Графічні бази даних ефективно зберігають великі обсяги взаємопов’язаних даних і забезпечують швидку обробку запитів. Але чи відомо вам, яку саме графову базу даних слід обрати? Продовжуйте читати, щоб дізнатися більше.
“Інформація – це нове золото”. Успіх будь-якої організації залежить від її здатності ефективно зберігати та використовувати дані. Щодня генерується величезна кількість даних. Тому потрібні надійні системи зберігання, де можна безпечно розміщувати дані та ефективно ними керувати. Спочатку для цього використовувалися реляційні бази даних.
З часом обсяг і різноманітність даних стрімко зростали. Виникла потреба зберігати відео, аудіо, зображення та інші типи даних. Це стало поштовхом до розробки баз даних SQL, NoSQL, Hadoop, а також графових баз даних. Кожна з них має свої особливості та застосовується до різних форматів даних. Графові бази даних були створені для спрощення роботи з даними та ефективного їх зберігання.
Графові бази даних
Граф – це структура даних, яка складається з вузлів і ребер. База даних – це набір таблиць, де зберігаються дані та зв’язки між ними. Графова база даних, натомість, зберігає дані у вигляді вузлів і зв’язків між ними у формі ребер. Графові бази даних допомагають оперативно обробляти запити та ефективно керувати відносинами “багато-до-багатьох” між об’єктами.
Популярними графовими моделями даних є графи властивостей і RDF-графи. Для аналізу та запитів переважно використовуються графи властивостей, тоді як інтеграція даних здійснюється за допомогою RDF-графів. Відмінність між ними полягає в тому, що RDF-графи представлені у вигляді трійок: суб’єкт, предикат і об’єкт.
Графові бази даних зберігають інформацію у вузлах, а зв’язки між даними – у вигляді ребер, що з’єднують вузли. Ребра можуть бути орієнтованими (однонаправленими) або неорієнтованими (двонаправленими).
Обробка запиту відбувається шляхом обходу графа. Для ефективної відповіді на запити використовуються алгоритми обходу графа, які допомагають знаходити шлях між вузлами, відстані між ними, виявляти закономірності, цикли в графі, можливості кластеризації тощо.
Застосування графових баз даних
Графові бази даних використовуються для виявлення шахрайства. Вузлами можуть бути імена, адреси, дати народження, а також підозрілі IP-адреси, номери пристроїв тощо. Коли шахрайський вузол взаємодіє з нешахрайським, між ними утворюються зв’язки, які позначаються як підозрілі.
Соціальні мережі використовують графові бази даних для надання рекомендацій щодо людей, з якими користувач може захотіти спілкуватися, і контенту, який він хотів би переглянути. Це відбувається за допомогою обходу графа в базі даних.
Мережева візуалізація, управління інфраструктурою, конфігураційними елементами також ефективно зберігаються та керуються за допомогою графових баз даних.
Графова база даних проти реляційної бази даних
У графовій базі даних таблиці з рядками та стовпцями замінено на вузли та ребра. Зв’язки між даними зберігаються на ребрах графової бази даних.
Реляційна база даних зберігає зв’язки між таблицями за допомогою зовнішніх ключів та інших таблиць. Отримання даних або надсилання запитів у графовій базі даних є простішим і не потребує складних об’єднань, на відміну від реляційних баз даних.
Реляційні бази даних найкраще підходять для транзакційних операцій, тоді як графові бази даних ідеальні для додатків з великою кількістю зв’язків та даних.
Графові бази даних підтримують структуровані, напівструктуровані та неструктуровані дані, тоді як реляційні бази даних вимагають фіксованої схеми.
Графові бази даних задовольняють динамічні вимоги, в той час як реляційні бази даних зазвичай використовуються для статичних задач.
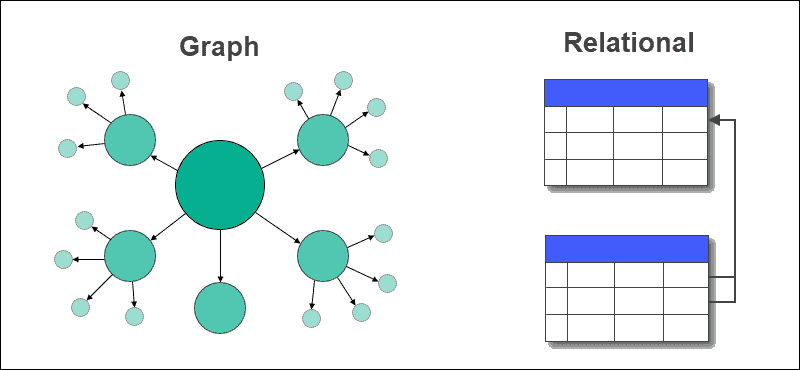 Порівняння графової та реляційної баз даних
Порівняння графової та реляційної баз даних
Розглянемо тепер кращі рішення для графових баз даних.
Кейлі
Cayley – це графова база даних з відкритим кодом, розроблена за ліцензією Apache 2.0. Вона написана на мові Go і призначена для роботи зі зв’язаними даними. Cayley використовувалася для створення Google Freebase і графа знань. Вона підтримує різні мови запитів, такі як MQL і Javascript, з графічним об’єктом на основі Gremlin.
Вона проста у використанні, швидка та має модульну структуру. Cayley інтегрується з різними серверами зберігання, такими як LevelDB, MongoDB і Bolt. Вона підтримує сторонні API, написані на різних мовах, таких як Java, .NET, Rust, Haskell, Ruby, PHP, Javascript і Clojure. Її можна розгорнути в Docker і Kubernetes. Ключові сфери застосування Cayley: інформаційні технології, комп’ютерне програмне забезпечення та фінансові послуги.
Амазон Нептун
Amazon Neptune відома своєю ефективною роботою з великими обсягами взаємопов’язаних даних. Це надійна, безпечна та повністю керована база даних, яка підтримує API відкритих графів. Вона може зберігати мільярди зв’язків і обробляти запити з мінімальною затримкою.
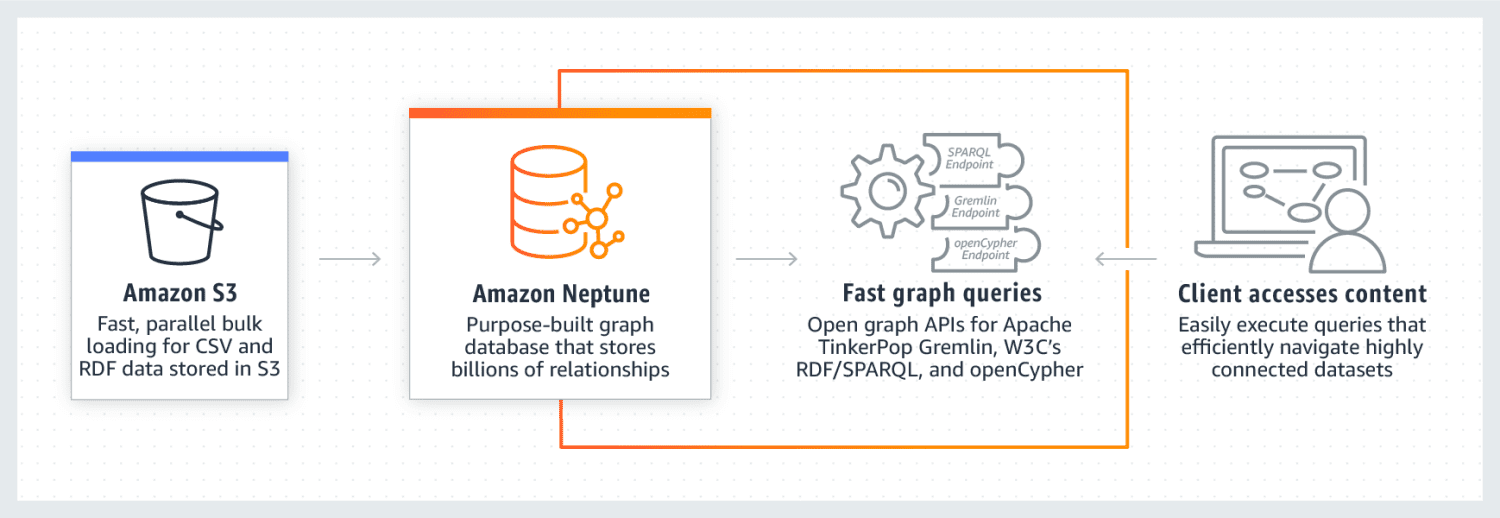
Модель даних графа Neptune складається з чотирьох частин: суб’єкта (S), предиката (P), об’єкта (O) і графа (G). Кожна з них використовується для зберігання позиції початкового вузла, цільового вузла, зв’язку між ними та їх властивостей.
Neptune використовує кеш для прискорення виконання запитів на читання. Дані зберігаються у вигляді кластерів БД, кожен з яких містить основний екземпляр БД та репліки для читання. Neptune забезпечує високий рівень безпеки за допомогою автентифікації IAM, сертифікації SSL і моніторингу журналів. Також легко перенести дані з інших джерел в Amazon Neptune. Завдяки реплікації та регулярному резервному копіюванню забезпечується відмовостійкість. Серед компаній, які використовують Neptune, можна виділити Herren, Onedot, Juncture і Hi Platform.
Neo4j
Neo4j – це масштабована, безпечна та надійна графова база даних. Вона створена на Java, а мовою запитів є Cypher. Neo4j використовує протокол Bolt, а транзакції відбуваються через HTTP. Вона забезпечує швидшу обробку запитів порівняно з реляційними базами даних. Neo4j не має складнощів з об’єднаннями і добре оптимізована для великих обсягів даних. Вона поєднує можливості зберігання графів з властивостями ACID реляційних баз даних.

Neo4j підтримує різні мови, такі як Java, .NET, Node.js, Ruby, Python, за допомогою драйверів. Вона використовується для аналізу графових даних і в процесах машинного навчання. Neo4j Aura DB – це відмовостійка і повністю керована хмарна база даних. Такі компанії, як Microsoft, Cisco, Adobe, eBay, IBM, Samsung використовують Neo4j.
ArangoDB
ArangoDB – це багатомодельна база даних з відкритим кодом. Вона дозволяє користувачам запитувати дані, використовуючи різні мови запитів. Вузли і ребра в ArangoDB представлені у вигляді документів JSON. Кожен документ має унікальний ідентифікатор. Зв’язки між вузлами позначаються ребрами, а їхні ідентифікатори зберігаються. Хороша продуктивність ArangoDB пояснюється наявністю хеш-індексу.

ArangoDB покращує обхід графа, об’єднання та пошук даних. Вона допомагає у проектуванні, масштабуванні та адаптації до різних архітектур. ArangoDB важлива для складних наукових завдань, таких як виділення ознак та розширений пошук.
ArangoDB може працювати в хмарному середовищі та сумісна з Mac OS, Linux та Windows. Автентифікація LDAP, маскування даних і шифрування забезпечують безпеку. ArangoDB використовується для управління ризиками, IAM, виявлення шахрайства, управління мережевою інфраструктурою, механізмів рекомендацій тощо. Accenture, Cisco, Dish і VMware – це деякі організації, що використовують ArangoDB.
DataStax
DataStax – це хмарна база даних NoSQL як послуга, побудована на Apache Cassandra. Вона є масштабованою, надійною та безпечною. Кожен документ, збережений у DataStax, має індекс, який забезпечує легкий та швидкий пошук даних. Дані розділені на шарди. Для розробки додатків можна використовувати різні джерела даних за допомогою інструментів Datastax Enterprise, Kafka і Docker.
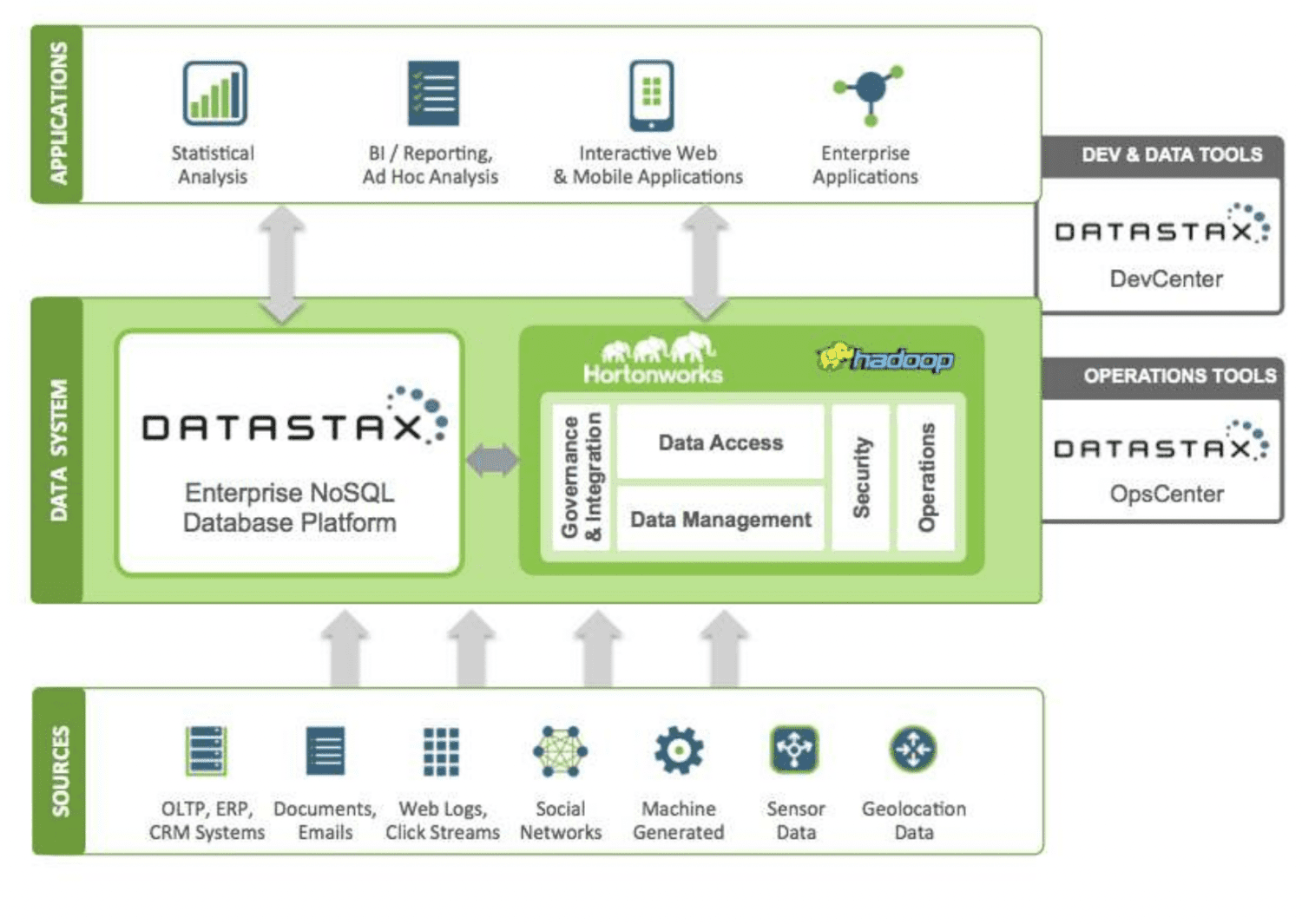
Дані з різних джерел надсилаються до екосистеми Hadoop і DataStax. Hadoop керує безпекою, операціями, доступом до даних та їх обробкою, взаємодіючи з DataStax. Дані обробляються за допомогою інструментів розробки та операцій Datastax.
Оброблені дані використовуються для статистичного аналізу, корпоративних додатків, звітності тощо. DataStax є хмарною платформою, тому користувачі платять лише за те, що використовують, і ціна є прийнятною. Verizon, CapitalOne, TMobile і Overstock є серед компаній, які використовують DataStax.
OrientDB
OrientDB – це графова база даних, яка ефективно керує даними та створює візуальні представлення для їх демонстрації. Це багатомодельна графова база даних, написана на Java. Вона зберігає дані у різних форматах: ключ-значення, документи, об’єктні моделі. OrientDB складається з трьох важливих компонентів: графічного редактора, студійного запиту та консолі командного рядка.
Графічний редактор використовується для візуалізації даних. Інтерфейс запитів Studio використовується для виконання запитів та відображення результатів у графічному та табличному вигляді. Консоль командного рядка використовується для запиту даних з OrientDB. OrientDB має розподілену архітектуру з кількома серверами, які можуть виконувати операції читання та запису. Сервери-репліки використовуються для операцій читання та запитів. OrientDB підтримує індексацію та сумісна з ACID. Серед компаній, які використовують OrientDB, є Comcast Corporation і Blackfriars Group.
Dgraph
Dgraph – це хмарна графова база даних, яка підтримує GraphQL. Вона розроблена на мові Go. Dgraph мінімізує кількість мережевих викликів та зменшує затримку завдяки паралельній обробці запитів. Інтеграція Dgraph з GraphQL дозволяє легко розробляти бекенд-додатки.

GraphQL-мутації обробляються через функцію Lambda, яка взаємодіє з базою даних та конвеєром даних, що спрощує обробку запитів. Dgraph горизонтально масштабується, тобто кількість ресурсів збільшується зі зростанням кількості запитів та даних. Вона надає різні функції, такі як авторизація на основі JWT, візуалізатор даних, хмарна автентифікація, резервне копіювання. Серед організацій, які використовують Dgraph, є Intuit, Intel і Factset.
Tigergraph
Tigergraph – це графова база даних з властивостями, розроблена на C++. Вона має високу масштабованість та забезпечує розширений аналіз зв’язаних даних. Tigergraph використовує власну графову структуру для зберігання даних та механізм обробки графів. База даних зберігається на диску та в пам’яті, а також використовує кеш процесора для швидкого пошуку. Tigergraph використовує функцію Map Reduce для паралельної обробки даних.
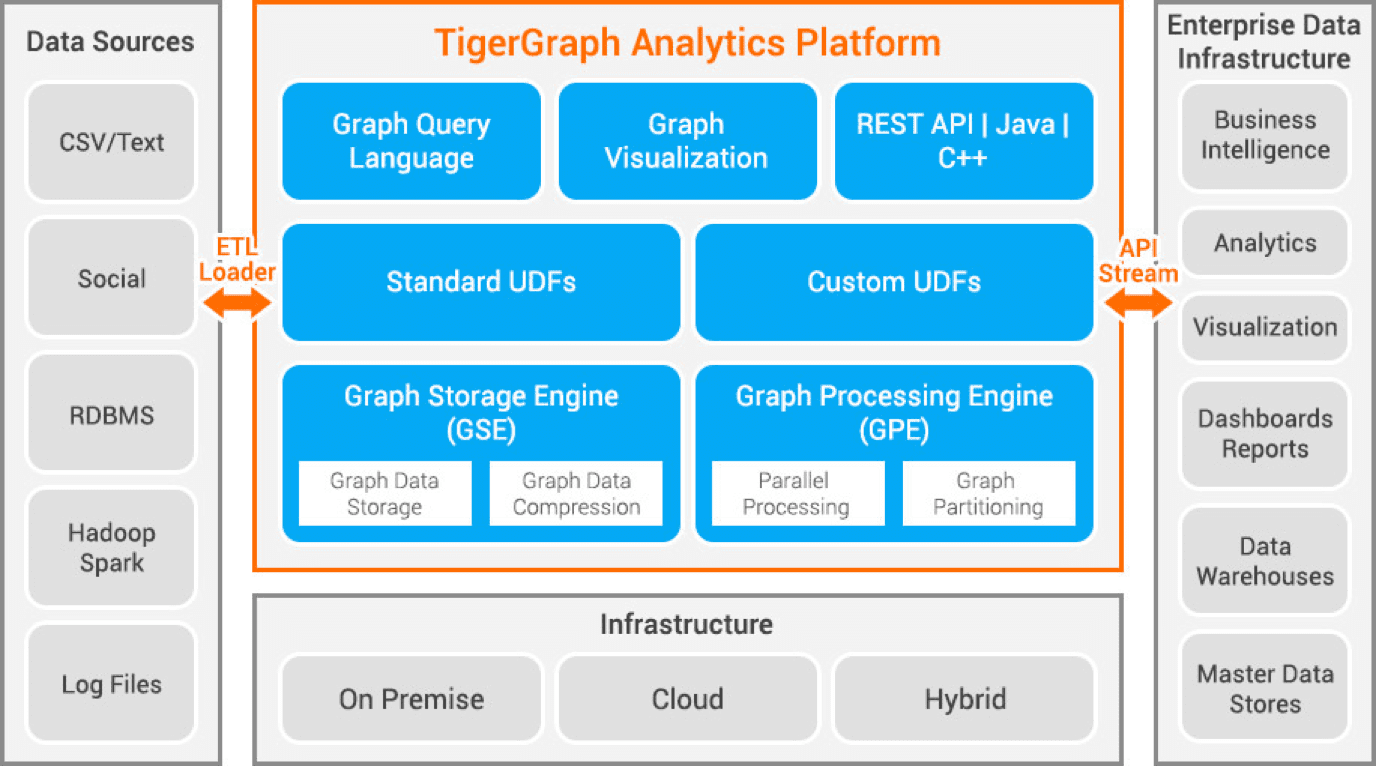
Tigergraph є надзвичайно швидкою та масштабованою. Вона забезпечує паралельні обчислення та оновлення в реальному часі. Tigergraph використовує методи стиснення даних та стискає дані у 10 разів. Вона автоматично розподіляє дані між серверами. Tigergraph застосовується для виявлення шахрайства, управління ланцюгом постачання та поліпшення охорони здоров’я. JPMorgan Chase, Intuit і United Health Group є серед організацій, що використовують Tigergraph.
AllegroGraph
AllegroGraph використовує технологію графа знань для аналізу та прийняття рішень щодо складних та великих обсягів даних. Дані зберігаються у форматах JSON та JSON-LD у вузлах графа. AllegroGraph використовує архітектуру протоколу REST. Вона обробляє великі обсяги даних шляхом поділу їх на частини, які розподіляються у сховищах баз знань.
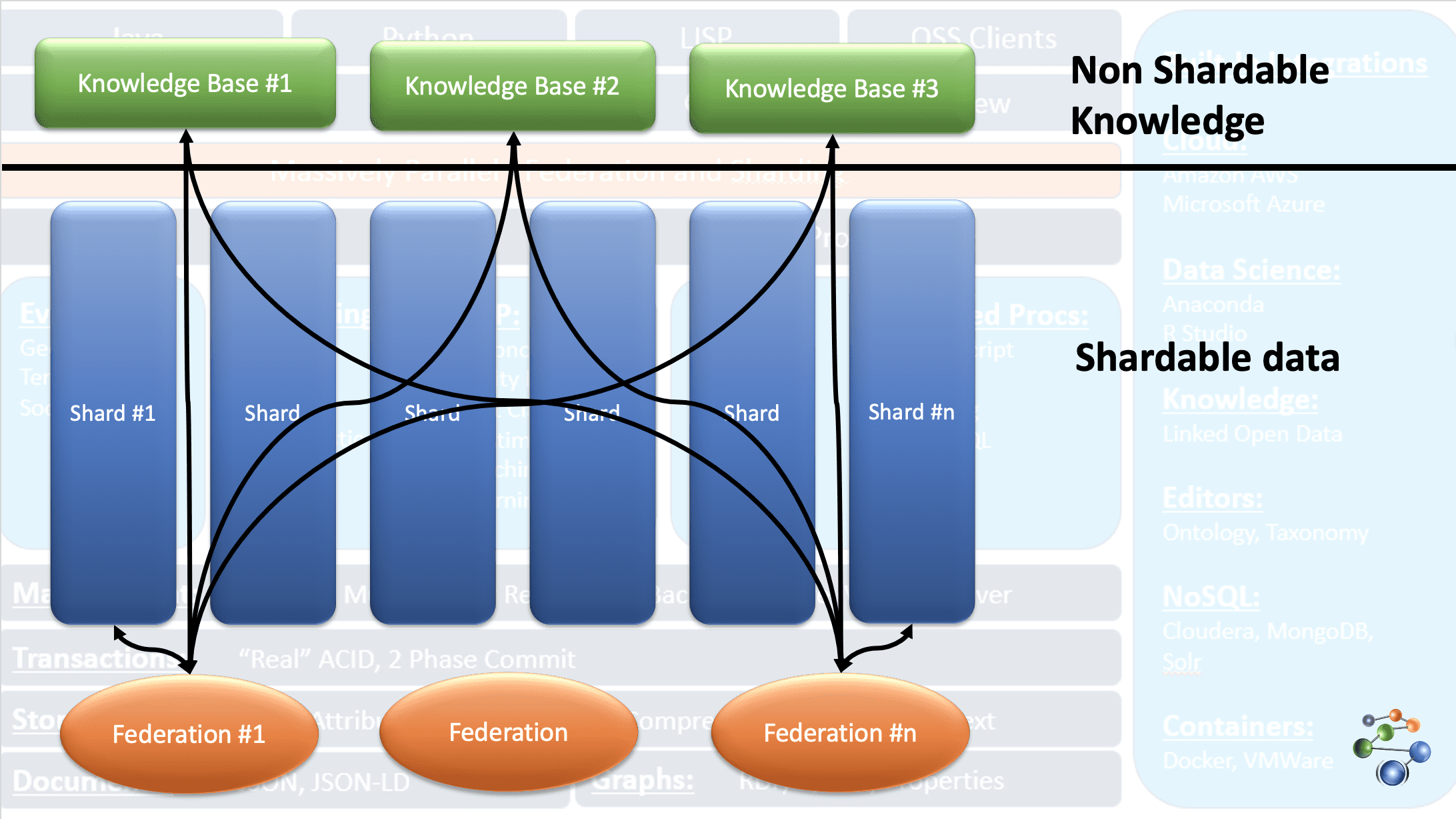
Це можливо завдяки функції FedShard. Виконання запитів відбувається шляхом об’єднання федерацій зі сховищами баз знань. AllegroGraph підтримує типи схем XML і використовує потрійні індекси. Вона зберігає геопросторові дані, такі як широта і довгота, а також часові дані. AllegroGraph сумісна з Windows, Mac і Linux. Її використовують для виявлення шахрайства, в охороні здоров’я, для ідентифікації об’єктів, прогнозування ризиків тощо.
Stardog
Stardog – це графова база даних, яка виконує віртуалізацію графових даних, зв’язуючи їх зі сховищами без фізичного копіювання в нове місце. Stardog побудована на відкритих стандартах RDF і підтримує структуровані, напівструктуровані та неструктуровані дані. Stardog поєднує графи знань та віртуалізацію.
Stardog використовує систему логічного висновування на базі штучного інтелекту для ефективної обробки запитів. Це ACID-сумісна графова база даних. Stardog підтримує одночасні операції читання та запису. Вона легко обробляє складні запити завдяки сучасній архітектурі. Stardog використовується в управлінні ІТ-активами, управлінні даними та аналітиці і забезпечує високу доступність. Серед компаній, які використовують Stardog, є Cisco, eBay, NASA та Finra.
Заключні слова
Графові бази даних дозволяють легко запитувати зв’язки “багато-до-багатьох” і ефективно зберігати дані. Вони масштабовані, безпечні і можуть інтегруватися зі сторонніми інструментами, API і мовами. Останніми роками вони інтегровані з хмарою та забезпечують високу продуктивність.
Графові бази даних спрощують складні об’єднання в прості запити, що полегшує роботу розробників. Задачі з обробкою великих обсягів даних, такі як IoT та Big Data, також використовують графові бази даних. Вони продовжуватимуть розвиватися та, безсумнівно, знайдуть застосування в багатьох інших сферах.