
Meta випустила Llama 2 влітку 2023 року. Нова версія Llama налаштована на 40% більше токенів, ніж оригінальна модель Llama, подвоївши довжину контексту та значно перевершуючи інші доступні моделі з відкритим кодом. Найшвидший і найпростіший спосіб отримати доступ до Llama 2 — через API через онлайн-платформу. Однак якщо ви хочете отримати найкращий досвід, найкраще встановити та завантажити Llama 2 безпосередньо на комп’ютері.
Пам’ятаючи про це, ми створили покроковий посібник із використання Text-Generation-WebUI для локального завантаження квантованого Llama 2 LLM на ваш комп’ютер.
Навіщо встановлювати Llama 2 локально
Є багато причин, чому люди вирішують запускати Llama 2 безпосередньо. Деякі роблять це з міркувань конфіденційності, деякі для налаштування, а інші для офлайн-можливостей. Якщо ви досліджуєте, налаштовуєте чи інтегруєте Llama 2 у свої проекти, то доступ до Llama 2 через API може бути не для вас. Сенс запуску LLM локально на вашому ПК полягає в тому, щоб зменшити залежність від сторонніх інструментів штучного інтелекту та використовувати штучний інтелект у будь-який час і будь-де, не турбуючись про витік потенційно конфіденційних даних компаніям та іншим організаціям.
З огляду на це, давайте почнемо з покрокового посібника з локального встановлення Llama 2.
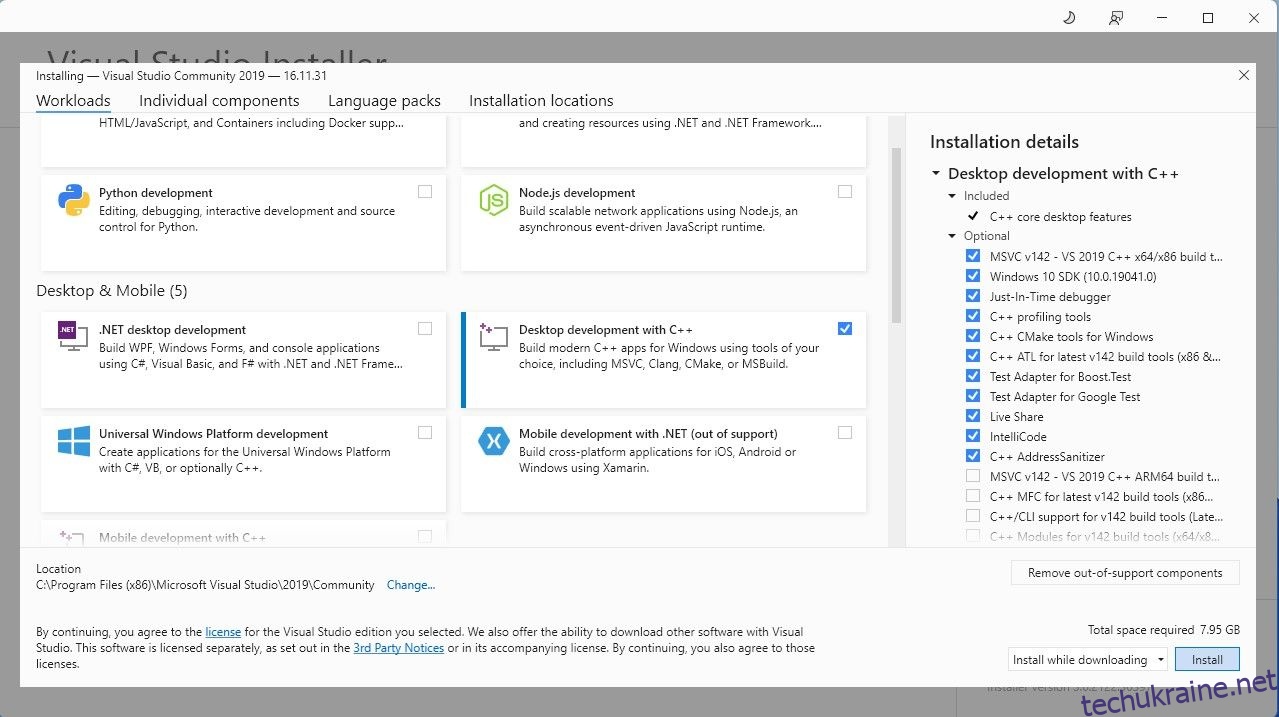
Щоб спростити речі, ми будемо використовувати інсталятор одним клацанням миші для Text-Generation-WebUI (програма, яка використовується для завантаження Llama 2 з GUI). Однак, щоб цей інсталятор працював, вам потрібно завантажити Visual Studio 2019 Build Tool і встановити необхідні ресурси.
Завантажити: Visual Studio 2019 (безкоштовно)
Тепер, коли ви встановили Desktop development with C++, настав час завантажити інсталятор Text-Generation-WebUI одним клацанням миші.
Крок 2. Встановіть Text-Generation-WebUI
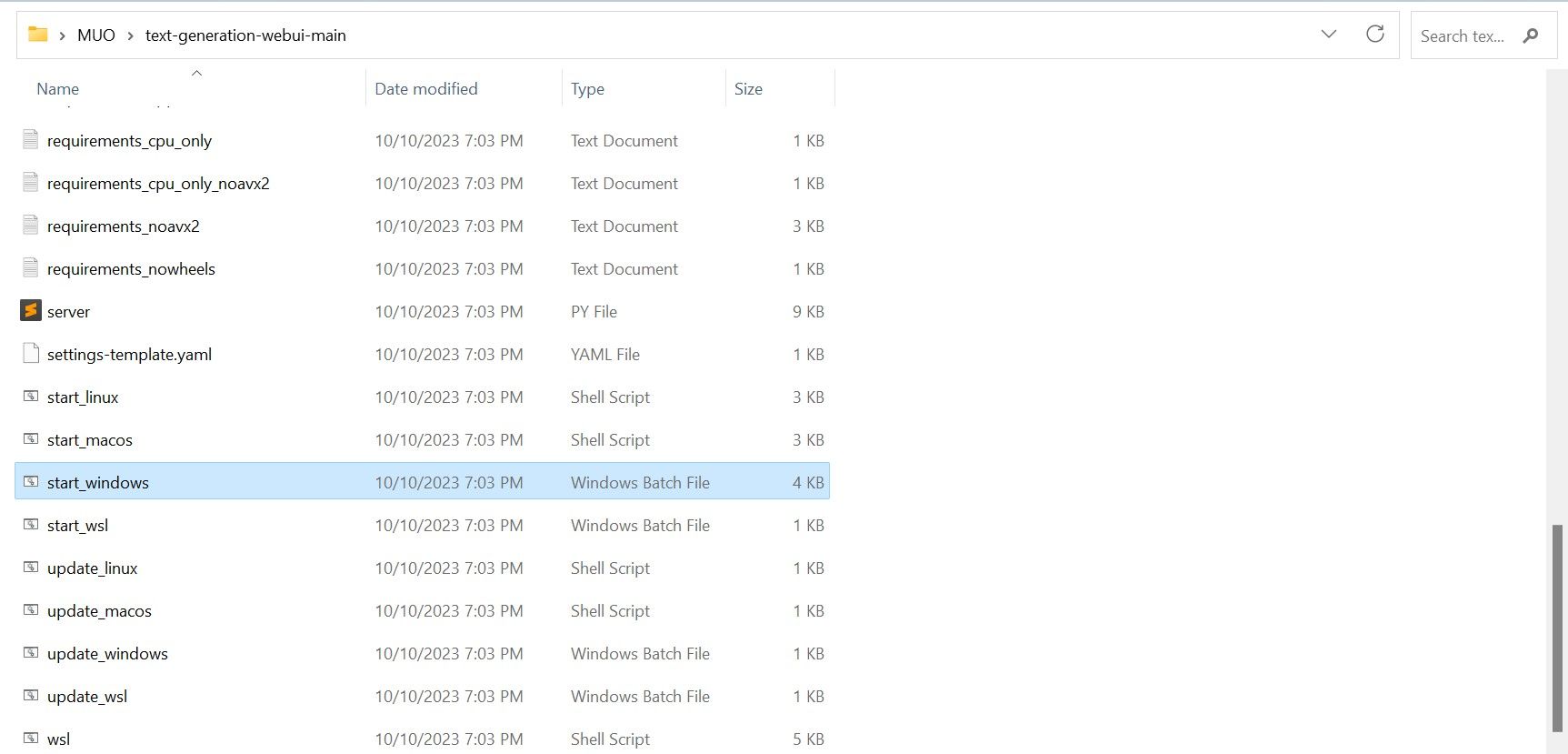
Інсталятор Text-Generation-WebUI одним клацанням миші — це сценарій, який автоматично створює необхідні папки та налаштовує середовище Conda та всі необхідні вимоги для запуску моделі ШІ.
Щоб установити сценарій, завантажте програму встановлення одним клацанням миші, натиснувши «Код» > «Завантажити ZIP».
Завантажити: Встановлювач WebUI Text-Generation (безкоштовно)
- Якщо ви використовуєте Windows, виберіть пакетний файл start_windows
- для MacOS виберіть сценарій оболонки start_macos
- для Linux, сценарій оболонки start_linux.
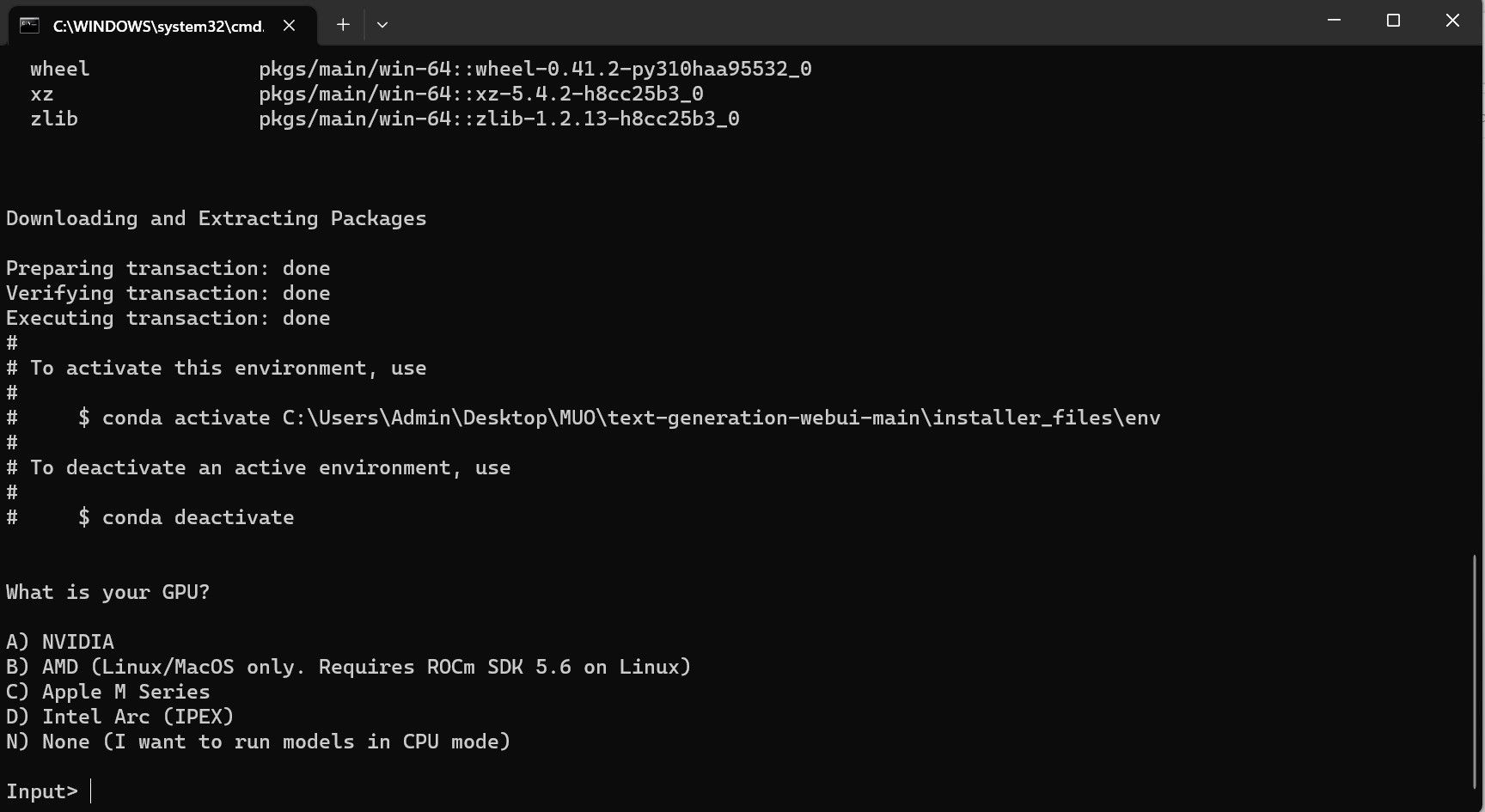
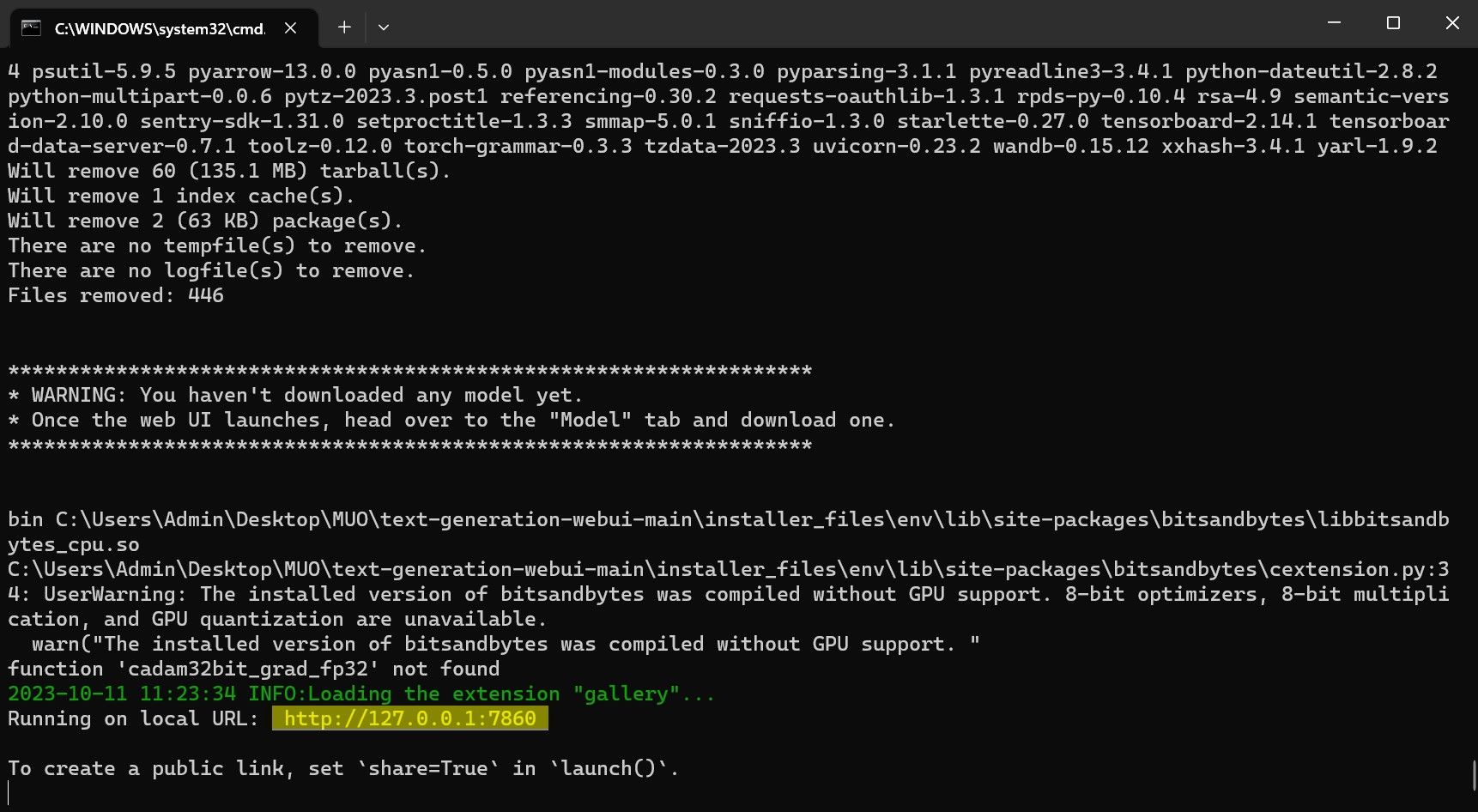
Однак програма є лише завантажувачем моделі. Давайте завантажимо Llama 2 для запуску моделі завантажувача.
Крок 3: Завантажте модель Llama 2
Вирішуючи, яка ітерація Llama 2 вам потрібна, потрібно враховувати чимало речей. До них належать параметри, квантування, апаратна оптимізація, розмір і використання. Вся ця інформація буде позначена в назві моделі.
- Параметри: кількість параметрів, які використовуються для навчання моделі. Більші параметри роблять моделі ефективнішими, але за рахунок продуктивності.
- Використання: може бути стандартним або чатом. Модель чату оптимізовано для використання як чат-бот, наприклад ChatGPT, тоді як стандартна модель є типовою.
- Оптимізація обладнання: вказує на те, яке обладнання найкраще запускає модель. GPTQ означає, що модель оптимізовано для роботи на виділеному GPU, тоді як GGML оптимізовано для роботи на CPU.
- Квантування: позначає точність ваг і активацій у моделі. Для логічного висновку оптимальною є точність q4.
- Розмір: Відноситься до розміру конкретної моделі.
Зауважте, що деякі моделі можуть бути організовані по-іншому та навіть не мати однакових типів інформації. Однак цей тип іменування є досить поширеним у бібліотеці HuggingFace Model, тому його все одно варто зрозуміти.

У цьому прикладі модель можна ідентифікувати як модель Llama 2 середнього розміру, навчену на 13 мільярдах параметрів, оптимізовану для створення висновків у чаті за допомогою виділеного ЦП.
Для тих, хто працює на виділеному GPU, виберіть модель GPTQ, а для тих, хто використовує CPU, виберіть GGML. Якщо ви хочете спілкуватися з моделлю, як із ChatGPT, виберіть чат, але якщо ви хочете поекспериментувати з моделлю з усіма її можливостями, скористайтеся стандартною моделлю. Що стосується параметрів, знайте, що використання більших моделей забезпечить кращі результати за рахунок продуктивності. Особисто я рекомендую вам почати з моделі 7B. Що стосується квантування, використовуйте q4, оскільки воно лише для логічного висновку.
Завантажити: GGML (безкоштовно)
Завантажити: GPTQ (безкоштовно)
Тепер, коли ви знаєте, яка ітерація Llama 2 вам потрібна, завантажте потрібну модель.
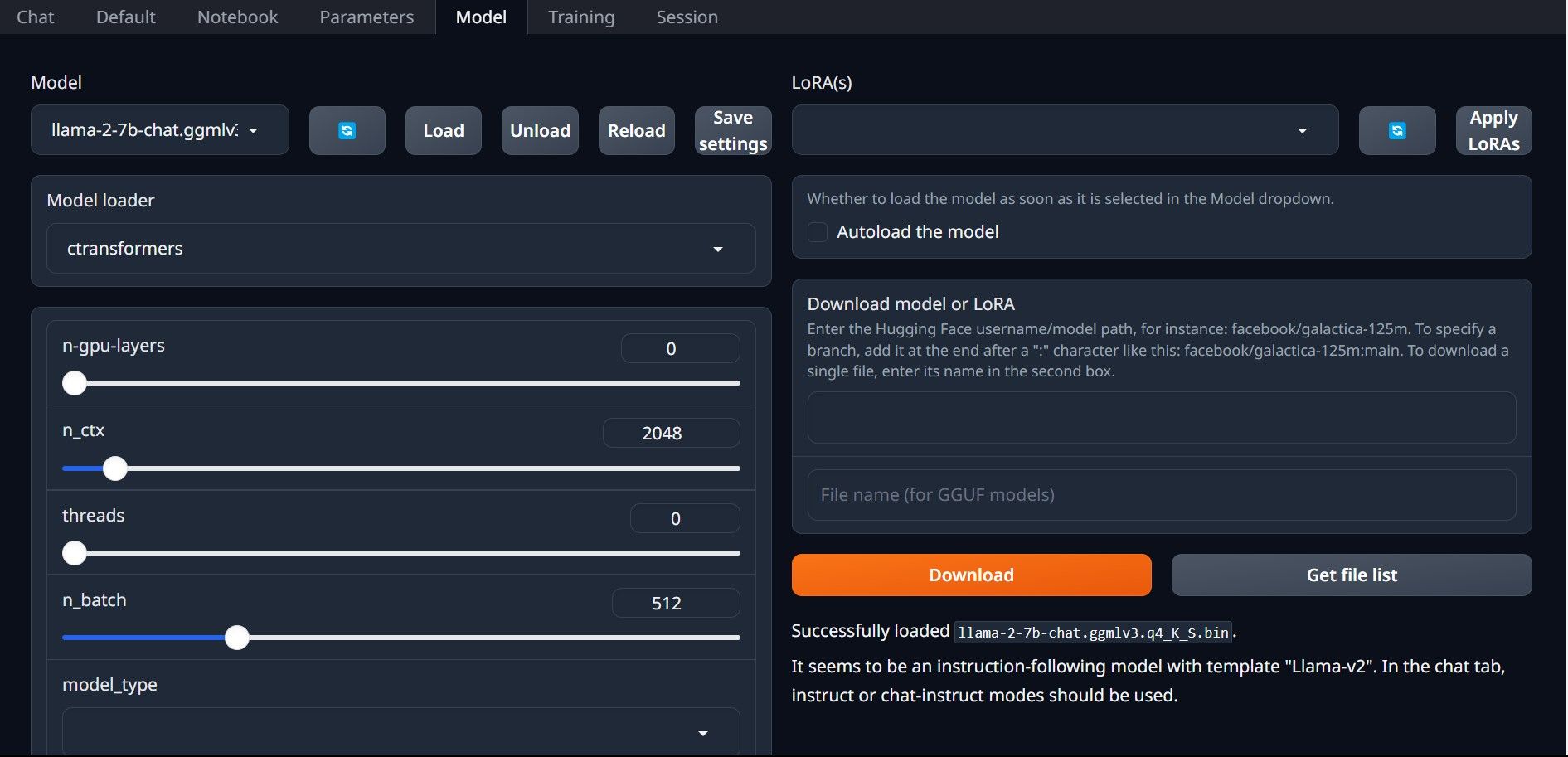
У моєму випадку, оскільки я запускаю це на ультрабуці, я буду використовувати модель GGML, налаштовану для чату, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
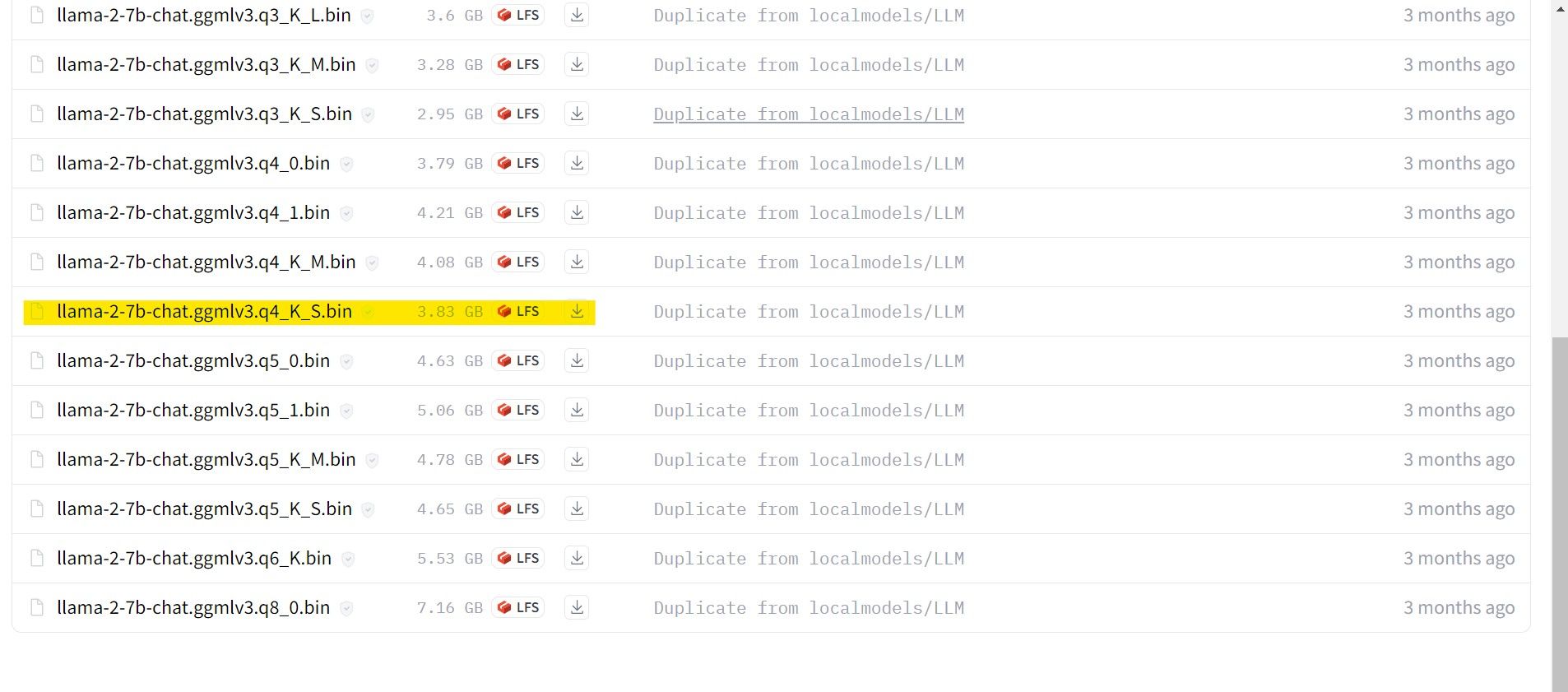
Після завершення завантаження розмістіть модель у text-generation-webui-main > models.
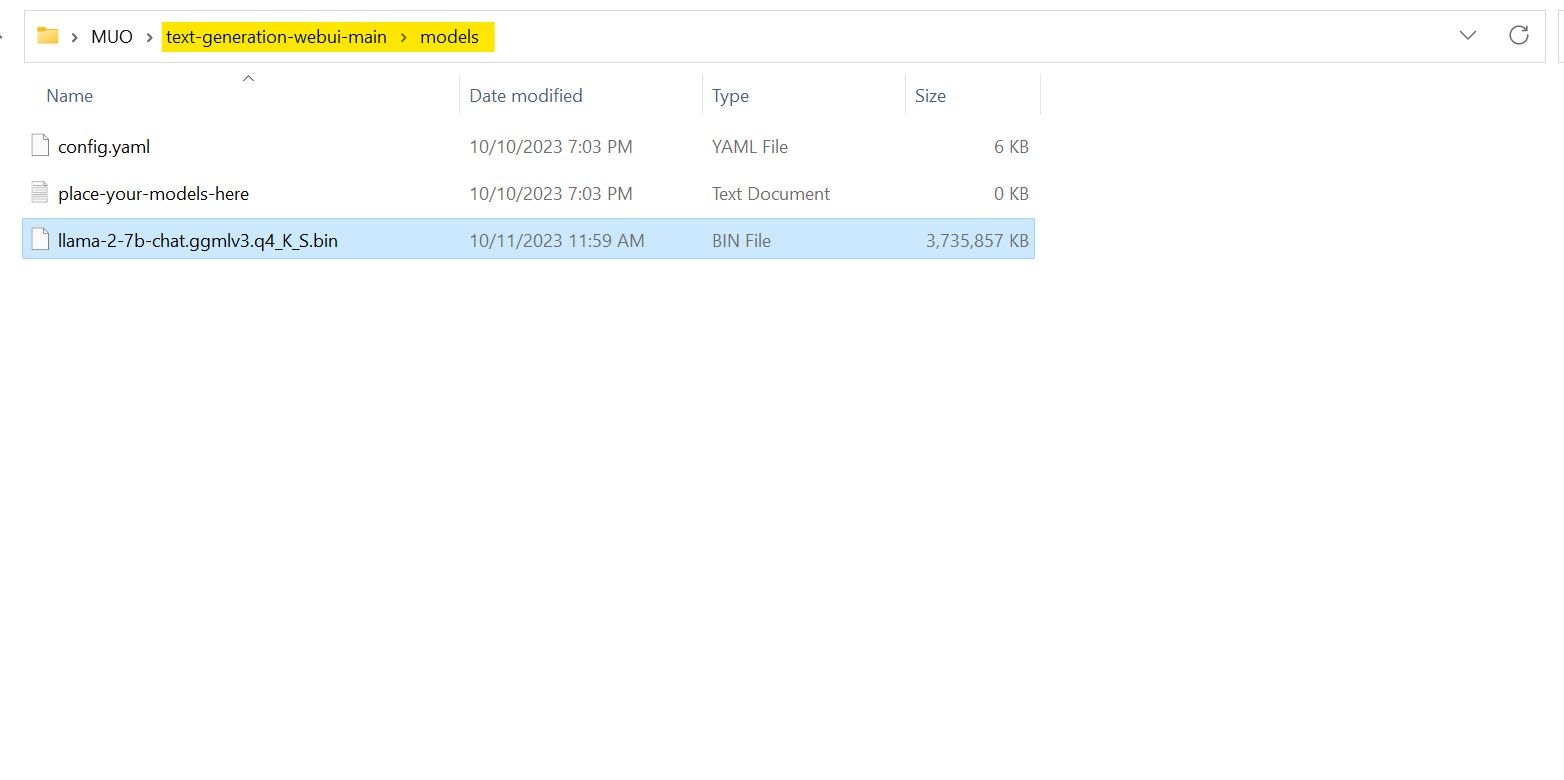
Тепер, коли ваша модель завантажена та розміщена в папці моделі, настав час налаштувати завантажувач моделі.
Крок 4: Налаштуйте Text-Generation-WebUI
Тепер почнемо етап налаштування.
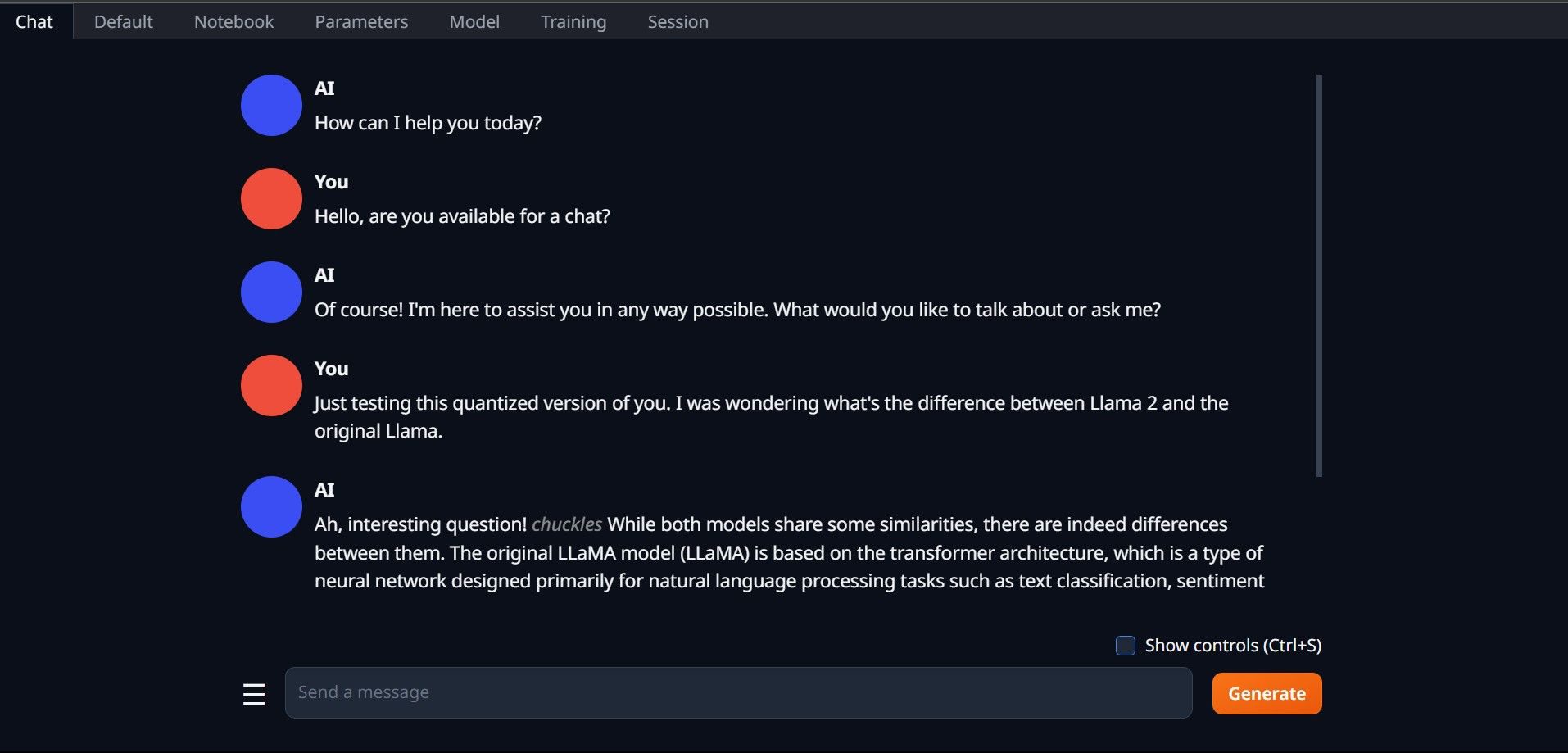
Вітаємо, ви успішно завантажили Llama2 на свій локальний комп’ютер!
Спробуйте інші LLM
Тепер, коли ви знаєте, як запускати Llama 2 безпосередньо на своєму комп’ютері за допомогою Text-Generation-WebUI, ви також повинні мати можливість запускати інші LLM, окрім Llama. Просто пам’ятайте про правила іменування моделей і про те, що на звичайні комп’ютери можна завантажити лише квантовані версії моделей (зазвичай з точністю q4). Багато квантованих LLM доступні на HuggingFace. Якщо ви хочете дослідити інші моделі, знайдіть TheBloke у бібліотеці моделей HuggingFace, і ви знайдете багато доступних моделей.