Спостереження за процесом розробки корпоративного програмного забезпечення протягом двох десятиліть чітко демонструє стійку тенденцію останніх років – міграцію баз даних у хмарне середовище.
Я брав участь у кількох проектах міграції, метою яких було перенесення існуючих локальних баз даних до хмарних сервісів Amazon Web Services (AWS). Хоча документація AWS може створювати враження легкості цього процесу, мій досвід показує, що реалізація такого плану не завжди є простою, і в деяких випадках може завершитися невдачею.
У цій статті я поділюся реальним досвідом, набутим у таких ситуаціях:
- Джерело: Хоча теоретично тип джерела не має великого значення (аналогічний підхід можна застосувати до більшості популярних баз даних), Oracle історично була обрана багатьма великими корпораціями. Саме на цьому варіанті я зосереджуся.
- Ціль: Немає необхідності обмежуватися конкретною цільовою базою даних. Ви можете обрати будь-яку цільову базу даних в AWS, і запропонований підхід все одно буде актуальним.
- Режим: Міграція може бути повним оновленням або здійснюватися поступово. Можливе пакетне завантаження даних (з призупиненням роботи вихідної та цільової баз даних) або (майже) завантаження даних у реальному часі. Обидва варіанти будуть розглянуті тут.
- Частота: Іноді потрібна одноразова міграція з подальшим повним переходом у хмару, а іноді – перехідний період з одночасним оновленням даних на обох сторонах, що передбачає щоденну синхронізацію між локальною системою та AWS. Перший варіант простіший і логічніший, але другий запитується частіше і створює більше потенційних проблем. Я розгляну обидва підходи.
Опис проблеми
Запит на міграцію часто формулюється просто:
“Ми хочемо почати розробку сервісів в AWS, тому скопіюйте всі наші дані до бази даних “ABC”. Швидко та легко. Нам потрібно використовувати ці дані в AWS. Пізніше ми визначимо, які частини структури бази даних потрібно змінити для наших потреб.”
Перш ніж продовжити, слід врахувати декілька важливих моментів:
- Не поспішайте з ідеєю “просто скопіюємо як є, а потім розберемося”. Так, це найпростіше рішення і його можна виконати швидко, але воно може створити фундаментальні архітектурні проблеми, які буде важко виправити без серйозного рефакторингу хмарної платформи. Пам’ятайте, що хмарна екосистема кардинально відрізняється від локальної. З часом з’являться нові сервіси, і користувачі почнуть використовувати дані по-іншому. Копіювання локальної структури 1:1 в хмару майже ніколи не є хорошою ідеєю. Можливо, у вашому конкретному випадку це спрацює, але потрібно перевірити це двічі.
- Поставте під сумнів вихідні вимоги, задаючи питання:
- Хто буде основним користувачем нової платформи? Локально це можуть бути транзакційні бізнес-користувачі, а в хмарі – фахівці з обробки даних, аналітики або самі сервіси (наприклад, Databricks, Glue, моделі машинного навчання).
- Чи збережуться звичайні щоденні завдання після переходу в хмару? Якщо ні, то як вони зміняться?
- Чи планується значне зростання обсягу даних? Швидше за все, відповідь буде “так”, оскільки це часто є основною причиною переходу в хмару. Нова модель даних має бути готова до цього.
- Проаналізуйте очікувані запити, які нова база даних отримуватиме від користувачів. Це визначить, наскільки існуюча модель даних потребує змін для забезпечення необхідної продуктивності.
Налаштування міграції
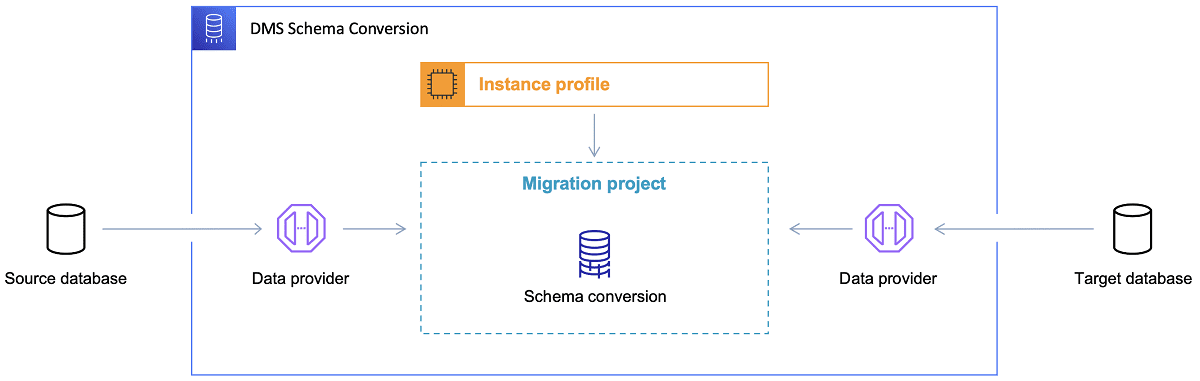
Після вибору цільової бази даних і обговорення моделі даних, наступним кроком є вивчення інструменту перетворення схем AWS. Цей інструмент може бути корисним у наступних аспектах:
- Аналіз та вилучення моделі вихідних даних. SCT зчитує структуру поточної локальної бази даних і створює модель вихідних даних.
- Пропонує цільову структуру моделі даних на основі обраної цільової бази даних.
- Створює сценарії розгортання цільової бази даних для встановлення цільової моделі даних (на основі інформації, отриманої з вихідної бази даних). Після виконання цих сценаріїв база даних у хмарі буде готова до завантаження даних із локальної бази даних.
 Посилання: Документація AWS
Посилання: Документація AWS
Ось декілька порад щодо використання інструменту перетворення схем.
По-перше, майже ніколи не слід використовувати згенерований вихідний код безпосередньо. Розглядайте його як довідковий матеріал, на основі якого ви повинні вносити зміни, ґрунтуючись на розумінні та цілях використання даних у хмарі.
По-друге, раніше вибір таблиць міг базуватися на необхідності швидкого отримання результатів для конкретних сутностей. Тепер дані можуть використовуватися для аналітичних цілей. Наприклад, індекси, які ефективно працювали в локальній базі даних, можуть бути марними у хмарі. Також, ви можете розподілити дані у цільовій системі інакше, ніж це було зроблено у вихідній системі.
Крім того, варто розглянути можливість виконання перетворення даних під час міграції, що означає зміну цільової моделі даних для деяких таблиць (щоб вони не були точними копіями 1:1). Правила трансформації потрібно буде реалізувати в інструменті міграції.
Якщо вихідна та цільова бази даних одного типу (наприклад, Oracle on-premise проти Oracle в AWS, PostgreSQL проти Aurora Postgresql), то найкраще використовувати спеціальні інструменти міграції, які підтримує відповідна база даних (наприклад, експорт та імпорт даних, Oracle Goldengate).
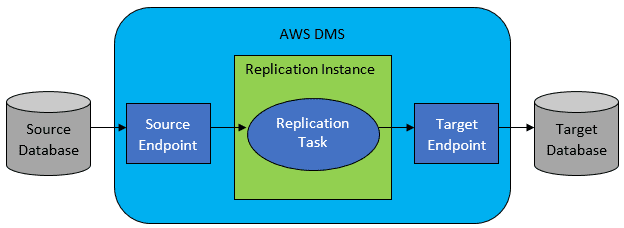
Однак, найчастіше вихідна та цільова бази даних не будуть сумісними, і тоді оптимальним інструментом є сервіс міграції баз даних AWS.
 Посилання: Документація AWS
Посилання: Документація AWS
AWS DMS дозволяє налаштувати список завдань на рівні таблиці, які визначають:
- Точну вихідну базу даних і таблицю, до яких потрібно підключитися.
- Специфікації операцій, які використовуватимуться для вилучення даних для цільової таблиці.
- Інструменти перетворення (якщо вони потрібні), які визначають, як вихідні дані повинні бути відображені в дані цільової таблиці (якщо не 1:1).
- Точну цільову базу даних і таблицю для завантаження даних.
Конфігурація завдань DMS виконується в зручному форматі, наприклад JSON.
У найпростішому випадку достатньо запустити сценарії розгортання у цільовій базі даних і запустити завдання DMS. Але на практиці все складніше.
Одноразова повна міграція даних

Найпростіший випадок – це одноразове перенесення всієї бази даних до цільової хмарної бази даних. Процес міграції виглядає так:
- Визначте завдання DMS для кожної вихідної таблиці.
- Переконайтеся, що конфігурація завдань DMS налаштована правильно. Це означає налаштування паралелізму, кешування, конфігурацію сервера DMS, розмір кластера DMS тощо. Це, як правило, найскладніший етап, оскільки вимагає ретельного тестування для досягнення оптимального стану.
- Переконайтеся, що кожна цільова таблиця створена (порожня) у цільовій базі даних з очікуваною структурою.
- Заплануйте часове вікно для виконання міграції. Переконайтеся (з допомогою тестів продуктивності), що цього часу буде достатньо для завершення міграції. Під час міграції продуктивність вихідної бази даних може бути обмежена. Також очікується, що вихідна база даних не буде змінюватися під час міграції. Інакше дані, які будуть перенесені, можуть відрізнятися від даних у вихідній базі даних після завершення міграції.
Якщо конфігурацію DMS налаштовано правильно, у цьому сценарії нічого поганого не повинно статися. Кожна вихідна таблиця буде скопійована до цільової бази даних AWS. Єдине, про що варто турбуватися – це продуктивність процесу та впевненість, що на кожному кроці достатньо вільного місця.
Поступова щоденна синхронізація

Тут ситуація стає складнішою. Якби все було ідеально, то все б працювало без проблем, але реальність далека від ідеалу.
DMS можна налаштувати для роботи у двох режимах:
- Повне завантаження – режим за замовчуванням, описаний вище. Завдання DMS виконуються або при запуску, або за розкладом. Після завершення завдання DMS зупиняється.
- Change Data Capture (CDC) – у цьому режимі завдання DMS працюють безперервно. DMS постійно відстежує зміни у вихідній базі даних на рівні таблиць. Якщо виявляються зміни, DMS негайно намагається відтворити ці зміни в цільовій базі даних, відповідно до конфігурації завдання DMS.
При виборі CDC потрібно зробити ще один вибір: як CDC вилучатиме дельта-зміни з вихідної БД.
#1. Oracle Redo Logs Reader
Один із варіантів – використовувати власний інструмент читання журналів повторного виконання бази даних Oracle, який CDC може використовувати для вилучення змінених даних і відтворення їх у цільовій базі даних.
Хоча це може здаватися очевидним вибором при роботі з Oracle, є важливий нюанс: читач журналів Oracle redo використовує ресурси вихідного кластера Oracle, що безпосередньо впливає на всі інші дії, які виконуються в базі даних (фактично, це створює додаткові активні сеанси в базі даних).
Чим більше завдань DMS ви налаштуєте (або чим більше кластерів DMS працює паралельно), тим більші ресурси, ймовірно, вам знадобиться виділити кластеру Oracle – по суті, вам потрібно буде виконати вертикальне масштабування основного кластера бази даних Oracle. Це, безумовно, вплине на загальну вартість рішення, особливо якщо щоденна синхронізація буде постійним елементом проекту.
#2. Майнер журналів AWS DMS
На відміну від попереднього варіанту, це власне рішення AWS для тієї ж проблеми. У цьому випадку DMS не впливає на вихідну базу даних Oracle. Натомість він копіює журнали повторного виконання Oracle у кластер DMS і виконує обробку там. Хоча це економить ресурси Oracle, це повільніше рішення, оскільки задіяно більше операцій. Крім того, спеціальний зчитувач для журналів повторного виконання Oracle, ймовірно, виконує свою роботу повільніше, ніж нативний зчитувач від Oracle.
Залежно від розміру вихідної бази даних і кількості щоденних змін, у кращому випадку можна досягти поступової синхронізації даних із локальної бази даних Oracle у хмарну базу даних AWS майже в реальному часі.
У будь-якому іншому випадку синхронізація не буде близькою до реального часу, але ви можете спробувати максимально наблизитися до прийнятної затримки (між джерелом і цільовим каналом), налаштувавши конфігурацію продуктивності вихідного та цільового кластерів і паралелізм, або шляхом експериментів з кількістю завдань DMS та їх розподілом між інстанціями CDC.
Також, слід враховувати, які зміни структури вихідної таблиці підтримуються CDC (наприклад, додавання стовпця), оскільки підтримуються не всі зміни. У деяких випадках єдиний спосіб виправити проблему – це вручну змінити цільову таблицю і перезапустити завдання CDC з нуля (при цьому ви втратите всі наявні дані в цільовій базі даних).
Коли все йде не так, незважаючи ні на що

Мій досвід показує, що існує один специфічний сценарій, пов’язаний з DMS, коли щоденна реплікація стає важкодосяжною.
DMS може обробляти журнали повторного виконання тільки з певною визначеною швидкістю. Не має значення, скільки екземплярів DMS виконують ваші завдання. Кожен екземпляр DMS читає журнали повторення з обмеженою швидкістю, і кожен з них повинен читати їх повністю. Не має значення, чи використовуєте ви Oracle redo logs, чи AWS log miner. Обидва рішення мають це обмеження.
Якщо вихідна база даних генерує велику кількість змін протягом дня, і розмір журналів повторного виконання Oracle стає дуже великим (наприклад, понад 500 ГБ) щодня, CDC просто не працюватиме. Реплікація не буде завершена до кінця дня. Необроблена робота переноситься на наступний день, де вже чекає новий набір змін. Обсяг необроблених даних буде тільки зростати.
У цьому конкретному випадку CDC не був варіантом (після багатьох тестів продуктивності). Єдиний спосіб гарантувати, що хоча б усі дельта-зміни поточного дня будуть відтворені в той же день, полягав у такому підході:
- Виділити великі таблиці, які не так часто використовуються, і реплікувати їх лише раз на тиждень (наприклад, у вихідні).
- Налаштувати реплікацію великих таблиць, розподіливши їх між декількома завданнями DMS. В одному випадку таблицю було перенесено 10 або більше окремими завданнями DMS паралельно, забезпечуючи чіткий розподіл даних між завданнями (за допомогою спеціального кодування) і їх щоденне виконання.
- Додати більше (у цьому випадку до 4) екземплярів DMS і рівномірно розподілити завдання DMS між ними, зважаючи не тільки на кількість таблиць, але і на їх розмір.
Фактично, для реплікації щоденних даних ми використовували режим повного завантаження DMS, оскільки це був єдиний спосіб гарантувати завершення реплікації даних принаймні в той же день.
Це не ідеальне рішення, але воно працює і навіть через багато років залишається актуальним. Тому, можливо, це не так вже й погано. 😃