
Спостерігаючи за розробкою корпоративного програмного забезпечення з першого ряду протягом двох десятиліть, стає очевидним незаперечний тренд останніх кількох років – переміщення баз даних у хмару.
Я вже брав участь у кількох проектах міграції, де метою було перенести наявну локальну базу даних у хмарну базу даних Amazon Web Services (AWS). Хоча з матеріалів документації AWS ви дізнаєтесь, наскільки це може бути легко, я тут, щоб сказати вам, що реалізація такого плану не завжди легка, і бувають випадки, коли він може зазнати невдачі.
У цій публікації я розповім про реальний досвід у такому випадку:
- Джерело: хоча теоретично не має значення, яке ваше джерело (ви можете використовувати дуже схожий підхід для більшості найпопулярніших БД), Oracle був системою баз даних, яку вибирали великі корпоративні компанії протягом багатьох років, і саме на цьому я буду зосереджений.
- Мета: Немає причин для того, щоб бути конкретним з цього боку. Ви можете вибрати будь-яку цільову базу даних в AWS, і підхід все одно підійде.
- Режим: Ви можете мати повне оновлення або поступове оновлення. Пакетне завантаження даних (вихідний і цільовий стани затримуються) або (майже) завантаження даних у реальному часі. Обидва вони будуть торкатися тут.
- Частота. Можливо, вам знадобиться одноразова міграція з подальшим повним переходом на хмару або потрібен певний перехідний період і одночасне оновлення даних з обох сторін, що передбачає розробку щоденної синхронізації між локальною системою та AWS. Перше є простішим і має набагато більше сенсу, але друге запитується частіше і має набагато більше точок переривання. Я розгляну обидва тут.
опис проблеми
Вимога часто проста:
Ми хочемо почати розробляти сервіси всередині AWS, тому скопіюйте всі наші дані в базу даних «ABC». Швидко і просто. Зараз нам потрібно використовувати дані в AWS. Пізніше ми з’ясуємо, які частини дизайну БД потрібно змінити, щоб відповідати нашій діяльності.
Перш ніж йти далі, варто розглянути наступне:
- Не переходьте занадто швидко до ідеї «просто скопіюйте те, що у нас є, і розберіться з цим пізніше». Я маю на увазі, так, це найпростіше, що ви можете зробити, і це буде зроблено швидко, але це потенційно може створити настільки фундаментальну архітектурну проблему, яку неможливо буде виправити пізніше без серйозної рефакторингу більшості нової хмарної платформи . Тільки уявіть, що хмарна екосистема повністю відрізняється від локальної. З часом буде запроваджено кілька нових послуг. Природно, люди почнуть використовувати одне і те ж зовсім по-різному. Копіювати локальний стан у хмарі у форматі 1:1 майже ніколи не є гарною ідеєю. Це може бути у вашому конкретному випадку, але обов’язково ще раз перевірте це.
- Поставте під сумнів вимогу з деякими значущими сумнівами, наприклад:
- Хто буде типовим користувачем нової платформи? На місці він може бути транзакційним бізнес-користувачем; у хмарі це може бути фахівець із обробки даних або аналітик сховища даних, або основним користувачем даних може бути служба (наприклад, Databricks, Glue, моделі машинного навчання тощо).
- Чи очікується, що звичайні повсякденні завдання залишаться навіть після переходу в хмару? Якщо ні, то як вони очікуються змінитися?
- Чи плануєте ви значне зростання даних з часом? Швидше за все, відповідь буде так, оскільки це часто є єдиною найважливішою причиною переходу в хмару. Для цього має бути готова нова модель даних.
- Очікуйте, що кінцевий користувач думатиме про деякі загальні очікувані запити, які нова база даних отримуватиме від користувачів. Це визначить, наскільки існуюча модель даних має змінитися, щоб залишатися релевантною продуктивності.
Налаштування міграції
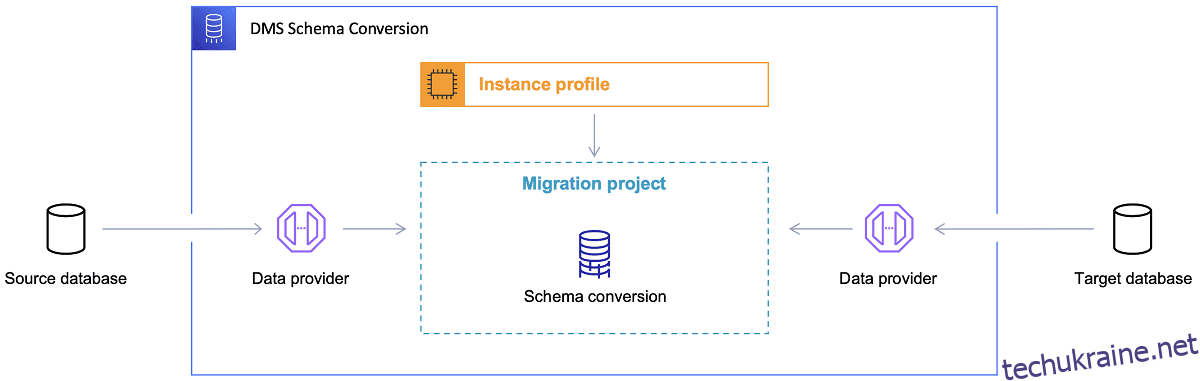
Після вибору цільової бази даних і задовільного обговорення моделі даних наступним кроком є ознайомлення з інструментом перетворення схеми AWS. Є кілька сфер, у яких може використовуватися цей інструмент:
 Посилання: Документація AWS
Посилання: Документація AWS
Тепер є кілька порад щодо використання інструменту перетворення схем.
По-перше, майже ніколи не слід використовувати вихід безпосередньо. Я б вважав це скоріше довідковими результатами, звідки ви повинні вносити свої коригування на основі вашого розуміння та призначення даних і способу використання даних у хмарі.
По-друге, раніше таблиці, ймовірно, вибиралися користувачами, які очікували швидких коротких результатів щодо певної сутності домену даних. Але тепер дані можуть бути відібрані для аналітичних цілей. Наприклад, індекси бази даних, які раніше працювали в локальній базі даних, тепер будуть марними та точно не покращать продуктивність системи БД, пов’язану з цим новим використанням. Так само ви можете розділити дані на цільовій системі по-іншому, як це було раніше на вихідній системі.
Крім того, було б добре розглянути можливість виконання деяких перетворень даних під час процесу міграції, що в основному означає зміну цільової моделі даних для деяких таблиць (щоб вони більше не були копіями 1:1). Пізніше правила трансформації потрібно буде реалізувати в інструменті міграції.
Якщо вихідна та цільова бази даних одного типу (наприклад, Oracle on-premise проти Oracle в AWS, PostgreSQL проти Aurora Postgresql тощо), тоді найкраще використовувати спеціальний інструмент міграції, який конкретна база даних підтримує нативно ( наприклад, експорт та імпорт насосів даних, Oracle Goldengate тощо).
Однак у більшості випадків вихідна та цільова база даних не будуть сумісні, і тоді очевидним інструментом вибору буде служба міграції бази даних AWS.
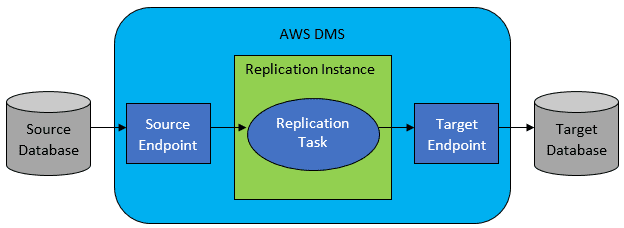 Посилання: Документація AWS
Посилання: Документація AWS
AWS DMS в основному дозволяє налаштувати список завдань на рівні таблиці, який визначатиме:
- Яка точна вихідна БД і таблиця, до яких потрібно підключитися?
- Специфікації операторів, які використовуватимуться для отримання даних для цільової таблиці.
- Інструменти перетворення (якщо такі є), що визначають, як вихідні дані мають бути відображені в дані цільової таблиці (якщо не 1:1).
- Яка точна цільова база даних і таблиця для завантаження даних?
Конфігурація завдань DMS виконується в зручному форматі, наприклад JSON.
Тепер у найпростішому сценарії все, що вам потрібно зробити, це запустити сценарії розгортання в цільовій базі даних і запустити завдання DMS. Але це набагато більше.
Одноразова повна міграція даних

Найпростіший випадок для виконання – це запит на одноразове переміщення всієї бази даних у цільову хмарну базу даних. Тоді в основному все, що необхідно зробити, виглядатиме так:
Якщо конфігурацію DMS виконано правильно, у цьому сценарії нічого поганого не станеться. Кожна вихідна таблиця буде підібрана та скопійована в цільову базу даних AWS. Єдине, що вас хвилює, – продуктивність діяльності та перевірка правильності розміру на кожному кроці, щоб не вийшло з ладу через брак місця для зберігання.
Поступова щоденна синхронізація

Ось де все починає ускладнюватися. Я маю на увазі, якби світ був ідеальним, то він, мабуть, працював би чудово весь час. Але світ ніколи не буває ідеальним.
DMS можна налаштувати для роботи в двох режимах:
- Повне завантаження – режим за замовчуванням, описаний і використаний вище. Завдання DMS запускаються або тоді, коли ви їх запускаєте, або коли їх заплановано. Після завершення завдання DMS виконано.
- Change Data Capture (CDC) – у цьому режимі завдання DMS виконуються безперервно. DMS сканує вихідну базу даних на предмет змін на рівні таблиці. Якщо зміни відбуваються, він негайно намагається відтворити зміни в цільовій базі даних на основі конфігурації всередині завдання DMS, пов’язаного зі зміненою таблицею.
Вибираючи CDC, вам потрібно зробити ще один вибір, а саме, як CDC витягуватиме дельта-зміни з вихідної БД.
#1. Oracle Redo Logs Reader
Одним із варіантів є вибір власного засобу читання журналів повторного виконання бази даних від Oracle, який CDC може використовувати для отримання змінених даних і, на основі останніх змін, відтворити ті самі зміни в цільовій базі даних.
Хоча це може виглядати як очевидний вибір, якщо мати справу з Oracle як джерелом, є підступ: програма для читання журналів Oracle redo використовує вихідний кластер Oracle і таким чином безпосередньо впливає на всі інші дії, що виконуються в базі даних (це фактично безпосередньо створює активні сеанси в база даних).
Чим більше завдань DMS ви налаштували (або більше кластерів DMS паралельно), тим більше вам, імовірно, знадобиться збільшити кластер Oracle – по суті, налаштувати вертикальне масштабування основного кластера бази даних Oracle. Це, безумовно, вплине на загальну вартість рішення, навіть більше, якщо щоденна синхронізація збирається залишатися з проектом протягом тривалого періоду часу.
#2. Майнер журналів AWS DMS
На відміну від варіанту вище, це власне рішення AWS для тієї ж проблеми. У цьому випадку DMS не впливає на вихідну базу даних Oracle. Натомість він копіює журнали повторного виконання Oracle у кластер DMS і виконує всю обробку там. Хоча це економить ресурси Oracle, це повільніше рішення, оскільки задіяно більше операцій. Крім того, як можна легко припустити, спеціальний зчитувач для журналів повторення Oracle, ймовірно, повільніше виконує свою роботу, ніж нативний зчитувач від Oracle.
Залежно від розміру вихідної бази даних і кількості щоденних змін, у найкращому випадку ви можете отримати поступову синхронізацію даних із локальної бази даних Oracle у хмарну базу даних AWS майже в реальному часі.
У будь-якому іншому сценарії синхронізація все одно не буде близькою до реального часу, але ви можете спробувати максимально наблизитися до прийнятної затримки (між джерелом і цільовим каналом), налаштувавши конфігурацію продуктивності вихідного та цільового кластерів і паралелізм або поекспериментувавши з кількість завдань DMS та їх розподіл між інстанціями CDC.
І ви можете дізнатися, які зміни вихідної таблиці підтримуються CDC (наприклад, додавання стовпця), оскільки підтримуються не всі можливі зміни. У деяких випадках єдиним способом є змінити цільову таблицю вручну та перезапустити завдання CDC з нуля (попутно втрачаючи всі існуючі дані в цільовій базі даних).
Коли все йде не так, незважаючи ні на що

Я навчився цьому на важкому шляху, але є один конкретний сценарій, пов’язаний із DMS, коли обіцянку щоденної реплікації важко досягти.
DMS може обробляти журнали повторного виконання лише з певною визначеною швидкістю. Не має значення, чи є більше екземплярів DMS, які виконують ваші завдання. Тим не менш, кожен екземпляр DMS читає журнали повторів лише з однією визначеною швидкістю, і кожен з них повинен читати їх повністю. Навіть не має значення, використовуєте ви Oracle redo logs або AWS log miner. Обидва мають цю межу.
Якщо вихідна база даних містить велику кількість змін протягом дня, що журнали повторного виконання Oracle стають дуже великими (наприклад, більше 500 ГБ) щодня, CDC просто не працюватиме. Тиражування не буде завершено до кінця дня. Це перенесе частину необробленої роботи на наступний день, де вже чекає новий набір змін, які потрібно відтворити. Кількість необроблених даних з кожним днем тільки зростатиме.
У цьому конкретному випадку CDC не був варіантом (після багатьох тестів продуктивності та спроб, які ми виконали). Єдиний спосіб гарантувати, що принаймні всі дельта-зміни поточного дня будуть відтворені в той самий день, полягав у такому підході:
- Відокремте справді великі таблиці, які використовуються не так часто, і повторюйте їх лише раз на тиждень (наприклад, у вихідні).
- Налаштування реплікації не дуже великих, але все одно великих таблиць для розподілу між кількома завданнями DMS; одну таблицю зрештою було переміщено 10 або більше окремими завданнями DMS паралельно, забезпечуючи чіткий розподіл даних між завданнями DMS (тут залучено спеціальне кодування) і їх виконання щодня.
- Додайте більше (у цьому випадку до 4) екземплярів DMS і рівномірно розподіліть завдання DMS між ними, тобто не лише за кількістю таблиць, але й за розміром.
По суті, ми використовували режим повного завантаження DMS для реплікації щоденних даних, оскільки це був єдиний спосіб досягти завершення реплікації даних принаймні в той же день.
Не ідеальне рішення, але воно все ще існує, і навіть через багато років воно все ще працює так само. Отже, можливо, це все-таки не таке вже й погане рішення. 😃