмарних графів, яка підтримує GraphQL. Він був створений за допомогою Go. Це мінімізує мережеві виклики та зменшує затримку за рахунок максимальної одночасної обробки запитів. Повна інтеграція Dgraph із GraphQL допомагає легко розробляти серверні програми GraphQL.

Мутація GraphQL передається через функцію Lambda, яка взаємодіє з базою даних і конвеєром даних. Це спрощує обробку запитів. Він горизонтально масштабований, тобто кількість ресурсів збільшується зі збільшенням запитів і даних. Він надає різні функції, такі як авторизація на основі JWT, візуалізатор даних, хмарна автентифікація, резервне копіювання даних тощо. Деякі організації, які використовують Dgraph, включають Intuit, intel і Factset.
Tigergraph
Tigergraph — це база даних графів властивостей, розроблена за допомогою C++. Він має високу масштабованість і виконує розширену аналітику високопідключених даних. Він використовує власну графову структуру для зберігання даних і механізм обробки графів для обробки даних. База даних зберігається на диску та в пам’яті, а також використовує кеш ЦП для швидкого пошуку. Він використовує функцію Map Reduce для паралельної обробки даних.
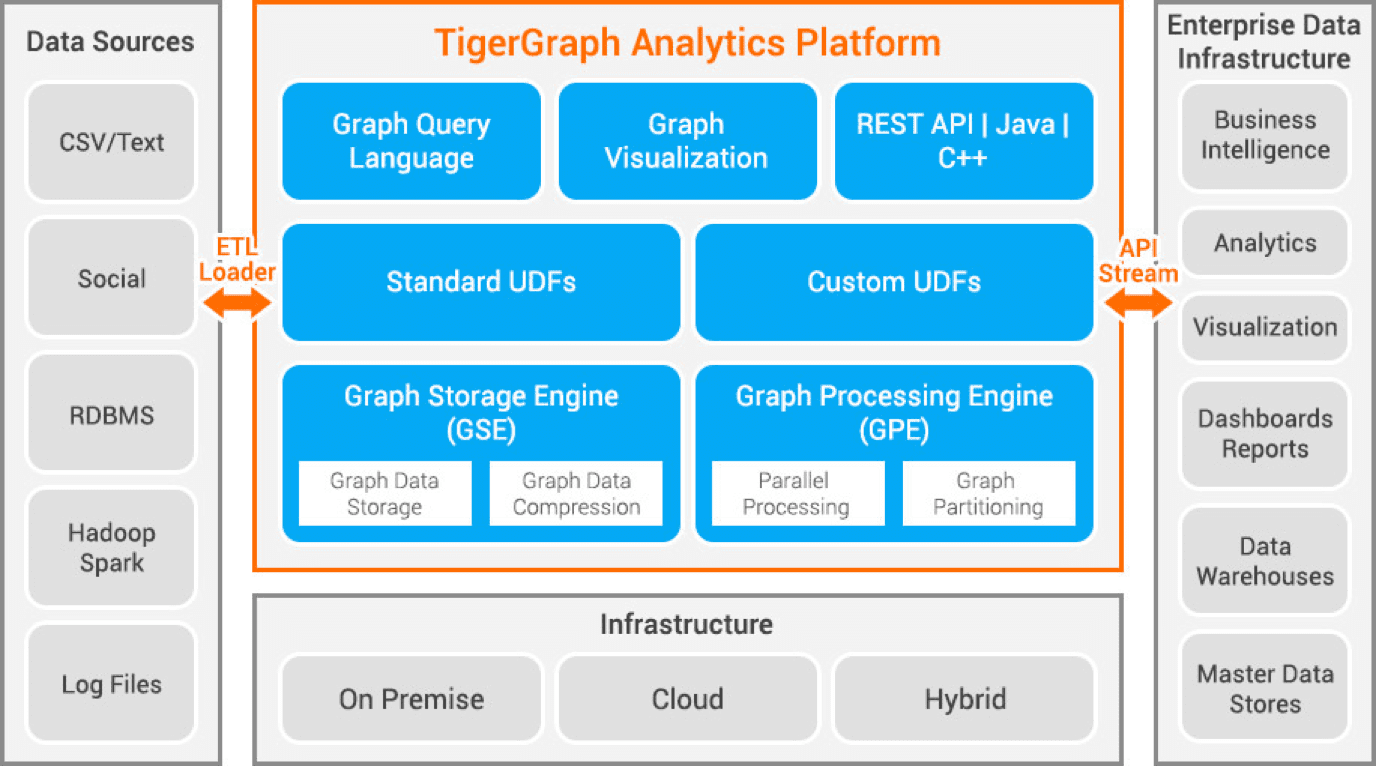
Він надзвичайно швидкий і масштабований. Він виконує паралельні обчислення та забезпечує оновлення в реальному часі. Він використовує методи стиснення даних і стискає дані в 10 разів. Він автоматично розподіляє дані між серверами, заощаджуючи час і зусилля користувача, необхідні для розділення даних вручну. Він використовується для виявлення шахрайства в домогосподарствах, управління ланцюгом постачання та покращення охорони здоров’я. JPMorgan Chase, Intuit і United Health Group є деякими організаціями, які використовують Tigergraph.
AllegroGraph
AllegroGraph використовує технологію графів знань сутності-події для виконання аналітики та прийняття рішень щодо високопов’язаних, складних і щільних даних. Дані зберігаються у форматі JSON і JSON-LD у вузлах графіка. Він використовує архітектуру протоколу REST. Він також має справу з надзвичайно великими наборами даних, розділяючи дані на основі певних критеріїв і розповсюджуючи їх у кількох сховищах баз знань.
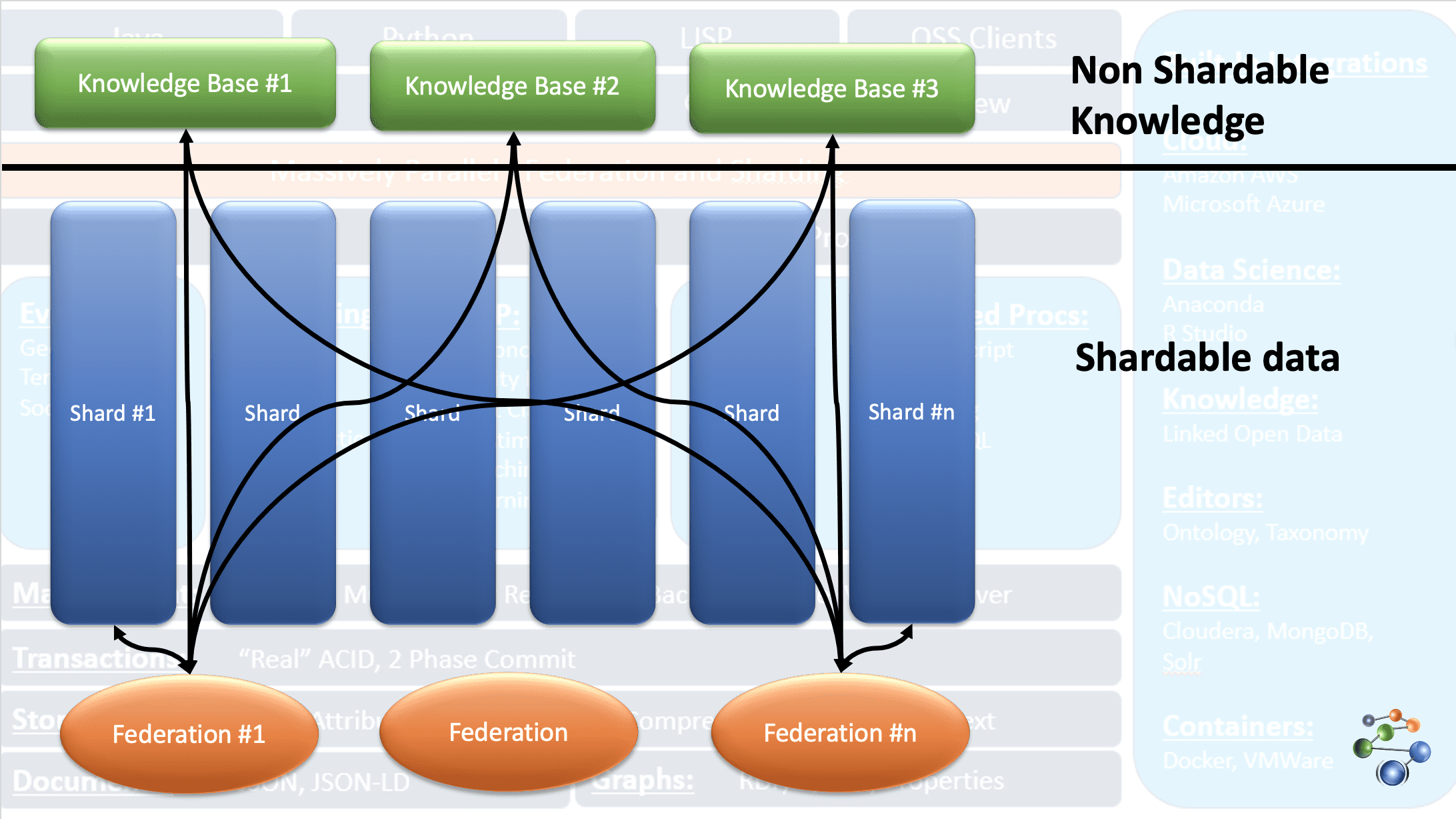
Це можливо завдяки функції FedShard бази даних AllegroGraph. Виконання запитів відбувається шляхом поєднання федерацій із сховищами баз знань. Він підтримує типи схем XML і використовує потрійні індекси. Він зберігає геопросторові дані, такі як широта й довгота, а також часові дані, такі як дата, позначка часу тощо. Він також сумісний із Windows, Mac і Linux. Він використовується для виявлення шахрайства, охорони здоров’я, ідентифікації об’єктів, прогнозування ризиків тощо.
Stardog
Stardog — це база даних графів, яка виконує віртуалізацію даних графів і зв’язує дані зі сховищ даних і озер даних без фізичного копіювання даних у нове місце зберігання. Stardog побудовано на відкритих стандартах RDF. Він підтримує структуровані, напівструктуровані та неструктуровані дані. Цей тип матеріалізації, зроблений Stardog, забезпечує гнучкість. Це єдина база даних графів, яка поєднує графи знань і віртуалізацію.
Stardog використовує систему логічного висновку на базі штучного інтелекту для ефективної обробки та надання результатів запитів. Це ACID-сумісна графічна база даних. Підтримується одночасне читання та запис. Він легко обробляє складні запити завдяки «надсучасній» архітектурі. Він використовується в управлінні ІТ-активами, управлінні та аналітиці даних і забезпечує високу доступність. Деякі компанії, які використовують Stardog, це Cisco, eBay, NASA та Finra.
Заключні слова
Графічні бази даних допомагають легко запитувати зв’язки «багато-до-багатьох» і ефективно зберігати дані. Вони масштабовані, безпечні та можуть бути інтегровані з багатьма сторонніми інструментами, API та мовами. В останні роки вони були інтегровані з хмарою та забезпечують найкращу продуктивність.
Вони спрощують складні об’єднання в прості запити, що робить це легким завданням для розробників. Завдання, що містять інтенсивні дані, такі як IoT і Big Data, також є графовими базами даних. Вони продовжуватимуть розвиватися та, безсумнівно, поширюватимуться на інші випадки використання в майбутньому.