Якщо ви вивчали різні мови програмування, то, можливо, стикалися з поняттям синтаксичного аналізу тексту. Цей процес застосовується для спрощення обробки складних даних у файлах. Дана стаття допоможе вам розібратися, як аналізувати текст, використовуючи мову програмування. Крім того, якщо ви зіткнулися з помилкою аналізу тексту, тут ви знайдете інформацію про те, як її виправити.

Як Здійснити Аналіз Тексту
У цій статті ми детально розглянемо різні методи аналізу тексту та надамо базове розуміння цього процесу.
Що Таке Аналіз Тексту?
Перш ніж заглиблюватися в технічні аспекти аналізу тексту за допомогою коду, важливо мати базові знання мови програмування та кодування.
Обробка Природної Мови (NLP)
Аналіз тексту часто використовує обробку природної мови (NLP), що є підгалуззю штучного інтелекту. Мова Python, зокрема, широко застосовується для аналізу тексту завдяки своїм можливостям у цій галузі.
Інструменти NLP дозволяють комп’ютерам розуміти та обробляти людську мову, роблячи її придатною для різних цілей. Для застосування методів машинного навчання до тексту, неструктуровані дані необхідно перетворити у структурований табличний формат. Мова Python часто використовується для модифікації програмного коду під час цього процесу.
Суть Аналізу Тексту
Аналіз тексту, по суті, передбачає перетворення даних з одного формату в інший. Формат файлу, який потрібно обробити, може бути перетворений в інший формат, придатний для використання в різних програмах.
- Процес включає аналіз рядка або тексту та його розбиття на логічні складові шляхом зміни формату файлу.
- Для виконання цього типового завдання програмування використовуються певні правила мови Python. Під час аналізу тексту задана послідовність символів розділяється на менші елементи.
Навіщо Потрібен Аналіз Тексту?
У цьому розділі розглянемо основні причини необхідності аналізу тексту, що є важливим для розуміння процесу.
- Комп’ютерні дані можуть мати різноманітні формати залежно від програми.
- Різні програми можуть використовувати несумісні формати даних, що може призвести до помилок.
- Не існує універсальної програми, здатної обробляти дані у всіх форматах.
Метод 1: Використання Класу DataFrame
Клас DataFrame у мові Python має всі необхідні інструменти для аналізу тексту. Ця вбудована бібліотека містить код, необхідний для перетворення даних з одного формату в інший.
Короткий Огляд Класу DataFrame
DataFrame Class – це багатофункціональна структура даних, яка використовується для аналізу даних. Це потужний інструмент, який дозволяє аналізувати дані з мінімальними зусиллями.
- Код зчитується в pandas DataFrame для виконання аналізу за допомогою Python.
- Клас містить численні пакети, що використовуються аналітиками даних Python.
- Особливістю цього класу є абстракція, де внутрішня функціональність прихована від користувачів. Також використовується бібліотека NumPy, яка містить команди та функції для роботи з масивами.
- Клас DataFrame можна використовувати для візуалізації двовимірних масивів з кількома індексами рядків і стовпців (MultiIndex), які потрібно змінювати, щоб виправити помилку аналізу.
Бібліотека pandas мови Python дозволяє виконувати SQL-операції з високою точністю, уникаючи помилок під час аналізу тексту. Вона також містить інструменти введення-виведення для аналізу файлів CSV, MS Excel, JSON, HDF5 та інших форматів даних.
Процес Аналізу Тексту за Допомогою Класу DataFrame
Щоб зрозуміти, як аналізувати текст, можна скористатися стандартним процесом, що використовує клас DataFrame, описаним нижче.
- Визначте формат вхідних даних.
- Визначте формат вихідних даних, наприклад, CSV.
- Запишіть дані у код у примітивному типі, наприклад, list або dict.
Примітка: Написання коду в порожньому DataFrame може бути складним. Pandas дозволяє створювати дані у класі DataFrame з цих типів даних, що полегшує аналіз даних у потрібному форматі.
- Проаналізуйте дані за допомогою інструменту аналізу pandas DataFrame і виведіть результат.
Варіант I: Стандартний Формат
Тут описано стандартний метод форматування файлу з певним форматом даних, наприклад, CSV.
- Збережіть файл з даними локально, наприклад, data.txt.
- Імпортуйте файл у pandas з потрібною назвою та збережіть дані у змінній. Наприклад, pandas імпортується як pd.
- Імпорт повинен мати повний код із детальною інформацією про назву вхідного файлу, функцію та формат вхідного файлу.
Примітка: Змінна res використовується для читання даних з data.txt за допомогою pd. Формат вхідних даних вказується як CSV.
- Викличте вказаний тип файлу та виведіть проаналізований текст. Наприклад, команда res виведе проаналізований текст.
Нижче наведено приклад коду цього процесу:
import pandas as pd
res = pd.read_csv('data.txt')
res
У цьому випадку, якщо в data.txt ввести [1,2,3], ви отримаєте 1 2 3.
Варіант II: Рядковий Метод
Якщо текст містить рядки або буквено-цифрові символи, розділені комами, пробілами і т.д., їх можна використовувати для розділення та аналізу тексту. Цей процес схожий на звичайні операції з рядками. Щоб уникнути помилок, виконайте аналіз за цим параметром, як описано нижче.
- Дані витягуються з рядка, і визначаються всі спеціальні символи, що розділяють текст.
Наприклад, у коді нижче спеціальні символи в рядку my_string визначені як ‘,’ та ‘:’.
- Текст розбивається на окремі значення на основі позиції спеціальних символів.
Наприклад, рядок розбивається на текстові значення за допомогою команди split.
- Значення виводяться окремо як проаналізований текст. Інструкція print використовується для виведення проаналізованого значення.
Зразок коду:
my_string = 'Names: Tech, computer'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print("Names: {}".format(sfinal))
Результат буде виглядати так:
Names: ['Tech', 'computer']
Для кращого розуміння аналізу рядків використовується цикл for:
my_string = 'Names: Tech, computer'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print("Step {}: {}".format(idx, item))
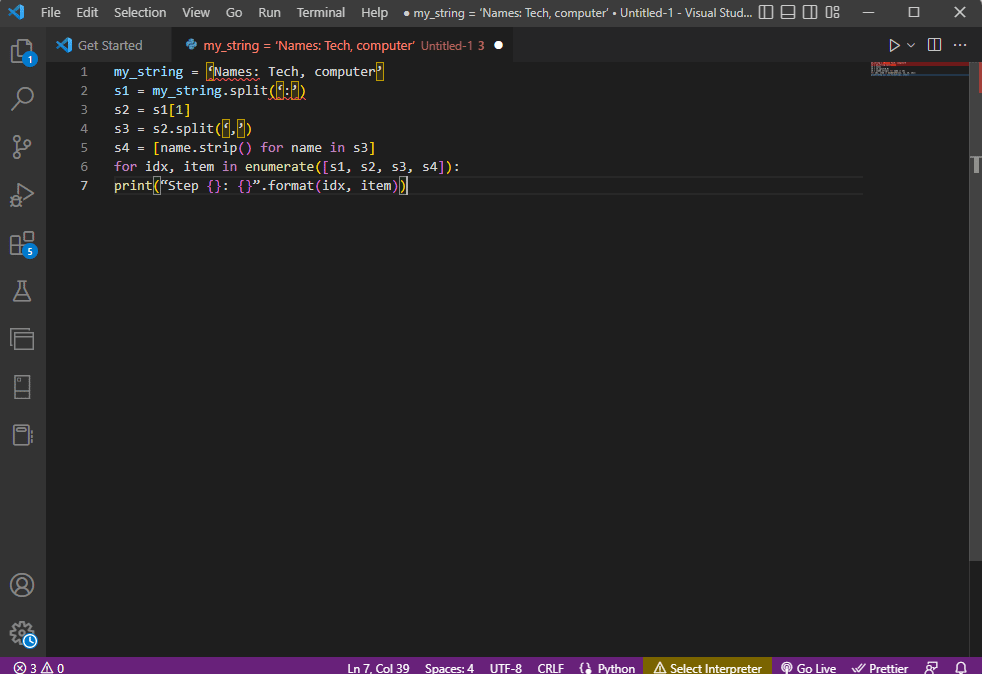
Результат аналізу на кожному кроці:
Step 0: ['Names', 'Tech, computer'] Step 1: Tech, computer Step 2: [' Tech', ' computer'] Step 3: ['Tech', 'computer']
Варіант III: Аналіз Складного Файлу
У багатьох випадках дані у файлі можуть містити різні типи даних і значення. Аналіз такого файлу може бути складним за допомогою описаних вище методів.
Особливості аналізу складних даних:
- Заголовок або метадані виводяться у верхній частині файлу.
- Змінні та поля відображаються у табличній формі.
- Значення даних утворюють складений ключ.
Перед початком аналізу складних даних необхідно вивчити деякі базові поняття. Аналіз даних виконується на основі регулярних виразів.
Шаблони Регулярних Виразів
Важливо переконатися, що шаблони регулярних виразів правильні. Код для аналізу рядкових значень буде містити такі загальні шаблони:
-
’d’ : відповідає десятковій цифрі в рядку,
-
’s’ : відповідає пробільному символу,
-
’w’: відповідає буквено-цифровому символу,
-
’+’ або ’*’: виконує жадібний збіг, збігаючи один або більше символів у рядках,
-
’a-z’ : відповідає групам малих літер,
-
’A-Z’ або ’a-z’: відповідає групам літер верхнього та нижнього регістру,
-
’0-9’ : відповідає числовим значенням.
Регулярні Вирази
Модулі регулярних виразів є частиною пакета pandas у Python. Неправильний re може призвести до помилки аналізу. Регулярні вирази – це рядки зі спеціальним синтаксисом, що дозволяють користувачеві знаходити шаблони в інших рядках. Регулярний вираз створюється на основі типу даних і вимог до виразу в рядку, наприклад “Рядок = (.*)n”. Символи, які використовуються в регулярних виразах:
-
. : для отримання будь-якого символу з даних,
-
* : використовувати нуль або більше даних із попереднього виразу,
-
(.*) : щоб згрупувати частину регулярного виразу в дужках,
-
n : створити новий символ рядка в кінці рядка в коді,
-
d : створити коротке інтегральне значення в діапазоні від 0 до 9,
-
+ : використовувати одне або кілька даних із попереднього виразу,
-
| : створювати логічне висловлювання; використовується для або виразів.
RegexObjects
RegexObject – це значення, що повертається функцією компіляції, та використовується для повернення MatchObject, якщо вираз відповідає значенню відповідності.
1. MatchObject
Оскільки логічне значення MatchObject завжди дорівнює True, можна використовувати оператор if для ідентифікації позитивних збігів. Група, на яку посилається індекс, використовується для визначення збігу об’єкта у виразі.
-
group() повертає одну або більше підгруп відповідності,
-
group(0) повертає повний збіг,
-
group(1) повертає першу підгрупу в дужках,
- Посилаючись на кілька груп, ми повинні використовувати спеціальне розширення python. Це розширення використовується для вказівки назви групи, у якій потрібно знайти збіг. Наприклад, вираз (?P
regex1) посилатиметься на певну групу з іменем group1 і перевірятиме збіг у регулярному виразі regex1. Щоб дізнатися, як виправити помилку синтаксичного аналізу, ви повинні перевірити, чи група вказана правильно.
2. Методи MatchObject
MatchObject має два основні методи. Якщо MatchObject знайдено, він повертає його екземпляр, інакше повертає None.
- Метод match(string) використовується для пошуку збігів рядка на початку регулярного виразу.
- Метод search(string) використовується для сканування рядка, щоб знайти місце збігу в регулярному виразі.
Функції Регулярних Виразів
Регулярні вирази – це рядки коду, що використовуються для виконання певної функції, визначеної користувачем із набору отриманих значень даних.
Примітка: Для написання функцій використовуються “сирі” рядки, щоб уникнути помилок. Це робиться шляхом додавання нижнього індексу r перед кожним шаблоном у виразі.
Загальні функції, що використовуються у виразах:
1. re.findall()
Ця функція повертає всі шаблони в рядку, якщо збіг знайдено, і порожній список, якщо збігів немає. Наприклад, функція string = re.findall(’[aeiou]’, regex_filename) використовується для пошуку голосних у назві файлу.
2. re.split()
Ця функція використовується для поділу рядка, коли виявлено збіг з вказаним символом, наприклад, пробілом. Якщо збігів не знайдено, повертається порожній рядок.
3. re.sub()
Функція замінює відповідний текст вмістом наданої змінної заміни. Якщо шаблон не знайдено, повертається оригінальний рядок.
4. re.search()
Функція допомагає шукати шаблон у рядку та повертати відповідний об’єкт. Якщо збіг не знайдено, значення не повертається.
5. re.compile(шаблон)
Ця функція компілює шаблони регулярних виразів у RegexObject.
Інші Вимоги
- Для візуалізації регулярного виразу використовується регулярний вираз.
- Для перевірки регулярного виразу використовується regex101.
Процес Аналізу Тексту
Метод аналізу тексту в цій складній опції:
- Найважливіший крок — розуміння формату введення шляхом читання вмісту файлу. Наприклад, функції with open і read() використовуються для відкриття та читання вмісту файлу sample. Файл sample містить вміст із file.txt.
- Вміст файлу виводиться для ручного аналізу та знаходження метаданих. Тут print() виводить вміст файлу sample.
- Необхідні пакети імпортуються, а класу присвоюється ім’я. Тут імпортуються регулярні вирази та pandas.
- Регулярні вирази, необхідні для коду, визначаються шляхом включення шаблону та функції регулярного виразу.
- Функція compile() використовується для компіляції рядка з групи stringname1 файлу filename. Функція перевірки збігів у регулярному виразі використовується командою ief_parse_line(line).
- Парсер рядка написаний за допомогою def_parse_file(filepath). Тут метод regex search() шукає ключ rx в назві файлу та повертає ключ і збіг першого регулярного виразу.
- Створюється порожній список, як data = []. Відповідність перевіряється у кожному рядку, а точні дані повертаються на основі типу.
- Для отримання числа та значення для таблиці використовується команда line.strip().split(’,’). Команда row{} створює словник з рядком даних. data.append(row) використовується для розуміння даних і їх аналізу у табличному форматі.
Команда data = pd.DataFrame(data) створює pandas DataFrame. Також можна використовувати:
-
data.set_index([‘string’, ‘integer’], inplace=True), щоб встановити індекс таблиці.
-
data = data.groupby(level=data.index.names).first() для консолідації та видалення nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) для оновлення оцінки з числа з плаваючою точкою до цілого.
Останній крок — тестування аналізатора за допомогою if, присвоєння значень змінним та виведення їх за допомогою print(data).
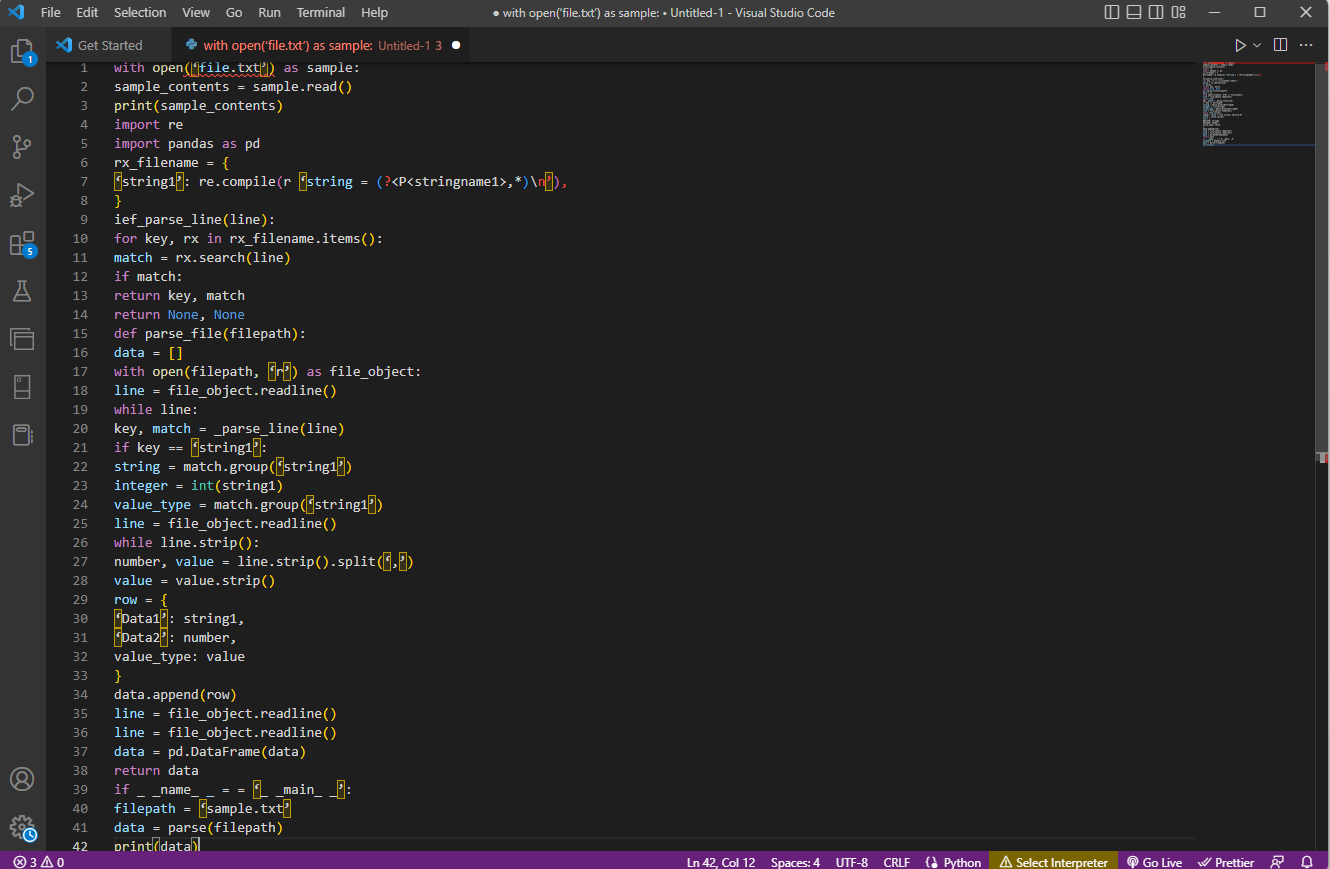
Приклад коду:
with open('file.txt') as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
'string1': re.compile(r 'string = (?<P<stringname1>,*)n'),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == 'string1':
string = match.group('string1')
integer = int(string1)
value_type = match.group('string1')
line = file_object.readline()
while line.strip():
number, value = line.strip().split(',')
value = value.strip()
row = {
'Data1': string1,
'Data2': number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _name_ == '_main_':
filepath = 'sample.txt'
data = parse(filepath)
print(data)
Метод 2: Токенізація Слів
Процес перетворення тексту на токени або менші фрагменти на основі правил називається токенізацією. Важливо проаналізувати команди токенізації в коді. Можна створювати власні правила для виконання завдань попередньої обробки тексту, таких як зіставлення частин мови. Також виконуються пошук і зіставлення загальних слів, очищення тексту та підготовка даних для розширеного аналізу. Неправильна токенізація може призвести до помилки аналізу.
Бібліотека Ntlk
Цей процес використовує популярну бібліотеку nltk, яка має функції для виконання багатьох завдань NLP. Її можна завантажити за допомогою пакетів Pip або Pip Installs. Базовий пакет Anaconda містить цю бібліотеку за замовчуванням.
Форми Токенізації
Поширеними формами є токенізація слів і речень. Токенізація на рівні слова друкує кожне слово один раз, тоді як на рівні речень – на рівні речення.
Процес Аналізу Тексту
- Імпортується бібліотека ntlk та форми токенізації.
- Надається рядок і команди для токенізації.
- Поки рядок друкується, результатом буде: комп’ютер – це слово.
- У випадку токенізації слів (word_tokenize()), кожне слово друкується окремо: “computer”, “is”, “the”, “word”, “.”.
- У випадку токенізації речень (sent_tokenize()), окремі речення розміщуються у лапках: “комп’ютер — це слово”.
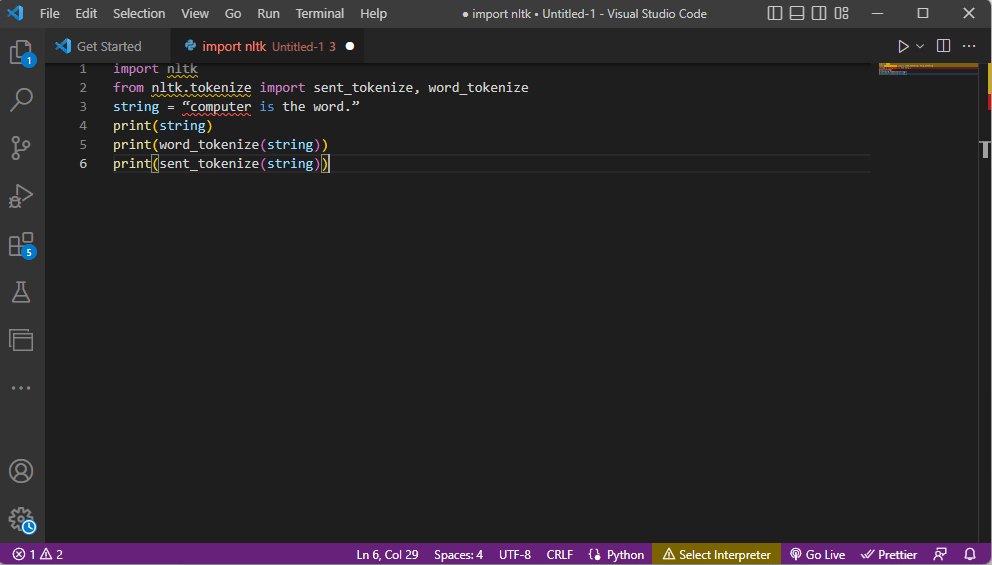
Код для токенізації:
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Метод 3: Використання Класу DocParser
Клас DocParser можна використовувати для аналізу тексту. Клас дозволяє викликати функцію аналізу за допомогою шляху до файлу.
Процес Аналізу Тексту
Щоб аналізувати текст за допомогою DocParser:
- Функція get_format(filename) отримує розширення файлу та передає його наступній функції.
- Логічна структура будується за допомогою операторів if-elif-else.
- Якщо розширення файлу та логічна структура правильні, функція get_parser використовується для аналізу даних та повернення рядкового об’єкта.
Примітка: Ця функція повинна бути реалізована правильно, щоб уникнути помилок.
- Аналіз даних виконується на основі розширення файлу. parse_txt або parse_docx створюють рядкові об’єкти із заданого типу файлу.
- Аналіз також можна виконати для parse_pdf, parse_html та parse_pptx.
- Значення даних та інтерфейс можна імпортувати за допомогою інструкцій імпорту та створити екземпляр об’єкта DocParser. Цю операцію потрібно виконувати обережно, щоб уникнути помилок.
Метод 4: Використання Інструменту Аналізу Тексту
Інструмент аналізу тексту використовується для вилучення даних зі змінних та їх зіставлення. Він незалежний від інших інструментів. Онлайн-інструмент Інструмент аналізу тексту онлайн можна використовувати для аналізу тексту.
Метод 5: TextFieldParser (Visual Basic)
TextFieldParser використовує об’єкти для аналізу великих структурованих файлів. Можна використовувати ширину та стовпець тексту, як-от файли журналу. Метод аналізу подібний до ітерації коду над текстовим файлом та використовується для вилучення полів тексту. Це робиться для токенізації розділених рядків і полів різної ширини за допомогою роздільника.
Функції Аналізу Тексту
- SetDelimiters визначає роздільник. Наприклад, testReader.SetDelimiters(vbTab) встановлює пробіл табуляції як роздільник.
- SetFieldWidths встановлює ширину поля на додатне ціле число для файлів з фіксованою шириною.
- TextFieldType перевіряє тип поля: testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Методи Пошуку MatchObject
- Перший метод — визначення формату та перегляд файлу за допомогою ReadFields.
- Метод PeekChars використовується для перевірки кожного поля окремо перед читанням.
У будь-якому випадку, якщо поле не відповідає вказаному формату, повертається виняток MalformedLineException.
Порада: Аналіз Тексту за Допомогою MS Excel
MS Excel можна використовувати для створення файлів з роздільниками табуляцією та комами. Це допоможе перевірити результати аналізу.
1. Скопіюйте значення даних з вихідного файлу (Ctrl + C).
2. Відкрийте програму Excel.
3. Вставте текст у комірку A1 (Ctrl + V).
4. Виберіть A1, перейдіть на вкладку “Дані” та натисніть “Текст у стовпці”.
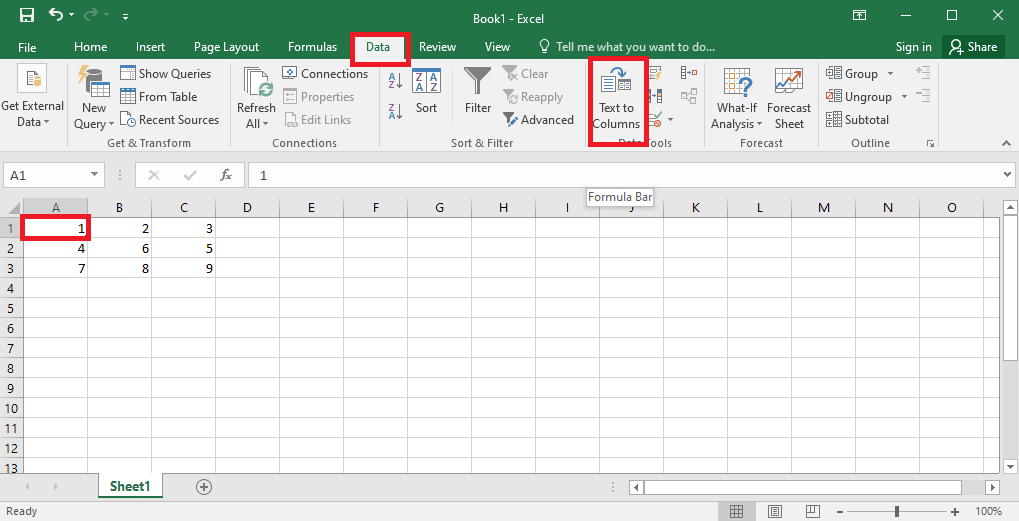
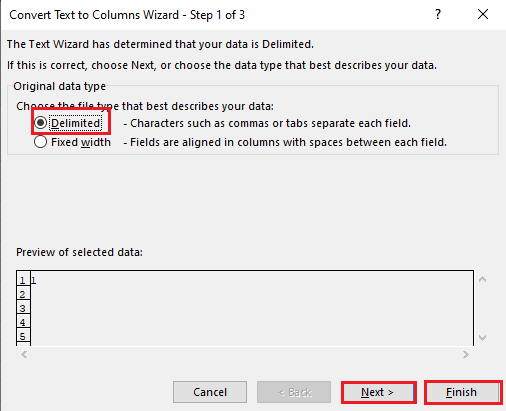
5A. Виберіть “З роздільниками”, якщо роздільником є кома або пробіл табуляції, і натисніть “Далі” та “Готово”.
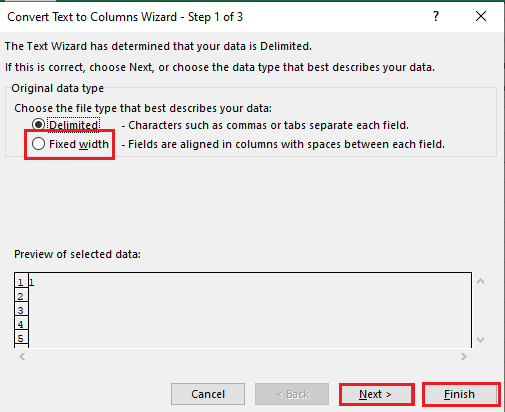
5B. Виберіть “Фіксована ширина”, встановіть роздільник та натисніть “Далі” та “Готово”.
Як Виправити Помилку Аналізу
Помилка аналізу тексту може виникнути на Android як “Помилка аналізу: сталася проблема аналізу пакета”. Це відбувається, коли програму не вдається встановити або під час запуску сторонньої програми.
Текст помилки може виникнути, якщо список символьних векторів зациклюється. Повідомлення про помилку: Error in parse(text = x, keep.source = FALSE):<text>:2.0:unexpected end of input 1:OffenceAgainst ~ ^.
Прочитайте статтю про те, як виправити помилку синтаксичного аналізу на Android, щоб дізнатися про причини та способи виправлення.
Інші способи виправлення:
- Повторне завантаження файлу .apk або відновлення імені файлу.
- Відновлення змін у файлі Androidmanifest.xml, якщо у вас є навички програмування.
***
Сподіваємося, що стаття допомогла вам навчитися розбирати текст та виправляти помилки. Повідомте нам, який метод допоміг вам, та якому методу ви надаєте перевагу. Поділіться своїми пропозиціями та запитами в розділі коментарів нижче.