

Якщо ви вивчили кілька мов комп’ютерного програмування, можливо, ви чули термін синтаксичний аналіз тексту. Це використовується для спрощення складних значень даних у файлі. Стаття допоможе вам зрозуміти, як розбирати текст за допомогою мови. На додаток до цього, якщо ви зіткнулися з помилкою аналізу тексту x, ви будете знати, як виправити помилку аналізу в статті.

Як розібрати текст
У цій статті ми показали повний посібник із розбору тексту різними способами, а також коротко дали введення в розбір тексту.
Що таке аналіз тексту?
Перш ніж заглибитися, вивчити концепції розбору тексту за допомогою будь-якого коду. Важливо знати про основи мови та кодування.
НЛП або обробка природної мови
Для аналізу тексту використовується обробка природної мови або NLP, яка є підполем домену штучного інтелекту. Мова Python, яка є однією з мов, які належать до категорії, використовується для аналізу тексту.
Коди NLP дозволяють комп’ютерам розуміти та обробляти людські мови, щоб зробити їх придатними для різноманітних програм. Щоб застосувати до мови методи ML або Machine Learning, неструктуровані текстові дані потрібно перетворити на структуровані табличні дані. Для завершення аналізу використовується мова Python для зміни програмних кодів.
Що таке аналіз тексту?
Розбір тексту просто означає перетворення даних з одного формату в інший. Формат, у якому зберігається файл, має бути проаналізований або перетворений у файл в іншому форматі, щоб користувач міг використовувати його в різних програмах.
- Іншими словами, процес означає аналіз рядка або тексту та перетворення в логічні компоненти шляхом зміни формату файлу.
- Деякі правила мови Python використовуються для виконання цього звичайного завдання програмування. Під час аналізу тексту задана серія тексту розбивається на більш дрібні компоненти.
Які причини для аналізу тексту?
У цьому розділі наведено причини, через які текст потрібно розібрати, і це є передумовою для того, щоб знати, як розбирати текст.
- Усі комп’ютеризовані дані не будуть мати однаковий формат і можуть відрізнятися залежно від різних програм.
- Формати даних відрізняються для різних програм, і несумісний код може призвести до цієї помилки.
- Окремої універсальної комп’ютерної програми для відбору даних усіх форматів даних не існує.
Спосіб 1: через клас DataFrame
Клас DataFrame мови Python має всі необхідні функції для аналізу тексту. Ця вбудована бібліотека містить необхідні коди для аналізу даних будь-якого формату в інший формат.
Короткий вступ до класу DataFrame
DataFrame Class — це багатофункціональна структура даних, яка використовується як інструмент аналізу даних. Це потужний інструмент аналізу даних, який можна використовувати для аналізу даних з мінімальними зусиллями.
- Код зчитується в pandas DataFrame для виконання аналізу мовою Python.
- Class поставляється з численними пакетами, наданими pandaми, які використовуються аналітиками даних Python.
- Особливістю цього класу є абстракція, код, в якому внутрішня функціональність функції прихована від користувачів, бібліотеки NumPy. Бібліотека NumPy — це бібліотека Python, яка містить команди та функції для роботи з масивами.
- Клас DataFrame можна використовувати для візуалізації двовимірного масиву з кількома індексами рядків і стовпців. Ці індекси допомагають зберігати багатовимірні дані, тому їх називають MultiIndex. Їх потрібно змінити, щоб знати, як виправити помилку аналізу.
Панди мови Python допомагають виконувати операції SQL або бази даних з максимальною досконалістю, щоб уникнути помилок під час аналізу тексту x. Він також містить деякі інструменти введення-виведення, які допомагають аналізувати файли CSV, MS Excel, JSON, HDF5 та інших форматів даних.
Процес розбору тексту за допомогою класу DataFrame
Щоб знати, як аналізувати текст, ви можете скористатися стандартним процесом із використанням класу DataFrame, наведеного в цьому розділі.
- Розшифруйте формат вхідних даних.
- Визначте вихідні дані даних, наприклад CSV або значення, розділені комами.
- Напишіть у код примітивний тип даних, наприклад list або dict.
Примітка. Написання коду на порожньому DataFrame може бути виснажливим і складним. Pandas дозволяє створювати дані в класі DataFrame з цих типів даних. Отже, дані в примітивному типі даних можна легко проаналізувати до необхідного формату даних.
- Проаналізуйте дані за допомогою інструменту аналізу даних pandas DataFrame та надрукуйте результат.
Варіант I: стандартний формат
Тут пояснюється стандартний метод форматування будь-якого файлу з певним форматом даних, наприклад CSV.
- Збережіть файл зі значеннями даних локально на вашому ПК. Наприклад, ви можете назвати файл data.txt.
- Імпортуйте файл у pandas із певною назвою та імпортуйте дані в іншу змінну. Наприклад, панди мови імпортуються в назву pd у наданому коді.
- Імпорт повинен мати повний код із детальною інформацією про назву вхідного файлу, функцію та формат вхідного файлу.
Примітка. Тут змінна res використовується для виконання функції читання даних у файлі data.txt за допомогою панд, імпортованих у pd. Формат даних вхідного тексту вказується у форматі CSV.
- Викличте вказаний тип файлу та проаналізуйте проаналізований текст у надрукованому результаті. Наприклад, команда res після виконання командного рядка допоможе надрукувати розібраний текст.
Нижче наведено приклад коду описаного вище процесу, який допоможе зрозуміти, як аналізувати текст.
import pandas as pd res = pd.read_csv(‘data.txt’) res
У цьому випадку, якщо ви введете значення даних у файл data.txt, наприклад [1,2,3]його буде проаналізовано та відображено як 1 2 3.
Варіант II: Струнковий метод
Якщо текст, наданий коду, містить лише рядки або буквені символи, спеціальні символи в рядку, такі як коми, пробіли тощо, можна використовувати для розділення та аналізу тексту. Процес подібний до звичайних внутрішніх операцій із рядками. Щоб дізнатися, як виправити помилку синтаксичного аналізу, ви повинні виконати процес синтаксичного аналізу тексту за допомогою цього параметра, який пояснюється нижче.
- Дані витягуються з рядка, і всі спеціальні символи, які розділяють текст, зазначаються.
Наприклад, у наведеному нижче коді визначено спеціальні символи в рядку my_string, якими є ‘,’ і ‘:’. Цей процес потрібно виконувати обережно, щоб уникнути помилок у аналізі тексту x.
- Текст у рядку розбивається окремо на основі значень і позиції спеціальних символів.
Наприклад, рядок розбивається на текстові значення даних на основі спеціальних символів, ідентифікованих за допомогою команди split.
- Значення даних рядка друкуються окремо як проаналізований текст. Тут інструкція print використовується для друку проаналізованого значення даних тексту.
Зразок коду описаного вище процесу наведено нижче.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
У цьому випадку результат проаналізованого рядка відображатиметься, як показано нижче.
Names: [‘Tech’, ‘computer’]
Щоб отримати кращу ясність і знати, як аналізувати текст, використовуючи рядковий текст, використовується цикл for і код змінюється наступним чином.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
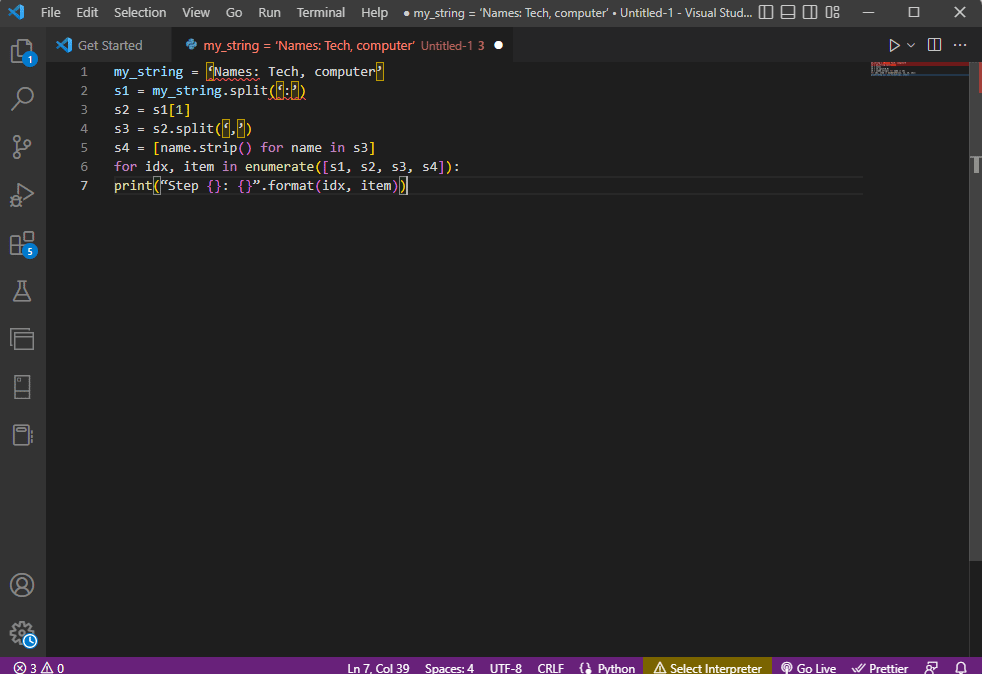
Результат аналізу тексту для кожного з цих кроків відображається, як наведено нижче. Ви можете зауважити, що на кроці 0 рядок відокремлено на основі спеціального символу: і значення текстових даних розділено на основі символу на наступних кроках.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Варіант III: Розбір складного файлу
У більшості випадків дані файлу, які потрібно проаналізувати, містять різні типи даних і значення даних. У цьому випадку може бути важко проаналізувати файл за допомогою описаних раніше методів.
Особливості аналізу складних даних у файлі полягають у відображенні значень даних у табличному форматі.
- Заголовок або метадані значень друкуються у верхній частині файлу,
- Змінні та поля виводяться у вивід у табличній формі та
- Значення даних утворюють складений ключ.
Перш ніж заглибитися в вивчення того, як розбирати текст за допомогою цього методу, необхідно вивчити кілька основних понять. Розбір значень даних виконується на основі регулярних виразів або регулярних виразів.
Шаблони регулярних виразів
Щоб знати, як виправити помилку синтаксичного аналізу, ви повинні переконатися, що шаблони регулярних виразів у виразах правильні. Код для аналізу значень даних рядків включатиме загальні шаблони регулярних виразів, перелічені нижче в цьому розділі.
-
‘d’ : відповідає десятковій цифрі в рядку,
-
‘s’ : відповідає символу пропуску,
-
‘w’: відповідає буквено-цифровому символу,
-
‘+’ або ‘*’: виконує жадібний збіг, збігаючи один або більше символів у рядках,
-
‘a-z’ : відповідає групам нижніх літер у значеннях текстових даних,
-
‘A-Z’ або ‘a-z’: відповідає групам верхнього та нижнього регістру рядка, а також
-
‘0-9’ : відповідає числовим значенням.
Регулярні вирази
Модулі регулярних виразів є основною частиною пакета pandas у мові Python, і неправильний re може призвести до помилки аналізу тексту x. Це маленька мова, вбудована в Python, щоб знайти шаблон рядка у виразі. Регулярні вирази або Regex — це рядки зі спеціальним синтаксисом. Це дозволяє користувачеві зіставляти шаблони в інших рядках на основі значень у рядках.
Регулярний вираз створюється на основі типу даних і вимоги до виразу в рядку, наприклад «Рядок = (.*)n. Регулярний вираз використовується перед шаблоном у кожному виразі. Символи, які використовуються в регулярних виразах, перераховані нижче, і вони допоможуть зрозуміти, як аналізувати текст.
-
. : для отримання будь-якого символу з даних,
-
* : використовувати нуль або більше даних із попереднього виразу,
-
(.*) : щоб згрупувати частину регулярного виразу в дужках,
-
n : створити новий символ рядка в кінці рядка в коді,
-
d : створити коротке інтегральне значення в діапазоні від 0 до 9,
-
+ : використовувати одне або кілька даних із попереднього виразу та
-
| : створювати логічне висловлювання; використовується для або виразів.
RegexObjects
RegexObject є значенням, що повертається функцією компіляції, і використовується для повернення MatchObject, якщо вираз відповідає значенню відповідності.
1. MatchObject
Оскільки логічне значення MatchObject завжди дорівнює True, ви можете використовувати оператор if для ідентифікації позитивних збігів в об’єкті. У разі використання оператора if група, на яку посилається індекс, використовується для визначення збігу об’єкта у виразі.
-
group() повертає одну або більше підгруп відповідності,
-
group(0) повертає повний збіг,
-
group(1) повертає першу підгрупу в дужках, і
- Посилаючись на кілька груп, ми повинні використовувати спеціальне розширення python. Це розширення використовується для вказівки назви групи, у якій потрібно знайти збіг. Конкретне розширення вказано в групі в дужках. Наприклад, вираз (?P
regex1) посилатиметься на певну групу з іменем group1 і перевірятиме збіг у регулярному виразі regex1. Щоб дізнатися, як виправити помилку синтаксичного аналізу, ви повинні перевірити, чи група вказана правильно.
2. Методи MatchObject
Знаходячись, як аналізувати текст, важливо знати, що MatchObject має два основні методи, перелічені нижче. Якщо MatchObject знайдено у вказаному виразі, він повертає його екземпляр, інакше повертає None.
- Метод match(string) використовується для пошуку збігів рядка на початку регулярного виразу
- Метод search(string) використовується для сканування рядка, щоб знайти місце збігу в регулярному виразі.
Функції регулярних виразів
Регулярні вирази – це рядки коду, які використовуються для виконання певної функції, визначеної користувачем із набору отриманих значень даних.
Примітка. Щоб написати функції, необроблені рядки використовуються для регулярних виразів, щоб уникнути помилок у синтаксичному аналізі тексту x. Це робиться шляхом додавання нижнього індексу r перед кожним шаблоном у виразі.
Загальні функції, які використовуються у виразах, пояснюються нижче.
1. re.findall()
Ця функція повертає всі шаблони в рядку, якщо збіг знайдено, і повертає порожній список, якщо збігів не знайдено. Наприклад, функція string = re.findall(‘[aeiou]’, regex_filename) використовується для пошуку входження голосної в назві файлу.
2. re.split()
Ця функція використовується для поділу рядка у разі виявлення збігу з указаним символом, наприклад пробілом. Якщо збігів не знайдено, повертається порожній рядок.
3. re.sub()
Функція замінює відповідний текст вмістом наданої змінної заміни. На відміну від інших функцій, якщо шаблон не знайдено, повертається оригінальний рядок.
4. re.search()
Однією з основних функцій, які допомагають навчитися розбирати текст, є функція пошуку. Це допомагає шукати шаблон у рядку та повертати відповідний об’єкт. Якщо під час пошуку не вдається знайти збіг, значення не повертається.
5. re.compile(шаблон)
Ця функція використовується для компіляції шаблонів регулярних виразів у RegexObject, який обговорювався раніше.
Інші вимоги
Перелічені вимоги є додатковою функцією, яку використовують досвідчені програмісти під час аналізу даних.
- Для візуалізації регулярного виразу використовується регулярний вираз і
- Щоб перевірити регулярний вираз, використовується regex101.
Процес розбору тексту
Метод аналізу тексту в цій складній опції описаний нижче.
- Найважливішим кроком є розуміння формату введення шляхом читання вмісту файлу. Наприклад, функції with open і read() використовуються для відкриття та читання вмісту файлу під назвою sample. Файл зразка містить вміст із файлу file.txt; щоб дізнатися, як виправити помилку аналізу, файл потрібно прочитати повністю.
- Вміст файлу друкується, щоб проаналізувати дані вручну та знайти метадані значень. Тут функція print() використовується для друку вмісту файлу зразка.
- Необхідні пакети даних для аналізу тексту імпортуються в код, а класу присвоюється ім’я для подальшого кодування. Тут імпортуються регулярні вирази та панди.
- Регулярні вирази, необхідні для коду, визначені у файлі шляхом включення шаблону регулярного виразу та функції регулярного виразу. Це дозволяє текстовому об’єкту або корпусу брати код для аналізу даних.
- Щоб дізнатися, як аналізувати текст, ви можете звернутися до наведеного тут прикладу коду. Функція compile() використовується для компіляції рядка з групи stringname1 файлу filename. Функція перевірки збігів у регулярному виразі використовується командою ief_parse_line(line),
- Парсер рядка для коду написаний за допомогою def_parse_file(filepath), у якому визначена функція перевіряє всі збіги регулярних виразів у вказаній функції. Тут метод regex search() шукає ключ rx в назві файлу та повертає ключ і збіг першого відповідного регулярного виразу. Будь-яка проблема з кроком може призвести до помилки аналізу тексту x.
- Наступним кроком є написання аналізатора файлів за допомогою функції аналізатора файлів, яка є def_parse_file(filepath). Для збору даних коду створюється порожній список, як data = []відповідність перевіряється в кожному рядку за допомогою match = _parse_line(line), і точні дані про значення повертаються на основі типу даних.
- Щоб отримати число та значення для таблиці, використовується команда line.strip().split(‘,’). Команда row{} використовується для створення словника з рядком даних. Команда data.append(row) використовується для розуміння даних і аналізу їх у табличному форматі.
Команда data = pd.DataFrame(data) використовується для створення pandas DataFrame зі значень dict. Крім того, ви можете використовувати наступні команди для відповідних цілей, як зазначено нижче.
-
data.set_index([‘string’, ‘integer’]inplace=True), щоб встановити індекс таблиці.
-
data = data.groupby(level=data.index.names).first() для консолідації та видалення nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) для оновлення оцінки з числа з плаваючою точкою до цілого.
Останнім кроком, щоб дізнатися, як аналізувати текст, є тестування синтаксичного аналізатора за допомогою оператора if, присвоюючи значення змінним даним і друкуючи їх за допомогою команди print(data).
Приклад коду для пояснення вище наведено тут.
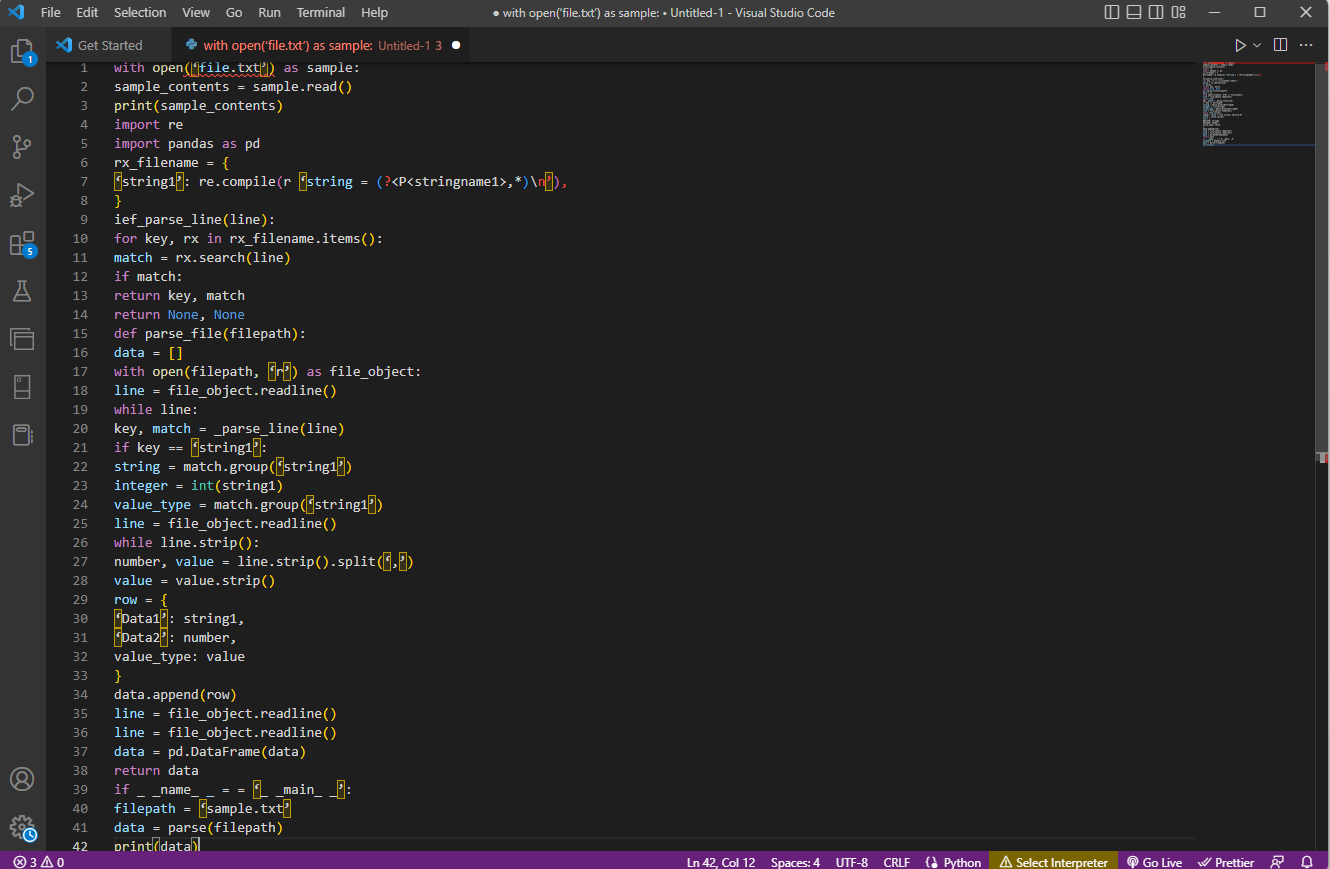
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Спосіб 2: через токенізацію Word
Процес перетворення тексту або корпусу в токени або менші фрагменти на основі певних правил називається токенізація. Щоб дізнатися, як виправити помилку аналізу, важливо проаналізувати команди токенізації слів у коді. Подібно до регулярного виразу, у цьому методі можна створювати власні правила, і це допомагає виконувати завдання попередньої обробки тексту, наприклад зіставлення частин мови. Крім того, у цьому методі виконуються такі дії, як пошук і зіставлення загальних слів, очищення тексту та підготовка даних для розширених методів аналізу тексту, таких як аналіз настроїв. Якщо токенізація неправильна, може виникнути помилка аналізу тексту x.
Бібліотека Ntlk
Цей процес використовує популярну бібліотеку мовних інструментів під назвою nltk, яка має багатий набір функцій для виконання багатьох завдань NLP. Їх можна завантажити за допомогою пакетів Pip або Pip Installs. Щоб знати, як аналізувати текст, ви можете скористатися базовим пакетом дистрибутива Anaconda, який містить бібліотеку за замовчуванням.
Форми токенізації
Поширеними формами цього методу є токенізація слів і токенізація речень. Завдяки лексемі на рівні слова перший друкує одне слово лише один раз, тоді як другий друкує слово на рівні речення.
Процес розбору тексту
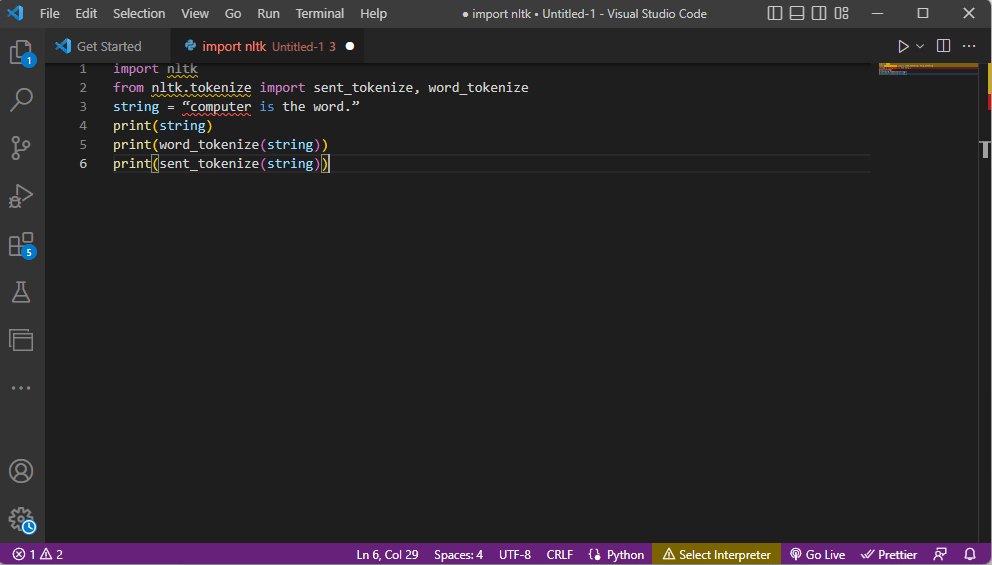
- Бібліотека інструментарію ntlk імпортується, а форми токенізації імпортуються з бібліотеки.
- Надається рядок і надаються команди для виконання токенізації.
- Поки рядок друкується, результатом буде комп’ютер – це слово.
- У разі токенізації слів або word_tokenize() кожне слово в реченні друкується окремо в межах ” і відокремлюється комою. Результатом для команди буде «computer», «is», «the», «word», «.»
- У разі токенізації речень або sent_tokenize(), окремі речення розміщуються в межах ”, і допускається повторення слів. Результатом команди буде «комп’ютер — це слово».
Тут наведено код, що пояснює кроки для токенізації вище.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Спосіб 3: через клас DocParser
Подібно до класу DataFrame, клас DocParser можна використовувати для аналізу тексту в коді. Клас дозволяє викликати функцію аналізу за допомогою шляху до файлу.
Процес розбору тексту
Щоб знати, як аналізувати текст за допомогою класу DocParser, дотримуйтеся наведених нижче інструкцій.
- Функція get_format(filename) використовується для отримання розширення файлу, повернення його до встановленої змінної для функції та передачі його наступній функції. Наприклад, p1 = get_format(filename) витягне розширення файлу filename, встановить його у змінну p1 і передасть його наступній функції.
- Логічна структура з іншими функціями будується за допомогою операторів і функцій if-elif-else.
- Якщо розширення файлу дійсне, а структура логічна, функція get_parser використовується для аналізу даних у шляху до файлу та повернення рядкового об’єкта користувачеві.
Примітка. Щоб знати, як виправити помилку синтаксичного аналізу, ця функція має бути реалізована правильно.
- Розбір значень даних виконується з розширенням файлу. Конкретна реалізація класу, якою є parse_txt або parse_docx, використовується для створення рядкових об’єктів із частин заданого типу файлу.
- Розбір можна виконати для файлів з іншими доступними для читання розширеннями, наприклад parse_pdf, parse_html і parse_pptx.
- Значення даних та інтерфейс можна імпортувати в програми за допомогою інструкцій імпорту та створити екземпляр об’єкта DocParser. Це можна зробити шляхом аналізу файлів мовою Python, наприклад parse_file.py. Цю операцію слід виконувати обережно, щоб уникнути помилки в аналізі тексту x.
Спосіб 4: за допомогою інструмента аналізу тексту
Інструмент аналізу тексту використовується для вилучення певних даних зі змінних і зіставлення їх з іншими змінними. Це не залежить від будь-яких інших інструментів, які використовуються в завданні, а інструмент платформи BPA використовується для споживання та виведення змінних. Скористайтеся наведеним тут посиланням, щоб отримати доступ до Інструмент аналізу тексту онлайн і використовуйте наведені раніше відповіді про те, як аналізувати текст.
Спосіб 5: за допомогою TextFieldParser (Visual Basic)
TextFieldParser використовував об’єкти для аналізу та обробки дуже великих файлів, які структуровані та розділені. У цьому методі можна використовувати ширину та стовпець тексту, як-от файли журналу або інформацію про застарілу базу даних. Метод синтаксичного аналізу подібний до ітерації коду над текстовим файлом і в основному використовується для вилучення полів тексту, подібно до методів маніпулювання рядками. Це робиться для токенізації розділених рядків і полів різної ширини за допомогою визначеного розділювача, такого як кома або пробіл табуляції.
Функції для аналізу тексту
Наступні функції можна використовувати для аналізу тексту в цьому методі.
- Щоб визначити роздільник, використовується SetDelimiters. Наприклад, команда testReader.SetDelimiters (vbTab) використовується для встановлення простору табуляції як розділювача.
- Щоб установити ширину поля на додатне ціле число для фіксованої ширини поля текстових файлів, ви можете скористатися командою testReader.SetFieldWidths (ціле число).
- Щоб перевірити тип поля тексту, ви можете використати таку команду testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Методи пошуку MatchObject
Існує два основні методи пошуку MatchObject у коді або проаналізованому тексті.
- Перший метод полягає у визначенні формату та перегляді файлу за допомогою методу ReadFields. Цей метод допоможе обробити кожен рядок коду.
- Метод PeekChars використовується для перевірки кожного поля окремо перед його читанням, визначення кількох форматів і реагування.
У будь-якому випадку, якщо поле не відповідає вказаному формату під час виконання аналізу або пошуку способу аналізу тексту, повертається виняток MalformedLineException.
Професійна порада: як аналізувати текст за допомогою MS Excel
Як останній і простий спосіб розібрати текст можна використовувати MS Excel додаток як аналізатор для створення файлів із роздільниками табуляцією та комами. Це допоможе у перехресній перевірці результату аналізу та допоможе знайти, як виправити помилку аналізу.
1. Виберіть значення даних у вихідному файлі та одночасно натисніть клавіші Ctrl + C, щоб скопіювати файл.
2. Відкрийте програму Excel за допомогою панелі пошуку Windows.
3. Натисніть на комірку A1 і одночасно натисніть клавіші Ctrl + V, щоб вставити скопійований текст.
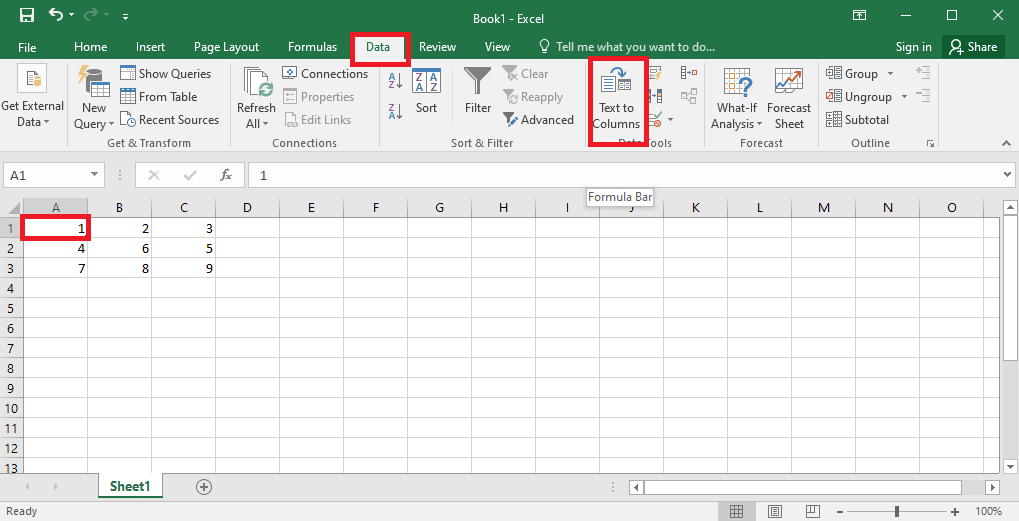
4. Виберіть комірку A1, перейдіть на вкладку «Дані» та натисніть опцію «Текст у стовпці» в розділі «Інструменти даних».
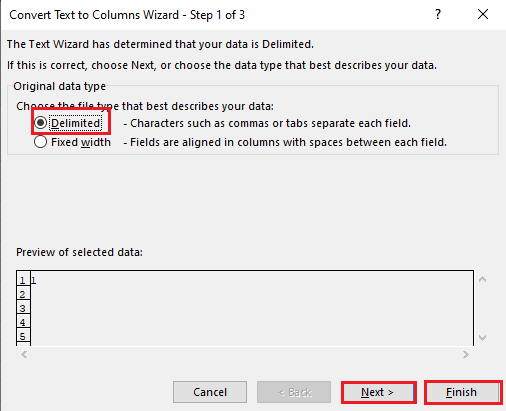
5А. Виберіть параметр «З роздільниками», якщо як роздільник використовується кома або пробіл табуляції, і натисніть кнопки «Далі» та «Готово».
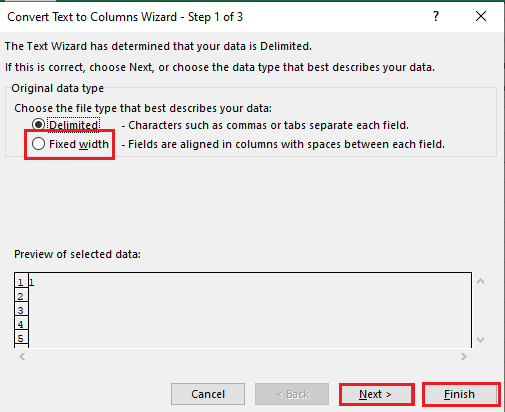
5B. Виберіть опцію «Фіксована ширина», призначте значення для роздільника та натисніть кнопки «Далі» та «Готово».
Як виправити помилку аналізу
Помилка синтаксичного аналізу тексту x може виникнути на пристроях Android як Помилка аналізу: сталася проблема аналізу пакета. Зазвичай це трапляється, коли програму не вдається встановити з магазину Google Play або під час запуску програми стороннього розробника.
Текст помилки x може виникнути, якщо список символьних векторів зациклюється, а інші функції формують лінійну модель для обчислення значень даних. Повідомлення про помилку: Error in parse(text = x, keep.source = FALSE):
Ви можете прочитати статтю про те, як виправити помилку синтаксичного аналізу на Android, щоб дізнатися про причини та способи виправлення помилки.
Окрім рішень у посібнику, ви можете спробувати наступні виправлення.
- Повторне завантаження файлу .apk або відновлення імені файлу.
- Відновлення змін у файлі Androidmanifest.xml, якщо у вас є навички програмування експертного рівня.
***
Стаття допоможе навчитися розбирати текст і навчитися виправляти помилку розбору. Повідомте нам, який метод допоміг виправити помилку в аналізі тексту x і якому методу аналізу надається перевага. Будь ласка, поділіться своїми пропозиціями та запитами в розділі коментарів нижче.