Потокова платформа Apache Kafka: принципи роботи та інсталяція
Apache Kafka – це потужна система для обробки потокових даних, що дозволяє різним програмам у розподіленому середовищі взаємодіяти та обмінюватися інформацією через повідомлення.
Вона працює за принципом “видавник-підписник”, де програми-виробники публікують дані, а програми-споживачі підписуються на ці потоки.
Застосування Apache Kafka забезпечує гнучку архітектуру, де компоненти системи, що створюють та обробляють дані, слабо пов’язані між собою. Це значно спрощує розробку та управління всією системою. Для управління метаданими та синхронізації між елементами кластера Kafka використовує Zookeeper.
Ключові характеристики Apache Kafka
Apache Kafka отримала широке визнання завдяки наступним перевагам:
- Можливість масштабування за допомогою кластерів та розділів даних
- Висока швидкість обробки – здатна обробляти мільйони записів на секунду
- Гарантоване збереження порядку повідомлень
- Забезпечення надійності завдяки механізму реплікації даних
- Можливість оновлення без простою в роботі
Розглянемо деякі типові сценарії застосування Kafka.
Поширені випадки використання Apache Kafka
Kafka часто застосовується для обробки великих обсягів даних, запису та аналізу подій, наприклад, кліків користувачів для аналітичних цілей, а також для централізованого збору журналів з різних компонентів системи.
Вона забезпечує ефективну взаємодію між різними програмами та дозволяє обробляти дані в реальному часі з пристроїв IoT.
Далі детально розглянемо процес встановлення Kafka на операційних системах Windows та Linux.
Встановлення Kafka на Windows
Перед встановленням Apache Kafka на Windows переконайтеся, що на вашому комп’ютері встановлена Java. Відкрийте командний рядок від імені адміністратора та введіть команду:
java --versionЯкщо Java встановлена, ви побачите інформацію про поточну версію JDK.
Якщо з’явиться повідомлення про помилку “команда не розпізнана”, це означає, що Java не встановлена. Для встановлення Java перейдіть на веб-сайт Adoptium.net та завантажте інсталятор.
Запустіть завантажений інсталятор. З’явиться вікно майстра встановлення.
Для встановлення з параметрами за замовчуванням, кілька разів натисніть “Далі”. Після завершення встановлення перевірте, чи Java встановилася правильно. Закрийте поточний командний рядок, відкрийте новий від імені адміністратора та введіть команду:
java --versionЦього разу ви повинні побачити інформацію про встановлену версію JDK. Після завершення встановлення Java можна переходити до встановлення Kafka.
Для встановлення Kafka перейдіть на офіційний веб-сайт Kafka.

Перейдіть на сторінку завантажень. Завантажте останні доступні бінарні файли.
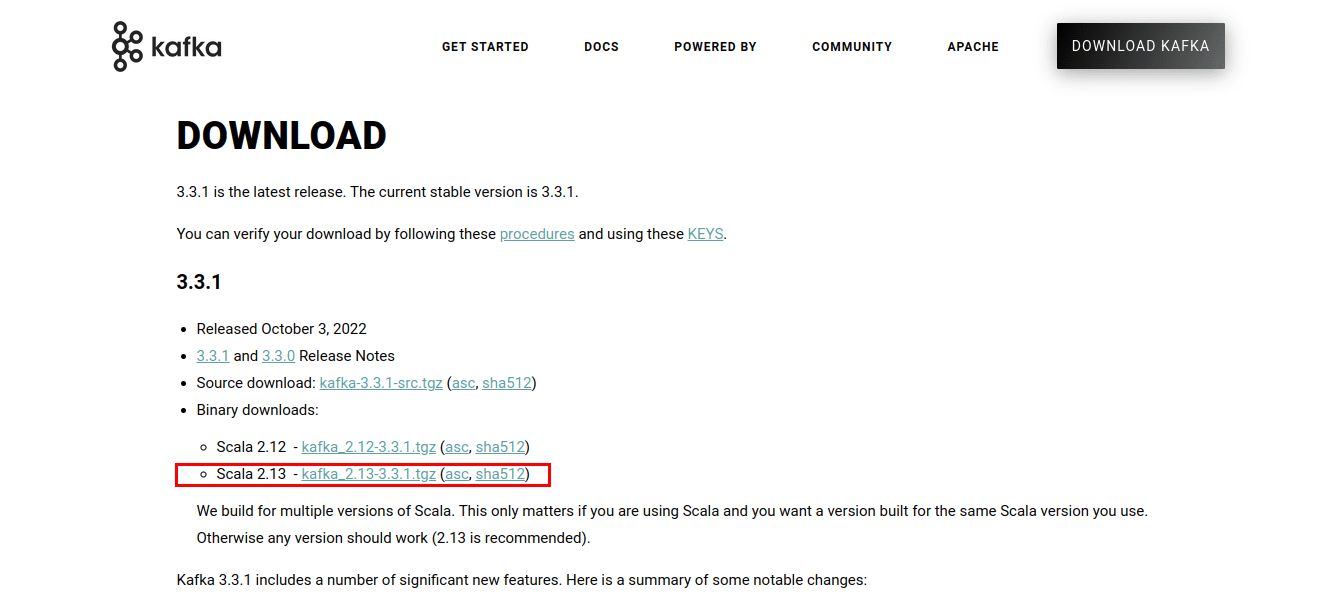
Завантажиться архів .tgz, що містить скрипти та бінарні файли Kafka. Розпакуйте цей архів. Для розпакування я використаю WinZip, який можна завантажити з веб-сайту WinZip.
Після розпакування перемістіть папку з файлами до кореневого каталогу диску C:, щоб шлях до файлів став C:\kafka.
Далі відкрийте командний рядок від імені адміністратора, перейдіть до каталогу Kafka та запустіть Zookeeper, виконавши файл zookeeper-server-start.bat з файлом конфігурації zookeeper.properties:
cd C:\kafka
bin\windows\zookeeper-server-start.bat config\zookeeper.propertiesПісля запуску Zookeeper, потрібно додати виконуваний файл wmic, який використовується Kafka, до системної змінної PATH:
set PATH=C:\Windows\System32\wbem;%PATH%;Потім запустіть сервер Apache Kafka. Відкрийте інший командний рядок від імені адміністратора, перейдіть до папки C:\kafka:
cd C:\kafkaЗапустіть Kafka, виконавши команду:
bin\windows\kafka-server-start.bat config\server.propertiesПісля цього Kafka має запрацювати. Ви можете налаштувати властивості сервера, наприклад, шлях до файлів журналів, у файлі server.properties.
Встановлення Kafka на Linux
Спочатку оновіть систему, виконавши наступну команду:
sudo apt update && sudo apt upgradeПотім перевірте, чи встановлено Java, виконавши команду:
java --versionЯкщо Java встановлена, ви побачите інформацію про версію. Якщо Java не встановлена, встановіть її за допомогою apt:
sudo apt install default-jdkДалі встановіть Apache Kafka, завантаживши бінарні файли з веб-сайту.
Відкрийте термінал та перейдіть до папки, куди було завантажено архів. У моєму випадку це папка “Завантаження”:
cd DownloadsРозпакуйте завантажені файли за допомогою tar:
tar -xvzf kafka_2.13-3.3.1.tgzПерейдіть до розпакованої папки:
cd kafka_2.13-3.3.1.tgzПерегляньте вміст папки.
У розпакованій папці запустіть сервер Zookeeper, виконавши скрипт zookeeper-server-start.sh, який розташовано у каталозі bin.
Скрипт потребує файл конфігурації Zookeeper. Файл за замовчуванням називається zookeeper.properties і розташований у підкаталозі config.
Запустіть сервер командою:
bin/zookeeper-server-start.sh config/zookeeper.propertiesПісля запуску Zookeeper запустіть сервер Apache Kafka. Скрипт kafka-server-start.sh також знаходиться у каталозі bin. Команда також потребує файл конфігурації, типовий файл server.properties знаходиться у папці config.
bin/kafka-server-start.sh config/server.propertiesЦе повинно запустити Apache Kafka. У каталозі bin ви знайдете багато скриптів для створення тем, управління виробниками та споживачами. Також, ви можете налаштувати властивості сервера у файлі server.properties.
Висновок
У цій інструкції ми розглянули, як встановити Java та Apache Kafka. Ви можете встановлювати та керувати кластерами Kafka вручну, а також скористатися керованими сервісами, такими як Amazon Web Services та Confluent.
Наступним кроком може бути вивчення обробки даних за допомогою Kafka та Spark.