Бажаєте розширити свій набір інструментів програміста, включивши в нього структури даних? Зробіть перший крок вже сьогодні, досліджуючи структури даних, доступні в Python.
Вивчаючи будь-яку нову мову програмування, надзвичайно важливо зрозуміти основні типи даних та вбудовані структури даних, які підтримує ця мова. В цьому довіднику ми розглянемо структури даних Python, а саме:
- переваги, які надає використання структур даних
- вбудовані структури даних Python, такі як списки, кортежі, словники та множини
- реалізацію абстрактних типів даних, наприклад, стеків і черг.
Отже, почнемо!
Чому структури даних є корисними?
Перш ніж детально розглядати різноманітні структури даних, давайте з’ясуємо, чому їх використання є вигідним:
- Ефективна обробка даних: правильний вибір структури даних значно підвищує ефективність обробки інформації. Наприклад, якщо необхідно зберігати набір елементів одного типу з швидким доступом та тісним зв’язком, варто обрати масив.
- Покращене керування пам’яттю: у великих проектах одна структура даних може виявитися більш економічною в плані використання пам’яті порівняно з іншою для зберігання однакових даних. Наприклад, у Python для зберігання колекцій даних як списки, так і кортежі можна використовувати для зберігання колекцій даних одного або різних типів. Проте, якщо вам відомо, що колекцію не потрібно буде змінювати, краще обрати кортеж, оскільки він займає менше пам’яті, ніж список.
- Організованіший код: застосування відповідної структури даних для певної задачі робить ваш код більш організованим і зрозумілим. Інші програмісти, переглядаючи ваш код, очікуватимуть, що ви використовуватимете певні структури даних, відповідно до їхньої передбачуваної поведінки. Наприклад, якщо вам потрібне відображення ключ-значення з постійним часом пошуку та вставки, оптимальним вибором буде словник.
Списки
Коли у Python виникає потреба у створенні динамічних масивів – чи то під час співбесід з програмування, чи у звичайних сценаріях використання – списки є фундаментальними структурами даних.
Списки у Python є контейнерними типами даних, що є змінними та динамічними, дозволяючи додавати та видаляти елементи безпосередньо, не створюючи при цьому копію.
При роботі зі списками Python:
- Індексація списку та доступ до елемента за певним індексом є операцією, що виконується за постійний час.
- Додавання елемента в кінець списку також є операцією, що виконується за постійний час.
- Вставка елемента за певним індексом є лінійною за часом операцією.
Існує набір методів списку, що допомагають ефективно виконувати типові завдання. Наведений нижче фрагмент коду демонструє, як ці операції виконуються на прикладі списку:
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Списки Python також підтримують нарізку та перевірку наявності елемента за допомогою оператора in:
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
Структура даних списку є не тільки гнучкою та простою, але й дозволяє зберігати елементи різних типів даних. Python також має спеціалізовану структуру даних масиву для ефективного зберігання елементів одного типу даних. Ми докладніше розглянемо її далі в цьому посібнику.
Кортежі
У Python кортежі є ще однією популярною вбудованою структурою даних. Вони мають схожість зі списками Python в тому, що ви можете індексувати їх за постійний час та розділяти. Однак, вони є незмінними, тому їх не можна модифікувати безпосередньо. Наступний фрагмент коду демонструє це на прикладі кортежу nums:
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # not a valid operation! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
Таким чином, якщо ваша мета – створити незмінну колекцію з можливістю її ефективної обробки, кортеж буде відмінним вибором. Якщо вам потрібна колекція, яку можна змінювати, тоді варто надати перевагу списку.
📋 Дізнайтеся більше про схожість і відмінності між списками та кортежами Python.
Масиви
Масиви – це менш поширена структура даних в Python. Вони подібні до списків Python за набором підтримуваних операцій, таких як індексація за постійний час та вставка елемента за певним індексом за лінійний час.
Проте, ключова відмінність між списками та масивами полягає в тому, що масиви зберігають елементи одного типу даних. Це означає, що вони зберігаються тісніше і більш ефективно використовують пам’ять.
Для створення масиву можна використати конструктор array() з вбудованого модуля array. Конструктор array() приймає рядок, що визначає тип даних елементів, та самі елементи. Наприклад, тут ми створюємо nums_f – масив чисел з плаваючою комою:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
До масиву можна звертатися за індексом (так само, як і до списків Python):
>>> nums_f[0] 1.5
Масиви є змінними, тому їх можна змінювати:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Однак ви не можете змінювати тип даних елемента:
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Рядки
У Python рядки є незмінними послідовностями символів Unicode. На відміну від деяких мов програмування, таких як C, Python не має спеціального типу даних для символів. Тому символ – це рядок довжиною в один символ.
Як вже зазначалося, рядок є незмінним:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Рядки Python підтримують нарізку та мають набір методів для їхнього форматування. Ось кілька прикладів:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'python'
⚠ Слід пам’ятати, що всі наведені вище операції повертають копію рядка, а не змінюють вихідний рядок. Якщо вам цікаво, ознайомтесь з детальним посібником з операцій над рядками в Python.
Множини
У Python множини – це колекції унікальних та хешованих елементів. З множинами можна виконувати типові операції, такі як об’єднання, перетин та різниця:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Множини за замовчуванням є змінними, тому до них можна додавати нові елементи та змінювати їх:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Ознайомтеся з повним посібником з множин у Python, що містить приклади коду.
FrozenSets
Якщо потрібна незмінна множина, можна використовувати заморожену множину (frozenset). Заморожену множину можна створити на основі існуючих множин чи інших ітерованих елементів.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
Оскільки frozenset_1 є замороженою множиною, спроба додати елемент (або іншим чином змінити її) призведе до помилки:
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Словники
Функціональність словника Python аналогічна хеш-мапі. Словники використовуються для зберігання пар ключ-значення. Ключі словника мають бути хешованими. Це означає, що хеш-значення об’єкта не змінюється.
Ви можете отримувати доступ до значень за допомогою ключів, вставляти нові пари ключ-значення та видаляти існуючі за постійний час. Для виконання цих операцій існують спеціальні методи словника.
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Хоча словник Python забезпечує відображення ключ-значення, за своєю природою це невпорядкована структура даних. Починаючи з Python 3.7, порядок вставки елементів зберігається. Проте, ви можете зробити це більш явним, використовуючи OrderedDict з модуля collections.
Як показано нижче, OrderedDict зберігає порядок ключів:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
Defaultdict
Помилки, пов’язані з ключами, є досить поширеними при роботі зі словниками в Python. Кожного разу, коли ви намагаєтеся отримати доступ до ключа, якого немає у словнику, ви отримаєте виняток KeyError.
Але, використовуючи defaultdict з модуля collections, можна обробити цей випадок нативно. Коли відбувається спроба доступу до ключа, якого немає у словнику, ключ автоматично додається та ініціалізується значенням за замовчуванням, визначеним фабрикою за замовчуванням.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
Стеки
Стек – це структура даних, що працює за принципом “останнім прийшов – першим вийшов” (LIFO). Операції, які можна виконувати зі стеком:
- Додавання елементів на вершину стека: операція push.
- Видалення елементів з вершини стека: операція pop.
Нижче наведено приклад, що ілюструє принцип роботи операцій push та pop у стеку:
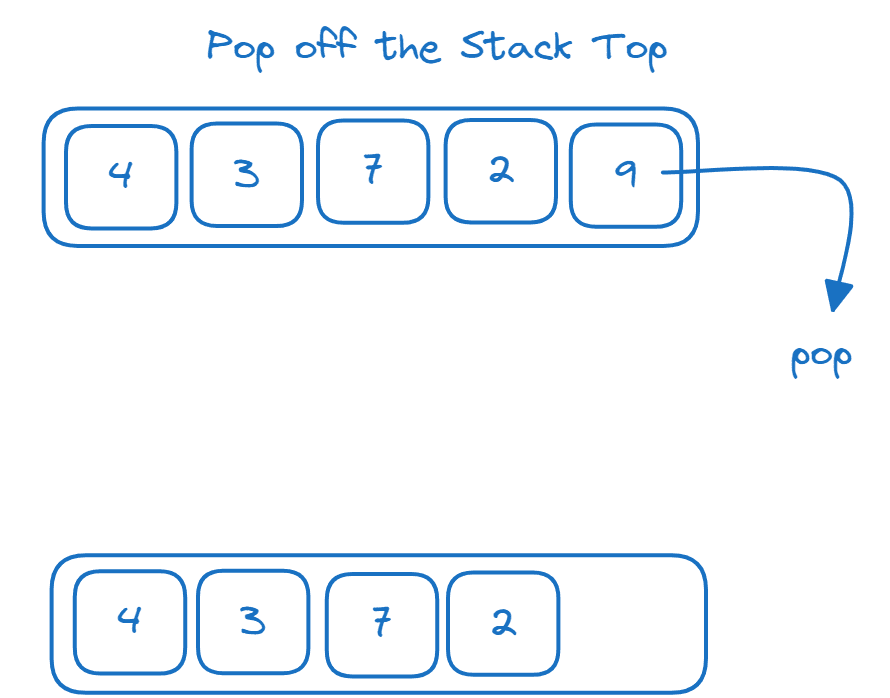
Як реалізувати стек за допомогою списку
У Python структуру даних стека можна реалізувати за допомогою списку Python.
Список Еквівалентна Операція для стека Операція Push у стек Додавання в кінець списку за допомогою методу append() Операція Pop у стек Видалення і повернення останнього елемента за допомогою методу pop()
Наведений нижче код демонструє, як можна імітувати поведінку стека за допомогою списку Python:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Як реалізувати стек за допомогою Deque
Інший спосіб реалізації стека – використання deque з модуля collections. Deque означає “двостороння черга”, підтримує додавання та видалення елементів з обох кінців.
Для імітації стека можна:
- додавати елементи в кінець deque за допомогою append(), і
- витягувати останній доданий елемент за допомогою pop().
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2, 9]) >>> stk.pop() 9
Черги
Черга – це структура даних типу FIFO. Елементи додаються в кінець черги та видаляються з її початку, як показано нижче:
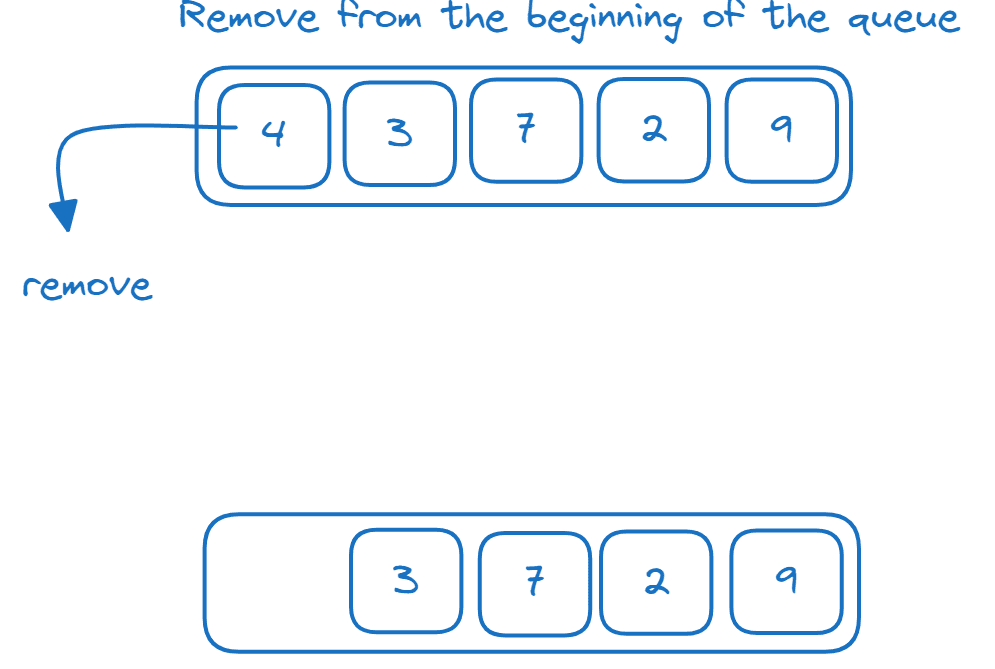
Структуру даних черги можна реалізувати за допомогою deque:
- додавати елементи в кінець черги за допомогою append()
- видаляти елемент з початку черги за допомогою методу popleft()
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Купи
У цьому розділі ми розглянемо двійкові купи. Особливу увагу приділимо міні-купам.
Міні-купа – це повне бінарне дерево. Розберемо, що означає повне бінарне дерево:
- Бінарне дерево – це деревоподібна структура даних, де кожен вузол має не більше двох дочірніх вузлів, причому кожен вузол менший за свого нащадка.
- Термін “повне” означає, що дерево повністю заповнене, за винятком, можливо, останнього рівня. Якщо останній рівень заповнений частково, він заповнюється зліва направо.
Оскільки кожен вузол має не більше двох дочірніх вузлів, а також задовольняє властивість того, що він менший за свого нащадка, корінь є мінімальним елементом у міні-купі.
Ось приклад міні-купи:
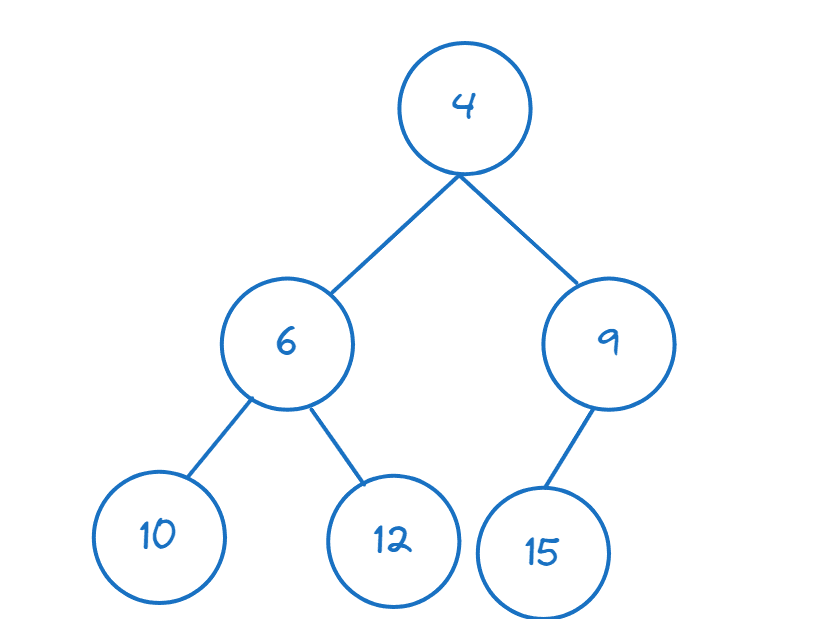
У Python модуль heapq дозволяє нам створювати купи та виконувати над ними операції. Імпортуємо необхідні функції з heapq:
>>> from heapq import heapify, heappush, heappop
Якщо у вас є список або інший ітерований елемент, ви можете створити з нього купу, викликавши heapify():
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
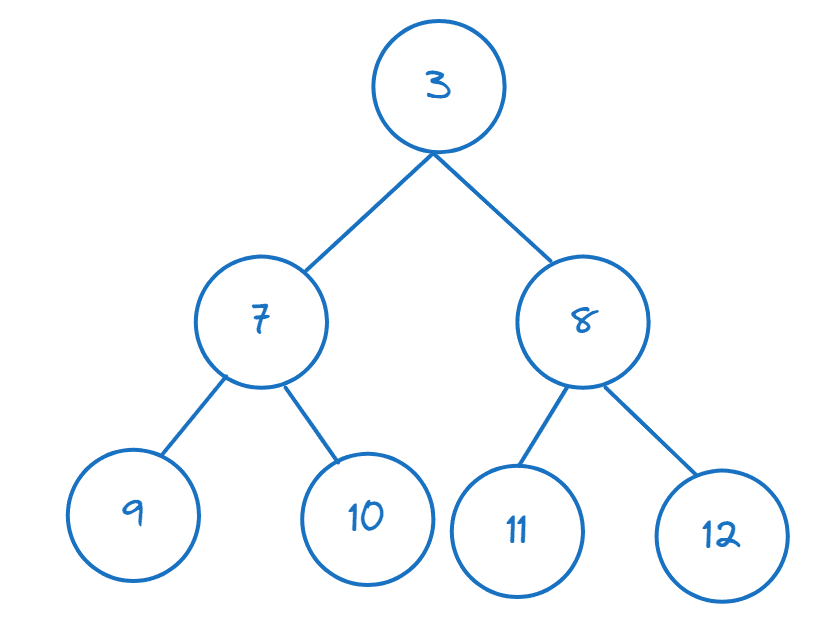
Можна перевірити перший елемент за індексом, щоб переконатися, що він є мінімальним:
>>> nums[0] 3
Тепер, якщо вставити елемент у купу, вузли будуть переставлені таким чином, щоб вони задовольняли властивість міні-купи.
>>> heappush(nums,1)
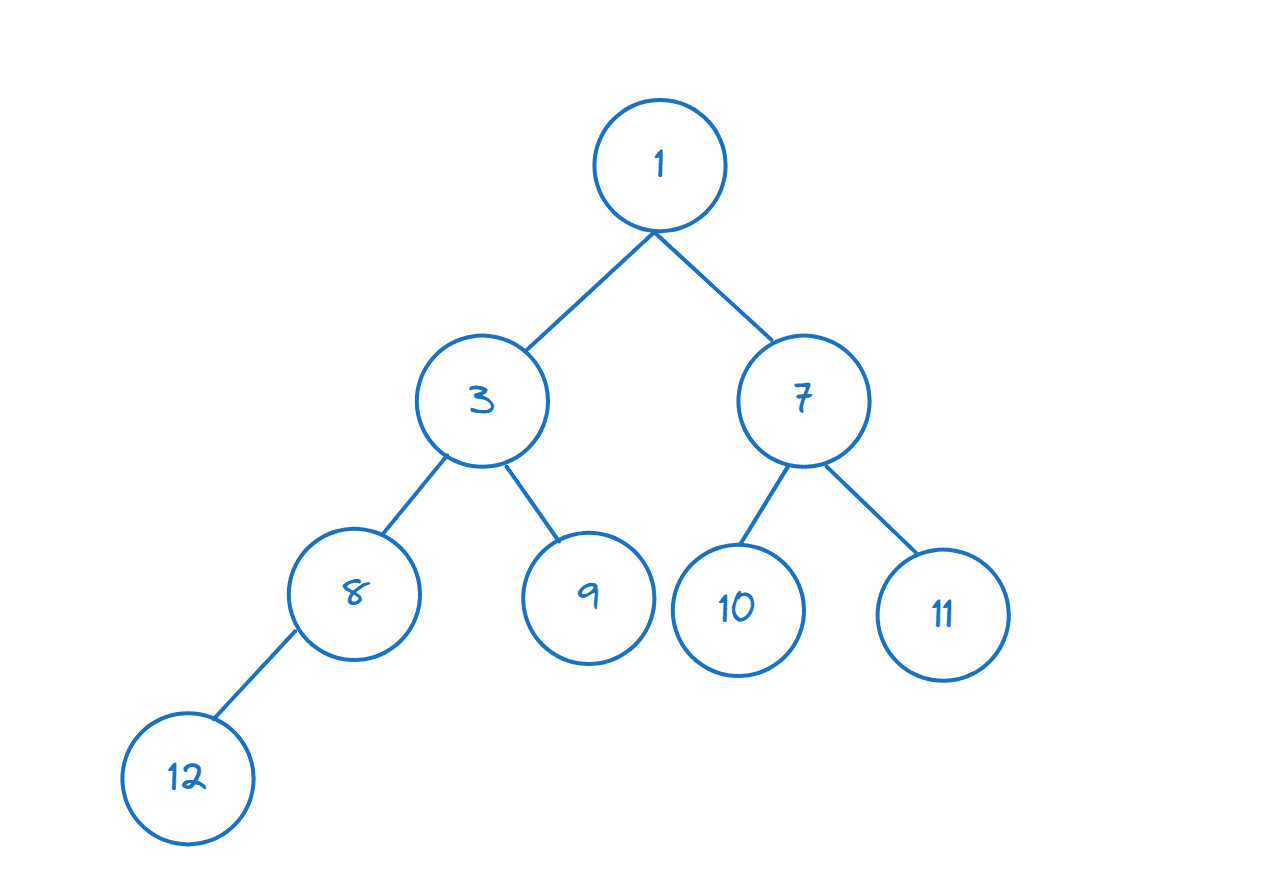
Оскільки ми вставили 1 (1 < 3), бачимо, що nums[0] повертає 1, що тепер є мінімальним елементом (і кореневим вузлом).
>>> nums[0] 1
Можна видаляти елементи з міні-купи, викликаючи функцію heappop(), як показано нижче:
>>> while nums: ... print(heappop(nums)) ...
# Output 1 3 7 8 9 10 11 12
Макс Купи в Python
Тепер, коли ви знаєте про міні-купи, чи можете ви здогадатися, як реалізувати максимальну купу?
Що ж, можна перетворити реалізацію міні-купи в максимальну, помноживши кожне число на -1. Заперечені числа, розташовані в міні-купі, еквівалентні оригінальним числам, розташованим у максимальній купі.
В реалізації на Python можна помножувати елементи на -1, коли вони додаються до купи за допомогою heappush():
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Корневий вузол, помножений на -1, буде максимальним елементом.
>>> -1*maxHeap[0] 7
Видаляючи елементи з купи, використовуйте heappop() і помножте на -1, щоб повернути початкове значення:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Пріоритетні Черги
На завершення обговорення розглянемо структуру даних пріоритетної черги в Python.
Ми знаємо, що в черзі елементи видаляються в тому ж порядку, в якому вони потрапляють до неї. Проте, пріоритетна черга обслуговує елементи відповідно до їхнього пріоритету, що є дуже корисним у таких застосунках, як планування. Таким чином, завжди повертається елемент із найвищим пріоритетом.
Для визначення пріоритету можна використовувати ключі. Тут ми будемо використовувати числові ваги для ключів.
Як реалізувати пріоритетні черги за допомогою Heapq
Ось приклад реалізації пріоритетної черги за допомогою heapq та списку Python:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
Під час видалення елементів, черга спочатку обслужить елемент з найвищим пріоритетом (1, ‘read’), потім (2, ‘write’), і потім (3, ‘code’).
# Output (1, 'read') (2, 'write') (3, 'code')
Як реалізувати пріоритетні черги за допомогою PriorityQueue
Для реалізації пріоритетної черги також можна використовувати клас PriorityQueue з модуля queue. Він також внутрішньо використовує купу.
Ось еквівалентна реалізація пріоритетної черги з використанням PriorityQueue:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'read') (2, 'write') (3, 'code')
Підсумок
В цьому посібнику ви ознайомилися з різноманітними вбудованими структурами даних у Python. Також ми розглянули різноманітні операції, які підтримують ці структури даних, і вбудовані методи для їхнього виконання.
Потім ми розглянули інші структури даних, такі як стеки, черги та пріоритетні черги, та їхню реалізацію в Python з використанням можливостей модуля collections.
Далі пропонуємо ознайомитись зі списком проектів Python, які підходять для початківців.