У світі, де домінують дані, класичний підхід до збору інформації вручну втратив свою актуальність. Завдяки наявності комп’ютерів з доступом до інтернету на кожному робочому місці, мережа стала безмежним джерелом відомостей. Отже, вебагрегація є більш дієвим та економічним методом збору даних. Коли йдеться про вебагрегацію, Python пропонує інструмент під назвою Beautiful Soup. У цій статті я проведу вас через процес встановлення Beautiful Soup, щоб ви могли почати працювати з вебагрегацією.
Перш ніж перейти до інсталяції та роботи з Beautiful Soup, давайте розберемося, чому вам варто його використовувати.
Що таке Beautiful Soup?
Уявіть, що ви досліджуєте тему “Вплив COVID на здоров’я людей” і знайшли кілька веб-сторінок з необхідними даними. Але що робити, якщо ці сайти не пропонують можливості завантажити дані одним кліком? Саме тут на допомогу приходить Beautiful Soup.
Beautiful Soup є однією з бібліотек Python, призначених для отримання даних з потрібних веб-сайтів. Вона спрощує процес отримання інформації зі сторінок HTML або XML.
Леонард Річардсон запропонував концепцію Beautiful Soup для сканування інтернету у 2004 році. Його внесок у проект триває й до сьогодні. Він з ентузіазмом анонсує кожне нове оновлення Beautiful Soup у своєму Twitter-акаунті.
Незважаючи на те, що Beautiful Soup для вебагрегації було розроблено з використанням Python 3.8, вона бездоганно працює як з Python 3, так і з Python 2.4.
Часто веб-сайти застосовують захист капчею, щоб убезпечити свої дані від інструментів штучного інтелекту. У таких випадках, кілька змін у заголовку “user-agent” в Beautiful Soup або використання API, що розгадують капчу, можуть імітувати справжній браузер і обійти систему виявлення.
Однак, якщо у вас немає часу на вивчення Beautiful Soup або ви хочете, щоб копіювання було ефективним та простим, вам слід звернути увагу на API веб-скрапінгу, де ви можете просто надати URL-адресу і отримати дані.
Якщо ви вже програміст, використання Beautiful Soup для скрапінгу не буде для вас складним через його інтуїтивний синтаксис для навігації веб-сторінками та вилучення необхідних даних на основі умовного аналізу. Водночас вона також підходить для початківців.
Хоча Beautiful Soup не призначений для розширеного аналізу, він ідеально підходить для збору даних з файлів, написаних мовами розмітки.
Чітка та детальна документація – ще одна важлива перевага Beautiful Soup.
Давайте знайдемо простий спосіб встановити Beautiful Soup на ваш комп’ютер.
Як встановити Beautiful Soup для вебагрегації?
Pip, простий менеджер пакетів Python, розроблений у 2008 році, тепер є стандартним інструментом для розробників для встановлення будь-яких бібліотек або залежностей Python.
Pip зазвичай поставляється разом з встановленням останніх версій Python. Тож, якщо у вас встановлено одну з останніх версій Python, ви готові до роботи.
Відкрийте командний рядок та введіть наступну команду pip, щоб швидко встановити Beautiful Soup.
pip install beautifulsoup4
На екрані ви побачите щось схоже на зображення нижче.
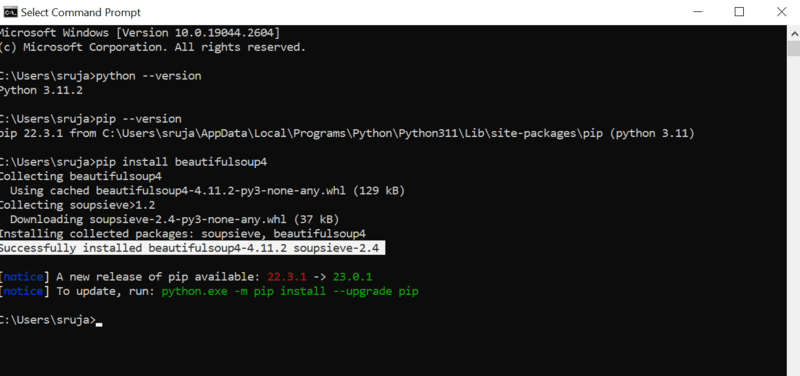
Переконайтеся, що ви оновили програму встановлення pip до останньої версії, щоб уникнути поширених помилок.
Команда для оновлення інсталятора pip до останньої версії:
pip install --upgrade pip
У цій статті ми успішно пройшли половину шляху.
Тепер, коли Beautiful Soup встановлено на вашому комп’ютері, давайте подивимось, як використовувати його для веб-скрапінгу.
Як імпортувати та працювати з Beautiful Soup для вебагрегації?
Введіть наступну команду у вашому Python IDE, щоб імпортувати Beautiful Soup у ваш поточний Python-скрипт.
from bs4 import BeautifulSoup
Тепер Beautiful Soup доступний у вашому Python-файлі для використання у процесі скрапінгу.
Давайте розглянемо приклад коду, щоб зрозуміти, як витягувати потрібні дані за допомогою Beautiful Soup.
Ми можемо наказати Beautiful Soup шукати певні HTML-теги на вихідному веб-сайті та отримувати дані, що містяться в цих тегах.
У цьому прикладі я використаю marketwatch.com, який оновлює ціни акцій різних компаній у режимі реального часу. Давайте витягнемо деякі дані з цього веб-сайту, щоб ознайомитися з бібліотекою Beautiful Soup.
Імпортуйте пакет “requests”, який дозволить нам відправляти HTTP-запити та отримувати відповіді, а також “urllib” для завантаження веб-сторінки за її URL-адресою.
from urllib.request import urlopen import requests
Збережіть посилання на веб-сторінку у змінній, щоб потім мати до неї легкий доступ.
url="https://www.marketwatch.com/investing/stock/amzn"
Далі скористаємося методом “urlopen” з бібліотеки “urllib” для збереження HTML-сторінки у змінній. Передайте URL-адресу функції urlopen і збережіть результат у змінній.
page = urlopen(url)
Створіть об’єкт Beautiful Soup та проаналізуйте необхідну веб-сторінку за допомогою ‘html.parser’.
soup_obj = BeautifulSoup(page, 'html.parser')
Тепер весь HTML-скрипт цільової веб-сторінки зберігається у змінній ‘soup_obj’.
Перш ніж продовжити, давайте розглянемо вихідний код цільової сторінки, щоб отримати більше інформації про HTML-скрипт та теги.
Клацніть правою кнопкою миші у будь-якій точці веб-сторінки. Далі ви побачите опцію перевірки, як показано нижче.
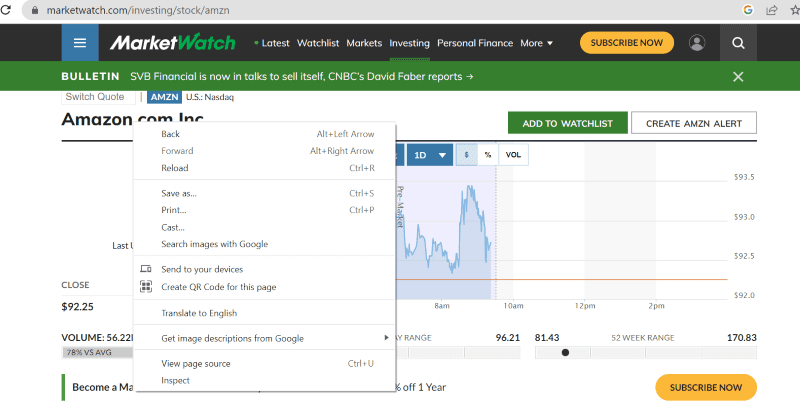
Натисніть “Перевірити”, щоб переглянути вихідний код.
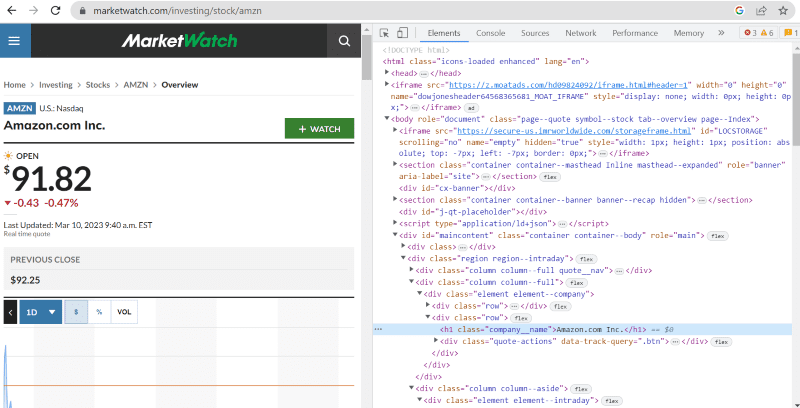
У вихідному коді вище можна знайти теги, класи та більш конкретну інформацію про кожен елемент, видимий в інтерфейсі веб-сайту.
Метод “find” у Beautiful Soup дозволяє шукати потрібні HTML-теги та отримувати дані. Для цього ми вказуємо назву класу та теги методу, який витягує певні дані.
Наприклад, “Amazon.com Inc.” на веб-сторінці має назву класу: ‘company__name’ з тегом ‘h1’. Ми можемо ввести цю інформацію в метод “find”, щоб отримати відповідний фрагмент HTML у змінну.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Давайте виведемо HTML-скрипт, збережений у змінній “name”, і необхідний текст на екрані.
print(name) print(name.text)

Ви можете бачити витягнуті дані, надруковані на екрані.
Вебагрегація з веб-сайту IMDb
Багато хто з нас перевіряє рейтинги фільмів на сайті IMDb перед переглядом. Ця демонстрація надасть вам перелік фільмів з найвищим рейтингом і допоможе вам звикнути до Beautiful Soup для вебагрегації.
Крок 1. Імпортуйте необхідні бібліотеки Beautiful Soup і requests.
from bs4 import BeautifulSoup import requests
Крок 2. Призначимо URL-адресу, з якої ми хочемо отримати дані, змінній “url” для легкого доступу в коді.
Пакет “requests” використовується для отримання HTML-сторінки з URL-адреси.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Крок 3: У наступному фрагменті коду ми розберемо HTML-сторінку поточної URL-адреси для створення об’єкта Beautiful Soup.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Змінна “soup_obj” тепер містить весь HTML-скрипт необхідної веб-сторінки, як на зображенні нижче.
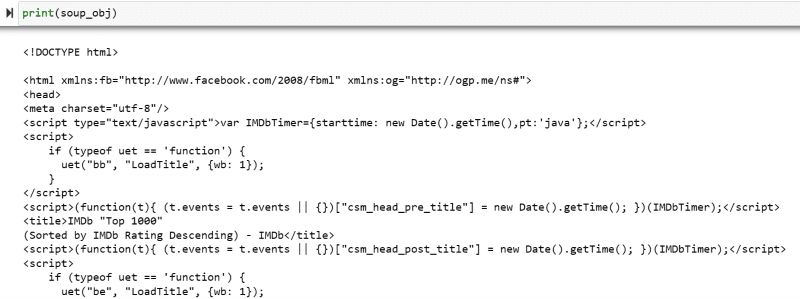
Давайте перевіримо вихідний код веб-сторінки, щоб знайти HTML-скрипт даних, які ми хочемо отримати.
Наведіть курсор на елемент веб-сторінки, який потрібно витягнути. Далі клацніть правою кнопкою миші та виберіть опцію перевірки, щоб переглянути вихідний код цього конкретного елемента. Наступні візуальні матеріали допоможуть вам краще.
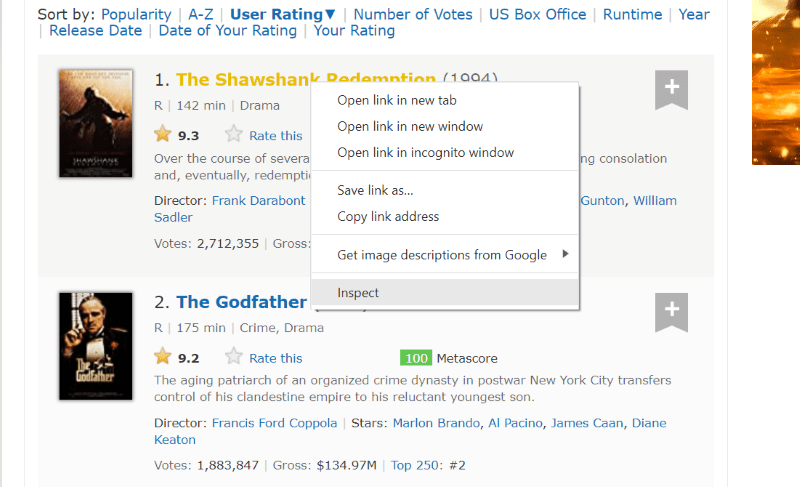
Клас “lister-list” містить всі дані, пов’язані з фільмами з найвищим рейтингом, у вигляді підрозділів у послідовних div-тегах.
У HTML-скрипті кожної картки фільму під класом “lister-item mode-advanced” є тег “h3”, який зберігає назву фільму, рейтинг та рік випуску, як показано на зображенні нижче.
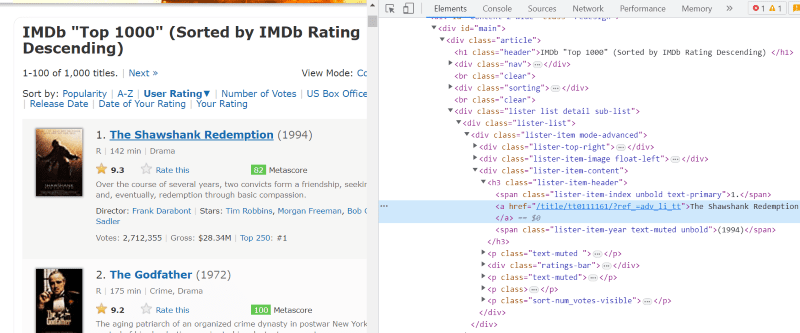
Примітка. Метод “find” у Beautiful Soup шукає перший тег, який відповідає заданій назві. На відміну від “find”, метод “find_all” шукає всі теги, які відповідають заданим критеріям.
Крок 4. Ви можете використовувати методи “find” і “find_all”, щоб зберегти HTML-скрипт назви, рейтингу та року випуску кожного фільму у змінній списку.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
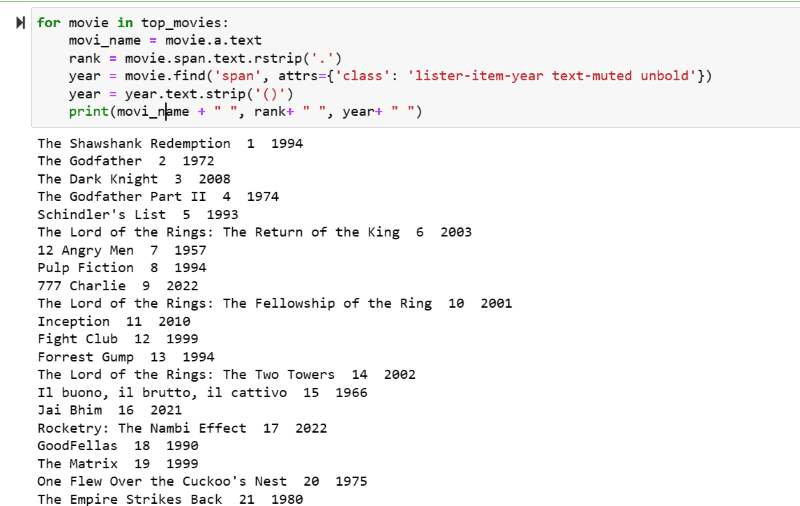
Крок 5. Перегляньте список фільмів, збережених у змінній “top_movies”, та витягніть назву, рейтинг і рік кожного фільму в текстовому форматі з його HTML-скрипту за допомогою наведеного нижче коду.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
На вихідному скріншоті ви можете побачити список фільмів з їхньою назвою, рейтингом та роком випуску.
Ви можете легко перемістити ці дані до Excel-таблиці за допомогою Python-коду і використовувати їх для подальшого аналізу.
Заключні слова
Ця стаття допоможе вам встановити Beautiful Soup для веб-агрегації. Крім того, наведені приклади скрапінгу допоможуть вам почати працювати з Beautiful Soup.
Оскільки вас цікавить встановлення Beautiful Soup для веб-скрапінгу, я наполегливо рекомендую вам ознайомитися з цим детальним посібником, щоб дізнатися більше про вебагрегацію з використанням Python.