Влітку 2023 року компанія Meta представила Llama 2. Ця оновлена версія Llama може обробляти на 40% більше токенів порівняно з оригінальною моделлю, а також збільшено довжину контексту вдвічі. Це робить її значно кращою за інші моделі з відкритим кодом. Найшвидший спосіб скористатися Llama 2 – через API на онлайн-платформі. Однак, для отримання максимальної продуктивності, краще встановити та завантажити Llama 2 безпосередньо на ваш комп’ютер.
Враховуючи це, ми підготували детальну інструкцію з використання Text-Generation-WebUI для локального завантаження квантованої моделі Llama 2 LLM на ваш пристрій.
Навіщо встановлювати Llama 2 локально?
Існує кілька причин, чому користувачі обирають локальний запуск Llama 2. Деякі роблять це для забезпечення конфіденційності, інші для можливості налаштування, а ще інші – для доступу до функціоналу в офлайн-режимі. Якщо ви займаєтеся дослідженнями, кастомізацією або інтеграцією Llama 2 у ваші проекти, то використання API може бути не найкращим варіантом. Запуск LLM локально на вашому комп’ютері дозволяє зменшити залежність від сторонніх інструментів штучного інтелекту та використовувати його будь-де і будь-коли, не турбуючись про потенційну передачу конфіденційних даних стороннім компаніям чи організаціям.
Перейдемо до покрокової інструкції з локального встановлення Llama 2.
Для спрощення процесу ми будемо використовувати інсталятор одним клацанням миші для Text-Generation-WebUI (програми для завантаження Llama 2 з графічним інтерфейсом). Проте, для його коректної роботи необхідно попередньо завантажити та встановити Visual Studio 2019 Build Tool, а також потрібні компоненти.
Завантажити: Visual Studio 2019 (безкоштовно)
- Завантажте версію Community.
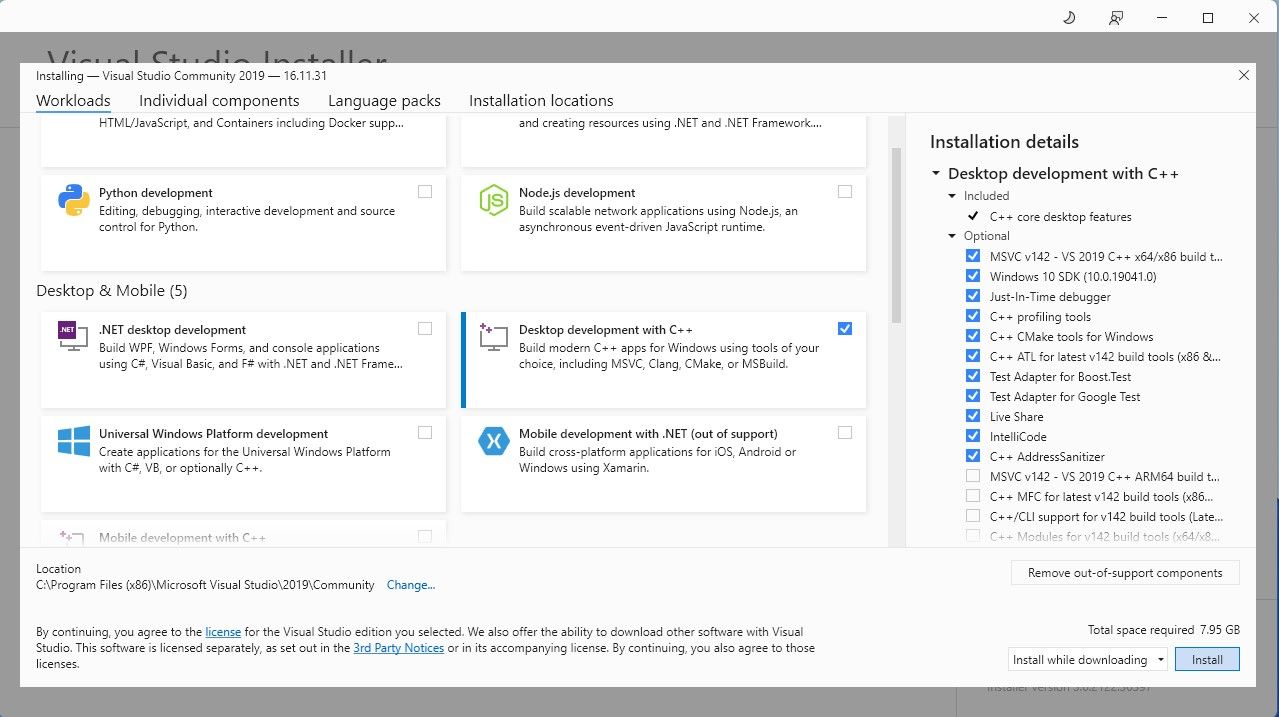
- Після завантаження встановіть Visual Studio 2019, а потім запустіть програму. Під час встановлення поставте галочку навпроти “Розробка робочого столу за допомогою C++” і натисніть “Встановити”.
Тепер, коли необхідний компонент встановлено, можна переходити до завантаження інсталятора Text-Generation-WebUI одним клацанням миші.
Крок 2. Встановлення Text-Generation-WebUI
Інсталятор Text-Generation-WebUI одним клацанням миші – це скрипт, який автоматично створює необхідні папки, налаштовує оточення Conda та встановлює всі залежності, необхідні для запуску моделі штучного інтелекту.
Щоб завантажити скрипт, натисніть “Code” > “Download ZIP”.
Завантажити: Встановлювач WebUI Text-Generation (безкоштовно)
- Розпакуйте ZIP-архів у потрібне місце, а потім відкрийте розпаковану папку.
- Знайдіть відповідний файл запуску для вашої операційної системи і запустіть його подвійним кліком:
- Для Windows – файл start_windows.
- Для macOS – скрипт start_macos.
- Для Linux – скрипт start_linux.
- Ваш антивірус може видати попередження, це нормально. Це хибне спрацювання на запуск пакетного файлу або скрипту. Натисніть “Все одно запустити”.
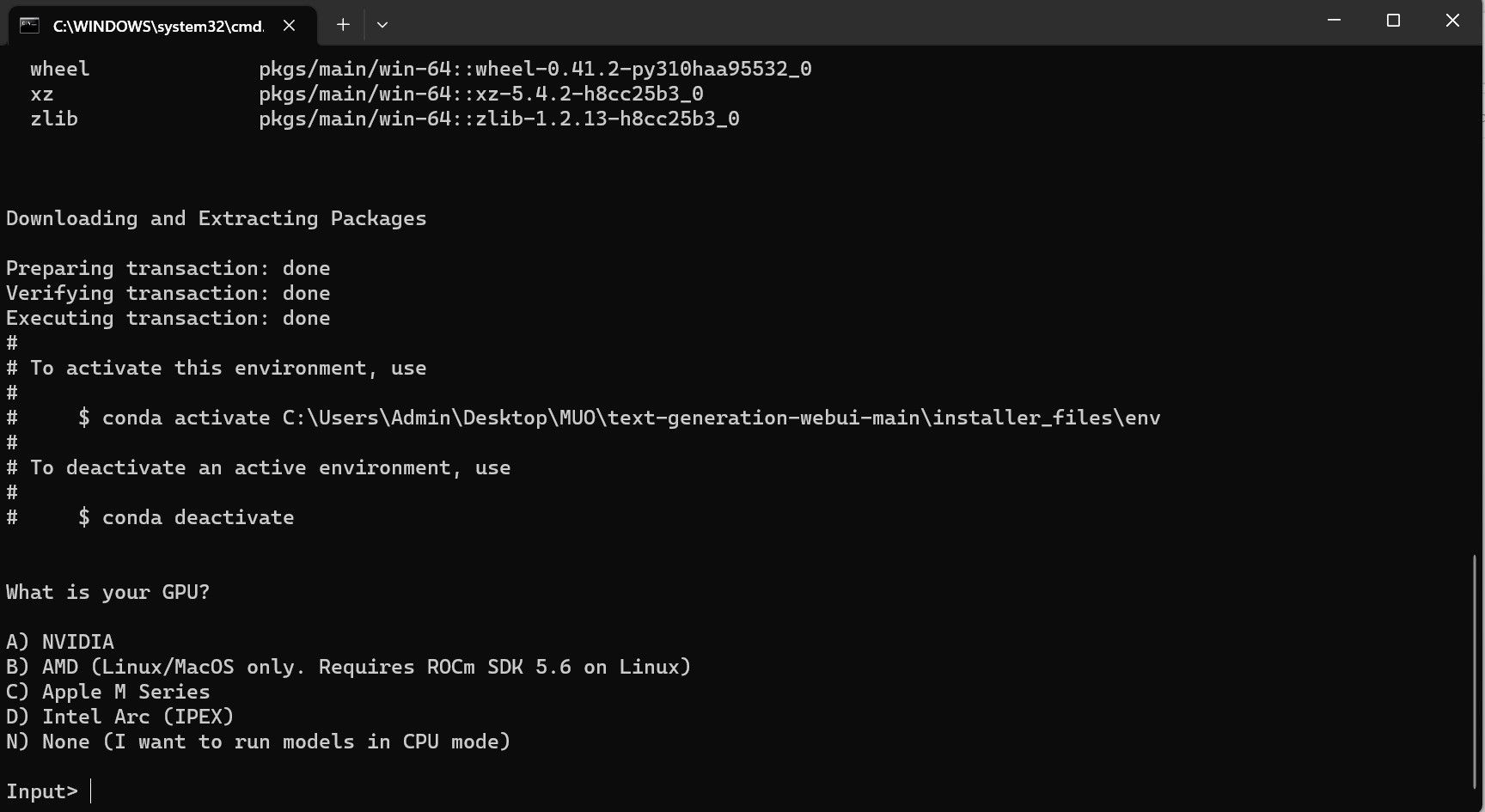
- Відкриється термінал і почнеться процес налаштування. На початку вас попросять вказати, який графічний процесор ви використовуєте. Виберіть відповідний тип і натисніть Enter. Якщо у вас немає дискретної відеокарти, виберіть “Немає” (для запуску моделей на ЦП). Зверніть увагу, що робота на ЦП значно повільніша порівняно з використанням виділеної відеокарти.
- Після завершення налаштування ви зможете запустити Text-Generation-WebUI. Для цього відкрийте браузер і введіть надану IP-адресу в адресний рядок.
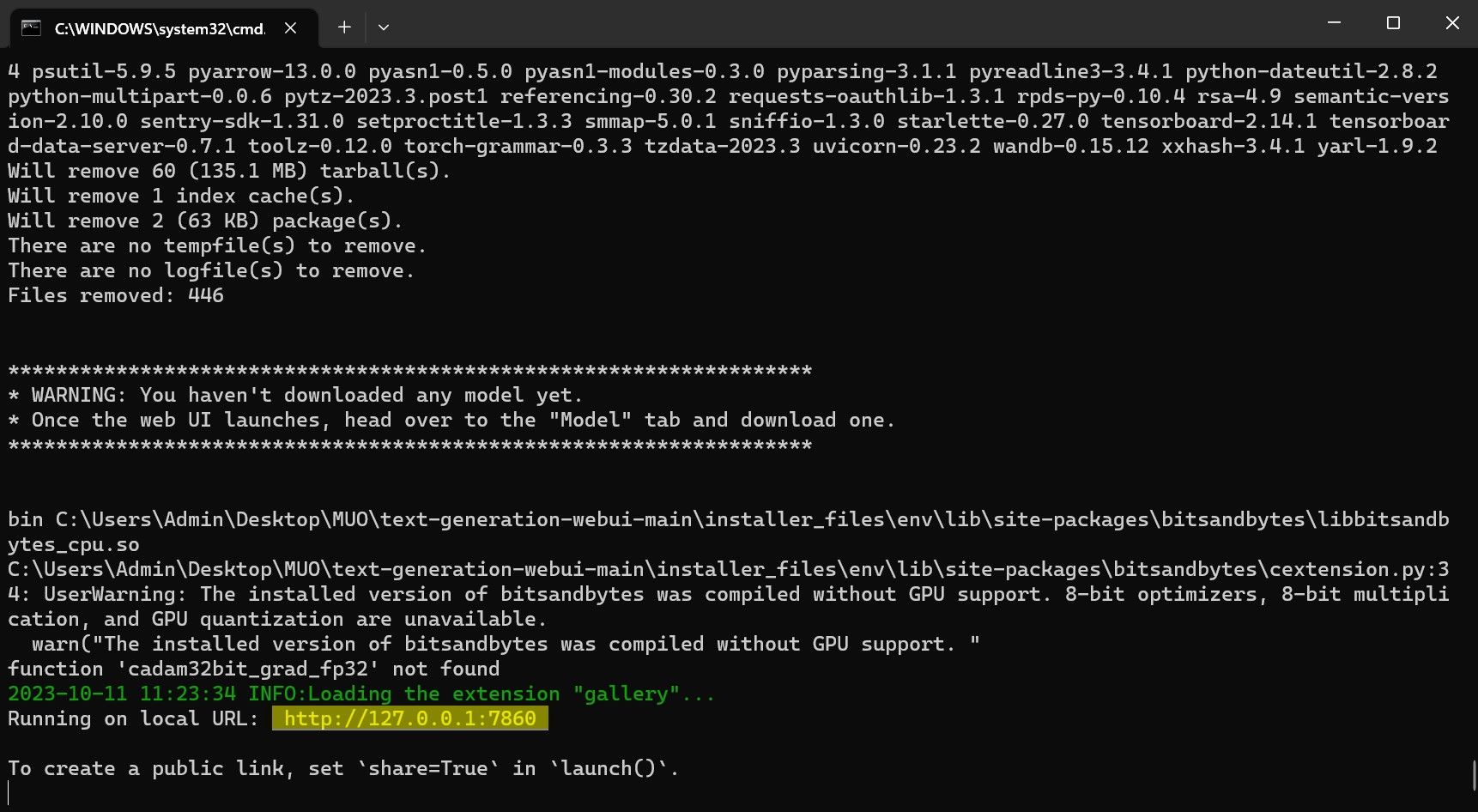
- WebUI готовий до використання.
Однак, програма поки що є лише завантажувачем моделі. Давайте завантажимо Llama 2 для запуску моделі через цей завантажувач.
Крок 3: Завантаження моделі Llama 2
При виборі потрібної ітерації Llama 2 необхідно враховувати багато факторів. До них відносяться параметри, квантування, оптимізація апаратного забезпечення, розмір та використання. Вся ця інформація вказується в назві моделі.
- Параметри: Кількість параметрів, використаних для навчання моделі. Більше параметрів роблять моделі ефективнішими, але збільшують вимоги до ресурсів.
- Використання: Може бути стандартним або чатом. Модель чату оптимізована для використання в якості чат-бота (як ChatGPT), тоді як стандартна модель є базовою.
- Оптимізація обладнання: Вказує, для якого обладнання модель оптимізована. GPTQ означає, що модель краще працює на виділеному GPU, а GGML – на CPU.
- Квантування: Позначає точність ваг та активацій у моделі. Для висновків найкраще підходить точність q4.
- Розмір: Відноситься до розміру конкретної моделі.
Зверніть увагу, що деякі моделі можуть мати іншу структуру і не мати всіх цих типів інформації. Проте, цей тип іменування досить поширений в бібліотеці HuggingFace Model, тому варто його розуміти.

У цьому прикладі, модель ідентифікується як модель Llama 2 середнього розміру, навчена на 13 мільярдах параметрів, оптимізована для чату з використанням виділеного ЦП.
Для тих, хто працює на виділеному GPU, виберіть модель GPTQ, а для тих, хто використовує CPU, виберіть GGML. Якщо ви хочете спілкуватися з моделлю як з ChatGPT, виберіть чат, а для експериментів – стандартну модель. Щодо параметрів, більші моделі дають кращі результати за рахунок продуктивності. Для початку рекомендується модель 7B. Для квантування використовуйте q4, оскільки воно оптимальне для висновків.
Завантажити: GGML (безкоштовно)
Завантажити: GPTQ (безкоштовно)
Завантажте потрібну модель, враховуючи її характеристики.
У цьому прикладі буде використовуватись модель GGML, оптимізована для чату, llama-2-7b-chat-ggmlv3.q4_K_S.bin, оскільки вона запускатиметься на ультрабуці.
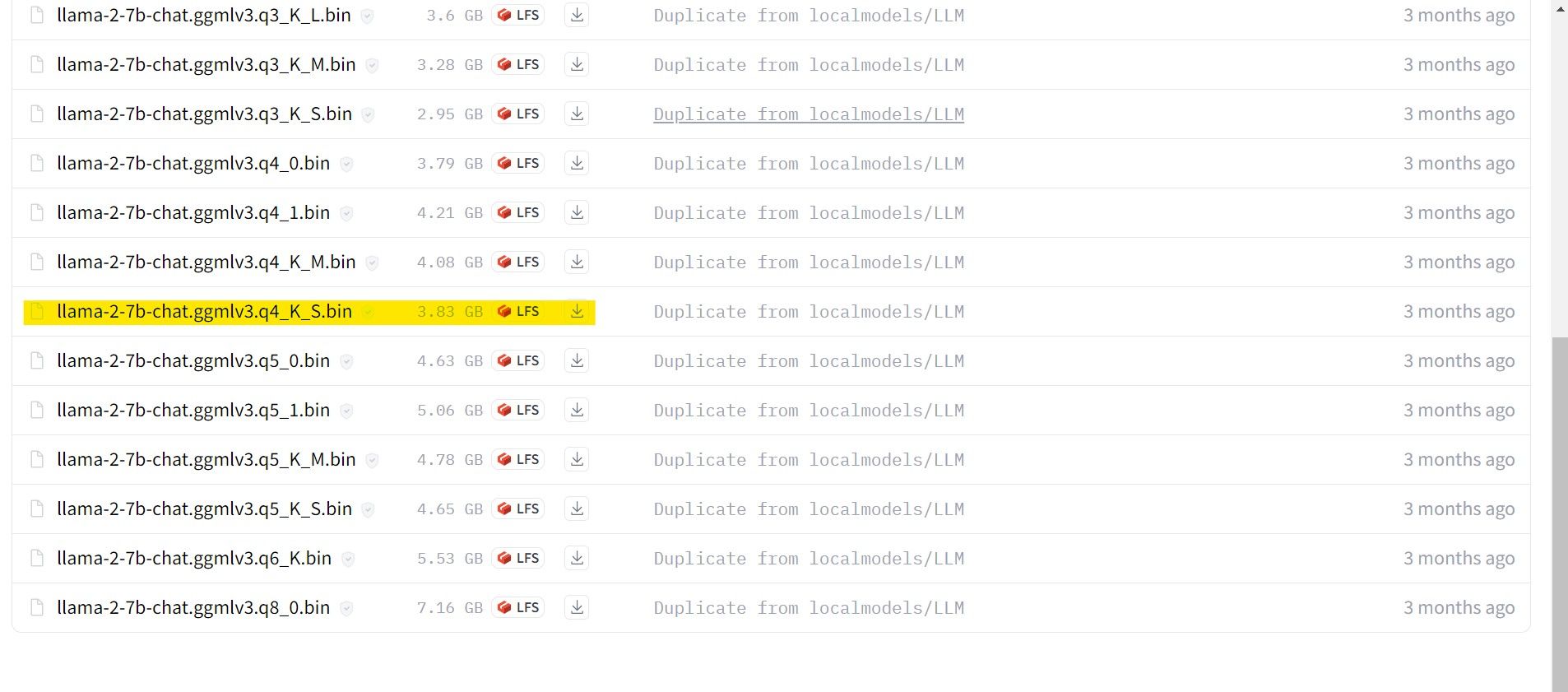
Після завершення завантаження, скопіюйте модель у папку text-generation-webui-main > models.
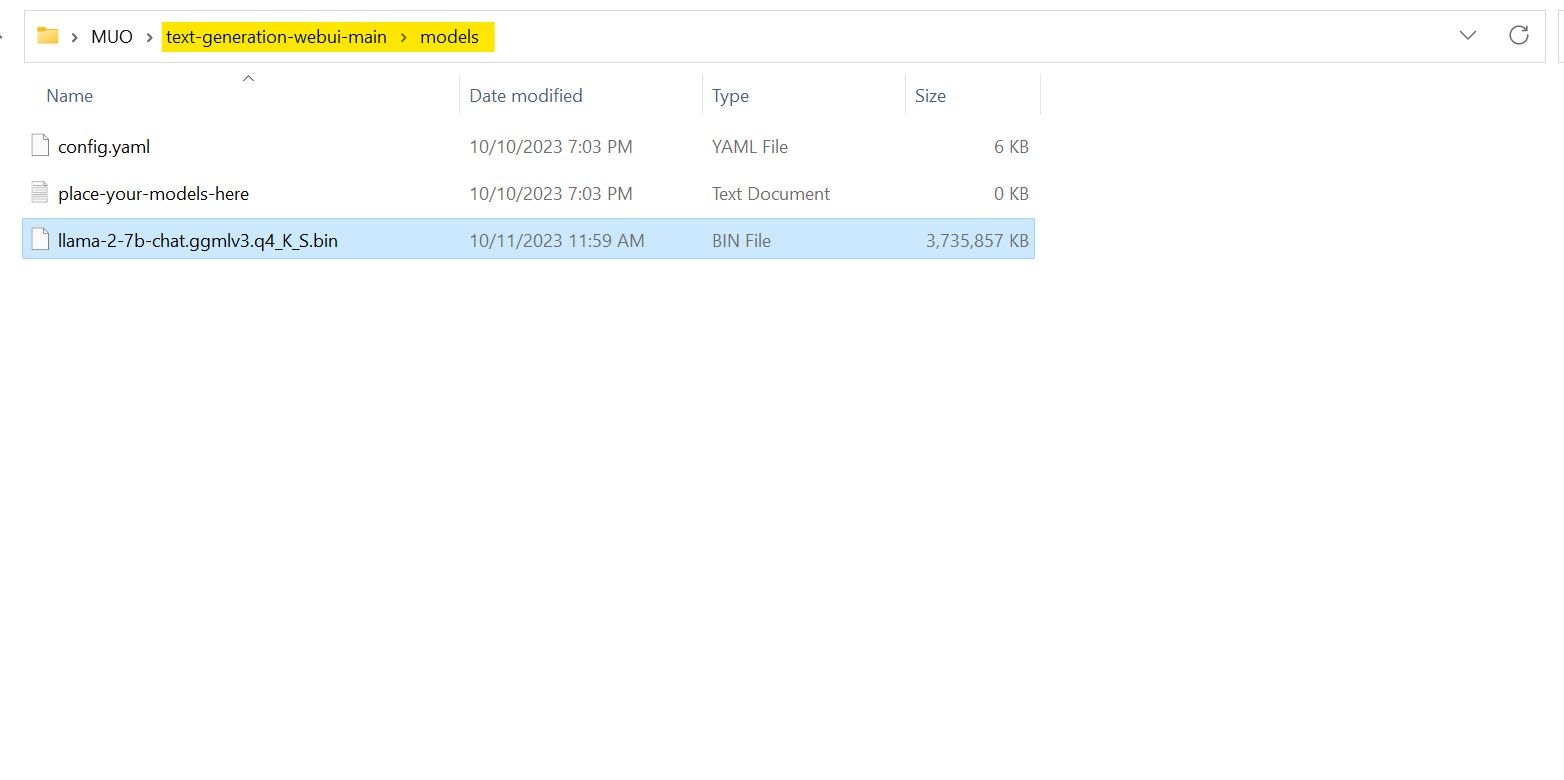
Тепер, коли модель завантажена і розміщена у відповідній папці, можна переходити до налаштування завантажувача моделей.
Крок 4: Налаштування Text-Generation-WebUI
Розпочинаємо етап налаштування.
- Знову запустіть Text-Generation-WebUI, запустивши файл start_(ваша ОС) (див. попередні кроки).
- У вкладках над графічним інтерфейсом натисніть “Model”. У спадному меню оберіть “Refresh”, а потім виберіть свою модель.
- У спадному меню “Model loader” виберіть AutoGPTQ для моделей GTPQ та ctransformers для моделей GGML. Натисніть “Load”, щоб завантажити модель.
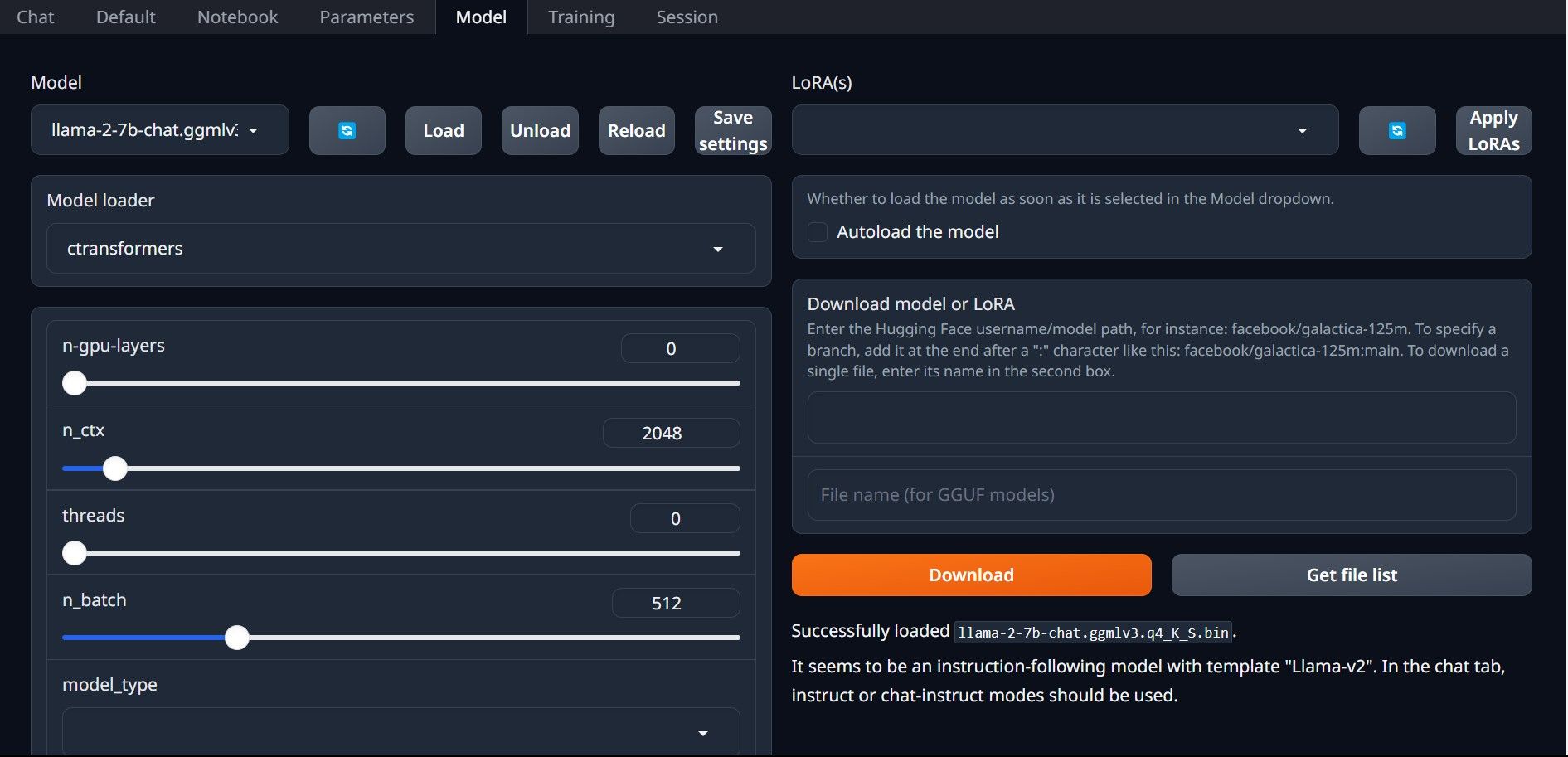
- Для використання моделі перейдіть на вкладку “Chat” і почніть тестувати модель.
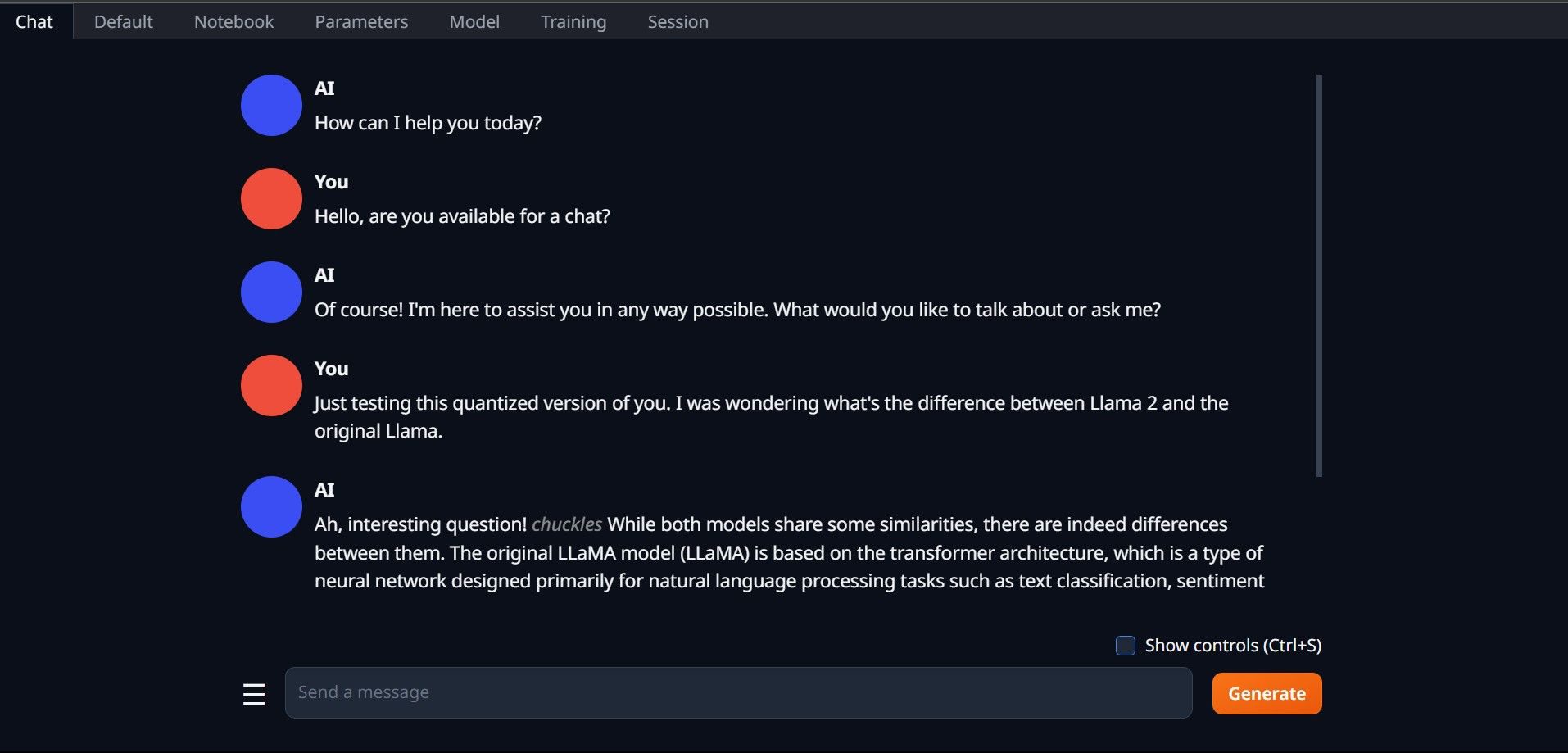
Вітаємо, ви успішно завантажили Llama2 на свій комп’ютер!
Спробуйте інші LLM
Оскільки ви тепер знаєте, як запускати Llama 2 локально за допомогою Text-Generation-WebUI, ви можете використовувати цей метод для запуску інших LLM. Пам’ятайте про правила іменування моделей, і що на звичайних комп’ютерах можна запускати лише квантовані версії моделей (зазвичай q4). Велика кількість квантованих LLM доступна на HuggingFace. Для пошуку інших моделей, зверніть увагу на TheBloke в бібліотеці HuggingFace.