Llama 2 – це потужна мовна модель з відкритим вихідним кодом, розроблена компанією Meta. Вона є високоефективною мовною моделлю, яка у певних аспектах може перевершувати деякі закриті моделі, наприклад GPT-3.5 та PaLM 2. Llama 2 представлена в трьох варіантах з різною кількістю параметрів: 7 мільярдів, 13 мільярдів та 70 мільярдів. В даній статті розглянемо, як використати її для створення інтерактивного чат-бота.
В цій статті ви дізнаєтесь, як розкрити розмовний потенціал Llama 2, розробивши чат-бота за допомогою Streamlit та самої Llama 2.
Знайомство з Llama 2: Характеристики та Переваги
Чим саме Llama 2 відрізняється від попередньої мовної моделі Llama 1?
- Масштабована архітектура: модель використовує до 70 мільярдів параметрів. Завдяки цьому вона здатна глибше аналізувати та встановлювати зв’язки між словами та реченнями.
- Покращені можливості діалогу: завдяки використанню Reinforcement Learning from Human Feedback (RLHF), модель демонструє покращені розмовні навички. Це дозволяє генерувати природний та зрозумілий контент навіть у складних діалогах.
- Прискорений процес висновування: впровадження нової методики, групового запиту уваги, прискорює процес висновування. Це робить її більш пристосованою до створення таких інструментів, як чат-боти та віртуальні асистенти.
- Ресурсоефективність: Llama 2 є більш ефективною в плані використання пам’яті та обчислювальних ресурсів, порівняно з попередньою версією.
- Відкритий вихідний код та некомерційна ліцензія: модель доступна для використання та модифікацій дослідниками та розробниками без обмежень, що сприяє її широкому застосуванню.
Llama 2 значно перевершує свого попередника за всіма показниками. Ці вдосконалення роблять її потужним інструментом для широкого спектру застосувань, включаючи чат-боти, віртуальних асистентів та обробку природної мови.
Налаштування середовища Streamlit для розробки чат-бота
Перед початком розробки, необхідно налаштувати ізольоване середовище, щоб уникнути конфліктів між різними проєктами.
Спершу, створіть віртуальне середовище за допомогою бібліотеки Pipenv:
pipenv shell
Далі, встановіть необхідні бібліотеки для розробки чат-бота:
pipenv install streamlit replicate
Streamlit – це відкритий фреймворк, який спрощує створення веб-додатків для машинного навчання та обробки даних.
Replicate – це хмарна платформа, яка надає доступ до великих моделей машинного навчання з відкритим вихідним кодом для їх розгортання.
Отримання API токена Llama 2 від Replicate
Для отримання токена API від Replicate, вам потрібно спочатку зареєструватися на Replicate, використовуючи ваш GitHub акаунт.
Після входу в особистий кабінет, перейдіть до розділу «Дослідити» та знайдіть чат Llama 2, зокрема модель llama-2–70b.
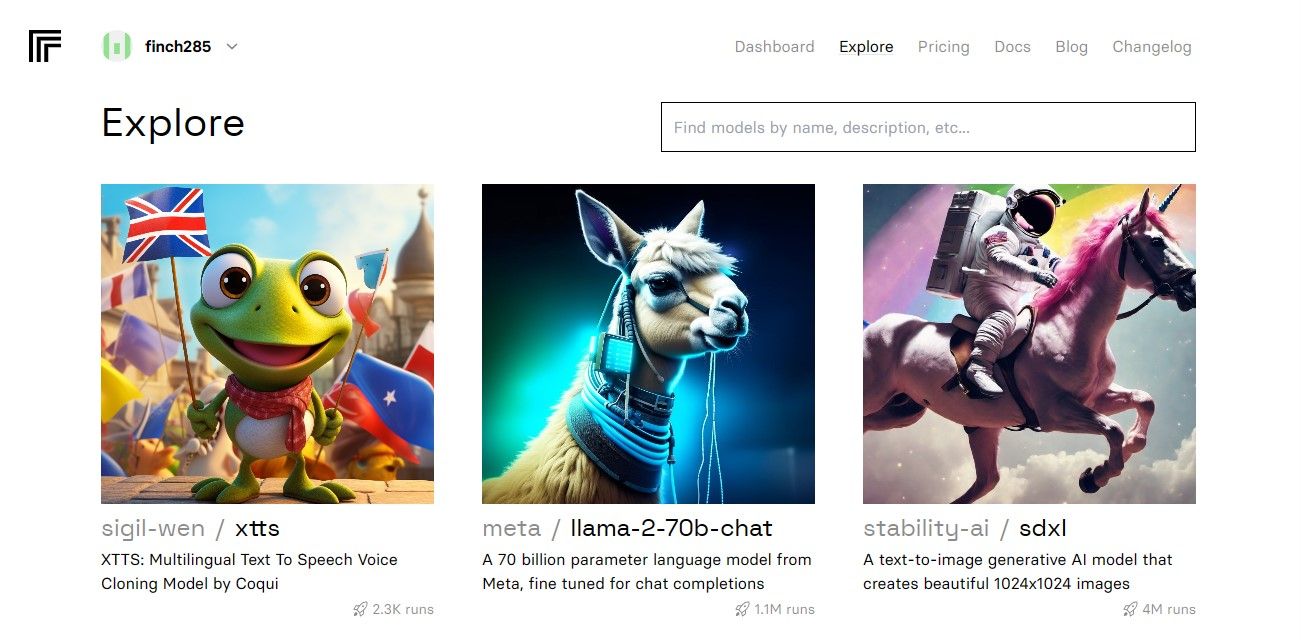
Клікніть на модель llama-2–70b-chat, щоб переглянути кінцеві точки API. Перейдіть у вкладку API на панелі навігації. З правого боку виберіть Python, щоб отримати доступ до токена API для розробки на Python.
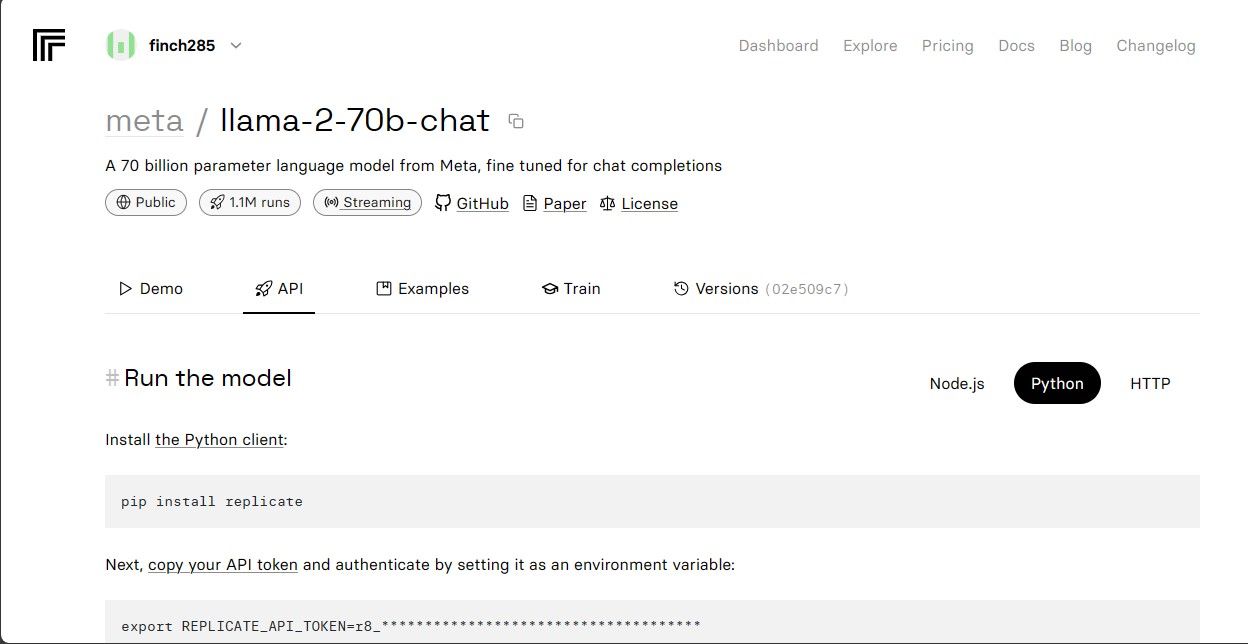
Скопіюйте `REPLICATE_API_TOKEN` та збережіть його для подальшого використання.
Розробка Чат-бота
Створіть файл Python з назвою `llama_chatbot.py` та файл `.env`. Код буде розміщено у `llama_chatbot.py`, а секретні ключі та API токени у `.env`.
У файлі `llama_chatbot.py`, імпортуйте необхідні бібліотеки, як показано нижче:
import streamlit as st
import os
import replicate
Далі, встановіть глобальні змінні для моделі llama-2–70b-chat.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
У файлі `.env`, додайте ваш Replicate токен та кінцеві точки моделей у наступному форматі:
REPLICATE_API_TOKEN='Ваш_Replicate_Токен'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Вставте токен реплікації та збережіть файл `.env`.
Проектування Логіки Діалогу Чат-бота
Створіть початковий промпт для моделі Llama 2, залежно від задачі, яку необхідно виконати. У даному випадку, модель повинна виступати в ролі асистента.
PRE_PROMPT = "Ти – корисний асистент. Твої відповіді ніколи не починаються як 'Користувач', і ти не імітуєш 'Користувача'." \
" Ти завжди відповідаєш лише один раз, як Асистент."
Налаштуйте конфігурацію сторінки вашого чат-бота:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Створіть функцію, яка ініціалізує та встановлює змінні стану сесії.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Виберіть модель LLaMA2:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Ця функція ініціалізує такі важливі змінні як `chat_dialogue`, `pre_prompt`, `llm`, `top_p`, `max_seq_len` і `temperature` у стані сесії. Вона також обробляє вибір моделі Llama 2 на основі користувацького вибору.
Напишіть функцію для відображення вмісту бічної панелі застосунку Streamlit.
def render_sidebar():
st.sidebar.header("Чат-бот LLaMA2")
st.session_state['temperature'] = st.sidebar.slider('Температура:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Максимальна довжина послідовності:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Промпт перед початком чату. Змініть, якщо необхідно:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Ця функція відображає заголовок та змінні налаштування чат-бота Llama 2 для коригування.
Напишіть функцію, що відображає історію чату в головній області вмісту застосунку Streamlit.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Функція перебирає `chat_dialogue`, збережений у стані сесії, відображаючи кожне повідомлення з відповідною роллю (користувач або помічник).
Обробляйте користувацьке введення за допомогою наступної функції:
def handle_user_input():
user_input = st.chat_input(
"Введіть ваше запитання для спілкування з LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Ця функція надає поле введення для користувачів, куди вони можуть вводити свої повідомлення та запитання. Повідомлення додається до `chat_dialogue` у стані сесії, з роллю “користувач”, після того як користувач надішле повідомлення.
Створіть функцію, яка генерує відповіді від моделі Llama 2 та відображає їх у зоні чату.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "Користувач" if dict_message["role"] == "user" else "Асистент"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Асистент: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Ця функція створює рядок історії розмови, що містить повідомлення користувача та помічника, перед тим як викликати функцію `debounce_replicate_run` для отримання відповіді помічника. Вона постійно оновлює відповідь в інтерфейсі користувача для забезпечення чату в реальному часі.
Напишіть основну функцію, яка відповідає за відтворення всього застосунку Streamlit.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Вона викликає усі визначені функції для налаштування стану сесії, візуалізації бічної панелі, історії чату, обробки введених користувачем даних та створення відповідей помічника у логічному порядку.
Створіть функцію для виклику `render_app` і запуску застосунку під час виконання скрипту.
def main():
render_app()if __name__ == "__main__":
main()
Наразі ваш застосунок має бути готовим до запуску.
Обробка API Запитів
Створіть файл `utils.py` у каталозі проєкту та додайте наступну функцію:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Час останнього виклику: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Затримка запиту")
return "Привіт! Ваші запити надто швидкі. Будь ласка, зачекайте декілька " \
"секунд перед відправленням ще одного запиту."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Асистент: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Ця функція реалізує механізм зменшення дребезгу для запобігання надмірно частим API запитам від користувача.
Далі, імпортуйте функцію `debounce_replicate_run` у файл `llama_chatbot.py` наступним чином:
from utils import debounce_replicate_run
Тепер запустіть застосунок:
streamlit run llama_chatbot.py
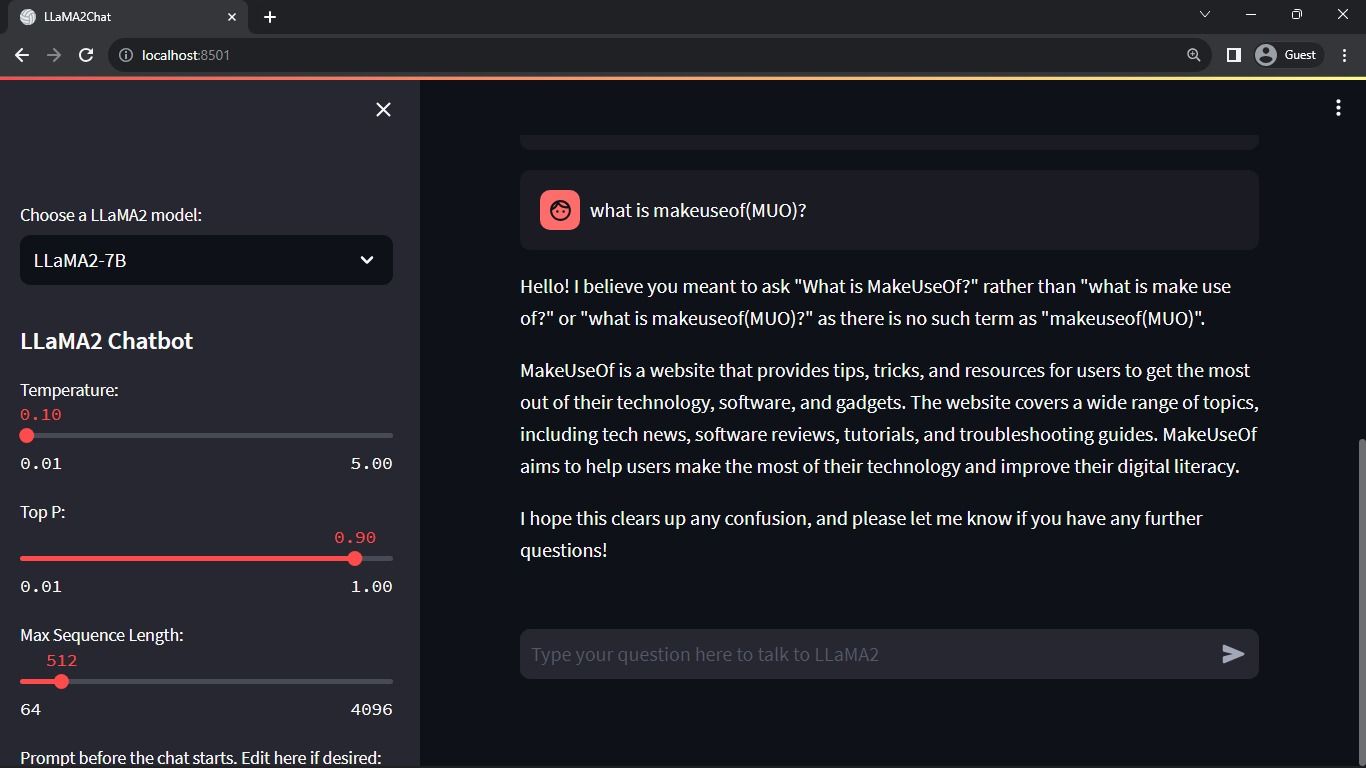
Очікуваний результат:
Результат показує діалог між моделлю та людиною.
Реальні Застосування Чат-ботів на Streamlit та Llama 2
Деякі приклади застосування Llama 2 у реальному світі:
- Чат-боти: створення чат-ботів для інтерактивної комунікації з користувачами на різноманітні теми.
- Віртуальні помічники: розробка віртуальних асистентів, які розуміють запити природною мовою та надають відповідну допомогу.
- Мовний переклад: виконання задач мовного перекладу з високою точністю.
- Зведення тексту: створення коротких резюме з великих текстових масивів для швидкого сприйняття.
- Дослідження: використання Llama 2 для дослідницьких цілей, отримуючи відповіді на питання з різних областей знань.
Майбутнє Штучного Інтелекту
В умовах, коли існують такі закриті моделі як GPT-3.5 та GPT-4, невеликим розробникам стає важко створювати значущі проєкти з використанням LLM через високу вартість доступу до API моделей GPT.
Відкриття таких передових великих мовних моделей, як Llama 2, для спільноти розробників є початком нової ери в ШІ. Це стимулюватиме більш креативне та інноваційне впровадження моделей у реальні застосунки, сприяючи прискореному розвитку до штучного суперінтелекту (ASI).